
大数据技术介绍
大数据技术的介绍:
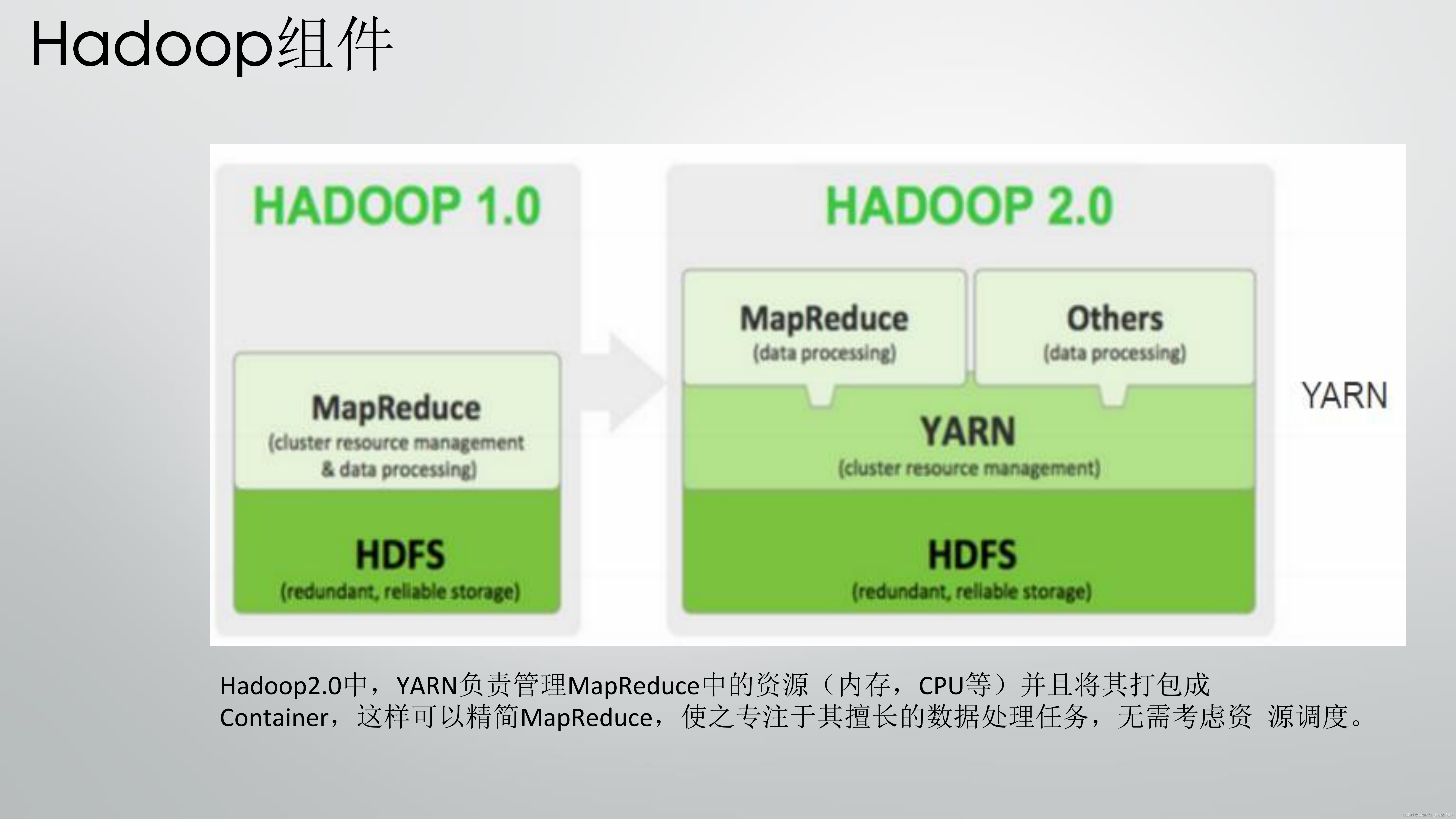
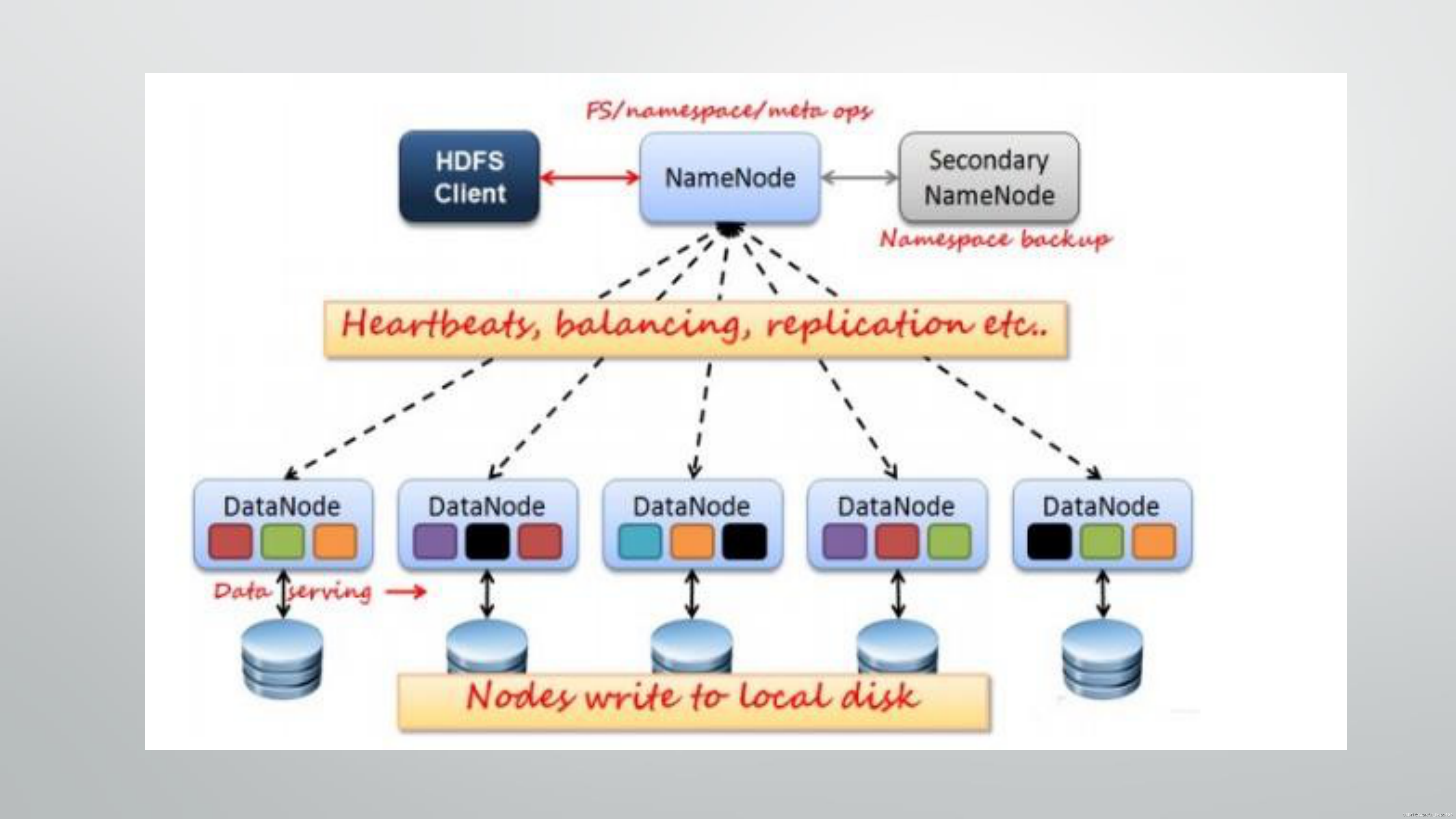
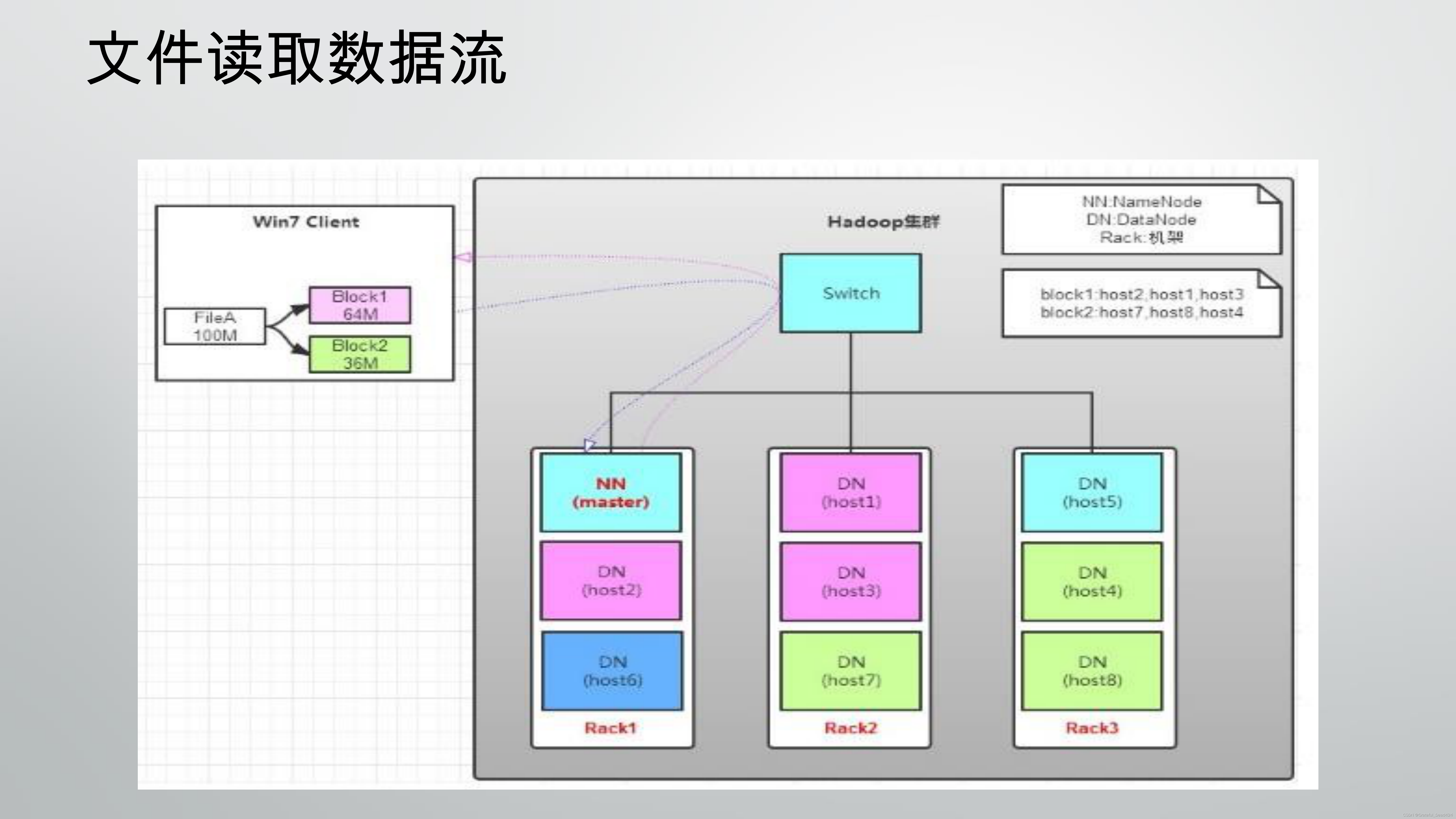
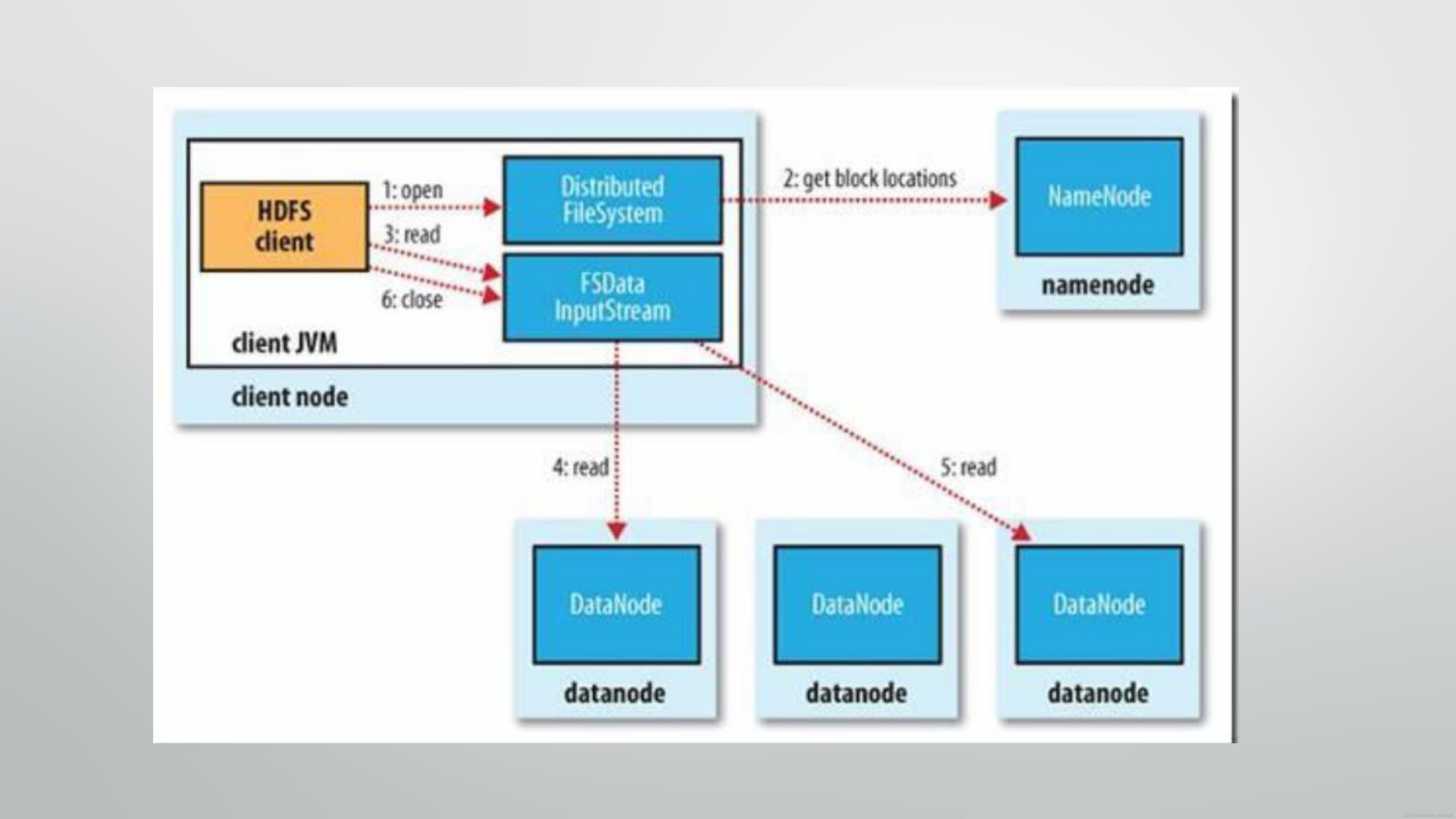
1、存储,我们需要了解在大数据的架构下,数据大致是怎么进行存储的,传统的文件系统是单机的,不能横跨不同的机器。HDFS(Hadoop Distributed FileSystem)的设计本质上是为了大量的数据能横跨成百上千台机器,但是用户在实际的应用中,看到的是一个文件系统而不是多个文件系统。比如要获取/hdfs/tmp/file1的数据,看起来和单机无异,引用的是一个文件路径,但是实际的数据存放在很多不同的机器上。作为用户,不需要知道数据具体是怎么存储在分布式系统中的,就好比在单机上我们不关心文件分散在什么磁道什么扇区一样。HDFS会自动为你管理这些数据;
