

🎄🎄>>>深度学习Tricks,第一时间送达<<<🎄🎄

💖💖🎄🎄魔改YOLOv5/YOLOv7目标检测算法结合各种新颖且行之有效的网络结构,效果俱佳!📚📚🎈🎈
YOLOv5/YOLOv7结合以下创新改进项目:
🍀链接直达:YOLO算法创新改进系列项目汇总(入门级教程指南)💖
主要包括注意力SE、CBAM、ECA、CA、C3SE、C3CBAM、C3ECA、C3CA、PSA、NAM、GAM、SimAM、Criss-Cross、SOCA,加权双向特征金字塔网络BiFPN,Swin Transfomer v2、Transformer、BotNet、CotNet、MCA、DIOU NMS、EIOU Loss、Alpha-IoU、SIOU Loss等损失函数,检测头部Head改进Decoupled/ASFF、空间金字塔池化改进ASPP/RFBNet、各类激活函数替换,低分辨率图像SPD-Conv,****Involution内卷积,GSConv+Slim-neck降低模型复杂度,纯卷积主干网络ConvNeXt,移动端高性能骨干MobileOne,轻量化网络PP-LCNet、MobileNetV3、Shufflenetv2、GhostNet、RepVGG以及其他Tricks等等。
🌴 持续更新中……
🚀小海带在自身数据集上进行实验训练,发现平均精度均值mAP涨点明显。有需要的小伙伴赶快点赞+收藏起来喔!!!👍👍👍
✨【YOLO创新算法尝新系列】✨
🏂 美团出品 | YOLOv6 v3.0 is Coming(超越YOLOv7、v8)
🏂 官方正品 | Ultralytics YOLOv8算法来啦(尖端SOTA模型)
🍀还包括其他创新&算法训练&论文投稿相关内容:
1.YOLO算法创新改进系列项目汇总(入门级教程指南)
2.手把手教你搭建属于自己的PyQt5-YOLOv5目标检测平台(保姆级教程)
3.目标检测算法——YOLOv7训练自己的数据集(保姆级教程)
4.YOLO算法改进之结合GradCAM可视化热力图(附详细教程)
5.人工智能前沿——玩转OpenAI聊天机器人ChatGPT(中文版)
6.深度学习之语义分割算法(入门学习)
7.知识经验分享——YOLOv5-6.0训练出错及解决方法(RuntimeError)
8.目标检测算法——将xml格式转换为YOLOv5格式txt
9.目标检测算法——YOLOv5/YOLOv7如何改变bbox检测框的粗细大小
10.人工智能前沿——6款AI绘画生成工具
11.YOLOv5结合人体姿态估计
12.超越YOLOv5,0.7M超轻量,又好又快(PP-YOLOE&PP-PicoDet)
13.目标检测算法——收藏|小目标检测的定义(一)
14.目标检测算法——收藏|小目标检测难点分析(二)
15.目标检测算法——收藏|小目标检测解决方案(三)
16.人工智能前沿——深度学习热门领域(确定选题及研究方向)
17.人工智能前沿——2022年最流行的十大AI技术
18.人工智能前沿——未来AI技术的五大应用领域
19.人工智能前沿——无人自动驾驶技术
20.人工智能前沿——AI技术在医疗领域的应用
21.人工智能前沿——随需应变的未来大脑
22.目标检测算法——深度学习知识简要普及
23.目标检测算法——10种深度学习框架介绍
24.目标检测算法——为什么我选择PyTorch?
