
1:下载paddleocr
develop和release分支都可以,这里以release为例
下载地址:https://github.com/PaddlePaddle/PaddleOCR
paddleocr项目结构如下
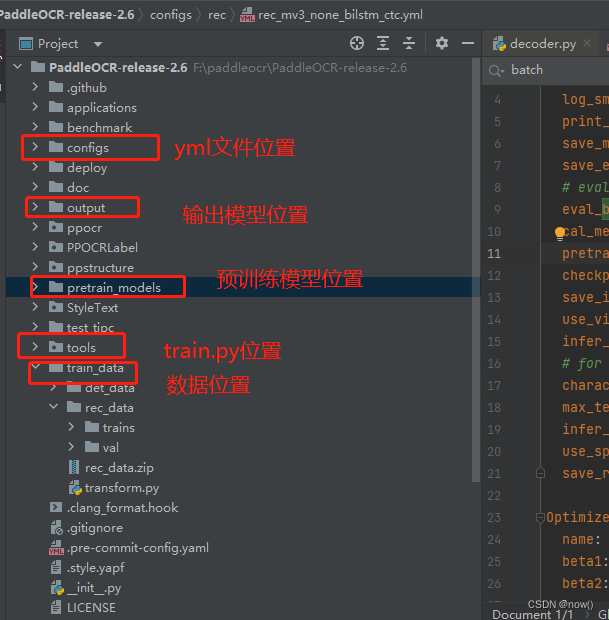
2:跟其他框架一样,我们只需要标注好数据然后配置yml文件,就可以正常训练模型了
首先需要进行数据标注,打开自带的标注工具PPOCRLabel
cd .\PPOCRLabel\
python .\PPOCRLabel.py --lang ch
** 注意:**
1:标注完成后选择文件-导出标注结果,原图和Label.txt在det训练时要用到,这个默认保存的Simpledata格式,不需要转换,只需要分割数据集
2:标注完成后选择文件-导出识别结果,分割出的文字轮廓图像和rec_gt.txt在rec训练时用到,这种需要转换,在使用icdar15数据集不需要,使用mv3时需要转为LMDB格式
3:LMDB转换
使用下述代码进行转换,
数据路径如下
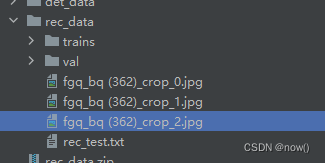
转换命令如下
python .\transform.py --data_root_dir ./rec_data --label_file_paths ./rec_data/rec_test.txt --delimiter tab --lmdb_out_dir ./rec_data/val
4:det模型训练
模型下载
MobileNetV3预训练模型连接:
https://paddle-imagenet-models-name.bj.bcebos.com/MobileNetV3_large_x0_5_pretrained.tar
ResNet18_vd预训练模型连接:
https://paddle-imagenet-models-name.bj.bcebos.com/ResNet18_vd_pretrained.tar
ResNet50_vd预训练模型连接:
https://paddle-imagenet-models-name.bj.bcebos.com/ResNet50_vd_ssld_pretrained.tar
下载完解压到 pretrain_models目录
这里有3种检测的网络结构,百度推荐的时db模型,所以这里用db模型
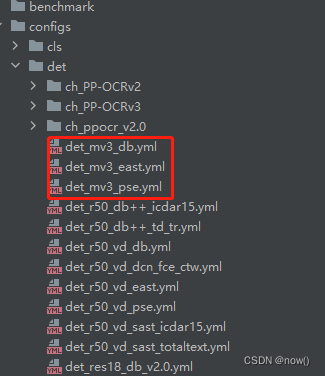
新建个自己的yml文件,把det_mv3_db.yml文字复制进去
需要修改以下内容
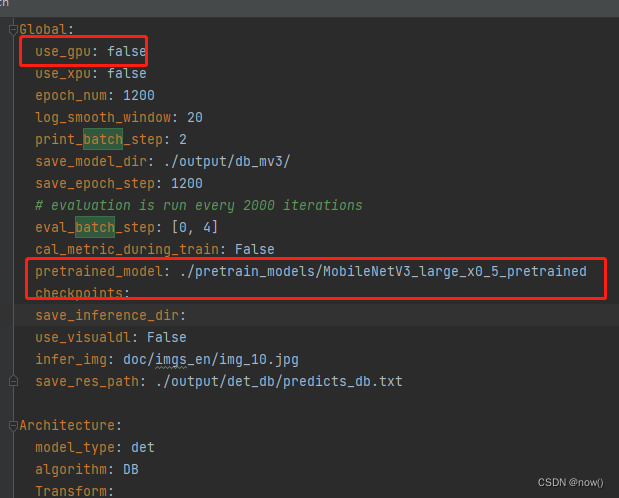
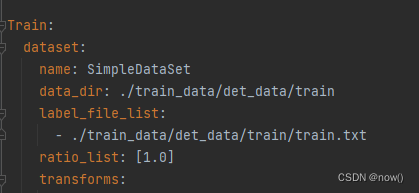
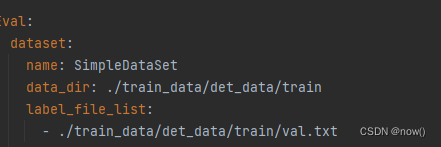
修改完成后可以测试下, 修改tools/train.py把main注释掉,test注释取消
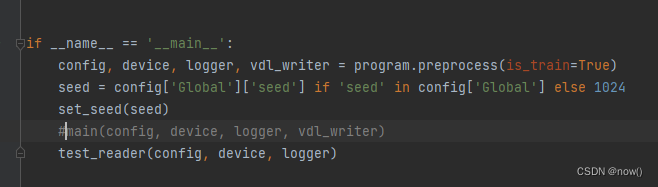
运行下
python tools/train.py -c configs/det/det_mv3_db.yml

出现这个表示模型加载成功,可以进行训练
python .\tools\train.py -c .\configs\det\det_mv3_db.yml 2>&1 | tee train_det.log
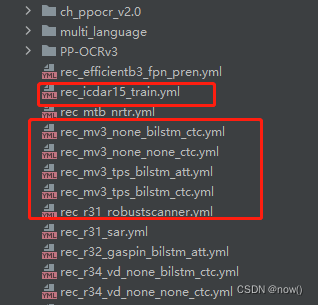
5:训练rec模型
前面已经讲过simpledata转lmdb格式,这里不再赘述
预训练模型下载
这几个模型都是中文模型,只是结构不一样,rec_icdar15_train前面讲过了使用crop_img和rec_gt.txt数据训练就可以,rec_mv3_none_bilstm_ctc.yml,因为这里用到的MV3而且是中文模型,百度推荐的RCNN结构,所以选择这个文件