2、数据处理,解决了存储的问题之后,我们就要开始考虑如何处理数据了,虽然HDFS可以整体管理不同机器上的数据,但是这些数据太大了。一台机器承载着也是巨量的数据,使用一台机器跑也许需要好几天甚至好几周。那么,一个非常自然的想法,既然数据可以在多台机器上存储,难道不能使用多台机器来处理吗?这就好比我们常使用的多核计算,类比来看,在大数据中,一台机器对应的就是一个核,因此同样,和多核计算一样,我们面临着如何分配不同机器工作的问题,如果一台机器挂了如何重新启动相应的任务,机器之间如何互相通信交换数据以完成复杂的计算等等,这就是MapReduce架构、spark的功能。
3、Mapreduce mapreduce不仅仅提供了技术上的架构,更重要的是其思想,对于巨大型任务的处理思路,其实很简单,先map,然后reduce,它的思想和多核计算是非常相似的:我们来概览一下mapreduce的结构,然后把mapreduce框架下整个任务处理的流程过一遍就能体会mapreduce的思想了:首先会有一个master节点,作为用户在大数据框架中的“计算机代理”负责整个任务的调度(这样我们就不用人为地去给不同的worker(机器)分配工作了,这是mapreduce框架非常方便的地方),然后数据的input,既然我们要把计算拆分到多台机器上,(这里我们以简单经典的词频统计为例,假设我们要统计两篇长篇小说的词频),map要先把这两篇长篇小说进行拆分,假设我们是按照章节拆分的,并且每个章节的大小恰好相同(为了便于理解这里的假设都是非常理想的),将两篇小说分别划分为3个章节和2个章节,一共5个章节,然后呢,master就会分配一些worker去领任务,比如派了5个worker分别对5个章节进行词频统计,统计完之后得到5个结果保存缓存在硬盘上,这就是一个完整的map(映射,其实本质就是功能性函数的运行,把原始数据通过一些计算转化为另一些数据)过程,简单来说就是把一个任务分配给不同的机器执行,接着,我们发现,我们的最终目标是统计两个长篇小说,此时只是得到了每个章节的词频统计结果,那么,这个时候