
大家好,我是木易,一个持续关注AI领域的互联网技术产品经理,国内Top2本科,美国Top10 CS研究生,MBA。我坚信AI是普通人变强的“外挂”,所以创建了“AI信息Gap”这个公众号,专注于分享AI全维度知识,包括但不限于AI科普,AI工具测评,AI效率提升,AI行业洞察。关注我,AI之路不迷路,2024谷歌一起变强。
一些结论
- 统一的视觉数据表示:Sora模型将各种类型的视觉数据(包括不同持续时间、分辨率和宽高比的视频和图像)转换成统一的表示形式,即时空补丁,便于大规模训练。
- 视频压缩网络:通过降低视觉数据的维度,Sora将原始视频转换为压缩的潜在表示,然后利用这一表示进行高效的视频生成。
- 扩展变换器模型:作为一个扩散模型,Sora利用变换器架构处理噪声补丁和文本提示,预测出原始的“干净”补丁,展现出在视频生成领域的可扩展性。
- 灵活的生成能力:Sora能够生成多种尺寸和格式的视频和图像,支持自由调整生成内容的分辨率、持续时间和宽高比,以适应不同的应用场景。
- 语言理解和内容生成:通过高度描述性的视频说明和利用GPT生成详细的字幕,Sora能够准确理解用户提示并生成高质量的视频内容。
- 编辑和转换能力:Sora不仅支持文本到视频的生成,还能够处理现有的图像或视频输入,执行如视频扩展、风格转换等多样的编辑任务。
- 新兴的模拟能力:训练于大规模数据集的Sora展现出了一些新兴能力,如3D一致性、长程连贯性和物体恒存性,以及能够模拟简单世界互动的能力。
Video generation models as world simulators 视频生成模型作为世界模拟器
We explore large-scale training of generative models on video data. Specifically, we train text-conditional diffusion models jointly on videos and images of variable durations, resolutions and aspect ratios. We leverage a transformer architecture that operates on spacetime patches of video and image latent codes. Our largest model, Sora, is capable of generating a minute of high fidelity video. Our results suggest that scaling video generation models is a promising path towards building general purpose simulators of the physical world.
我们探索了在视频数据上进行大规模训练生成模型。具体来说,我们在不同持续时间、分辨率和宽高比的视频和图像上联合训练了基于文本条件的扩散模型。我们利用了一种在视频和图像潜在代码的时空补丁上操作的变换器架构。我们最大的模型,Sora,能够生成一分钟的高保真视频。我们的结果表明,扩大视频生成模型的规模是构建物理世界的通用模拟器的一个有前景的路径。
This technical report focuses on (1) our method for turning visual data of all types into a unified representation that enables large-scale training of generative models, and (2) qualitative evaluation of Sora’s capabilities and limitations. Model and implementation details are not included in this report.
Much prior work has studied generative modeling of video data using a variety of methods, including recurrent networks, generative adversarial networks, autoregressive transformers, and diffusion models. These works often focus on a narrow category of visual data, on shorter videos, or on videos of a fixed size. Sora is a generalist model of visual data—it can generate videos and images spanning diverse durations, aspect ratios and resolutions, up to a full minute of high definition video.
本技术报告重点介绍了:(1)我们如何将各种类型的视觉数据转换为统一的表示,以实现生成模型的大规模训练;以及(2)对Sora能力和限制的定性评估。模型和实现细节不包含在本报告中。
许多先前的工作已经使用各种方法研究了视频数据的生成模型,包括循环网络、生成对抗网络、自回归变换器和扩散模型。这些工作往往专注于视觉数据的狭窄类别、较短的视频,或固定大小的视频。Sora是一种视觉数据的通才模型——它可以生成持续时间、宽高比和分辨率多样的视频和图像,最长可达一分钟的高清视频。
Turning visual data into patches 将视觉数据转化为补丁
We take inspiration from large language models which acquire generalist capabilities by training on internet-scale data. The success of the LLM paradigm is enabled in part by the use of tokens that elegantly unify diverse modalities of text—code, math and various natural languages. In this work, we consider how generative models of visual data can inherit such benefits. Whereas LLMs have text tokens, Sora has visual patches. Patches have previously been shown to be an effective representation for models of visual data. We find that patches are a highly-scalable and effective representation for training generative models on diverse types of videos and images.