输入命令训练
python tools/train.py -c configs/rec/rec_mv3_none_bilstm_ctc.yml
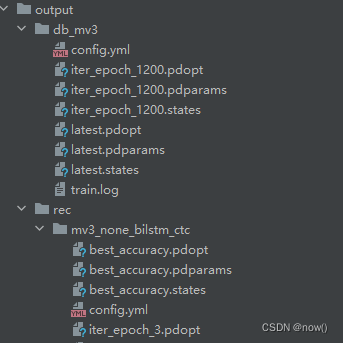
这是输出的模型
6:模型测试和导出inference模型
rec模型导出
python tools/export_model.py -c ./configs/rec/rec_mv3_none_bilstm_ctc.yml -o Global.checkpoints=./output/rec/best_accuracy Global.save_inference_dir=./inference/rec_crnn/
rec模型测试
python tools/infer/predict_rec.py --image_dir="./doc/imgs/00018069.jpg" --rec_model_dir="./inference/rec_crnn/"
det模型导出
python tools/export_model.py -c ./configs/det/det_mv3_db.yml -o Global.checkpoints=./output/det/best_accuracy Global.save_inference_dir=./inference/det_db/
det模型测试
python tools/infer/predict_det.py --image_dir="./doc/imgs/00018069.jpg" --det_model_dir="./inference/det_db/"
综合测试
python tools/infer/predict_system.py --image_dir="./train_data/ic_data/aaa/test/fgq_bq (1)_crop_2.jpg" --det_model_dir="./inference_results/ch_PP-OCRv2_det_infer/" --rec_model_dir
="./inference_results/ch_PP-OCRv2_rec_infer/" --cls_model_dir="./inference_results/ch_ppocr_mobile_v2.0_cls_slim_infer/" --use_angle_cls=True --use_space_char=True --use_gpu=False --rec_char_dict_path="./ppocr/utils/ppocr_keys_v1.
txt"
7:转nb模型(android部署)
安装paddlelite
pip install paddlelite
官方给了转换的demo
# 引用Paddlelite预测库 from paddlelite.lite import * # 1. 创建opt实例 opt=Opt() # 2. 指定输入模型地址 opt.set_model_dir("./inference/rec") # 3. 指定转化类型: arm、x86、opencl、npu opt.set_valid_places("arm") # 4. 指定模型转化类型: naive_buffer、protobuf opt.set_model_type("naive_buffer") # 4. 输出模型地址 opt.set_optimize_out("mobilenetv3_opt") # 5. 执行模型优化 opt.run()
生成的nb模型
可以参考,训练到评估过程讲的很详细(9条消息) 2_paddleOCR训练自己的模型_stefan-567的博客-CSDN博客_paddleocr训练自己的模型
版权归原作者 now() 所有, 如有侵权,请联系我们删除。