我们就需要reduce(归约,简单来说就是对所有worker的工作进行汇总)来分配机器,让workers去把刚才5个workers的计算结果进行汇总,比如上图,分配了两个workers,一个worker汇总3个map-workers的工作结果,一个worker汇总剩下两个workers的工作结果,最终将汇总计算的结果保存到本地的两个文件上;
上述的过程听起来简单,但是实现上是非常繁琐的,很多时候,例如对于词频的计算,我们要自己去手动编写一个词频计算的map function,这对于数据处理与分析来说,实在太麻烦了,这就好比你想要去计算某一个特征的取值情况,通过pandas的value_counts()功能就可以轻松实现,但是现在你要自己写个func去做统计,我们希望有个更高层更抽象的语言层来描述算法和数据处理流程,于是,就诞生了Hive和pig。Pig是接近脚本方式去描述MapReduce(没用过),Hive则用的是SQL(hive sql,对于经常写sql同学来说非常简单容易上手)。它们把脚本和SQL语言翻译成MapReduce程序,丟给计算引擎去计算,这样我们就从繁琐的MapReduce程序中解脱出来。
Hive逐渐成长成了大数据仓库的核心组件(因为sql本身没什么技术门槛,一般的非技术人员也可以)。甚至很多公司的流水线作业集完全是用SQL描述,因为易写易改,一看就懂,容易维护
但是hive也有一个个问题,Hive底层执行使用的是MapReduce引擎,仍然是一个批处理过程,难以满足查询的交互性,比如我们写一个数据分析报告,我们想要去统计譬如每个用户分别浏览了多少商品或者每个商品被多少用户浏览过,当数据量非常大的时候,hive的查询效率是偏低的,子是又诞生了impala等分布式交互查询数据库,其底层做厂非常多的性能优化大大提升了交互式查询,数据分析的效率;
再后来,spark的横空出世支撑了hive on spark和sparksql (也就是我们熱悉的spark dataframe的父集),尤其是spark dataframe,不仅对于sql使用者来说友好,对于pandas的使用者也是较为友好的:
