
前言
随着NLP预训练模型(大模型)以及多模态研究领域的发展,向量数据库被使用的越来越多。
在XOP亿级题库业务背景下,对于试题召回搜索单单靠着ES集群已经出现性能瓶颈,因此需要预研其他技术方案提高试题搜索召回率。
现一个方案就是使用Bert等模型提取试题题干特征,然后存储到向量数据库,检索试题先走向量数据库,拿到具体的试题ID等信息在走ES进行相似题召回,从而提高搜索的性能。需要考虑的就是特征提取的效率,Milvus的性能(比较吃服务器资源),然后进行评估。
本篇博客主要对Bert等模型以及主流的Milvus进行实践以及一些相关知识学习。
目录
- Milvus概述
- Milvus实践
- NLP文本特征提取实践
- 整合demo
一、Milvus概述
https://milvus.io/
Milvus创建于2019年,其唯一目标是:存储、索引和管理由深度神经网络和其他机器学习(ML)模型生成的大量嵌入向量。
作为一个专门设计用于处理输入向量查询的数据库,它能够索引万亿级的向量。与现有的关系数据库主要处理遵循预定义模式的结构化数据不同,Milvus是自底向上设计的,用于处理从非结构化数据转换而来的嵌入向量Embedding Vector。
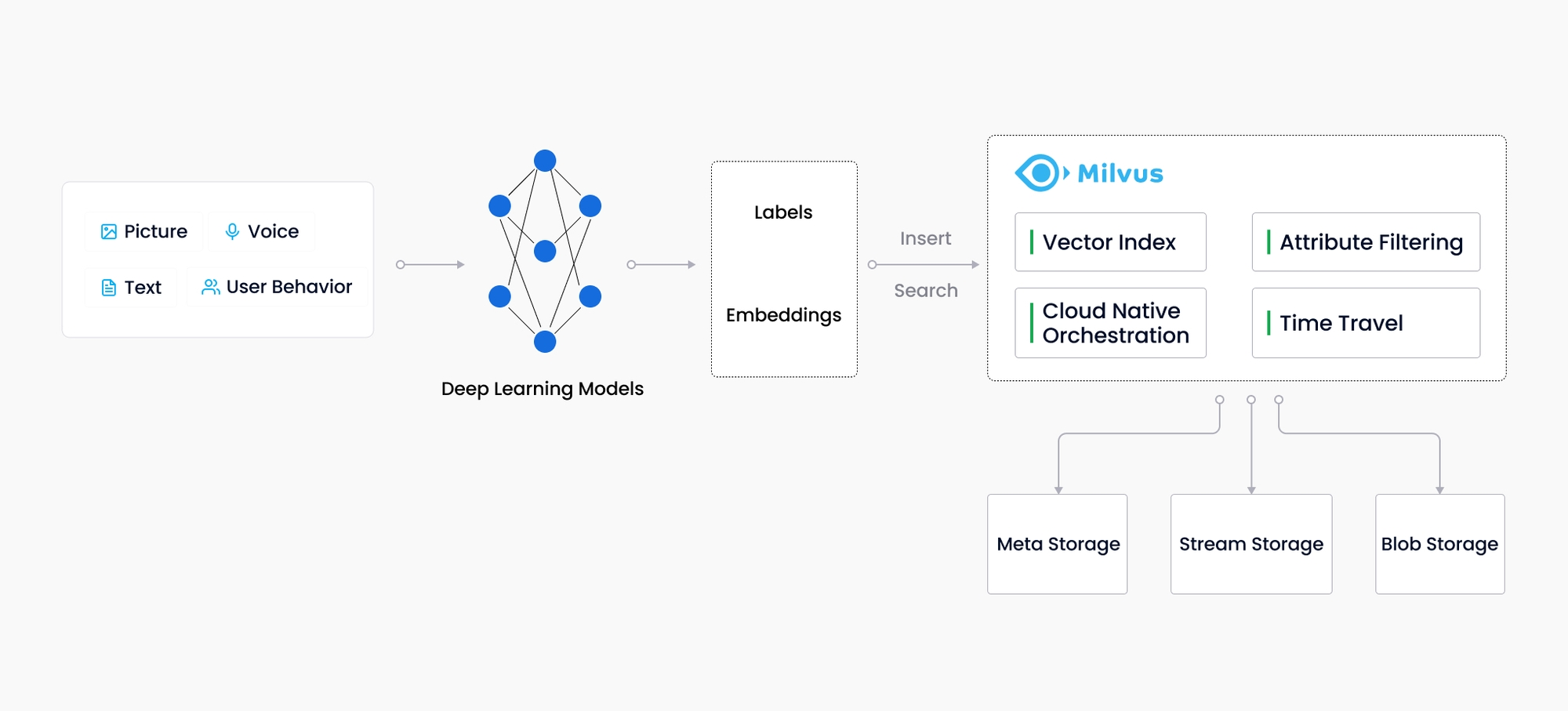
基础概念
- 标量:无向量,只有数值大小没有方向
- 向量:区别于具体的单维度数值标量,可以认为是一条线,有多个数值表示。嵌入向量Embedding Vector是非结构化数据的特征抽象,例如电子邮件、物联网传感器数据、Instagram照片、蛋白质结构等等。从数学上讲,嵌入向量是一个浮点数数组或二进制数组。
- 向量范数:向量范数是指向量的大小或长度,计算向量范式可以用来衡量向量的大小、相似度等。计算方式分为 - L1:曼哈顿范数,将向量元素绝对值相加之和- L2:欧几里得范数,将向量元素的平房和开更号
- 向量归一化:对向量进行归一化操作,以确保不同维度上的特征权重相等,避免某些维度对结果产生较大影响。可以采用L1、L2归一化,一种常用的归一化方法是使用 L2 范数进行单位化处理,即将向量除以其 L2 范数得到单位向量。
- 向量内积:点积、数量积,两个向量的点积就是吧对应位置元素点积之和,对于某个位置元素的点积a · b = |a|·|b|·cos v。其中||表示向量范数。点乘的几何意义是可以用来表征或计算两个向量之间的夹角,以及在b向量在a向量方向上的投影。
- 向量外积:外积(英语:Outer product),在线性代数中一般指两个向量的张量积,其结果为一矩阵;与外积相对,向量的外积是矩阵的克罗内克积的特殊情况。
- 余弦相似度:向量之间的夹角的余弦值,范围为[-1,1],越接近1表示两个向量越来约相似。
https://oi-wiki.org/math/linear-algebra/product/
数据模型相关概念
- Bitset:位图集合
- Channel:有两个不同的Channel在Milvus。它们是PChannel和VChannel。 - 每个PChannel对应一个日志存储主题。PChannel是物理Channel。每个PChannel对应一个日志存储主题。当Milvus集群启动时,默认情况下将分配一组256个PChannels来存储记录数据插入、删除和更新的日志。- 每个VChannel对应于集合中的一个分片。VChannel代表逻辑信道。每个VChannel代表集合中的一个分片。每个集合将被分配一组VChannels,用于记录数据插入、删除和更新。VChannel在逻辑上是分离的,但在物理上共享资源。
- Collection:数据实体集合,类比表
- Schema:集合模式,模式是定义数据类型和数据属性的Meta信息。每个集合都有自己的集合模式,该模式定义集合的所有字段、自动ID(主键)分配启用和集合描述。集合架构中还包括定义字段的名称、数据类型和其他属性的字段架构。
- Entity:数据实体,每个实体会有一个主键。
- Field:数据字段,类型可以是数字、字符串、向量等结构化数据。
- Normalization:归一化,归一化是指转换嵌入(向量)以使其范数等于1的过程。如果使用内积(IP)来计算嵌入相似度,则所有嵌入都必须归一化。归一化后,内积等于余弦相似度。
- Vector index:向量索引是从原始数据中派生出来的重组数据结构,可以大大加速向量相似性搜索的过程。Milvus支持多种向量索引类型。
- Vector similarity search:向量相似性搜索是将向量与数据库进行比较以找到与目标搜索向量最相似的向量的过程。近似最近邻(ANN)搜索算法用于计算向量之间的相似性。
系统设计概念,作为云原生矢量数据库,Milvus通过设计将存储和计算分离。为了增强弹性和灵活性,Milvus中的所有组件都是无状态的。
- 接入层:提供访问的API
- 协调服务:大脑,将任务分配给工作节点
- 工作节点:四肢,执行大脑下发的DML命令
- 存储服务:骨骼,负责数据持久化。它包括Meta存储、日志代理和对象存储。
