
说明:因为yolov5函数中已经计算了 FLOPS,因此如果想要计算访存量那么只需按照flops的位置,添加访存量的计算即可
一、先记住计算量和访存量的公式:
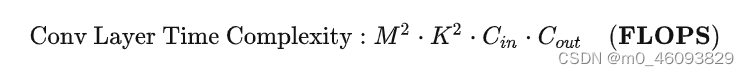
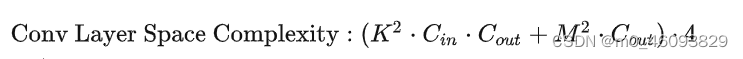

二、找到计算FLOPS的位置,并添加访存量
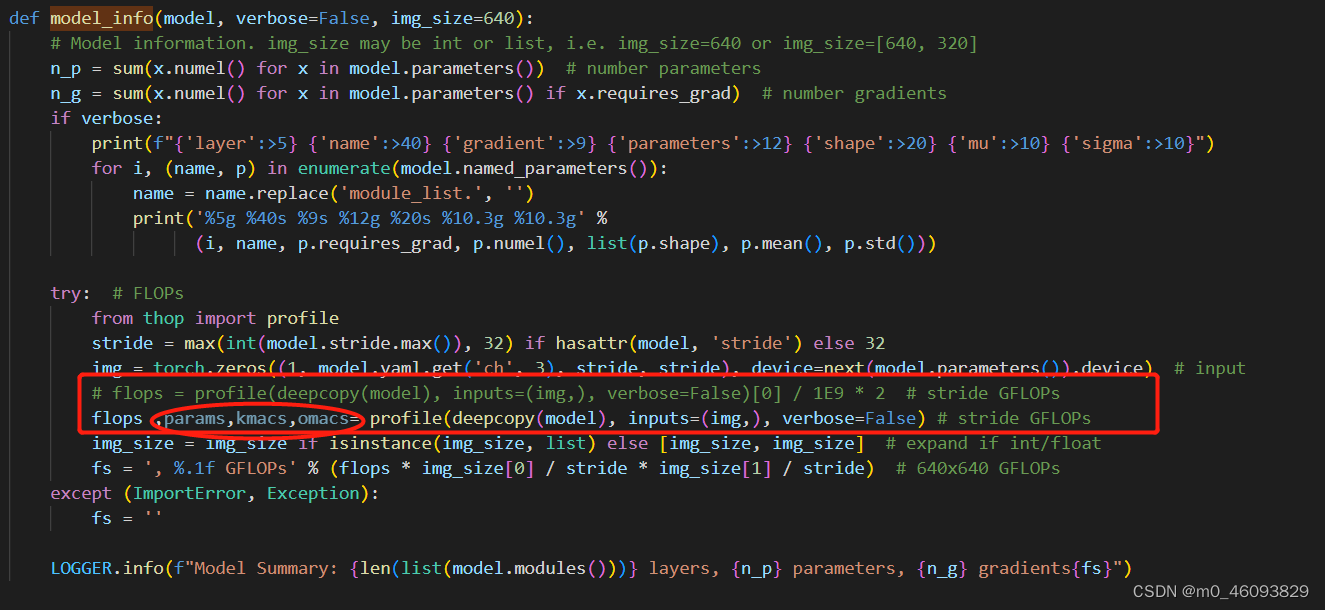
yolov5中计算flops的位置在torch_utiles.py文件,model_info函数中,故”
1. 修改 torch_utiles.py
2. 修改profile.py中的profile函数
profile 函数首先定义了一个 add_hooks,然后指令:model.apply(add_hooks) 先把这个hook挂起来,随后运行模型的时候才开始正式运行这个hook
2.1 hook 中的操作 --为每一层添加缓冲区并初始化
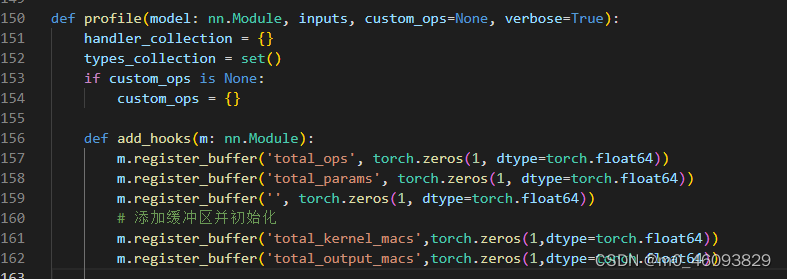
代码如下:
m.register_buffer('total_kernel_macs',torch.zeros(1,dtype=torch.float64))