25.知识经验分享——超全激活函数解析(数学原理+优缺点)
26.知识经验分享——卷积神经网络(CNN)
27.海带软件分享——Office 2021全家桶安装教程(附报错解决方法)
28.海带软件分享——日常办公学习软件分享(收藏)
**29.**论文投稿指南——收藏|SCI论文投稿注意事项(提高命中率)
30.论文投稿指南——收藏|SCI论文怎么投?(Accepted)
**31.**论文投稿指南——收藏|SCI写作投稿发表全流程
**32.**论文投稿指南——收藏|如何选择SCI期刊(含选刊必备神器)
**33.**论文投稿指南——SCI投稿各阶段邮件模板
**34.**论文投稿指南——计算机视觉 (Computer Vision) 顶会归纳
**35.**论文投稿指南——中文核心期刊
36.论文投稿指南——计算机领域核心期刊
**37.**论文投稿指南——中文核心期刊推荐(计算机技术)
**38.**论文投稿指南——中文核心期刊推荐(计算机技术2)
**39.**论文投稿指南——中文核心期刊推荐(计算机技术3)
40.论文投稿指南——中文核心期刊推荐(电子、通信技术)
41.论文投稿指南——中文核心期刊推荐(电子、通信技术2)
42.论文投稿指南——中文核心期刊推荐(电子、通信技术3)
43.论文投稿指南——中文核心期刊推荐(机械、仪表工业)
44.论文投稿指南——中文核心期刊推荐(机械、仪表工业2)
45.论文投稿指南——中文核心期刊推荐(机械、仪表工业3)
46.论文投稿指南——中国(中文EI)期刊推荐(第1期)
47.论文投稿指南——中国(中文EI)期刊推荐(第2期)
48.论文投稿指南——中国(中文EI)期刊推荐(第3期)
49.论文投稿指南——中国(中文EI)期刊推荐(第4期)
50.论文投稿指南——中国(中文EI)期刊推荐(第5期)
51.论文投稿指南——中国(中文EI)期刊推荐(第6期)
52.论文投稿指南——中国(中文EI)期刊推荐(第7期)
53.论文投稿指南——中国(中文EI)期刊推荐(第8期)
54.【1】SCI易中期刊推荐——计算机方向(中科院3区)
55.【2】SCI易中期刊推荐——遥感图像领域(中科院2区)
56.【3】SCI易中期刊推荐——人工智能领域(中科院1区)
57.【4】SCI易中期刊推荐——神经科学研究(中科院4区)
58.【5】SCI易中期刊推荐——计算机科学(中科院2区)
59.【6】SCI易中期刊推荐——人工智能&神经科学&机器人学(中科院3区)
60.【7】SCI易中期刊推荐——计算机 | 人工智能(中科院4区)
61.【8】SCI易中期刊推荐——图像处理领域(中科院4区)
**🌴 **持续更新中……
Transformer是一种主要基于自注意力机制的深度神经网络,最初是在自然语言处理领域中应用的。受到Transformer强大的表示能力的启发,研究人员提议将Transformer扩展到计算机视觉任务。与其他网络类型(例如卷积网络和循环网络)相比,基于Transformer的模型在各种视觉基准上显示出竞争性的甚至更好的性能。
卷积神经网络(CNN)引入了卷积层和池化层以处理图像等位移不变性的数据。递归神经网络(RNN)利用循环单元来处理顺序数据或时间序列数据。Transformer是一种新提出的神经网络,主要利用自我注意机制提取内在特征。在这些网络中,Transformer是最近发明的神经网络(2017年),对于广泛的人工智能应用具有巨大的潜力。
Transformer最初应用于自然语言处理(NLP)任务,并带来了显着的改进。例如,Vaswani等人首先提出了一种仅基于注意力机制来实现机器翻译和英语选区解析任务的Transformer。Devlin等人引入了一种称为BERT的新语言表示模型,该模型通过共同限制左右上下文来预训练未标记文本的翻译器。BERT在当时的11个NLP任务上获得了SOTA结果。Brown等人在45TB压缩明文数据上预训练了基于巨型Transformer的GPT-3模型,该模型具有1,750亿个参数,并且无需微调即可在不同类型的下游自然语言任务上实现出色的性能。这些基于Transformer的模型显示了强大的表示能力,并在NLP领域取得了突破。
受NLP中Transformer功能的启发,最近的研究人员将Transformer扩展到计算机视觉(CV)任务。CNN曾经是视觉应用中的基本组件,但是Transformer显示出了其作为CNN替代品的能力。Chen等人训练一个sequence Transformer去自动回归预测像素并在图像分类任务上与CNN取得竞争性结果。ViT是Dosovitskiy等人最近提出的Visual Transformer模型。ViT将一个纯粹的transformer直接用于图像块序列,并在多个图像识别基准上获得SOTA性能。除了基本的图像分类,transformer还用于解决更多计算机视觉问题,例如目标检测,语义分割,图像处理和视频理解。由于其出色的性能,提出了越来越多基于transformer的模型来改善各种视觉任务。