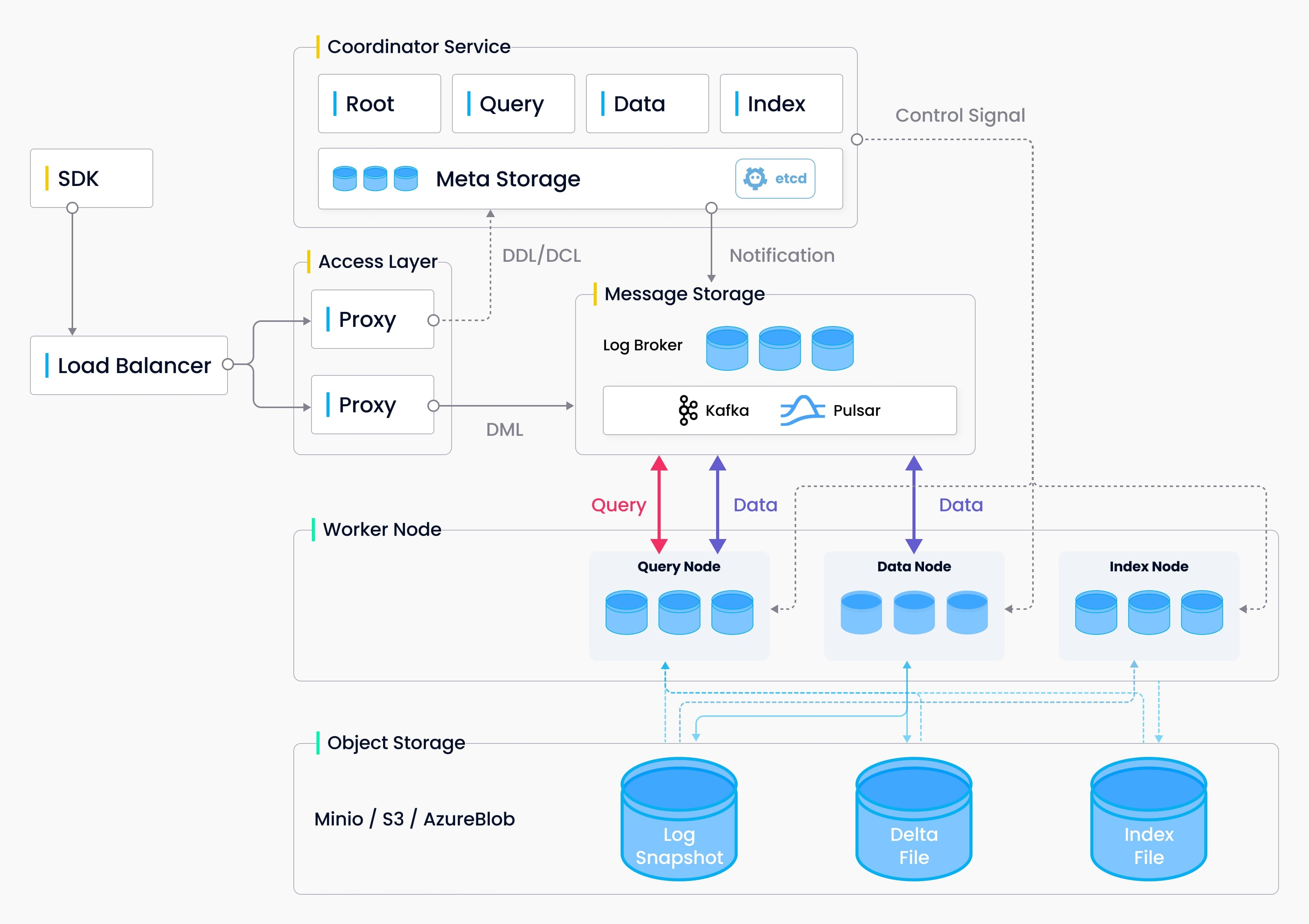
相关概念
- Message storage:消息存储是Milvus的日志存储引擎。
- Dependency:其他依赖,Milvus的依赖项包括etcd(存储Meta数据),MinIO或S3(对象存储)和Pulsar(管理快照日志)。
- Milvus cluster:在Milvus的集群部署中,服务由一组节点提供,以实现高可用性和易扩展性。
- Partition:分区是集合的物理划分。Milvus支持将收集数据划分为物理存储上的多个部分。这个过程称为分区,每个分区可以包含多个段。
- Segment:段是由Milvus自动创建的用于保存插入数据的数据文件。一个集合可以有多个段,一个段可以有多个实体。在向量相似性搜索期间,Milvus扫描每个片段并返回搜索结果。段可以是增长的,也可以是密封的。一个不断增长的段不断接收新插入的数据,直到它被密封。密封的段不再接收任何新数据,并将被刷新到对象存储中,留下新数据插入到新创建的增长段中。增长段将被密封,因为它持有的实体数量达到预定义的阈值,或者因为“增长”状态的跨度超过指定的限制。
- Sharding:分片是指将写操作分配到不同的节点(一个节点可以存储多个分区),以充分利用Milvus集群的并行计算潜力来写数据。默认情况下,单个集合包含两个分片。Milvus采用基于主键哈希的分片方法。Milvus的开发路线图包括支持更灵活的分片方法,如随机和自定义分片。
日志相关概念
- Log Broker:日志代理,支持回放的系统,负责流数据持久化、可靠的异步查询、事件通知和返回查询结果以及当工作节点故障恢复后增量数据的完整性。
- Log sequence:日志序列,记录更改集合状态的所有操作。
- Log snapshot:日志快照,二进制日志,一个较小的段单元,记录和处理对Milvus矢量数据库中数据的更新和更改。来自一个段的数据被持久化在多个binlog中。Milvus中有三种类型的binlog:InsertBinlog、DeleteBinlog和DDLBinlog。
- Log subscriber:日志订阅者订阅日志序列以更新本地数据,并以只读副本的形式提供服务。
二、Milvus实践
2.1、安装Milvus服务
因为是云原生的设计架构,安装可以使用k8s、docker compose安装:https://milvus.io/docs/prerequisite-helm.md,内存至少8g,配置挂在目录以及端口:https://milvus.io/docs/configure-docker.md
也可以使用普通安装方式
# Install Milvus
sudo yum https://github.com/milvus-io/milvus/releases/download/v2.0.0-pre-ga/milvus-2.0.0-preGA.1.el7.x86_64.rpm
# Check Milvus status
sudo systemctl status milvus
sudo systemctl status milvus-etcd
sudo systemctl status milvus-minio
或者直接使用Python安装轻量级的Milvus Lite,Milvus Lite是Milvus的轻量级版本,可与Google Colab和Google Notebook无缝协作。https://milvus.io/docs/milvus_lite.md
// 安装docker以及docker-compose插件
// 下载yml
wget https://github.com/milvus-io/milvus/releases/download/v2.3.3/milvus-standalone-docker-compose.yml -O docker-compose.yml
// 启动
docker-compose up -d
// 查看启动状态
docker compose ps// 关闭
docker compose down
2.2、安装可视化界面
https://github.com/zilliztech/attu,可以下载桌面版 or docker or k8s
2.3、使用Milvus
SDK支持Python、Java、Go、Nodejs,Python的SDK相对功能完善,其他语言的还在活跃的开发中,https://milvus.io/docs/install-pymilvus.md
1、使用Python SDK
// 安装依赖
python -m pip install pymilvus==2.3.3
2、使用Java SDK
https://github.com/milvus-io/milvus-sdk-java
https://milvus.io/api-reference/java/v2.3.x/About.md
<dependency>
<groupId>io.milvus</groupId>
<artifactId>milvus-sdk-java</artifactId>
