
YOLOv5 6.0/6.1结合ASFF
前言
YOLO小白纯干货分享!!!
一、主要修改代码

二、使用步骤
1. models/common.py:加入要修改的代码, 类ASFFV5 class ASFFV5(nn.Module):
classASFFV5(nn.Module):def__init__(self, level, multiplier=1, rfb=False, vis=False, act_cfg=True):"""
ASFF version for YoloV5 only.
Since YoloV5 outputs 3 layer of feature maps with different channels
which is different than YoloV3
normally, multiplier should be 1, 0.5
which means, the channel of ASFF can be
512, 256, 128 -> multiplier=1
256, 128, 64 -> multiplier=0.5
For even smaller, you gonna need change code manually.
"""super(ASFFV5, self).__init__()
self.level = level
self.dim =[int(1024*multiplier),int(512*multiplier),int(256*multiplier)]#print("dim:",self.dim)
self.inter_dim = self.dim[self.level]if level ==0:
self.stride_level_1 = Conv(int(512*multiplier), self.inter_dim,3,2)#print(self.dim)
self.stride_level_2 = Conv(int(256*multiplier), self.inter_dim,3,2)
self.expand = Conv(self.inter_dim,int(1024*multiplier),3,1)elif level ==1:
self.compress_level_0 = Conv(int(1024*multiplier), self.inter_dim,1,1)
self.stride_level_2 = Conv(int(256*multiplier), self.inter_dim,3,2)
self.expand = Conv(self.inter_dim,int(512*multiplier),3,1)elif level ==2:
self.compress_level_0 = Conv(int(1024*multiplier), self.inter_dim,1,1)
self.compress_level_1 = Conv(int(512*multiplier), self.inter_dim,1,1)
self.expand = Conv(self.inter_dim,int(256*multiplier),3,1)# when adding rfb, we use half number of channels to save memory
compress_c =8if rfb else16
self.weight_level_0 = Conv(
self.inter_dim, compress_c,1,1)
self.weight_level_1 = Conv(
self.inter_dim, compress_c,1,1)
self.weight_level_2 = Conv(
self.inter_dim, compress_c,1,1)
self.weight_levels = Conv(
compress_c*3,3,1,1)
self.vis = vis
defforward(self, x_level_0, x_level_1, x_level_2):#s,m,l"""
# 128, 256, 512
512, 256, 128
from small -> large
"""# print('x_level_0: ', x_level_0.shape)# print('x_level_1: ', x_level_1.shape)# print('x_level_2: ', x_level_2.shape)
x_level_0=x[2]
x_level_1=x[1]
x_level_2=x[0]if self.level ==0:
level_0_resized = x_level_0
level_1_resized = self.stride_level_1(x_level_1)
level_2_downsampled_inter = F.max_pool2d(
x_level_2,3, stride=2, padding=1)
level_2_resized = self.stride_level_2(level_2_downsampled_inter)#print('X——level_0: ', level_2_downsampled_inter.shape)elif self.level ==1:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized = F.interpolate(
level_0_compressed, scale_factor=2, mode='nearest')
level_1_resized = x_level_1
level_2_resized = self.stride_level_2(x_level_2)elif self.level ==2:
level_0_compressed = self.compress_level_0(x_level_0)
level_0_resized = F.interpolate(
level_0_compressed, scale_factor=4, mode='nearest')
x_level_1_compressed = self.compress_level_1(x_level_1)
level_1_resized = F.interpolate(
x_level_1_compressed, scale_factor=2, mode='nearest')
level_2_resized = x_level_2
# print('level: {}, l1_resized: {}, l2_resized: {}'.format(self.level,# level_1_resized.shape, level_2_resized.shape))
level_0_weight_v = self.weight_level_0(level_0_resized)
level_1_weight_v = self.weight_level_1(level_1_resized)