m.register_buffer('total_output_macs',torch.zeros(1,dtype=torch.float64))
2.2 hook中的操作--根据不同类型选择合适的计算函数
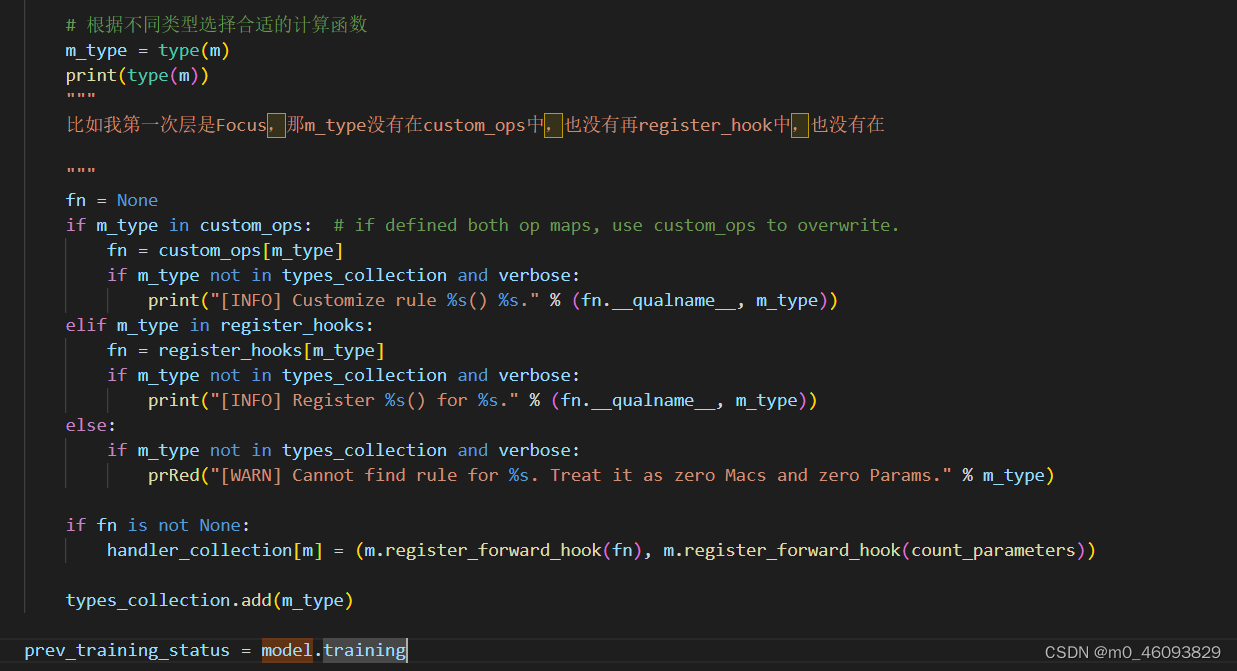
a. 根据分析可得出m_type属于register_hook 类型中,因此register_hooks,可得如下类型说明
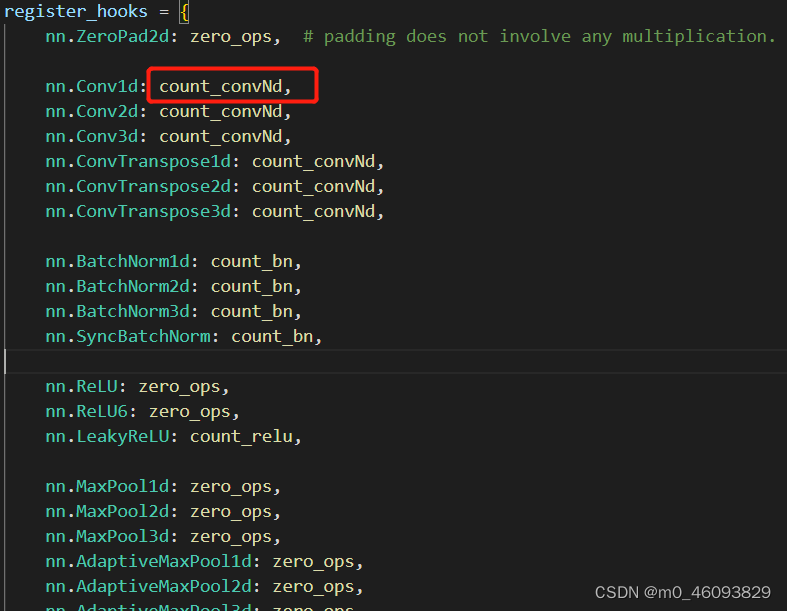
然后再进一步跳转到相应的类型
开始来看 count_convNd
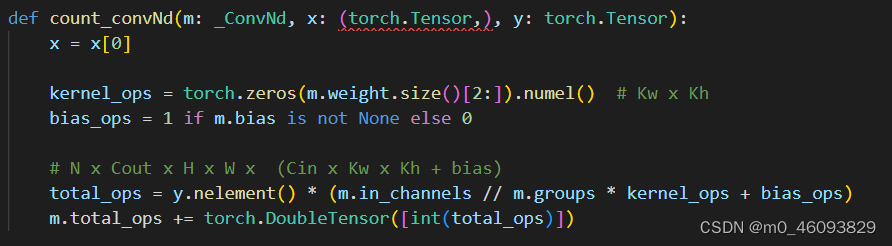
程序中本身已经计算了flops, 那么我们只需在后边添加计算访存量的程序即可,那根据访存量的公式我们知道,总访存量=卷积核的访存量加输出的访存量,那先来分析这些模块是都需要两种访存量都计算
conv需要计算kerneld 访存量,output的访存量
BatchNormalization 需要计算 output的访存量
激活函数需要计算 output的访存量