<version>2.3.3</version>
</dependency>
使用流程
- 创建数据库:与传统的数据库引擎类似,您也可以在Milvus中创建数据库,并将权限分配给某些用户来管理它们。然后,这些用户有权管理数据库中的集合。Milvus集群最多支持64个数据库。默认存在数据库default。
- 创建集合:集合由一个或多个分区组成。在创建新集合时,如果不指定分区数,Milvus会创建一个默认的partition分区_default。创建集合之前需要指定元数据,支持为标量设置默认值。创建集合可以指定分片数量,相比分区,分区通过指定分区名称来减少读取负载,而分片在多个服务器之间分散写入负载。
- 创建索引:需要指定为某向量字段、普通标量创建索引的类型(标量默认索引类型为字典树),额外参数传入聚类参数nlist。比如IVF_FLAT索引将向量数据划分为nlist聚类单元,然后比较目标输入向量与每个聚类中心之间的距离。根据系统设置为查询的聚类数(nprobe),仅基于目标输入和最相似聚类中的向量之间的比较返回相似性搜索结果-大大减少查询时间。
- 加载集合:将集合、集合分区加载进内存,Milvus2.1允许用户将集合按照分区加载为多个副本,以利用额外查询节点的CPU和内存资源。此功能可提高整体QPS和吞吐量,无需额外硬件。
- 插入数据:可以指定partition_name将数据插入指定分区,可以将文件中的实体数据插入集合,支持manualCompaction手动压缩数据
- 搜索数据:根据创建的向量索引以及指定的相似度度量参数(IP、L2等)来进行相似性索引、标量搜素。
数据字段类型
Type****DescriptionNoneFor internal usage.BoolBoolean.Int8Integer number stored with 8 bit.Int16Integer number stored with 16 bit.Int32Integer number stored with 32 bit.Int64Integer number stored with 64 bit.FloatFloating-point numbers.Double64-bit IEEE 754 floating point numbers.StringReserved. Do not use this.VarCharVariable-length string with a limit on the maximum length.BinaryVectorBinary vector. Each dimension is represented by 1 bit.FloatVectorFloat vector. Each dimension is represented by 1 float (4 bits) value.
动态数据类型
为了使Milvus插入数据更加灵活,对于之前创建的集合可以指定动态元数据模式。
动态模式使用户能够将具有新字段的实体插入到Milvus集合中,而无需修改现有模式。这意味着用户可以在不知道集合的完整架构的情况下插入数据,并且可以包括尚未定义的字段。
索引类型
ANN紧邻搜索的索引实现的几种方式
- Tree-based index
- Graph-based index
- Hash-based index
- Quantization-based index
在Milvus中根据数据类型将向量索引种类分为
- 内存索引 - 浮点嵌入索引- 二进制嵌入索引- 标量前缀索引
- 磁盘索引:默认启用DiskANN,可选择关闭。
https://milvus.io/api-reference/java/v2.3.x/Misc/IndexType.md
INVALIDFor internal usage.FLATOnly for FloatVector type field.IVF_FLATOnly for FloatVector type field.IVF_SQ8Only for FloatVector type field.IVF_PQOnly for FloatVector type field.HNSWOnly for FloatVector type field.ANNOYOnly for FloatVector type field.DISKANNOnly for FloatVector type field.BIN_FLATOnly for BinaryVector type field.BIN_IVF_FLATOnly for BinaryVector type field.TRIEOnly for VARCHAR type field.
聚类近似搜索
其中IVF_FLAT、IVF_SQ8、IVF_PQ、BIN_FLAT等索引创建的时候支持 nlist,查询时候支持nporbe参数,将向量数据划分为nlist聚类单元,然后比较目标输入向量与每个聚类中心之间的距离。根据系统设置为查询的聚类数(nprobe),仅基于目标输入和最相似聚类中的向量之间的比较返回相似性搜索结果-大大减少查询时间。
