
🌕写在前面 🎉欢迎关注🔎点赞👍收藏⭐️留言📝 ✉️今日分享:
生命中最伟大的光辉不在于永不坠落,而是坠落后总能再度升起。我欣赏这种有弹性的生命状态,快乐的经历风雨,笑对人生。
🍀 前言
数据脱敏最重要的一点就是能不能精准识别出敏感数据,之后才是针对性脱敏。静态脱敏可以概括为数据的“搬移并仿真替换”,动态脱敏可以概括为“边脱敏,边使用”。 一键式的敏感数据发现功能,盘点梳理数据库里面的敏感资产,并对相关资产进行分类分级;对敏感数据通过随机、转换、遮盖等脱敏方式实现对数据的脱敏。动态脱敏则可以针对不同的身份采用不同的动态脱敏策略,对不同权限的用户可分别返回真实数据、部分遮盖、全部遮盖等脱敏结果。
**🍀 **数据脱敏核心功能
** 🍊**敏感数据发现
能够按照用户指定的一部分敏感数据或预定义的敏感数据特征,在执行任务过程中对抽取的数据进行自动的识别并发现敏感数据。通过自动识别敏感数据,可以避免按照字段定义敏感数据元的繁琐工作,同时最大限度的对所有需要抽取的敏感数据进行自动脱敏,同时能够持续的发现新的敏感数据。
需要注意的是必须要解决组合字段作为敏感数据的场景,这样单表中多个敏感字段同时出现时可以发现为敏感数据,
🍊****敏感数据梳理
具备敏感数据梳理能力,包含敏感字段梳理和敏感文件梳理,用于数据库敏感字段及文件敏感列的梳理和核实。敏感数据梳理在敏感数据自动发现基础上,人工辅助对数据列、敏感数据关系的调整,达到更精细准确敏的感数据管理。
🍊****数据子集管理
在许多场景下,并不需要将全部生产环境中数据脱敏至目标环境使用,如开发环境可能仅需要生产环境中1%的数据;统计分析场景则需要对全部数据进行合理采样。支持对目标数据库中一部分数据进行脱敏,用户可指定过滤条件,对数据来源进行过滤筛选形成数据子集,适应不同场景下脱敏需求。
🍊 脱敏方案管理
可以根据各类数据应用场景如系统开发、功能测试、性能测试、数据分析等,制定不同的脱敏方案。针对开发及测试环境的脱敏方案可保证脱敏后数据具有唯一性及确定性,而针对数据分析场景,可保证脱敏后数据的可还原性。脱敏策略是将敏感数据进行脱敏处理的规则,脱敏策略包含了敏感数据特征以及对于这类数据的脱敏算法。对于同一类应用场景,用户可将若干脱敏策略组合成为适用于该场景的脱敏方案,脱敏方案制定后,可被重复利用于该场景下不同批次数据的脱敏需求。
还需要考虑不同数据库之间的数据脱敏转换。(异构数据脱敏)可能会出现源数据库使用的是一种类型,而数据需求方使用的数据库是另一种类型,这时候的数据脱敏就需要兼容不同数据库之间的数据转换。
🍊****脱敏任务管理
脱敏任务可针对目标数据库系统或结构化文件进行。通过脱敏任务,将产品与提供原始数据的业务系统和使用脱敏后数据的系统连接起来,用户可在任务内选择脱敏数据来源、脱敏数据去向以及最适合的数据脱敏方案。脱敏任务可兼容执行过程中遇到的异常情况,支持跳过异常数据继续执行任务。
🍊****发现规则管理
具备敏感数据发现规则管理能力。比如:正则表达式、数据字典或字段字典、自定义函数方式、字段名等。可以通过将字段内信息按位拆分成多个敏感数据,以此解决字段中存在复合敏感数据的数据发现需求。
🍀 数据脱敏实现原理
数据脱敏的基本原理是通过脱敏算法将敏感数据进行遮蔽、变形,将敏感级别降低后对外发放,或供访问使用。根据不同的使用场景可以分为“静态脱敏”和“动态脱敏”两类技术,这两类脱敏技术从适用场景、技术手段、部署方式三个方面有所不同。
🌳 数据静态脱敏实现原理
数据静态脱敏是按照用户指定或预定义的敏感数据特征,对数据进行自动识别,发现敏感数据。建立数据子集,并根据数据子集的范围抽取数据。抽取的数据中可进行关联数据的自动识别和数据抽取。对抽取的数据按照用户指定或预定义的脱敏算法策略,对数据进行屏蔽、变形、替换、随机等数据脱敏处理。将脱敏完成后的数据根据用户指定的目标数据库或目标文件进行数据加载。
** 🥝扩展知识: 获取数据的方式**
我们要知道数据脱敏第一步,需要获得数据库中的数据。如何获得数据主要有以下几种方式:
1、数据库开发接口
这种针对不同的数据库开发接口方式的有点在于数据采集速度较快,市面上大部分脱敏产品采用此种方式。这种采集方式的缺点也很明显,数据库类型太多,脱敏产品支持的数据库类型与版本都会受限制。如果用户将来升级了数据库版本,除非脱敏厂商也花精力开发升级版本,否则采购的脱敏产品可能无法继续支持。
2、ETL技术
这种采集技术的优势是兼容性大,ETL工具兼容的数据库类型是最全面的。当然这个方式也有弱点,由于不是专门针对特定数据库类型开发,在没有强大的ETL技术积累的情况下,采集数据的速度一般。从国外脱敏厂商来看,具备有一定ETL技术积累优势大多采用此种技术,如:Informatica 。而国内脱敏厂商中,大多数厂商主业并不是大数据处理,没有ETL工具的技术能力而很少采用。
** 3、代理软件**
使用代理软件,部署在数据库上从数据库读取数据。这种方式的脱敏产品对用户方来说是侵入式的,只有极少数产品才这样使用。市面上数据备份厂商的数据脱敏产品会采用这种方式,因为利用备份软件客户端作为数据脱敏的数据采集工具使用,速度较快。
🌳数据动态脱敏实现原理
动态数据脱敏是在用户层对数据进行独特屏蔽、加密、隐藏、审计或封锁访问途径的流程,当应用程序、维护、开发工具请求通过动态数据脱敏(DDM) 时,实时筛选请求的SQL语句,依据用户角色、权限和其他脱敏规则屏蔽敏感数据,并且能运用横向或纵向的安全等级,同时限制响应一个查询所返回的行数。
动态数据脱敏(DDM)以这种方式确保业务人员、运维人员以及外包开发人员严格根据其工作所需和安全等级访问敏感数据。
** 🥝扩展知识:三种动态脱敏技术**
1、第一代动态脱敏技术:数据库层动态脱敏(结果集改写技术)
最早,动态脱敏技术正是通过结果集改写方式来实现,此为第一代动态脱敏技术。结果集改写技术是基于结果集解析技术,在数据库返回结果后,在脱敏设备上判断结果集中哪些数据需要脱敏,并在设备中进行脱敏处理的技术路线。
2、第二代动态脱敏技术:数据库层动态脱敏(SQL语句改写技术)
SQL语句改写技术依然是通过对数据库协议的反向代理实现数据库层的动态脱敏目标,同样是在数据返回应用系统之前进行脱敏处理。该技术的面世解决了结果集改写方式效率低下的难题,可以称之为第二代动态脱敏技术。其基于SQL语句解析技术,将包含敏感字段的查询语句进行改写,对敏感字段采用函数运算的方式,让数据库自行返回不包含敏感数据的改写后的结果。其运算过程快速,与标准SQL语句执行相差无几,且过程执行是在数据库之中,脱敏设备不会成为业务的性能瓶颈。
3、第三代动态脱敏技术:混合模式动态脱敏
无论是第一代、第二代动脱技术,还是作为不同应用模式的四个细分技术路线,都各有优劣,且某些场景无法互相替代,所以动脱技术的进化方向就变得清晰起来——一种能够兼顾两种技术类型优势,覆盖不同应用模式的动态脱敏技术。混合脱敏技术应运而生,它可以同时支持结果集改写和SQL语句改写两种技术,可以根据需求灵活改变部署位置覆盖四种应用场景,我们将其称为第三代动态脱敏技术。第三代动脱技术兼具一二代技术的优势,一定程度突破了上述四种技术路线的瓶颈,由后台智能判断当前场景适合哪种脱敏技术,无需人工干预,实现兼容性、高性能、适用性的最佳平衡。当然,在某些单一场景下,第三代动脱技术依然存在第一代性能偏低的问题,但整体上是可以实现最佳平衡的。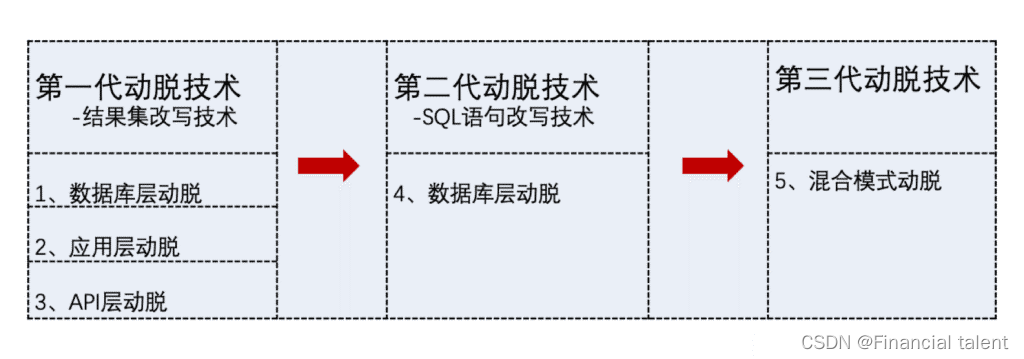
总结
只要需求在,技术的进步就没有止境。数据脱敏技术的发展演进,就是市场在持续满足不同用户的多样化数据脱敏需求场景下得以完成的。当然,这些场景需求的满足又都是在《数据安全法》的大语境和数据安全治理的大框架下徐徐展开的。企业数据安全建设能力的提升,必然依赖于核心技术的不断迭代进化和强势驱动,我们相信,技术进步永远是安全进步的尺度。
🙏作者水平很有限,如果发现错误,请留言轰炸哦!万分感谢感谢感谢
版权归原作者 Financial talent 所有, 如有侵权,请联系我们删除。