
这是「进击的Coder」的第 725 篇技术分享
作者:崔庆才

大家好,我是崔庆才。
大家国庆快乐哈,不过国庆期间除了玩,有些时间我也在“学习”,今天就给大家分享个干货吧!
想必大家平时可能会做一些数据分析,那么数据分析肯定就少不了数据。
数据从哪里来呢?我们可以通过网络爬虫来爬取数据,但是这个还是需要耗费一定时间的。
这时候就会有朋友说了,有没有现成的数据呢?当然有了,今天就给大家分享一个基于 Python 的、简便易用的数据接口,可能包含我们想要的各种各样的数据。
简介
这个库的名字叫 GoPUP,GitHub 主页是:https://github.com/justinzm/gopup
这其实是一个基于公开 API 的数据接口库,这个库封装了各种各样的方法,比如通过 wx_hot_list 这个方法我们就可以获取实时的微信热门文章榜单。
基本使用
下面我们来简单介绍下它的使用方法,首先是安装,使用 pip3 即可:
pip3 install gopup
因为这个库会不断升级,如果要升级的话大家可以运行如下命令:
pip3 install -U gopup
安装完毕之后就可以开始使用了,其实使用起来还是非常简单的。
比如这里我们以「微博指数」为例来说明下用法,官方文档见 http://doc.gopup.cn/#/data/index_data?id=微博指数数据
接口: weibo_index
描述: 获取指定 词语 的微博指数
输入参数
名称类型必须描述wordstrY关键词time_typestrYtime_type="1hour"; 1hour, 1day, 1month, 3month 选其一.输出参数
名称类型默认显示描述datedatetimeY日期-索引indexfloatY指数
大家可以看到,这个接口的目标地址实际上就是一个公开 API,然后我们只需要输入对应的词语和时间段,就可以输出对应的指数结果。
接口用法如下:
import gopup as gp
df_index = gp.weibo_index(word="疫情", time_type="3month")
print(df_index)
这里我们先导入了 gopup 库,然后调用了它的 weibo_index 方法,传入关键词和时间段,这里我们查询的是最近三个月的疫情对应的微博指数,也就对应这个词在微博的热度。
运行结果如下:
疫情
index
2022-07-04 1518338
2022-07-05 1950590
2022-07-06 1924655
2022-07-07 1825620
2022-07-08 1768546
... ...
2022-09-30 2083183
2022-10-01 1365015
2022-10-02 1498437
2022-10-03 1323310
2022-10-04 1244449
[93 rows x 1 columns]
可以看到输出的实际上是 Pandas 的 DataFrame 数据结构,如果我们用 Jupyter 运行的话可能更直观一些。
安装并运行 Jupyter
pip3 install jupyter
jupyter notebook