聚类单元是指进行聚类分析时,将数据点划分为不同的簇或群组的基本单位。每个聚类单元代表一个特定的数据集合,其内部的数据点在某种程度上相似。聚类算法通过计算各个数据点之间的距离或相似性来确定如何将它们分配到不同的聚类单元中。
聚类单元可以用于对数据进行分类、识别隐藏的模式和结构,并产生有关数据集的洞察力。利用聚类单元可以将复杂的数据集简化为更易理解和解释的形式,同时可作为进一步分析、预测和决策制定的基础。
相似度量规则
Type****DescriptionINVALIDFor internal usage.L2Euclidean distance. Only for float vectors.IPInner product. Only for normalized float vectors.COSINECosine Similarity. Only for normalized float vectors.HAMMINGOnly for binary vectors.JACCARDOnly for binary vectors.TANIMOTOOnly for binary vectors.
代码demo
具体的API参考官网文档下面举例向量+标量的混合搜索demo
milvusClient.loadCollection(
LoadCollectionParam.newBuilder().withCollectionName("book").build());
final Integer SEARCH_K = 2;
final String SEARCH_PARAM = "{\"nprobe\":10, \”offset\”:5}";
List<String> search_output_fields = Arrays.asList("book_id");
List<List<Float>> search_vectors = Arrays.asList(Arrays.asList(0.1f, 0.2f));
SearchParam searchParam = SearchParam.newBuilder().withCollectionName("book").withMetricType(MetricType.L2).withOutFields(search_output_fields).withTopK(SEARCH_K).withVectors(search_vectors).withVectorFieldName("book_intro").withExpr("word_count <= 11000").withParams(SEARCH_PARAM).build();
R<SearchResults> respSearch = milvusClient.search(searchParam);
Python SDK demo
// 执行demo代码
# hello_milvus.py demonstrates the basic operations of PyMilvus, a Python SDK of Milvus.# 1. connect to Milvus# 2. create collection# 3. insert data# 4. create index# 5. search, query, and hybrid search on entities# 6. delete entities by PK# 7. drop collection
import time
import numpy as np
from pymilvus import (
connections,
utility,
FieldSchema, CollectionSchema, DataType,
Collection,)
fmt = "\n=== {:30} ===\n"
search_latency_fmt = "search latency = {:.4f}s"
num_entities, dim = 3000, 8
################################################################################## 1. connect to Milvus# Add a new connection alias `default` for Milvus server in `localhost:19530`# Actually the "default" alias is a buildin in PyMilvus.# If the address of Milvus is the same as `localhost:19530`, you can omit all# parameters and call the method as: `connections.connect()`.## Note: the `using` parameter of the following methods is default to "default".
