
复现开源论文代码总结
随着深度学习的发展,深度学习已经逐步应用到很多领域。同时,越来越多的深度学习模型被提出,我们在了解一个新提出的深度学习模型是时候,只看论文可能会对模型有一个大致的了解,具体模型的效果怎样,往往还是需要自己运行一下原模型,才能有深入了解。那么快速复现开源论文的代码,可以对学习起到事半功倍的效果。
1. 找到开源论文的代码
很多开源论文都在论文中附带了代码的网址,比如论文《Compositionally restricted attention-based network for materials property predictions》在论文的数据获取部分加入了代码的github网址,如下图所示。
除此之外,也可以通过paperswithcode网站,输入文章标题,就可以看到论文的代码,如下图所示。对于一些经典的模型,可以直接在github中输入模型名字搜索。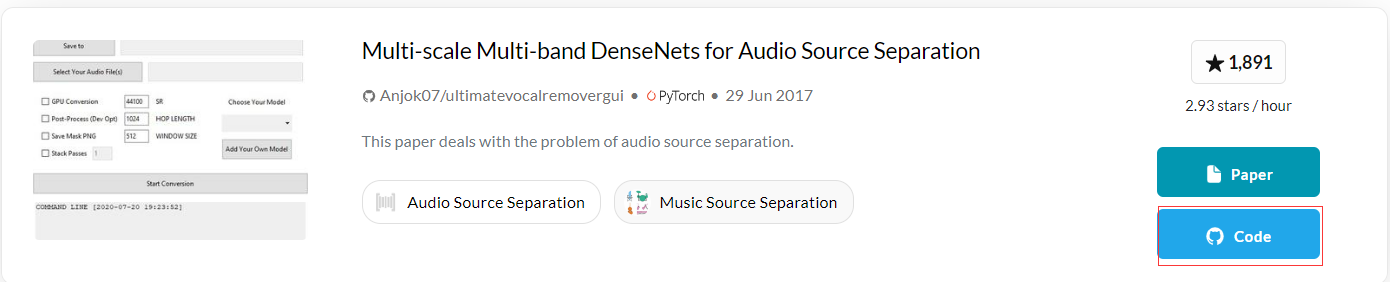
2. 阅读README.md说明文档
为了方便读者复现论文代码,作者一般会写一个README.md说明文档,内容可能包括代码依赖环境、代码内容介绍、代码引证的论文、如何运行代码等内容,不同的项目可以包括不同的内容。复现一个项目,读懂README.md文档可以帮助我们对代码有个大概的了解。下图是CrabNet模型的代码,项目中三个说明文档是对项目中三个不同部分说明。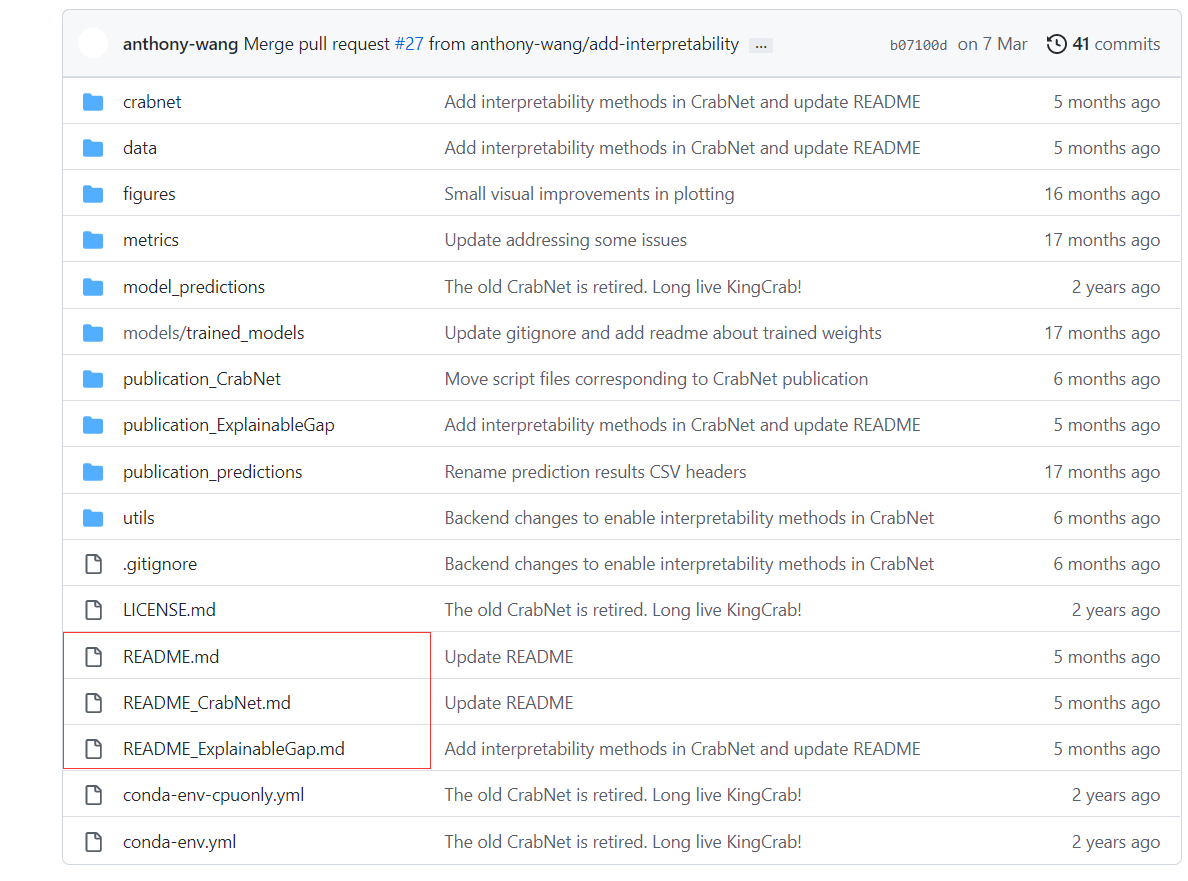
3. 代码下载与解压
在github中找到对应的项目工程,下载对应项目到本地并进行解压。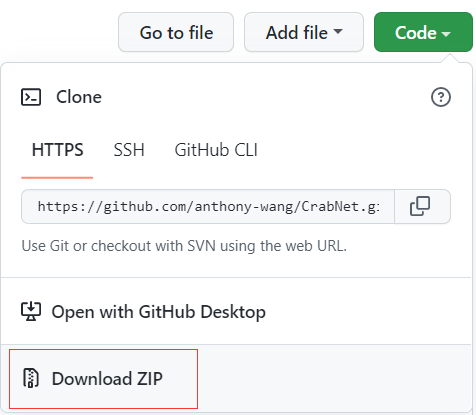
4. 配置环境、下载数据集与预训练权重
要想成功复现一个python项目代码,首先需要配置python环境,这里推荐两种配置环境的方法。
