
前言
10月17日,以“生成未来(PROMPT THE WORLD)”为主题的Baidu World 2023在北京首钢园举办。
李彦宏在百度世界2023上表示:“ 大模型带来的智能涌现,这是我们开发AI原生应用的基础。”。当天,李彦宏以《手把手教你做AI原生应用》为主题发表演讲,发布文心大模型4.0版本,并带来新搜索、新地图等十余款AI原生应用。
那么,什么是AI原生应用,文心大模型的新优化与新应用在哪,它在人工智能中的应用又有哪些?

AI原生应用
AI原生应用(AI Native)是指在设计和发展应用程序时,以人工智能(AI)技术为出发点,将AI作为核心驱动力,重新设计和构建应用。换句话说,AI原生应用是为了充分利用AI技术而设计和开发的,它们在代码层面和应用架构上就具备了与AI技术的深度融合。
AI原生应用的基础技术主要包括:深度学习和神经网络、自然语言处理和文本分析技术、计算机视觉和图像识别技术、强化学习和智能决策技术。
在接下来的内容中博主将结合文心大模型4.0详细介绍这些技术。

文心大模型4.0的特点
在李彦宏看来,AI原生应用的诞生,得益于大模型的理解、生成、逻辑和记忆四大核心能力,百度的AI原生应用也是基于文心一言来开发的,“这些能力是过去的时代所不具备的,因而才能打开无限的创新空间”。
基于文心大模型4.0,李彦宏依次演示了四大能力的特点与应用场景。
1.在理解能力上,他通过询问公积金异地贷款政策的案例,展示了文心一言对前后乱序、模糊意图、潜台词等复杂提示词的理解力,例如“在北京工作”等同于“在北京缴纳公积金”等等,“今天,你说的每一句话,它大概率都能听懂”。
2.在生成能力上,李彦宏展示了文心一言如何在短短几分钟内,根据一张素材图片,迅速生成了一组广告海报、五条广告文案以及一条营销视频。据介绍,基于这一系列能力,百度已经推出了AIGC营销创意平台擎舵,让“一个人就成为一支AI营销队伍”。

3.同时,他还通过解数学题、总结知识点等场景,展示了大模型的逻辑能力。
4.通过数千字的小说撰写和角色、情节设置,体现了大模型的记忆能力;以及数字人医生帮助患者解读药品说明书,来展现四大能力的综合应用。
文心大模型4.0在人工智能中的应用
在百度世界2023上,十余款AI原生应用重磅发布,包括Apollo智舱、地图、文库等。
百度新搜索、拥有创作能力的百度网盘和文档、精简优化后的百度地图和智能办公平台如流等等提高了百度的服务能力。

归根结底,AI大模型是基于人类需求而开发出来的,在人工智能领域,底层技术是我们不可忽略的。
自然语言处理
在我们发出询问到AI大模型应答的过程中,发生了什么 、涉及到了什么AI底层技术?
首先我们要介绍的是自然语言处理技术。
自然语言处理是人工智能领域的一个重要子领域,旨在使计算机能够理解和处理人类的自然语言。通俗来说,自然语言处理就是让计算机懂得人类语言,并与人类进行交互。
像我们日常使用的 Siri、小布、小爱同学,都是应用自然语言处理技术的新一代AI模型。只要你发出问答或命令,它们都能很好地理解并作出下一步应答。

如图为一种基于自然语言处理的问答流程:

博主给出学习人工智能相关知识中涉及到的部分自然语言处理代码,让大家有一个更深入的了解:
# 使用 Python 中的 nltk 库进行情感分析from nltk.sentiment import SentimentIntensityAnalyzer
text ="I love this movie!"
analyzer = SentimentIntensityAnalyzer()
sentiment_scores = analyzer.polarity_scores(text)print(sentiment_scores)
知识图谱
百度网盘在拥有AI大模型的加持后,不仅能精准定位到视频某一帧,还能在几秒钟内总结完长达1小时的视频内容,并从中提炼出金句和要点。
而在这个过程中,知识图谱是一个非常重要的概念。
什么是知识图谱呢?
知识图谱是一种用于表示和组织结构化知识的方式,它通过
将实体、属性和关系编码为图形结构
,以便机器可以理解和查询这些知识。
链接数据是构建知识图谱的一个方法,其核心思想是将各个分散的数据源连接起来,形成一个巨大的知识图谱网络:
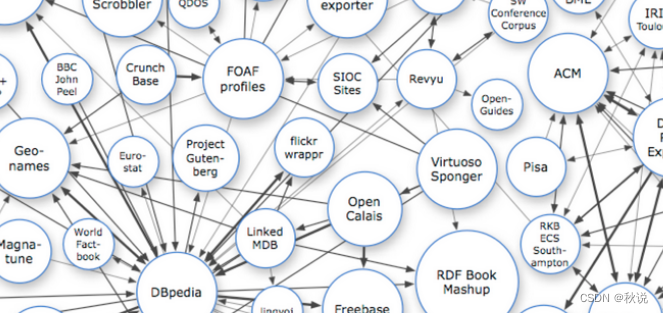
在一个知识图谱中,实体通常表示为节点,属性表示为节点上的标签,关系表示为节点之间的连接边。
博主给出部分涉及知识图谱的底层代码,让读者有一个更深入的了解:
import rdflib
# 创建一个空的知识图谱
graph = rdflib.Graph()# 定义命名空间
namespace = rdflib.Namespace("http://example.org/")# 添加实体和关系
graph.add((namespace.Person1, namespace.name, rdflib.Literal("John")))# 添加实体:Person1
graph.add((namespace.Person2, namespace.name, rdflib.Literal("Alice")))# 添加实体:Person2
graph.add((namespace.Person1, namespace.hasFriend, namespace.Person2))# 添加关系:Person1 hasFriend Person2# 查询关系
query ="""
SELECT ?person WHERE {
?person <http://example.org/hasFriend> <http://example.org/Person2>
}
"""
results = graph.query(query)for result in results:print(result)# 输出:Person1
深度学习
深度学习在图像处理方面发挥着关键作用,我们具体来讲一讲卷积神经网络的原理:
卷积神经网络主要分为三个层一个数:卷积层、池化层、激活函数、全连接层。
卷积层通过可学习的过滤器提取局部特征,池化层缩小特征图尺寸并保留重要信息
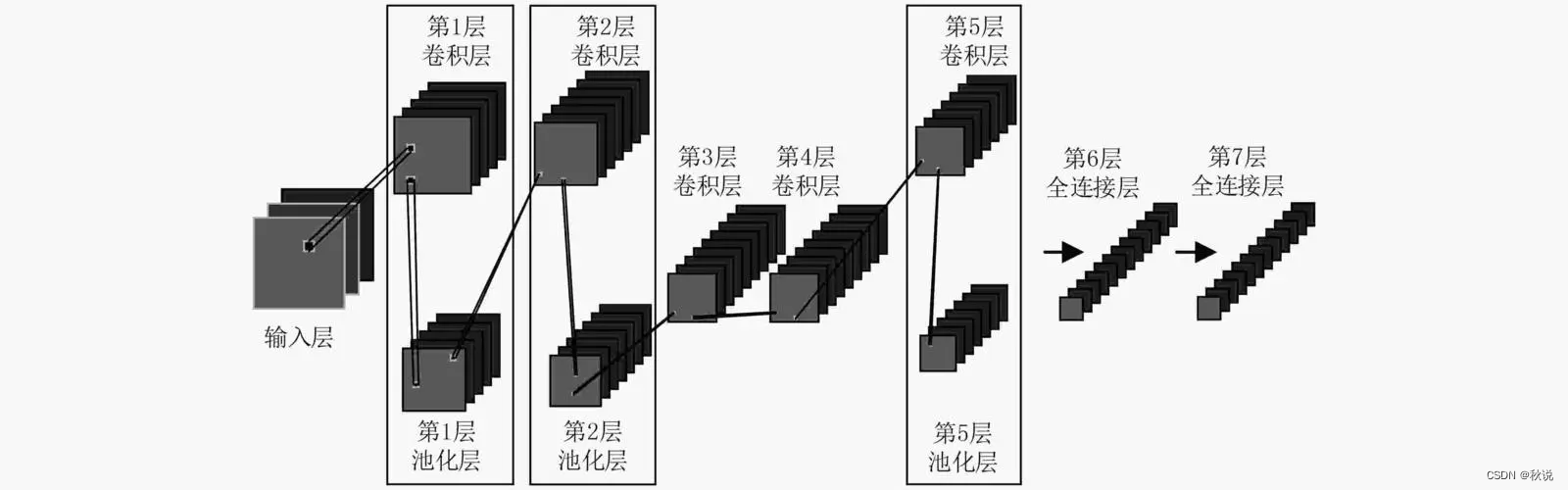
在卷积层和池化层之间,我们应用激活函数来引入非线性。它可以将卷积层输出的线性特征映射到非线性空间中,从而增强了网络的表达能力。