print(fmt.format("start connecting to Milvus"))
connections.connect("default", host="localhost", port="19530")
has = utility.has_collection("hello_milvus")
print(f"Does collection hello_milvus exist in Milvus: {has}")################################################################################## 2. create collection# We're going to create a collection with 3 fields.# +-+------------+------------+------------------+------------------------------+# | | field name | field type | other attributes | field description |# +-+------------+------------+------------------+------------------------------+# |1| "pk" | VarChar | is_primary=True | "primary field" |# | | | | auto_id=False | |# +-+------------+------------+------------------+------------------------------+# |2| "random" | Double | | "a double field" |# +-+------------+------------+------------------+------------------------------+# |3|"embeddings"| FloatVector| dim=8 | "float vector with dim 8" |# +-+------------+------------+------------------+------------------------------+
fields = [
FieldSchema(name="pk", dtype=DataType.VARCHAR, is_primary=True, auto_id=False, max_length=100),
FieldSchema(name="random", dtype=DataType.DOUBLE),
FieldSchema(name="embeddings", dtype=DataType.FLOAT_VECTOR, dim=dim)]
schema = CollectionSchema(fields,"hello_milvus is the simplest demo to introduce the APIs")
print(fmt.format("Create collection `hello_milvus`"))
hello_milvus = Collection("hello_milvus", schema, consistency_level="Strong")
################################################################################
# 3. insert data
# We are going to insert 3000 rows of data into `hello_milvus`
# Data to be inserted must be organized in fields.
#
# The insert() method returns:
# - either automatically generated primary keys by Milvus if auto_id=True in the schema;
# - or the existing primary key field from the entities if auto_id=False in the schema.
print(fmt.format("Start inserting entities"))
rng = np.random.default_rng(seed=19530)
entities = [
# provide the pk field because `auto_id` is set to False
[str(i) for i in range(num_entities)],
rng.random(num_entities).tolist(), # field random, only supports list
rng.random((num_entities, dim)), # field embeddings, supports numpy.ndarray and list
]
insert_result = hello_milvus.insert(entities)
# 测试打印
for x in range(3):
print(entities[x])
hello_milvus.flush()
print(f"Number of entities in Milvus: {hello_milvus.num_entities}") # check the num_entities
################################################################################
# 4. create index
# We are going to create an IVF_FLAT index for hello_milvus collection.
# create_index() can only be applied to `FloatVector` and `BinaryVector` fields.
print(fmt.format("Start Creating index IVF_FLAT"))
index = {
"index_type": "IVF_FLAT",
"metric_type": "L2",
"params": {"nlist": 128},
}
hello_milvus.create_index("embeddings", index)
################################################################################
# 5. search, query, and hybrid search
# After data were inserted into Milvus and indexed, you can perform:
# - search based on vector similarity
# - query based on scalar filtering(boolean, int, etc.)
# - hybrid search based on vector similarity and scalar filtering.
#
# Before conducting a search or a query, you need to load the data in `hello_milvus` into memory.
print(fmt.format("Start loading"))
hello_milvus.load()
# -----------------------------------------------------------------------------
# search based on vector similarity
print(fmt.format("Start searching based on vector similarity"))
vectors_to_search = entities[-1][-2:]
search_params = {
"metric_type": "L2",
"params": {"nprobe": 10},
}
start_time = time.time()
result = hello_milvus.search(vectors_to_search, "embeddings", search_params, limit=3, output_fields=["random"])
end_time = time.time()
for hits in result:
for hit in hits:
print(f"hit: {hit}, random field: {hit.entity.get('random')}")
print(search_latency_fmt.format(end_time - start_time))
# -----------------------------------------------------------------------------
# query based on scalar filtering(boolean, int, etc.)
print(fmt.format("Start querying with `random > 0.5`"))
start_time = time.time()
result = hello_milvus.query(expr="random > 0.5", output_fields=["random", "embeddings"])
end_time = time.time()
print(f"query result:\n-{result[0]}")
print(search_latency_fmt.format(end_time - start_time))
# -----------------------------------------------------------------------------
# pagination
r1 = hello_milvus.query(expr="random > 0.5", limit=4, output_fields=["random"])
r2 = hello_milvus.query(expr="random > 0.5", offset=1, limit=3, output_fields=["random"])
print(f"query pagination(limit=4):\n\t{r1}")
print(f"query pagination(offset=1, limit=3):\n\t{r2}")
# -----------------------------------------------------------------------------
# hybrid search
print(fmt.format("Start hybrid searching with `random > 0.5`"))
start_time = time.time()
result = hello_milvus.search(vectors_to_search, "embeddings", search_params, limit=3, expr="random > 0.5", output_fields=["random"])
end_time = time.time()
for hits in result:
for hit in hits:
print(f"hit: {hit}, random field: {hit.entity.get('random')}")
print(search_latency_fmt.format(end_time - start_time))