level_2_weight_v = self.weight_level_2(level_2_resized)# print('level_0_weight_v: ', level_0_weight_v.shape)# print('level_1_weight_v: ', level_1_weight_v.shape)# print('level_2_weight_v: ', level_2_weight_v.shape)
levels_weight_v = torch.cat((level_0_weight_v, level_1_weight_v, level_2_weight_v),1)
levels_weight = self.weight_levels(levels_weight_v)
levels_weight = F.softmax(levels_weight, dim=1)
fused_out_reduced = level_0_resized * levels_weight[:,0:1,:,:]+\
level_1_resized * levels_weight[:,1:2,:,:]+\
level_2_resized * levels_weight[:,2:,:,:]
out = self.expand(fused_out_reduced)if self.vis:return out, levels_weight, fused_out_reduced.sum(dim=1)else:return out
2. models/yolo.py:添加 类ASFF_Detect
然后在yolo.py 中 Detect 类下面,添加一个ASFF_Detect类
classASFF_Detect(nn.Module):#add ASFFV5 layer and Rfb
stride =None# strides computed during build
export =False# onnx exportdef__init__(self, nc=80, anchors=(), multiplier=0.5,rfb=False,ch=()):# detection layersuper(ASFF_Detect, self).__init__()
self.nc = nc # number of classes
self.no = nc +5# number of outputs per anchor
self.nl =len(anchors)# number of detection layers
self.na =len(anchors[0])//2# number of anchors
self.grid =[torch.zeros(1)]* self.nl # init grid
self.l0_fusion = ASFFV5(level=0, multiplier=multiplier,rfb=rfb)
self.l1_fusion = ASFFV5(level=1, multiplier=multiplier,rfb=rfb)
self.l2_fusion = ASFFV5(level=2, multiplier=multiplier,rfb=rfb)
a = torch.tensor(anchors).float().view(self.nl,-1,2)
self.register_buffer('anchors', a)# shape(nl,na,2)
self.register_buffer('anchor_grid', a.clone().view(self.nl,1,-1,1,1,2))# shape(nl,1,na,1,1,2)
self.m = nn.ModuleList(nn.Conv2d(x, self.no * self.na,1)for x in ch)# output conv
接着在 yolo.py的parse_model 中把函数放到模型的代码里:
(大概在283行左右)
if m in[Conv, GhostConv, Bottleneck, GhostBottleneck, SPP, DWConv, MixConv2d, Focus, CrossConv, BottleneckCSP,CBAM,ResBlock_CBAM,
C3]:
c1, c2 = ch[f], args[0]if c2 != no:# if not output
c2 = make_divisible(c2 * gw,8)
args =[c1, c2,*args[1:]]if m in[BottleneckCSP, C3]:
args.insert(2, n)# number of repeats
n =1elif m is nn.BatchNorm2d:
args =[ch[f]]elif m is Concat:
c2 =sum([ch[x]for x in f])elif m is ASFF_Detect:
args.append([ch[x]for x in f])ifisinstance(args[1],int):# number of anchors
args[1]=[list(range(args[1]*2))]*len(f)elif m is Contract:
c2 = ch[f]* args[0]**2elif m is Expand:
c2 = ch[f]// args[0]**2elif m is ASFFV5:
c2=args[1]else:
c2 = ch[f]
3.models/yolov5s-asff.yaml
在models文件夹下新建对应的yolov5s-asff.yaml 文件
然后将yolov5s.yaml的内容复制过来,将 head 部分的最后一行进行修改;
将
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5) ]
修改成下面:
[[17,20,23],1, ASFF_Detect,[nc, anchors]],# Detect(P3, P4, P5)]
4.查看网络结构
修改 models/yolo.py --cfg models/yolov5s-asff.yaml
接下来run yolo.py 即可查看网络结构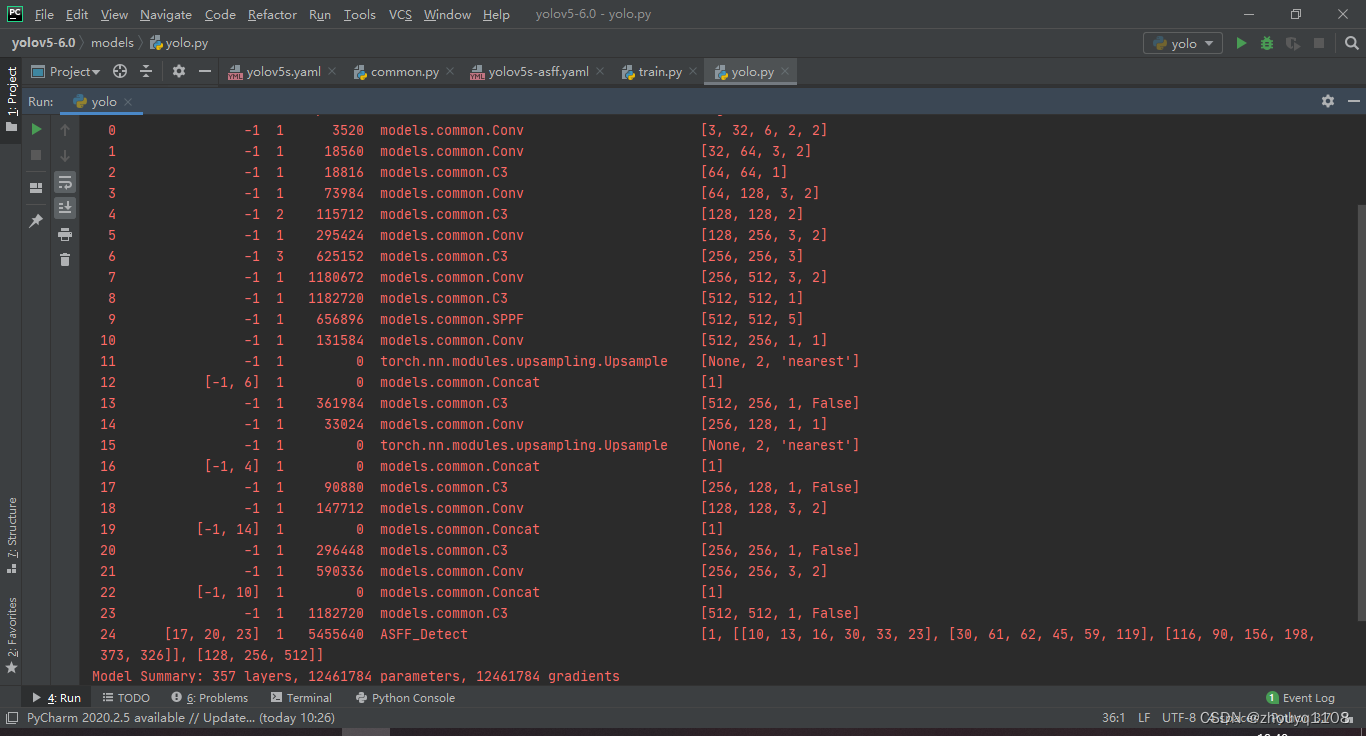
5.将train.py 中 --cfg中的 yaml 文件修改成本文文件即可,开始训练
总结
本人在多个数据集上做了大量实验,针对不同的数据集效果不同,需要大家进行实验。有效果有提升的情况占大多数。
最后,希望能互粉一下,做个朋友,一起学习交流。
本文转载自: https://blog.csdn.net/m0_52587978/article/details/127639341
版权归原作者 zhouyq1108 所有, 如有侵权,请联系我们删除。
版权归原作者 zhouyq1108 所有, 如有侵权,请联系我们删除。