运行类似的代码,结果如下: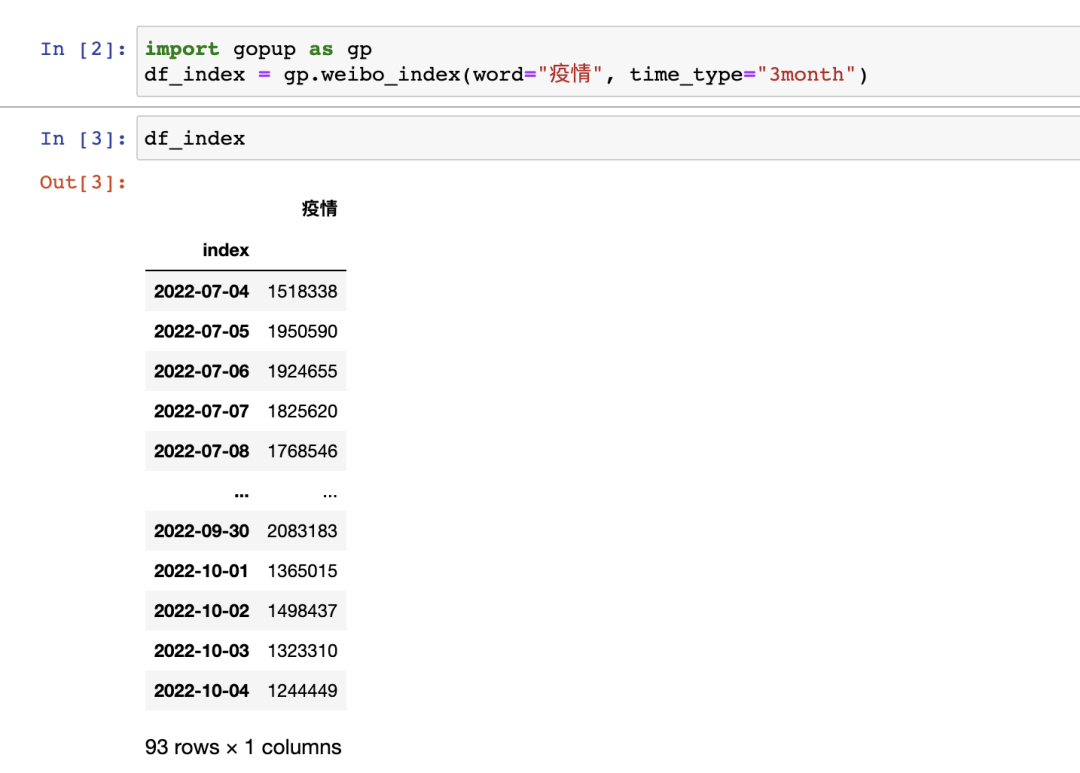
我们还可以进一步将其转化为可视化图表:
import matplotlib.pyplot as plt
plt.figure(figsize=(15, 5))
plt.title("微博「疫情」热度走势图")
plt.xlabel("时间")
plt.ylabel("指数")
plt.plot(df_index.index, df_index['疫情'], '-', label="指数")
plt.legend()
plt.grid()
plt.show()
结果如下: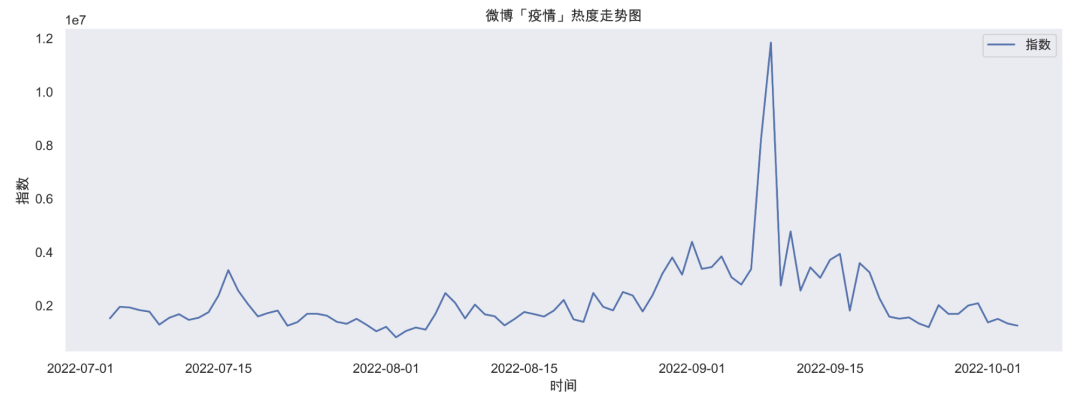
这样通过简单的几行代码我们就可以轻松将某个词的热度走势可视化出来了,绘制成折线图之后,热度走势一目了然。
更多数据
当然上面仅仅是冰山一角,GoPUP 集成了各种公开 API,就像个爬虫一样给各种 API 提供了封装,数据可谓是应有尽有。
根据 GoPUP 的简介,这里面的数据包括这些类别:
- 指数数据:微博指数数据,百度指数数据,百度搜索数据,百度资讯指数,百度媒体指数,百度需求图谱,百度人群画像年龄分布,百度人群画像性别分布,百度人群画像兴趣分布;
- 算数数据:算数指数数据,算数相关性分析,算数地域分析,算数城市分析,算数年龄分析,算数性别分析,算数用户阅读兴趣分类,谷歌指数数据,谷歌指数数据,谷歌事实查证;
- 宏观数据:中国宏观数据,中国宏观杠杆率数据,货币汇率数据;
- 利率数据:Shibor数据,Shibor报价数据,Shibor均值数据,LPR数据;
- 公司数据:千里马公司,独角兽公司,倒闭公司,商业特许经营公司;
- 信息数据:新闻联播文字稿;
- 生活数据:中国油价数据,汽柴油历史调价信息,调价日的地区油价历史数据;
- 诗词数据:唐代诗人,唐诗数据;
- 影视数据:实时电影票房数据,单日电影票房数据,单日影院票房数据,实时电视剧播映指数,实时综艺播映指数,艺人商业价值,艺人流量价值;
- 全国高校数据:全国普通高等学校名单,全国成人高等学校名单,全国高等学校详情数据;
- 疫情数据:网易疫情数据,丁香园疫情数据……
当然这个库也在不断更新,更多详细的内容大家可以到官方文档了解下:http://doc.gopup.cn/#/README
有了这些数据,我们做数据分析和可视化就不用再去写爬虫啦,直接拿来用就好了,简直不要太方便!
好了,关于 GoPUP 就介绍这么多了,大家可以来试试看吧~

End
崔庆才的新书《Python3网络爬虫开发实战(第二版)》已经正式上市了!书中详细介绍了零基础用 Python 开发爬虫的各方面知识,同时相比第一版新增了 JavaScript 逆向、Android 逆向、异步爬虫、深度学习、Kubernetes 相关内容,同时本书已经获得 Python 之父 Guido 的推荐,目前本书正在七折促销中!
内容介绍:《Python3网络爬虫开发实战(第二版)》内容介绍

扫码购买

点个在看你最好看

版权归原作者 VIP_CQCRE 所有, 如有侵权,请联系我们删除。