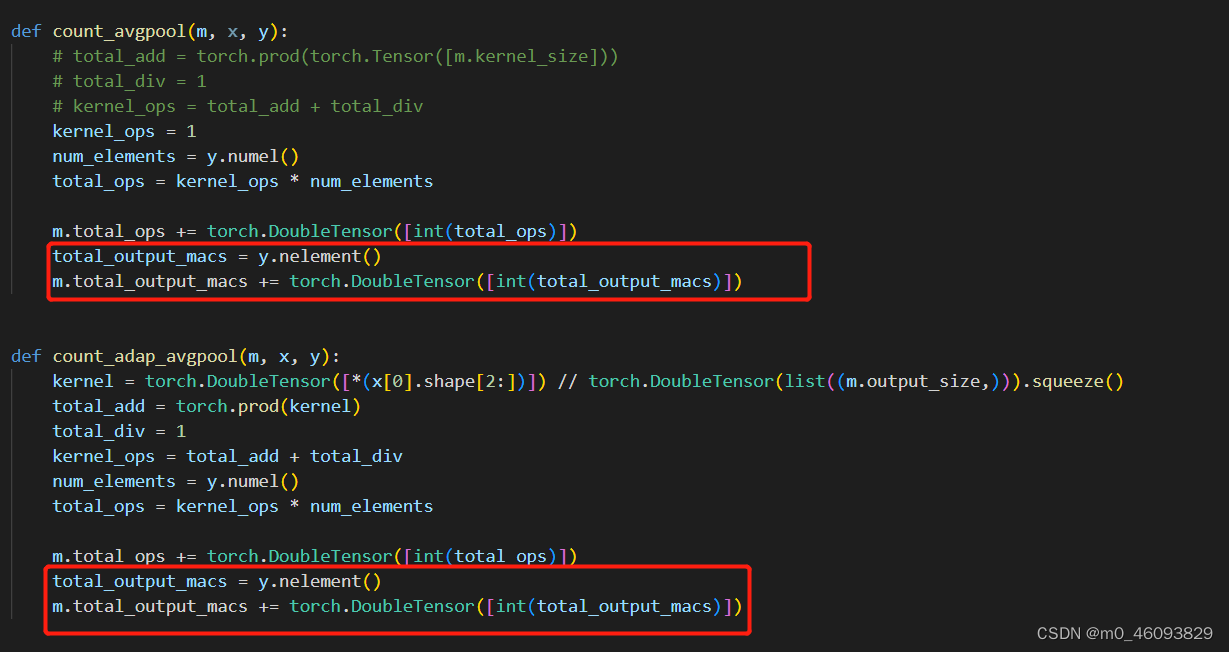
池化层需要计算 output的访存量
开始来看 count_convNd
程序中本身已经计算了flops, 那通过分析计算flops的过程我们可以知道:
y.nelement() :N x Cout x H x W
m.in_channels :Cin
kernel_ops : Kw x Kh
故添加如下程序计算 kerneld 访存量,output的访存量
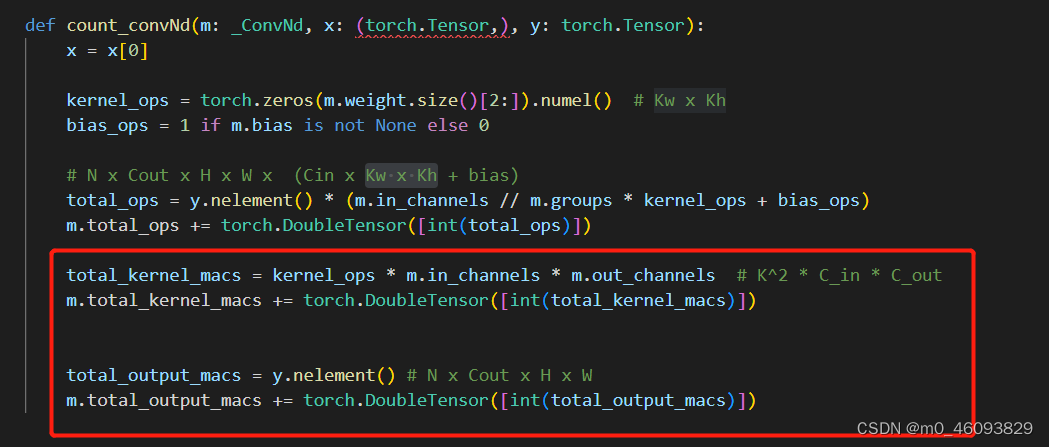
代码如下:
total_kernel_macs = kernel_ops * m.in_channels * m.out_channels # K^2 * C_in * C_out
m.total_kernel_macs += torch.DoubleTensor([int(total_kernel_macs)])
total_output_macs = y.nelement() # N x Cout x H x W
m.total_output_macs += torch.DoubleTensor([int(total_output_macs)])