这个时候,一个完整的大数据处理分析的框架就己经跃然纸上丁:
1、底层的mapreduce架构(hadoop)或spark;
2、中层的hive或pig或者在hdfs上跑impala等;
3、上层的hive on spark或是直接使用sparksal
最后,作为小白用户,我们直接可以通过例如sparksql来进行海量数据的快速分析与数据分析报告甚至是基本的特征工程等,这个时候,我们实际上已经较好的解决了没有实施需求的离线问题,后续的模型训练我们可以通过分布式的xgb、lgb、tf等框架或者是spark ml等进行模型的训练
那么,如果是有实时需求的业务场景呢?比如我们想要尽量让申请信货的用户能够实时得到审批的结果,该怎么办?
于是,流(streaning)计算就问世了,storm是最流行的流计算平台,流计算的思路是,如果要达到更实时的更新,我们可以直接在数据流进来的时候就进行相应处理,这和online learning的思想是比较类似的,比如还是词频统计的例子,我的数据流是一个一个的词,我就让他们一边流过我就一边开始统计了
除此之外,针对于不同的场景,有不同的成熟开源的分布式系统,例如基于hadoop的mahout和基于spark的spark ml, Mahout是hadoop的一个机器学习库,主要的编程模型是MapReduce; Spark ML则是基于Spark的机器学习,Spark自身拥有MLib作为机器学习库,不过现在Mahout已经停止接受新的MapReduce算法了,向Spark迁移。
MLlib基于RDD,天生就可以与Spark SQL、 Graphx、spark Streaming无缝集成,非常的方便;
最后是关于这么多大数据组件的集中管理,这里贴出网上的一个很有思的例子:有了这么多乱七八糟的工具,都在同一个集群上运转,大家需要互相尊重有序工作。所以另外一个重要组件是,调度系统。现在最流行的是Yarn。你可以把他看作中央管理,好比你妈在厨房监工,哎,你妹妹切菜切完了,你可以把刀拿去杀鸡了。只要大家都服从你妈分配,那大家都能愉快滴烧菜。