###############################################################################
# 6. delete entities by PK
# You can delete entities by their PK values using boolean expressions.
ids = insert_result.primary_keys
expr = f'pk in ["{ids[0]}" , "{ids[1]}"]'
print(fmt.format(f"Start deleting with expr `{expr}`"))
result = hello_milvus.query(expr=expr, output_fields=["random", "embeddings"])
print(f"query before delete by expr=`{expr}` -> result: \n-{result[0]}\n-{result[1]}\n")
hello_milvus.delete(expr)
result = hello_milvus.query(expr=expr, output_fields=["random", "embeddings"])
print(f"query after delete by expr=`{expr}` -> result: {result}\n")
###############################################################################
# 7. drop collection
# Finally, drop the hello_milvus collection
# print(fmt.format("Drop collection `hello_milvus`"))
# utility.drop_collection("hello_milvus")
三、NLP文本特征提取实践
BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
2018 年 9 月,Google 一篇 BERT 模型相关论文引爆全网:该自然语言模型,在机器阅读理解顶级水平测试 SQuAD1.1 中,连破 11 项 NLP 测试记录,两个衡量指标全面超越人类。
这不仅开启了 NLP 的全新时代,也标志着迁移学习和预训练+微调的模式,开始进入人们的视野。
使用NLP模型对文本进行特征提,将特征向量存储到Milvus数据库,然后进行相似搜索。
3.1、使用Bert
其他使用bert提取词向量参考https://winkkie.com/archives/%E4%BD%BF%E7%94%A8bert%E6%8F%90%E5%8F%96%E8%AF%8D%E5%90%91%E9%87%8F
可以将模型下载到本地,然后修改config.json文件名称,最终提取特征矩阵为(2,1024)
from transformers import BertTokenizer, BertModel
import torch
# 加载中文 BERT 模型和分词器# model_name = "bert-base-chinese"
tokenizer = BertTokenizer.from_pretrained('models/chinese_roberta_wwm_large_ext_pytorch')
model = BertModel.from_pretrained('models/chinese_roberta_wwm_large_ext_pytorch')defshow_array_properties(np_array):print("-----------------------")"""
常用属性介绍
:param np_array:
:return:
"""print(np_array.shape)# 代表每一个维度元素的个数print(np_array.ndim)# 总共多少维度print(np_array.dtype)# 数据类型print(np_array.size)# 数组中元素的个数defget_word_embedding(sentence):# 分词
tokens = tokenizer.tokenize(sentence)# 添加特殊标记 [CLS] 和 [SEP]
tokens =['[CLS]']+ tokens +['[SEP]']# 将分词转换为对应的编号
input_ids = tokenizer.convert_tokens_to_ids(tokens)# 转换为 PyTorch tensor 格式
input_ids = torch.tensor([input_ids])# 获取词向量
outputs = model(input_ids)# outputs[0]是词嵌入表示
embedding = outputs[0]# 去除头尾标记的向量值
word_embedding = embedding[:,1:-1,:]return word_embedding
if __name__ =='__main__':
matrix = get_word_embedding("你好")
show_array_properties(matrix[0])# show_array_properties(matrix[0][0])# show_array_properties(matrix[0][1])print(matrix[0][0][0])print(matrix[0][1][1023])# 解释# 根据模型名称加载# 第一次会在线加载模型,并且保存至用户子目录"\.cache\torch\transformers\"# tokenizer = BertTokenizer.from_pretrained('chinese-bert-wwm')# bert = BertModel.from_pretrained('chinese-bert-wwm')# 加载本地模型
bert_path ='/Users/sichaolong/Documents/my_projects/my_pycharm_projects/learn-bert-demo/models/chinese_wwm_ext_pytorch'
tokenizer = BertTokenizer.from_pretrained(bert_path)
bert = BertModel.from_pretrained(bert_path,return_dict=True)
inputs = tokenizer("你好", return_tensors="pt")# "pt"表示"pytorch"
outputs = bert(**inputs)print(outputs.last_hidden_state.shape)# torch.Size([1, 4, 768])print(outputs.pooler_output.shape)# torch.Size([1, 768])# 其中last_hidden_state的形状的含义为 (batch_size, sequence_length, hidden_size);# pooler_output是last_hidden_state中token [CLS]对应的特征(即last_hidden_state[:, 0, :])经过全连接运算得到,# 一般可以认为其概括了整句话的信息,其形状的含义为(batch_size, hidden_size)。
3.2、使用Bert-as-service
2018 年 10 月,BERT 发布仅一个月后,BERT-as-service 横空出世。用户可以使用一行代码,通过 C/S 架构的方式,连接到服务端,快速获得句向量。
BERT-as-service是一个用于在大规模文本语料库上进行基于特征提取的快速部署框架。它使用Google发布的预训练的BERT模型,并允许用户基于该模型编写客户端代码,以便方便地对新的文本数据生成向量表示,并进行相似度计算、分类、聚类等任务。BERT-as-service支持多种语言处理任务,例如语义检索、句子分类、问答系统等,并且能够在CPU或GPU加速下运行。
Bert-as-service使用transformer,目前本地安装环境出现一些问题,python==3.6的装不上,然后tensorflow=1.x的版本装不上去,导致报错,自行尝试 // TODO
# 安装bert-as-service
pip install -U bert-serving-server bert-serving-client
# 还需要安装tensorflow1.x版本,不能是2.x版本,否则报错:https://github.com/jina-ai/clip-as-service/issues/522# 下载预训练模型,将下载好的模型zip解压到指定文件夹,模型可从github下载。# 启动bert-as-service server,需要指定模型路径参数
bert-serving-start-model_dir /xxx/english_L-12_H-768_A-12/ -num_worker=4
# 启动bert-as-service clientfrom bert_serving.client import BertClient
bc = BertClient()
bc.encode(['First do it','then do it right','then do it better'])
3.3、使用CLIP-as-service
CLIP-as-service则是一种类似的工具,用于将OpenAI发布的预训练模型CLIP(Contrastive Language-Image Pretraining)转化为可供调用的API服务。多模态CLIP模型能够同时理解图像和文本,从而可以根据给定的图片描述生成与之匹配的图片表示,或者根据给定的文本描述找到与之相关的图片。
通过CLIP-as-service,开发人员可以轻松地将这个强大的视觉-语言模型集成到自己的应用程序中,用于图像搜索、标注、推荐等任务。
参考:https://clip-as-service.jina.ai/user-guides/server/,使用更加简单,将OpenAI CLIP等多模态研究工程,拆分为c/s模块,提供API直接使用。
CLIP-as-service函数封装得很方便,可以直接传入生成句向量,但是无法生成词向量
3.2.1、使用clip-client访问官方CAS服务
参考:https://zhuanlan.zhihu.com/p/562412434
3.2.2、安装使用clip-server、clip-client
参考官方文档:https://clip-as-service.jina.ai/index.html#
安装启动服务端
Make sure you are using Python 3.7+. You can install the client and server independently. It is not required to install both: e.g. you can install clip_server on a GPU machine and clip_client on a local laptop.
