

在 RAG (检索增强生成)领域,选对向量模型至关重要,它基本就决定了 RAG 系统的“天花板”,也因此,向量模型的选择总是业界的热门讨论话题。
最近,Jina AI 在 Hugging Face 上推出的 Jina-ColBERT 模型引起了 AI 圈子里不小的轰动,尤其是在 Twitter/X 上,大家都在讨论它能处理高达 8192 Token 的强大能力,为搜索带来了更多的可能性。
与 ColBERTv2 相比,Jina-ColBERT 在各项测试中都展现了顶尖的性能,特别在处理长文档数据集时,其表现更是显著优于 ColBERTv2。
模型链接: https://huggingface.co/jinaai/jina-colbert-v1-en。
与市场上大多数向量模型相比,Jina-ColBERT 有个显著的不同点——它采用的是多向量搜索技术。单向量模型会把整个文档或段落编码成一个单一向量,然后基于余弦相似度进行匹配。而 多向量模型,如 Jina-ColBERT,则是将文本中的每个词编码成独立向量,通过迟交互计算相似度。
很多人都听过 BERT 模型,但 ColBERT 是什么呢?
先说说背景。ColBERT 基于 BERT 模型开发,师出名门斯坦福。那为啥最近又翻红了呢?原来,ColBERT 升级到 v2 版本,不仅补齐了 v1 版本在存储和扩展性上的短板,还显著提升了性能。
再来说说 ColBERT 的家谱。之前大家没怎么注意到它,主要是因为从传统搜索(文本匹配)过渡到向量检索的过程中,大家都忙着折腾单向量模型,把这位和 BERT 同门的 ColBERT 给忽略了。
单向量模型是将查询和文档简化为单一向量的表示,ColBERT 则 为每个 token 生成一个向量,并通过 MaxSim(Maximum Similarity, 最大相似度)计算得分,即它对于每个查询词,从文档中找到与之最相似的词的向量,并将这些最大相似度值相加作为最终的相关性分数。
通过 采用 token 级别的细粒度交互,即首先将查询和文档在词粒度上逐项编码,再在查询阶段进行迟交互。 也就是说,文档侧的计算可以完全离线进行,这一点与单向量模型的做法一致,但在处理方法上更为精细。这就使得它的 可解释性更好,在 token-level 匹配之后,我们能够解释查询中哪个词与文档中的哪个词最匹配。
这种多向量的召回方式带来两大好处:一是逐 token 编码提供了更细粒度的表征,在 in-domain (领域内)具有很高的 MRR@10(头部排序能力)和 Recall@1k(腰尾部召回能力)。并且提供了更好的可解释性。二是提供 out-of-domain (未知领域) 更强的泛化能力,特别是在处理长尾查询或文档时,由于词粒度的惊喜表征,使得模型对于未见过的领域有更好的性能表现。
Colbert 迟交互机制
与传统的 query-doc 全交互型 BERT 及目前流行的 Embeddings 模型相比,ColBERT 提出的 Late Interaction (迟交互)机制 有着显著的优势。
具体来说,单向量模型是吃进一个句子,吐出一个向量,然后再基于这些向量做相似度比较。而同样是分别编码查询和文档,ColBERT 拿模型生成的 Token Embedding 来做相似度计算,在后续阶段计算查询和文档 Token Embedding 之间的交互。这种方法既考虑了匹配效率,也充分利用了上下文信息,使得 ColBERT 既能作为一个强大的召回模型,也可以用做召回之后的重排工具。
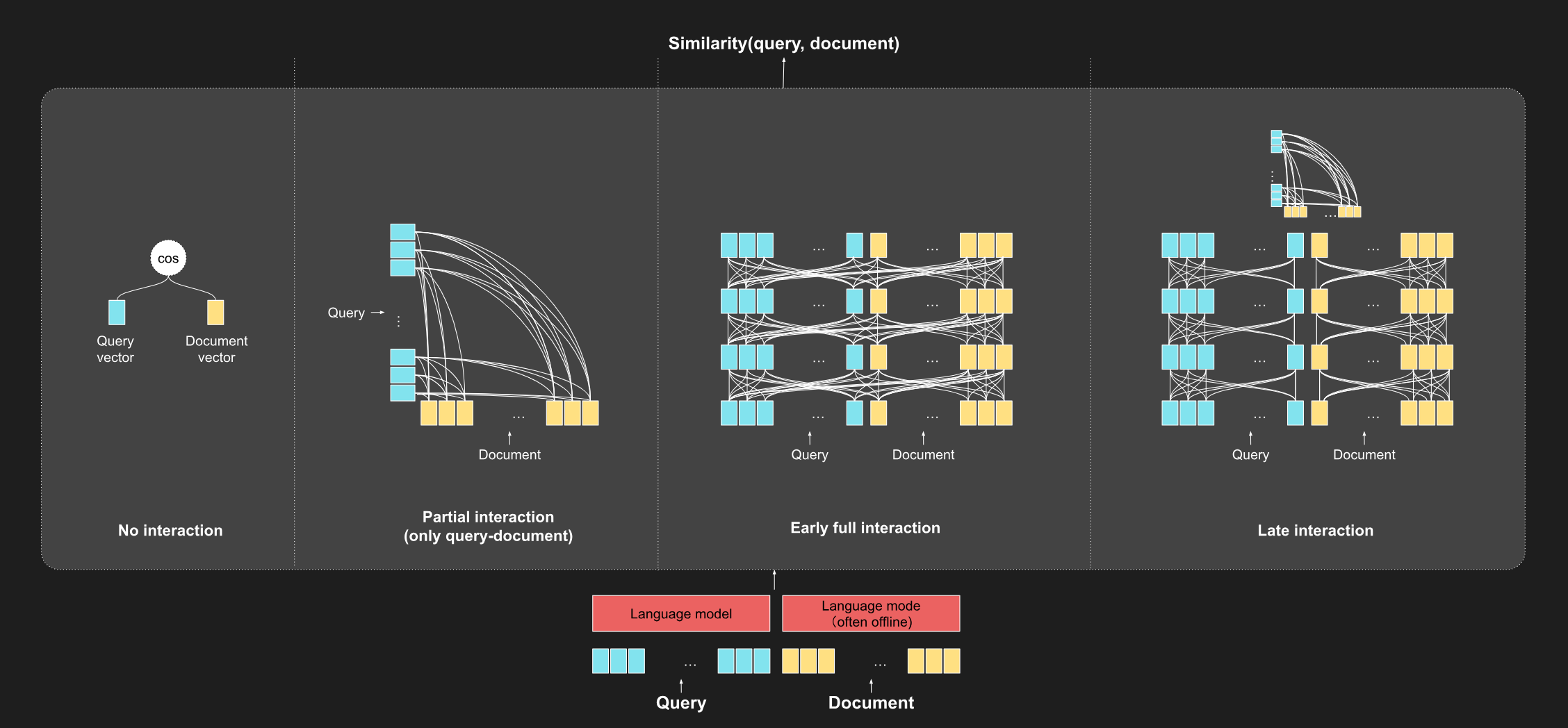
Interaction schemes
Jina-ColBERT 的升级亮点
Jina-ColBERT 是 Jina AI 对原有 ColBERT 模型的一番升级打磨。核心改进是采用了 jina-bert-v2-base-en 作为基础模型,从而支持一口气处理长达 8192 token 的文本。
这一改进意味着,无论是对付那些短小精悍的文本,还是那些长篇大论、需要深度理解的搜索任务,Jina-ColBERT 都能轻松应对。甚至在很多情况下,尤其长文本场景下,都能比 ColBERT v2 模型做得更好。