在全连接层中,特征图被展平成向量,并与权重矩阵相乘,得到最终的输出结果,其用于分类或回归等任务。
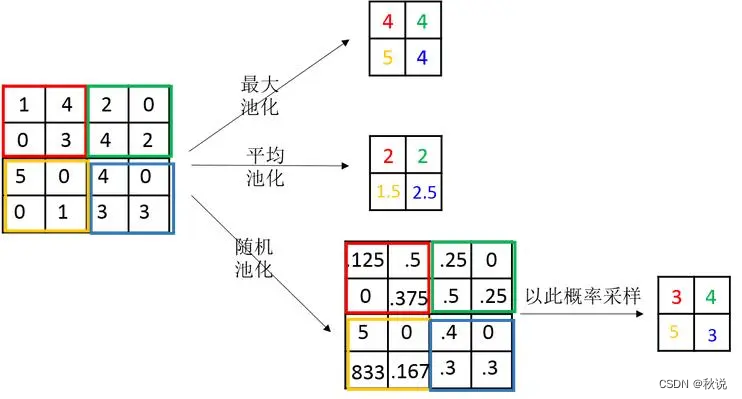
举个例子:
在百度网盘中,深度卷积神经网络可以用于视频内容的理解和分析。通过训练模型,网络可以学习从视频中提取关键帧,并对每个帧进行分类、标注或描述。 这样一来,用户可以方便地精准定位到视频中的某一帧,或者通过网络生成视频摘要、提炼出金句和要点等。
博主给出部分神经网络模型代码:
import tensorflow as tf
# 定义卷积神经网络模型
def cnn_model(input_shape, num_classes):
model = tf.keras.models.Sequential([
tf.keras.layers.Conv2D(32,(3,3), activation='relu', input_shape=input_shape),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Conv2D(64,(3,3), activation='relu'),
tf.keras.layers.MaxPooling2D((2,2)),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(64, activation='relu'),
tf.keras.layers.Dense(num_classes, activation='softmax')])return model
# 创建模型实例
input_shape =(224,224,3)# 输入图像的尺寸
num_classes =10# 分类任务的类别数量
model = cnn_model(input_shape, num_classes)# 编译模型
model.compile(optimizer='adam',
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=['accuracy'])# 加载数据并训练模型# 提取关键帧并分类、标注或描述# 使用模型生成视频摘要、提炼金句和要点等# ...
机器学习算法
“李彦宏强调,插件是一种特殊的AI原生应用,门槛最低,也最容易上手,能让开发者、创业者快速加入到生态中。他举例说,大模型接入权威法律数据的“智能法律助手”,能为用户提供法律咨询的相关建议,而简历助手插件则能帮用户一键生成简历模板。
拿生成简历模板为例:
简历助手插件使用命名实体识别算法来识别简历中的实体信息,如人名、公司名、学校名等。命名实体识别算法通过识别文本中特定的实体类型,帮助提取关键信息并构建简历模板。
简历助手插件还使用文本生成算法来根据用户提供的基本信息和关键词,自动生成简历的不同部分。文本生成算法可以基于预训练的语言模型,生成符合语法和语义规则的自然语言文本,从而生成个性化的简历模板。
总结

“中国有丰富的应用场景,中国用户又天然愿意拥抱新技术,有了先进的基础大模型,我们就能构建起一个繁荣的AI生态,共同创造新一轮经济增长。”李彦宏表示。
我们支持AI大模型的成长,同时我们也期待AI大模型及人工智能新技术为科技发展推波助澜。
版权归原作者 秋说 所有, 如有侵权,请联系我们删除。