# 安装clip-server,需要python==3.7.0之上
pip install clip-server
# 启动服务,启动会下载模型,下载速度比较慢
python -m clip_server
其中如果报错got an unexpected keyword argument ‘global_average_pool’,找到model.py文件将该参数删除即可。
⠏ Waiting clip_t... ━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━ 1/2 0:00:04UserWarning: `docs` annotation must be a type hint, got DocumentArray instead, you should ma
ybe remove the string annotation. Default valueDocumentArray will be used instead.(raised from C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\serve\executors\__init__.py:267)
⠧ Waiting clip_t... ━━━━━━━━━━━━━━━━━━━━╺━━━━━━━━━━━━━━━━━━━ 1/2 0:00:06CRITI… clip_t/rep-0@6792 can not load the executor from{"jtype": "CLIPEncoder","metas": {"py_modules": ["clip_server.executors.clip_torch"]}}[11/26/23 17:17:52]
ERROR clip_t/rep-0@6792 TypeError("__init__() got an unexpected keyword argument 'global_average_pool'") during 'WorkerRuntime' initialization
add "--quiet-error" to suppress the exception details
Traceback (most recent call last):
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\serve\executors\run.py", line 140, in run
runtime = AsyncNewLoopRuntime(
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\serve\runtimes\asyncio.py", line 92, in __init__
self._loop.run_until_complete(self.async_setup())
File "D:\mysoftware\anaconda3\lib\asyncio\base_events.py", line 647, in run_until_complete
return future.result()
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\serve\runtimes\asyncio.py", line 309, in async_setup
self.server = self._get_server()
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\serve\runtimes\asyncio.py", line 214, in _get_server
return GRPCServer(
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\serve\runtimes\servers\grpc.py", line 34, in __init__
super().__init__(**kwargs)
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\serve\runtimes\servers\__init__.py", line 63, in __init__
] = (req_handler or self._get_request_handler())
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\serve\runtimes\servers\__init__.py", line 88, in
_get_request_handler
return self.req_handler_cls(
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\serve\runtimes\worker\request_handling.py", line 139, in
__init__
self._load_executor(
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\serve\runtimes\worker\request_handling.py", line 375, in
_load_executor
self._executor: BaseExecutor = BaseExecutor.load_config(
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\jaml\__init__.py", line 792, in load_config
obj = JAML.load(tag_yml, substitute=False, runtime_args=runtime_args)
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\jaml\__init__.py", line 174, in load
r = yaml.load(stream, Loader=get_jina_loader_with_runtime(runtime_args))
File "D:\mysoftware\anaconda3\lib\site-packages\yaml\__init__.py", line 81, in load
return loader.get_single_data()
File "D:\mysoftware\anaconda3\lib\site-packages\yaml\constructor.py", line 51, in get_single_data
return self.construct_document(node)
File "D:\mysoftware\anaconda3\lib\site-packages\yaml\constructor.py", line 55, in construct_document
data = self.construct_object(node)
File "D:\mysoftware\anaconda3\lib\site-packages\yaml\constructor.py", line 100, in construct_object
data = constructor(self, node)
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\jaml\__init__.py", line 582, in _from_yaml
return get_parser(cls, version=data.get('version', None)).parse(
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\jaml\parsers\executor\legacy.py", line 46, in parse
obj = cls(
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\serve\executors\decorators.py", line 58, in arg_wrapper
f = func(self,*args,**kwargs)
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\serve\helper.py", line 73, in arg_wrapper
f = func(self,*args,**kwargs)
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\clip_server\executors\clip_torch.py", line 91, in __init__
self._model = CLIPModel(
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\clip_server\model\openclip_model.py", line 38, in __init__
self._model = load_openai_model(
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\clip_server\model\model.py", line 477, in load_openai_model
model = build_model_from_openai_state_dict(
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\clip_server\model\model.py", line 413, in
build_model_from_openai_state_dict
model = CLIP(
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\clip_server\model\model.py", line 281, in __init__
self.visual = _build_vision_tower(
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\clip_server\model\model.py", line 193, in _build_vision_tower
visual = VisionTransformer(
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\clip_server\model\model.py", line 83, in __init__
super().__init__(
TypeError: __init__() got an unexpected keyword argument 'global_average_pool'
ERROR Flow@14176 An exception occurred: [11/26/23 17:17:52]
ERROR Flow@14176 Flow is aborted due to ['clip_t'] can not be started.