你可以认为,大数据生态圈就是个厨房工具生态圈。为了做不同的菜,中国菜,日本菜,法国菜,你需要不同的工具。而且客人的需求正在复杂化,你的厨具不断被发明,也没有一个万用的厨具可以处理所有情况,因止他会变得越来越复杂。

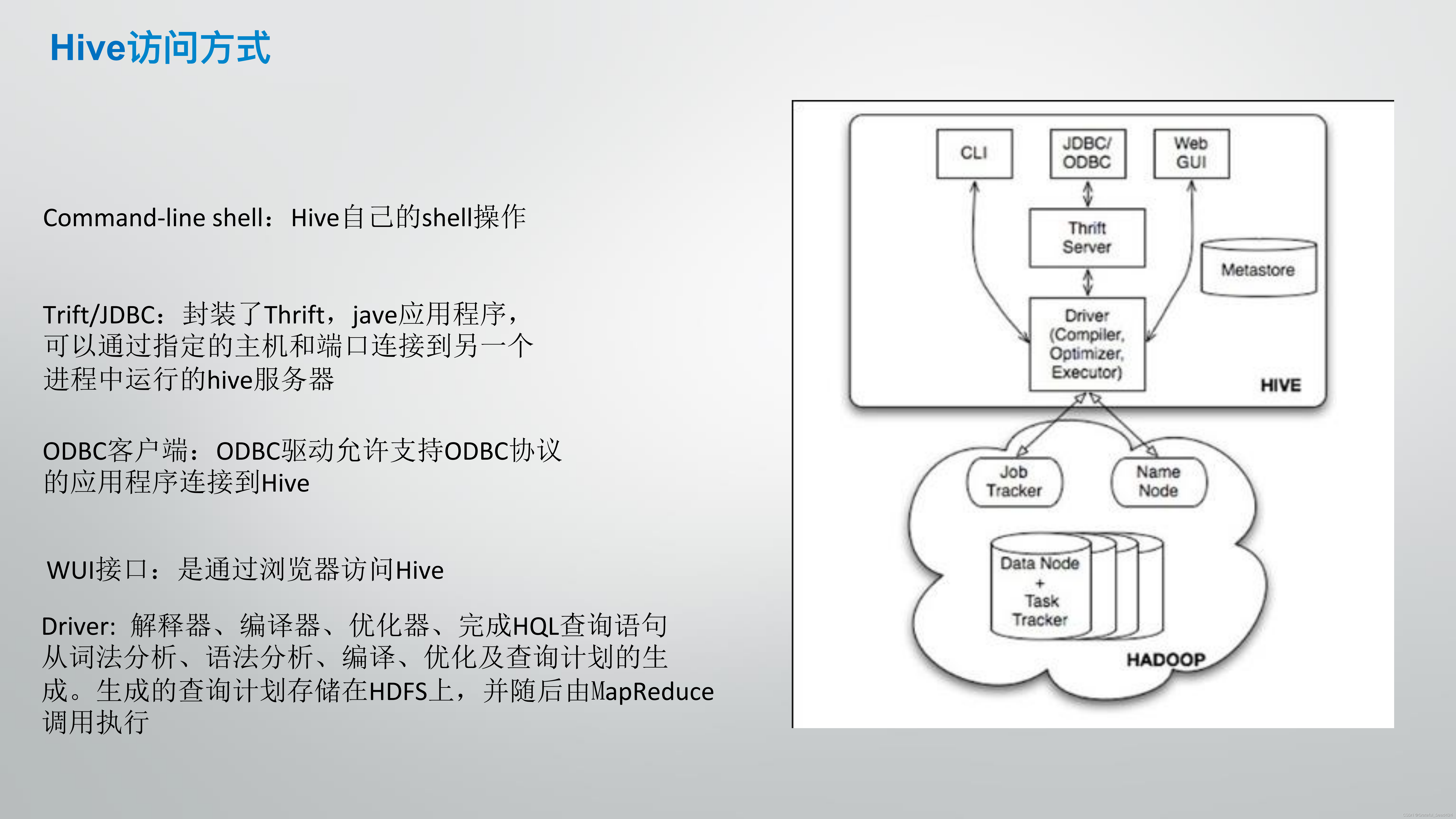
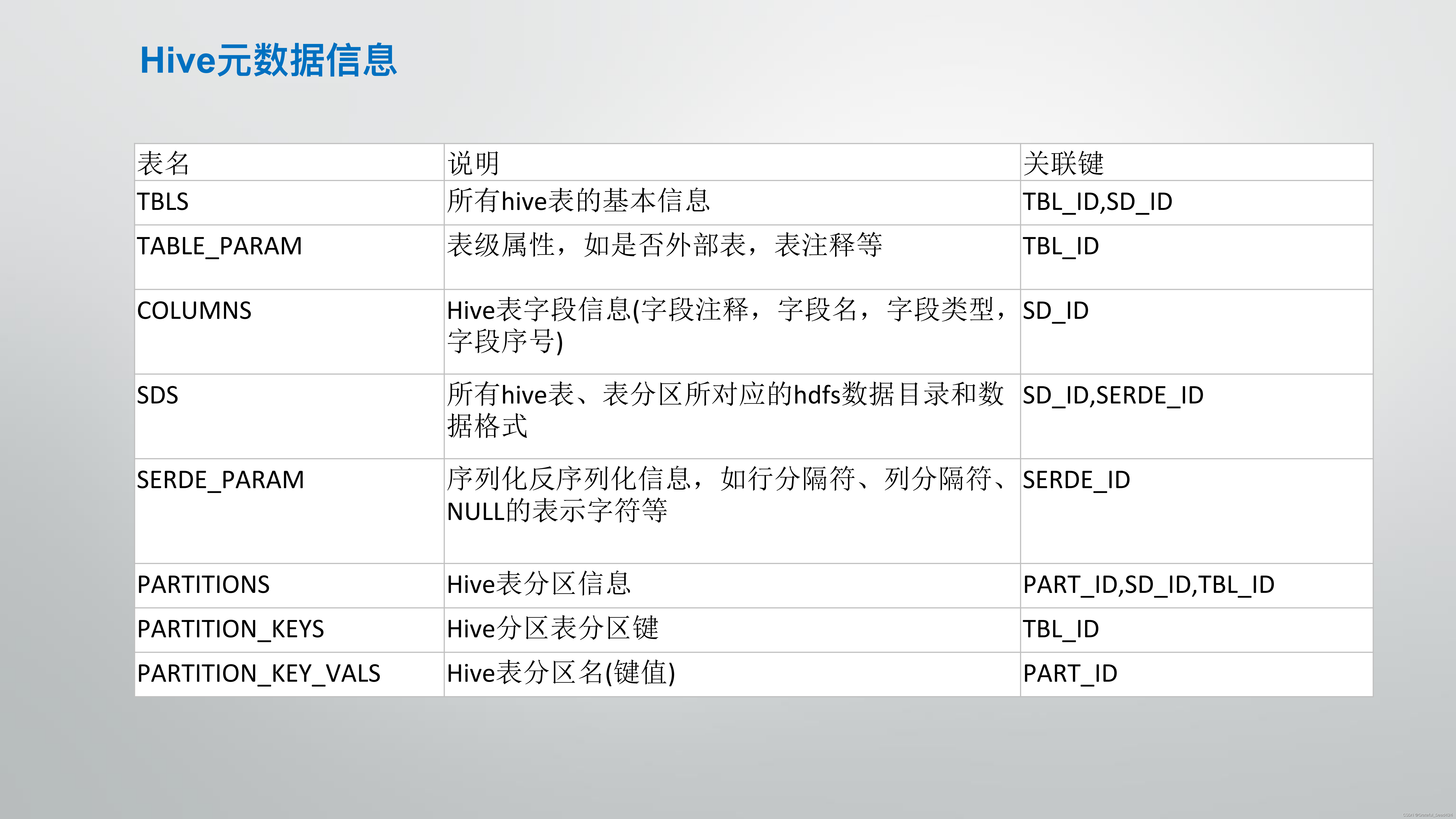
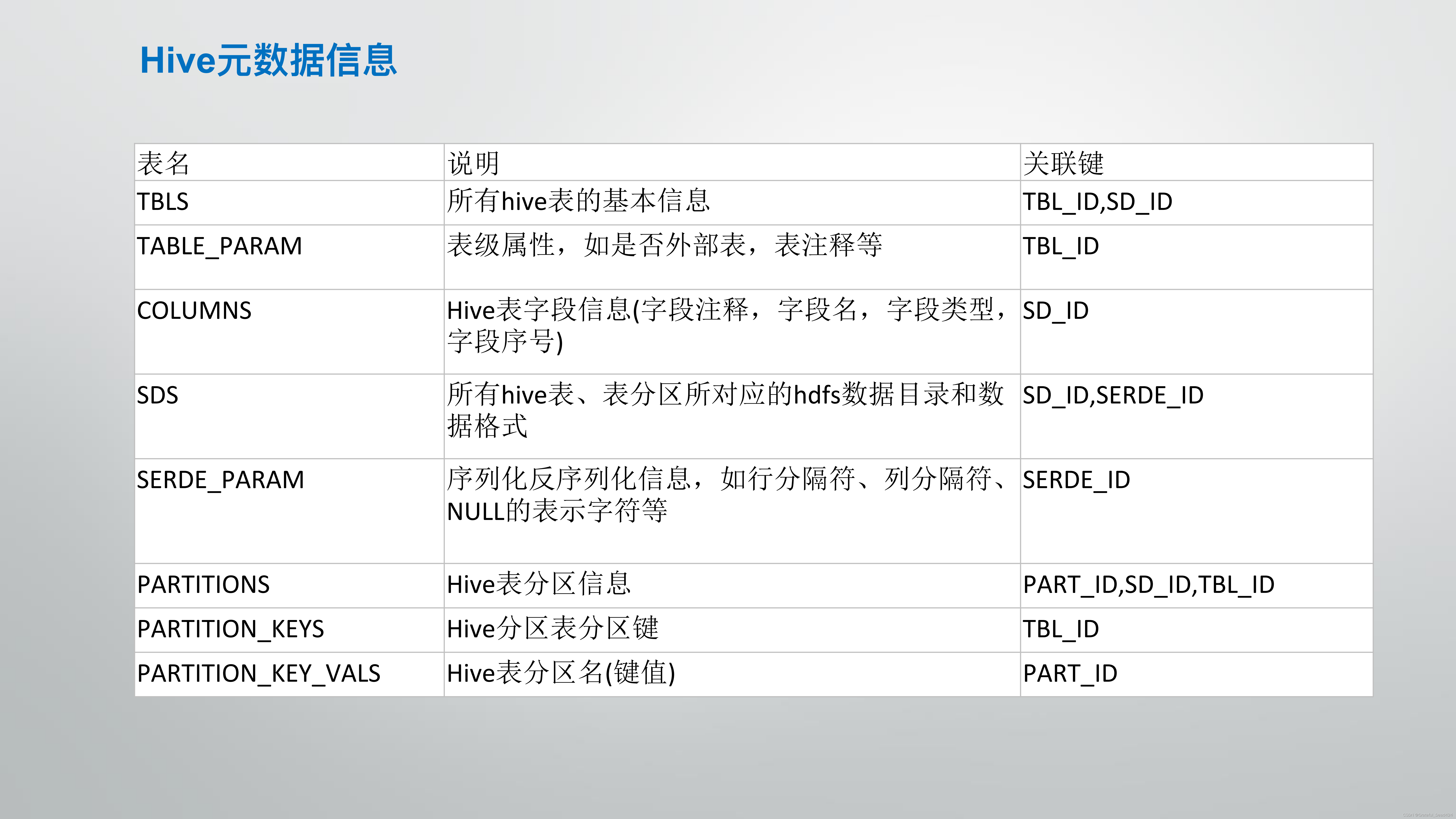
关于hadoop和hive的介绍









hive




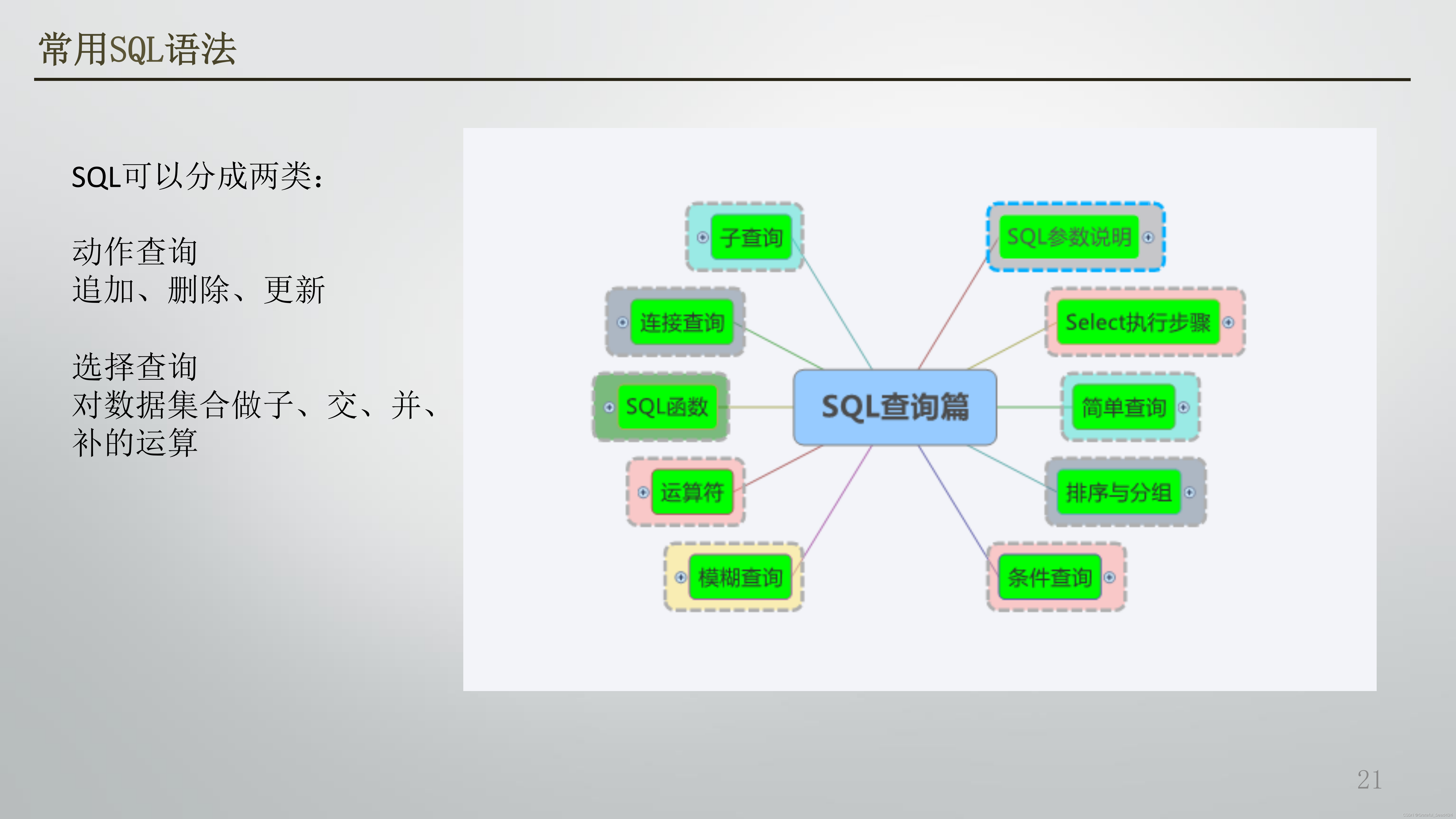
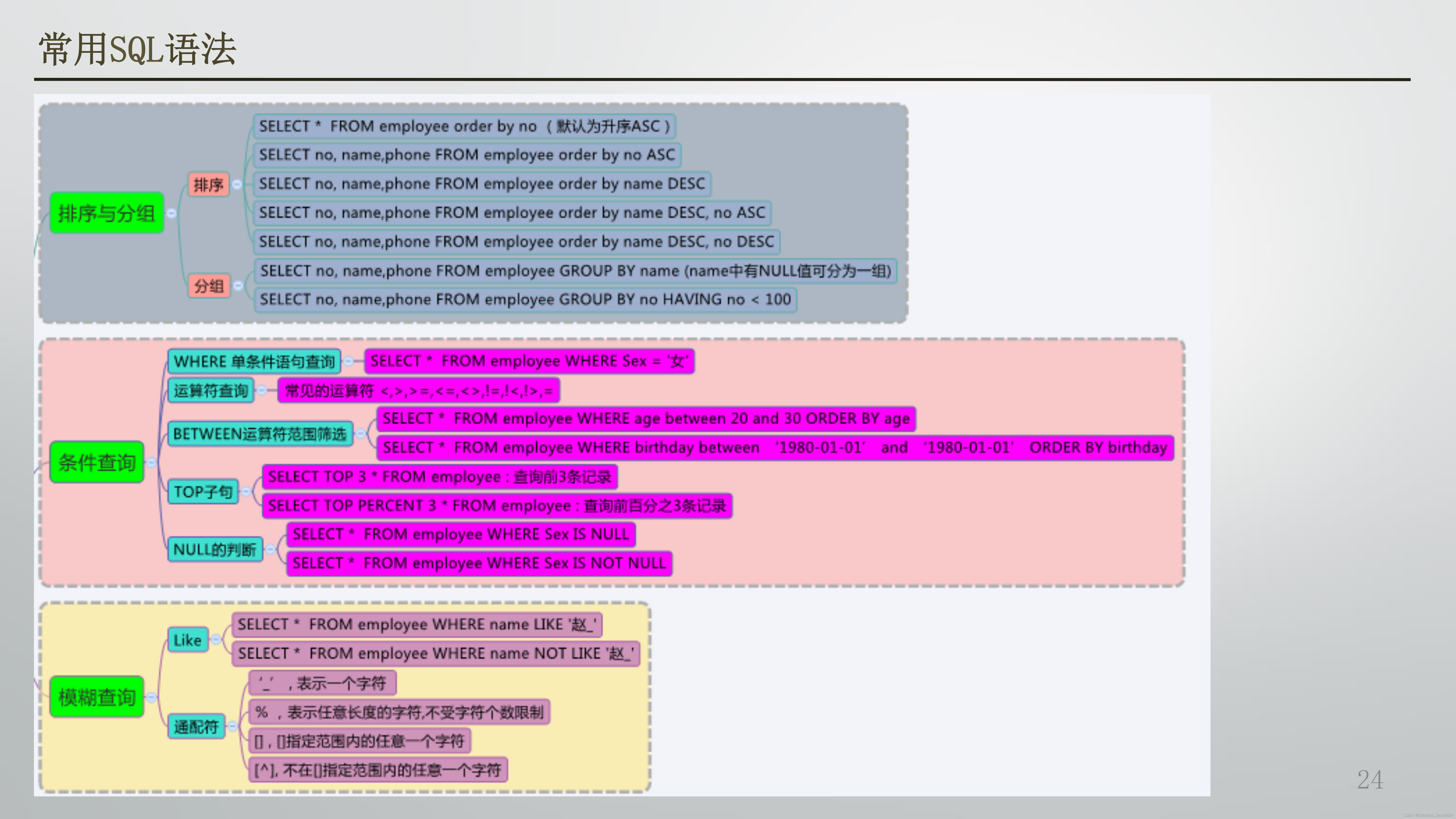
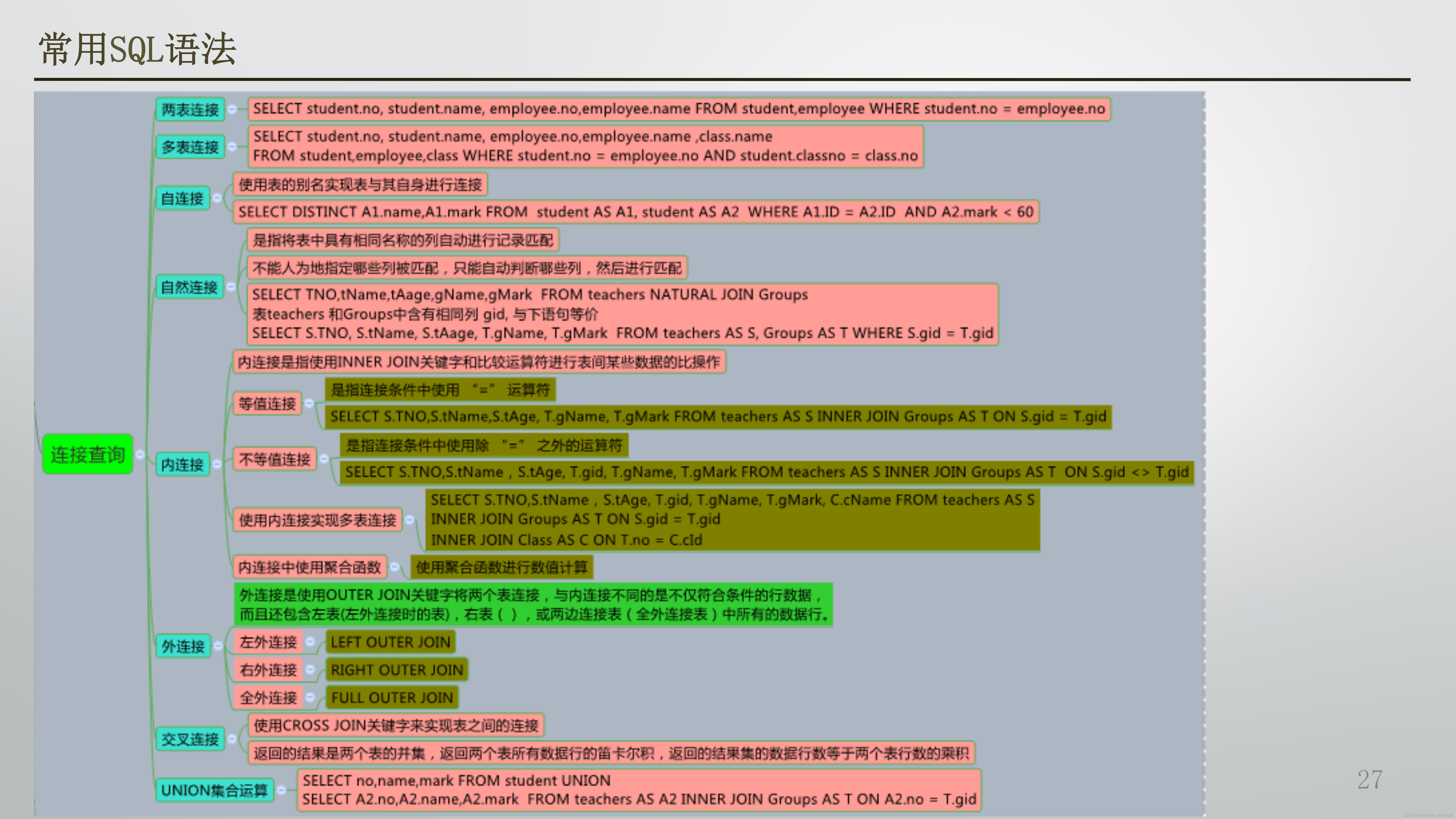
常用SQL语法





hive另外一些说明


版权归原作者 Grateful_Dead424 所有, 如有侵权,请联系我们删除。