1.视觉Transformer结构图:
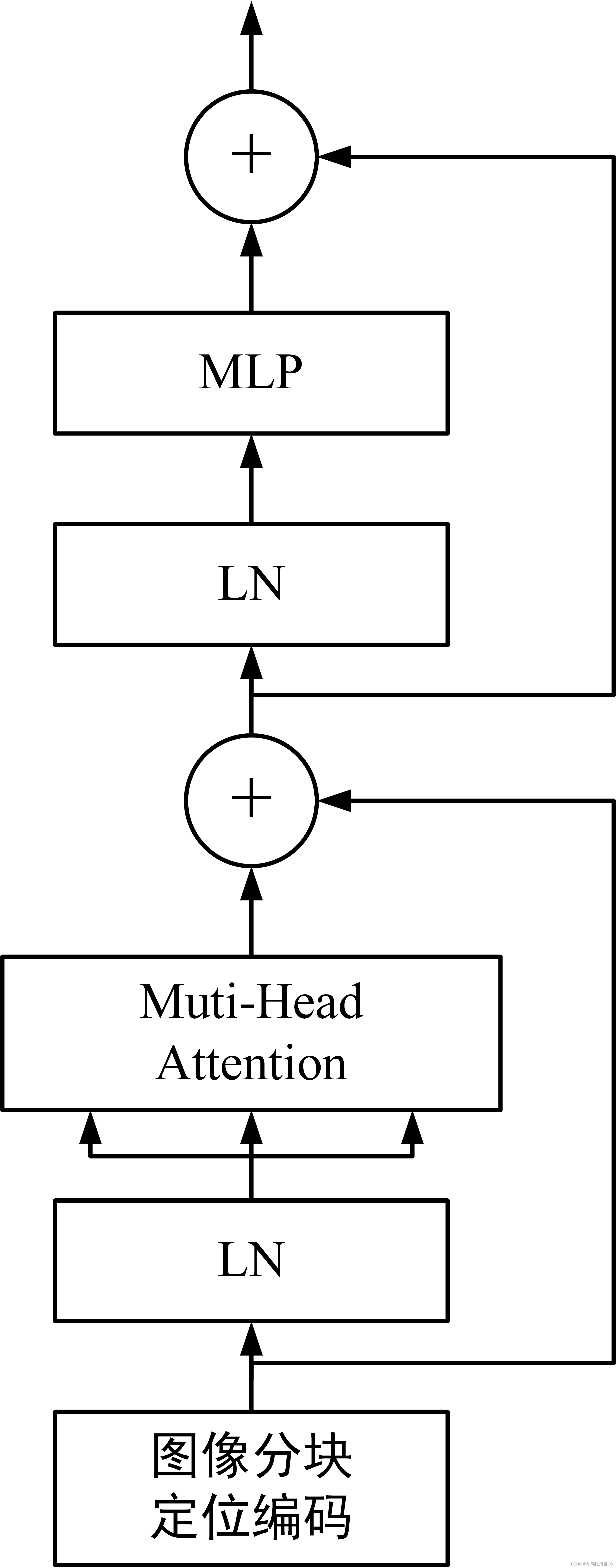
2. 部分代码:
class TransformerLayer(nn.Module):
# Transformer layer https://arxiv.org/abs/2010.11929 (LayerNorm layers removed for better performance)
def __init__(self, c, num_heads):
super().__init__()
self.q = nn.Linear(c, c, bias=False)
self.k = nn.Linear(c, c, bias=False)
self.v = nn.Linear(c, c, bias=False)
self.ma = nn.MultiheadAttention(embed_dim=c, num_heads=num_heads)
self.fc1 = nn.Linear(c, c, bias=False)
self.fc2 = nn.Linear(c, c, bias=False)
def forward(self, x):
x = self.ma(self.q(x), self.k(x), self.v(x))[0] + x
x = self.fc2(self.fc1(x)) + x
return x
class TransformerBlock(nn.Module):
# Vision Transformer https://arxiv.org/abs/2010.11929
def __init__(self, c1, c2, num_heads, num_layers):
super().__init__()
self.conv = None
if c1 != c2:
self.conv = Conv(c1, c2)
self.linear = nn.Linear(c2, c2) # learnable position embedding
self.tr = nn.Sequential(*[TransformerLayer(c2, num_heads) for _ in range(num_layers)])
self.c2 = c2
def forward(self, x):
if self.conv is not None:
x = self.conv(x)
b, _, w, h = x.shape
p = x.flatten(2)
p = p.unsqueeze(0)
p = p.transpose(0, 3)
p = p.squeeze(3)
e = self.linear(p)
x = p + e
x = self.tr(x)
x = x.unsqueeze(3)
x = x.transpose(0, 3)
x = x.reshape(b, self.c2, w, h)
return x
class SwinTransformerBlock(nn.Module):
def __init__(self, c1, c2, num_heads, num_layers, window_size=8):
super().__init__()
if c1 = c2:
self.conv = Conv(c1, c2)
# remove input_resolution
self.blocks = nn.Sequential(*[SwinTransformerLayer(dim=c2, num_heads=num_heads, window_size=window_size,
shift_size=0 if (i % 2 == 0) else window_size // 2) for i in range(num)])
def forward(self, x):
if self.conv is not None:
x = self.conv(x)
x = self.blocks(x)
return x

关于YOLO算法改进&论文投稿可关注并留言博主的CSDN/QQ
🎈🎄>>>一起交流!互相学习!共同进步!<<<🎄🎈
版权归原作者 加勒比海带66 所有, 如有侵权,请联系我们删除。