我们在 BEIR 数据集上,对比测试了 Jina-ColBERT,和原版 ColBERTv2,以及单向量模型 Jina-Embeddings-v2-base-en 模型的能力。
DatasetColBERTv2jina-colbert-v1-enjina-embeddings-v2-base-enArguana46.549.444.0Climate-Fever18.119.623.5DBPedia45.241.335.1FEVER78.879.572.3FiQA35.436.841.6HotpotQA67.565.961.4NFCorpus33.733.832.5NQ56.154.960.4Quora85.582.388.2SCIDOCS15.416.919.9SciFact68.970.166.7TREC-COVID72.675.065.9Webis-touch202026.027.026.2Average51.752.651.6
从这个表里,我们能看到 Jina-ColBERT 的亮眼表现,各项测试里,它都能和 ColBERTv2 一较高下。
值得一提的是,Jina-ColBERT 只用了 MSMARCO 数据集来训练,而 Jina-Embeddings-v2-base-en 使用了更广泛的训练数据,后者在某些特定任务上表现得更好。
我们还特别在专为长文本设计的新 LoCo Benchmark 上进行了测评,可以看到 Jina-ColBERT 在处理那些超出 ColBERTv2 常规上下文长度的场景时,表现更是出色。
DatasetColBERTv2jina-colbert-v1-enjina-embeddings-v2-base-enLoCo74.383.785.4
总的来说,Jina-ColBERT 在各项基准测试中都表现出和 ColBERTv2 相媲美的性能,当在文本的上下文更长时,它的表现就更胜一筹了。
如果你想在 RAG(检索增强生成)领域挑选出合适向量模型,这里有几条建议,帮你决定哪个最合适。
- 如果你偏好简单的单向量存储与检索,并且能够接受一定程度的精确度牺牲,那么 Jina-Embeddings-v2 是个不错的选择。
- 对于那些追求细颗粒度检索、关注模型在 out-of-domain(未知领域)的表现、以及需要模型可解释性的用户来说,Jina-ColBERT 会是更优选。
- 你也可以设计一个分阶段的检索流程:首先用 Jina-Embeddings-v2 快速召回候选文档,接着用 Jina-ColBERT 进行更细颗粒度的重新排序。
- 请注意,目前 Jina-ColBERT 仅支持英文内容的处理。
轻松上手:Jina-ColBERT 入门指南
上手 Jina-ColBERT 很简单,因为它是基于 ColBERT 模型优化的,你可以轻松地在现有支持 ColBERT 的平台上使用,比如 Vespa、RAGatouille、fastRAG 和 LangChain 等,只需将原模型名称换成 jina-colbert-v1-en。此外,我们还提供了一个专门的 Colab Notebook, 供大家快速上手。
Notebook: https://colab.research.google.com/drive/1-5WGEYPSBNBg-Z0bGFysyvckFuM8imrg
想要快速应用到项目里的话,推荐使用 RAGatouille,它做了很好的封装,可以更轻松用 ColBERT 构建 RAG Pipeline。
更多内容请访问 https://huggingface.co/jinaai/jina-colbert-v1-en。
展望未来:Jina-ColBERT 的新动向
我们正积极评估 Jina-ColBERT 作为 Reranker 的效果,并计划添加更多使用示例。同时,我们也将努力在更多数据集上进行微调,以进一步提升 Jina-ColBERT 的性能,并优化其存储性能。

版权归原作者 Jina AI 所有, 如有侵权,请联系我们删除。