BatchNormalization 需要计算 output的访存量,故添加代码如下: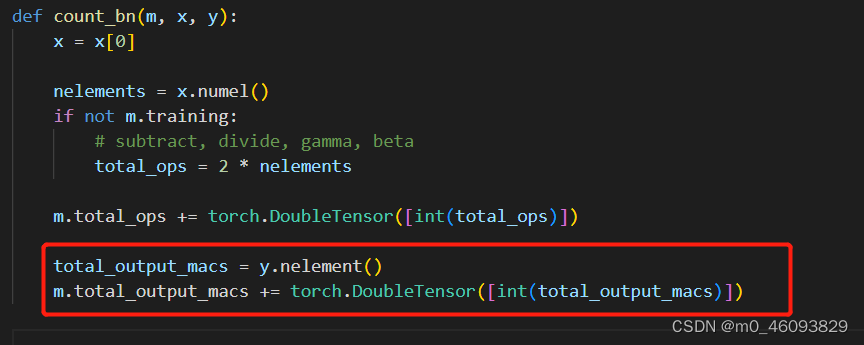
total_output_macs = y.nelement()
m.total_output_macs += torch.DoubleTensor([int(total_output_macs)])
激活函数需要计算 output的访存量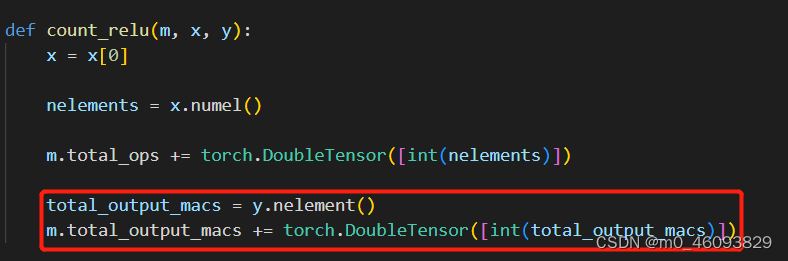
池化层需要计算 output的访存量
上采样需要计算output的访存量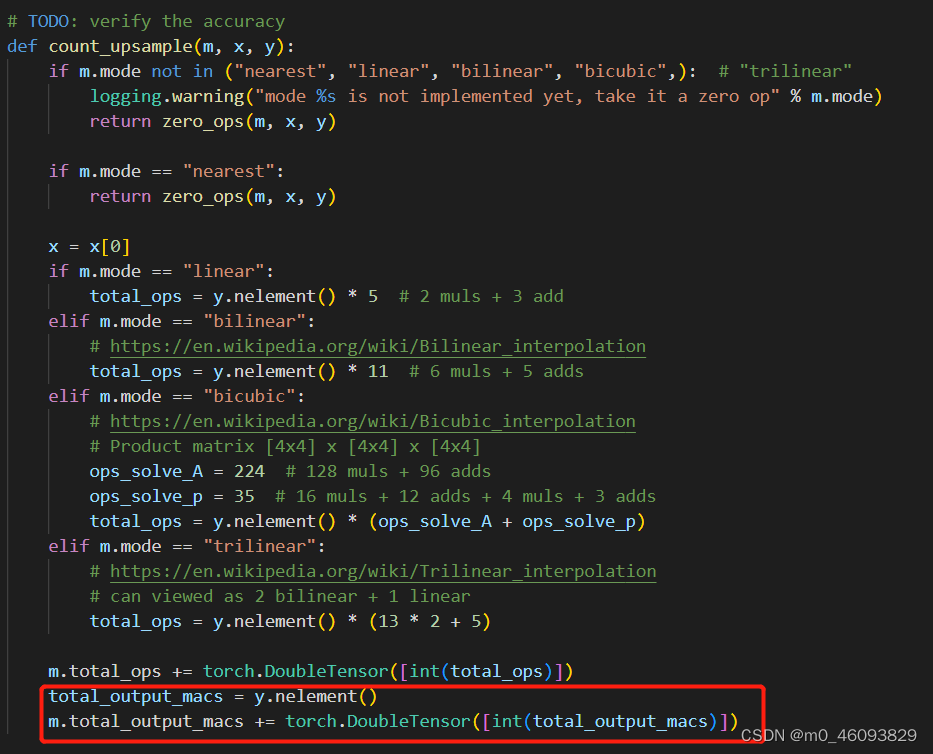
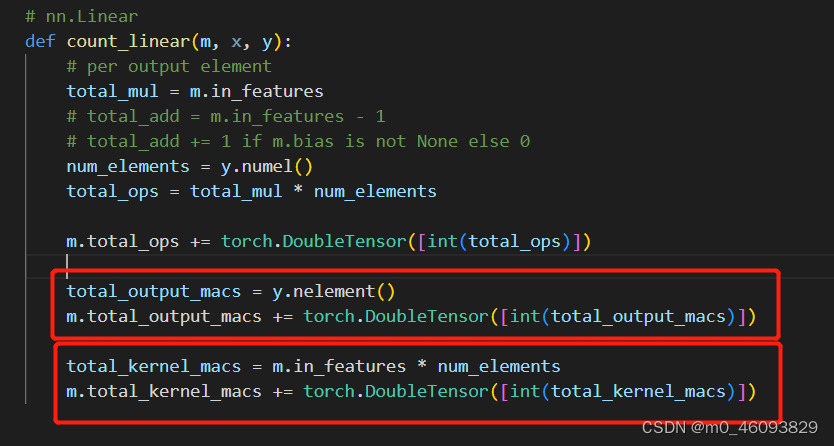
** 相应层的访存量和计算量都存到了自己的buffer中,然后程序继续向下运行**
如上,调用dfs_count()函数,把刚刚计算出来的参数和访存量叠加
2.3 计算整个模型的访存量和FLOPS
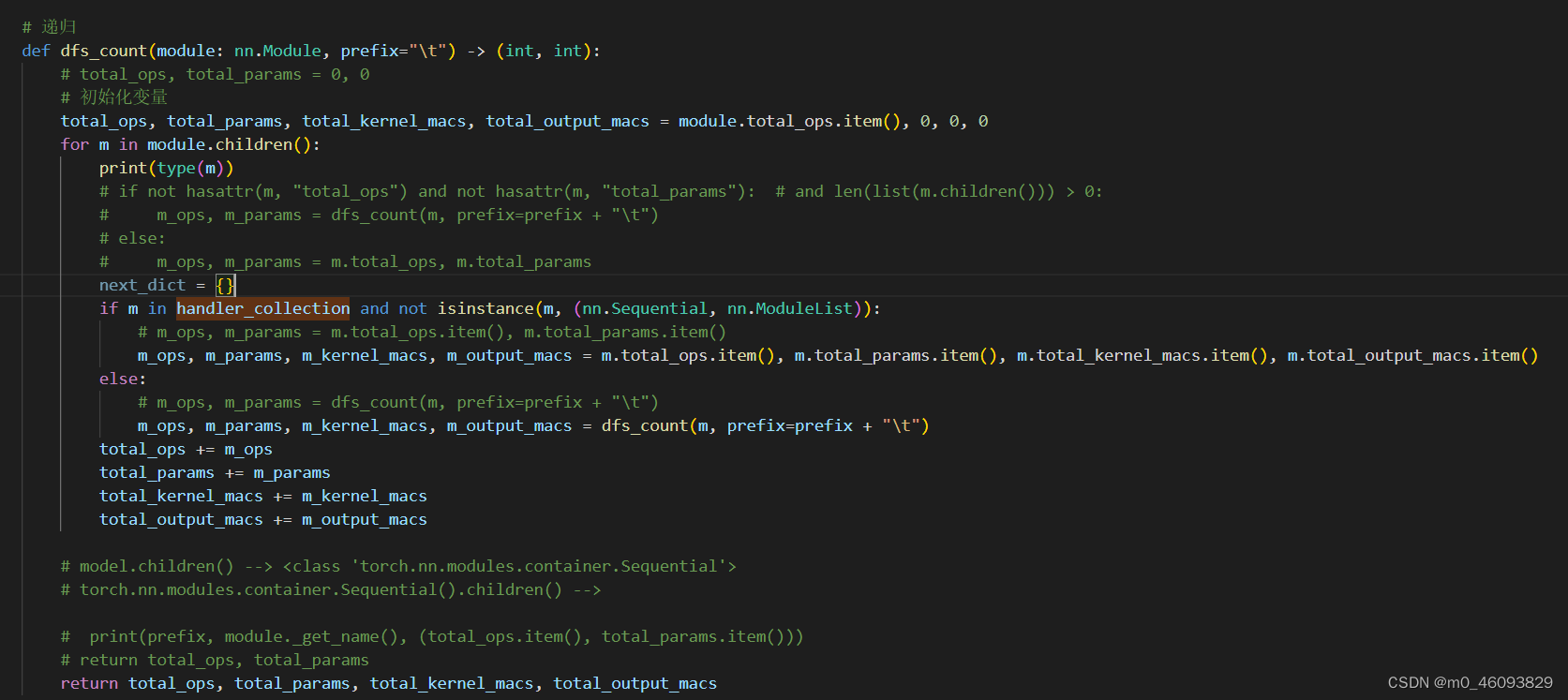
代码如下:
def dfs_count(module: nn.Module, prefix="\t") -> (int, int):