WARNI… gateway/rep-0@14176 Pod was forced to close after 1 second. Graceful closing is not available on Windows.[11/26/23 17:17:53]
Traceback (most recent call last):
File "D:\mysoftware\anaconda3\lib\runpy.py", line 197, in _run_module_as_main
return _run_code(code, main_globals, None,
File "D:\mysoftware\anaconda3\lib\runpy.py", line 87, in _run_code
exec(code, run_globals)
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\clip_server\__main__.py", line 25, in <module>
with f:
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\orchestrate\orchestrator.py", line 14, in __enter__
return self.start()
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\orchestrate\flow\builder.py", line 33, in arg_wrapper
return func(self,*args,**kwargs)
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\orchestrate\flow\base.py", line 1846, in start
self._wait_until_all_ready()
File "C:\Users\sicha\AppData\Roaming\Python\Python39\site-packages\jina\orchestrate\flow\base.py", line 2012, in _wait_until_all_ready
raise RuntimeFailToStart
jina.excepts.RuntimeFailToStart
安装启动客户端,使用grpc连接clip-server
from clip_client import Client
# 实例化Client# The protocol of the server, must be one of grpc, websocket, http, grpcs, websockets, https. Protocols end with s are TLS encrypted. This must match with the server protocol.
c = Client('grpc://127.0.0.1:51000')
c.profile()# 输出
D:\mysoftware\anaconda3_data\envs\clip-as-service\python.exe D:\myproject\my_pycharm_projects\clip-as-service\clip_as_service_demo.py
Roundtrip 139ms 100%
├── Client-server network 10ms 7%
└── Server 129ms 93%
├── Gateway-CLIP network 1ms 1%
└── CLIP model 128ms 99%
下载测试图片集,然后进行对文本和图片进行特征提取
from clip_client import Client
from docarray import DocumentArray
# 实例化Client# The protocol of the server, must be one of grpc, websocket, http, grpcs, websockets, https. Protocols end with s are TLS encrypted. This must match with the server protocol.
c = Client('grpc://127.0.0.1:51000')
def show_array_properties(np_array):
print("-----------------------")"""
常用属性介绍
:param np_array:
:return:
"""
print(np_array.shape)# 代表每一个维度元素的个数
print(np_array.ndim)# 总共多少维度
print(np_array.dtype)# 数据类型
print(np_array.size)# 数组中元素的个数if __name__ == '__main__':
# 测试连接
c.profile()# 加载测试图片集# da = DocumentArray.from_files(['images/left/*.jpg','images/right/*.jpg'])# 展示测试图片集# da.plot_image_sprites()# 对测试图像进行编码# da = c.encode(da, show_progress=True)
vec = c.encode(["你好","你好你好","deufherudhfuierhfg"])# r = da.find(query=vec, limit=1)# r.plot_image_sprites()
print(vec[0])
print("+++++++")
print(vec[0][0])
print("+++++++")
print(vec[0][76])# 可以理解为77行512列的矩阵
print("=======")
print(vec[0].size)# 39424
print("=======")
print(vec[0][0].size)# 512
show_array_properties(vec)# 末尾输出-----------------------(3, 77, 512)
3 =====> 如vec[0],vec[1],vec[2]
float32
118272 =====> 总个数 3 * 77行 * 512 列,也就是特征矩阵为(77,512)
参考
- 使用CLIP进行视频搜索:https://blog.csdn.net/Jina_AI/article/details/128475707
- 官方文档给的数据集443下载不了,可以将zip下载然后解压,https://sites.google.com/view/totally-looks-like-dataset
- 或者可下载Open-Image-set参考:https://storage.googleapis.com/openimages/web/download.html
3.4、文本特征矩阵转为指定维度向量
CLIP-as-service文本提取的特征矩阵维度为(77,512),需要转化为指定维度的向量才能存储到Milvus向量数据库。
降维转换方法很多,比如
- 平均池化(Average Pooling):可以通过对每一行取平均值来降维,得到一个大小为 (77, 1) 的向量。这是一种简单的降维方法。
- 主成分分析(Principal Component Analysis, PCA):使用 PCA 可以将数据降维到指定的维度。这需要使用库,如 scikit-learn。
import numpy as np
from sklearn.decomposition import PCA
def pca():
# 假设你的矩阵数据是 matrix,大小为 (77, 512)
matrix = np.random.rand(77, 512)# 指定降维后的维度
target_dimension = 1
# 使用 PCA 进行降维
pca = PCA(n_components=target_dimension)
reduced_vectors = pca.fit_transform(matrix)# 打印信息
print("原始矩阵形状:", matrix.shape)
print("降维后的向量形状:", reduced_vectors.shape)
print(reduced_vectors)if __name__ == '__main__':
# 假设你的矩阵数据是 matrix,大小为 (77, 512)
matrix = np.random.rand(77, 512)# 使用平均池化降维
average_vector = np.mean(matrix, axis=1)# 打印信息
print("原始矩阵形状:", matrix.shape)
print("降维后的向量形状:", average_vector.shape)
print(average_vector)
四、整合搜索demo
主要整合CLIP-as-service和milvus向量数据库,首先将模拟数据进行特征提取,将特征矩阵转为指定维度特征向量,然后存储到milvus数据库,接着模拟相似性搜索。
// TODO
版权归原作者 scl、 所有, 如有侵权,请联系我们删除。