- 对于某些代码复杂,需要安装的python依赖包较多,并且代码中提供了conda环境配置文件的项目,可以通过.yml配置文件创建一个该项目的虚拟环境,运行代码时需要激活该虚拟环境。通过配置文件创建虚拟环境的命令为
conda env create --file conda-env.yml - 对于一些python依赖包和自己已有环境中第三方包重合度较高,且没有提供conda环境配置文件的项目,可以在自己已有的环境中手动
pip install安装项目依赖包,运行项目需要激活安装依赖包对应的虚拟环境。对应一些pip安装不上的包,可以通过下载包对应的whl文件,然后通过pip install + whl文件名进行安装。
除此之外,一些项目需要自己下载数据集和预训练权重,可以通过作者提供的README.md文档查看如何下载对应文件,并把文件放在对应位置。如果README.md文档没有具体说明下载文件放置位置,可以通过代码对该文件调用时的路径来确定。
5. 运行代码,排错
经历了以上四步,接下来就可以运行代码。运行代码前要注意通过
conda activate environment_name
激活自己配置的环境。对于不同的平台,不同的python编辑器运行方式略有不同。
到这里如果运行没有成功,可以根据报错信息提示,解决对应的问题,下面列举几个出现问题常见的原因,遇到新的问题也会更新到下面。
- 自己电脑上的依赖项、数据集、预训练权重等相关文件没有放到对应路径、安装不完整或者版本不匹配;
- 可能是因为自己的电脑上的硬件不支持,例如报错显存不够。这时可以通过调整代码的运行参数来解决,通常可以设置batch size为1来解决;
参考
- 如何在自己的电脑上复现开源论文里的代码
- CrabNet项目代码
版权归原作者 喝过期的拉菲 所有, 如有侵权,请联系我们删除。