# total_ops, total_params = 0, 0
total_ops, total_params, total_kernel_macs, total_output_macs = module.total_ops.item(), 0, 0, 0
ret_dict = {}
for n, m in module.named_children():
# if not hasattr(m, "total_ops") and not hasattr(m, "total_params"): # and len(list(m.children())) > 0:
# m_ops, m_params = dfs_count(m, prefix=prefix + "\t")
# else:
# m_ops, m_params = m.total_ops, m.total_params
next_dict = {}
if m in handler_collection and not isinstance(m, (nn.Sequential, nn.ModuleList)):
# m_ops, m_params = m.total_ops.item(), m.total_params.item()
m_ops, m_params, m_kernel_macs, m_output_macs = m.total_ops.item(), m.total_params.item(), m.total_kernel_macs.item(), m.total_output_macs.item()
else:
# m_ops, m_params = dfs_count(m, prefix=prefix + "\t")
m_ops, m_params, m_kernel_macs, m_output_macs, next_dict = dfs_count(m, prefix=prefix + "\t")
ret_dict[n] = (m_ops, m_params, m_kernel_macs, m_output_macs, next_dict)
total_ops += m_ops
total_params += m_params
total_kernel_macs += m_kernel_macs
total_output_macs += m_output_macs
# print(prefix, module._get_name(), (total_ops.item(), total_params.item()))
# return total_ops, total_params
return total_ops, total_params, total_kernel_macs, total_output_macs, ret_dict
# total_ops, total_params = dfs_count(model)
total_ops, total_params, total_kernel_macs, total_output_macs, ret_dict = dfs_count(model)
2.4 删除缓冲区和计算函数hook
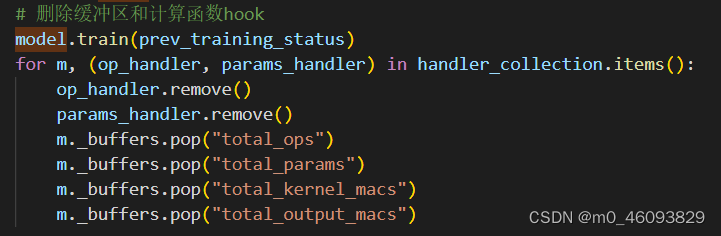
别忘了整个profile 函数返回total_ops, total_params, total_kernel_macs, total_output_macs
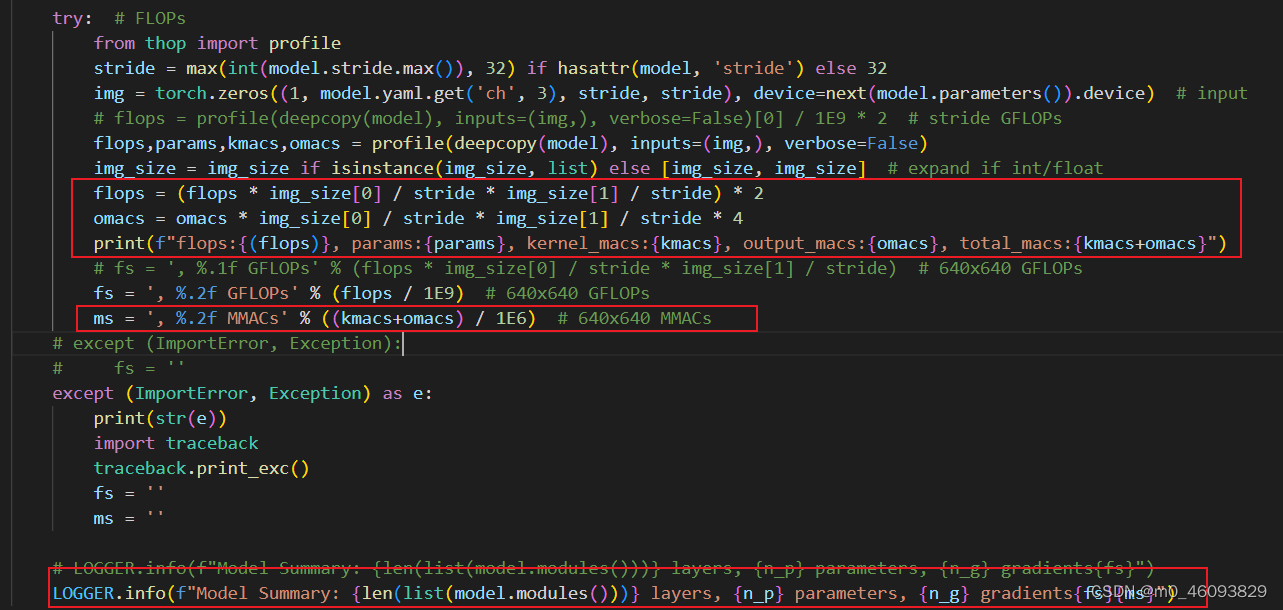
2.5 最后返回torch_utiles 处理一下flops和输出的访存量omacs
版权归原作者 m0_46093829 所有, 如有侵权,请联系我们删除。