我们从大型语言模型中汲取灵感,这些模型通过在互联网规模的数据上训练获得通才能力。语言大模型范式的成功部分得益于使用令牌,这些令牌巧妙地统一了文本的多种模式——代码、数学以及各种自然语言。在这项工作中,我们考虑视觉数据的生成模型如何继承这些好处。与语言大模型拥有文本令牌不同,Sora拥有视觉补丁。之前的研究已经表明,补丁是视觉数据模型的一种有效表示。我们发现,补丁是一种高度可扩展且有效的表示形式,用于在多种类型的视频和图像上训练生成模型。
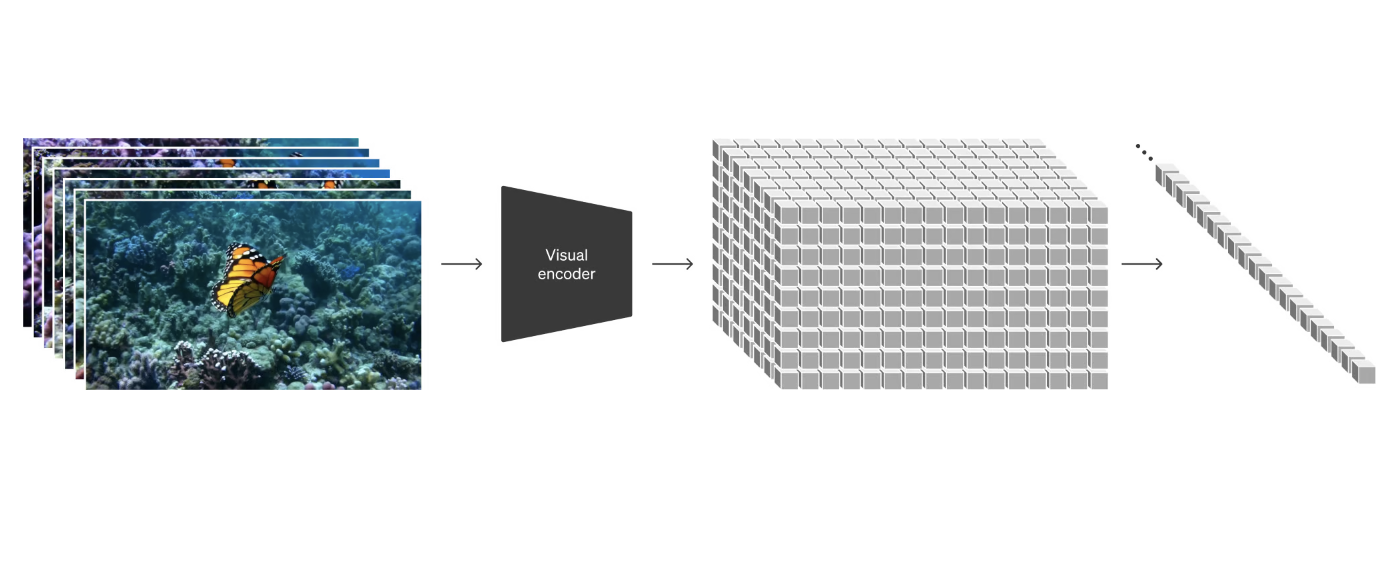
At a high level, we turn videos into patches by first compressing videos into a lower-dimensional latent space, and subsequently decomposing the representation into spacetime patches.
在高层次上,我们首先将视频压缩到低维潜在空间中,然后将其分解为时空补丁,从而将视频转化为补丁。
Video compression network 视频压缩网络
We train a network that reduces the dimensionality of visual data.20 This network takes raw video as input and outputs a latent representation that is compressed both temporally and spatially. Sora is trained on and subsequently generates videos within this compressed latent space. We also train a corresponding decoder model that maps generated latents back to pixel space.
我们训练了一个降低视觉数据维度的网络。该网络以原始视频为输入,输出一个在时间和空间上都被压缩的潜在表示。Sora在这个压缩的潜在空间内进行训练,并随后生成视频。我们还训练了一个相应的解码器模型,将生成的潜在表示映射回像素空间。
Spacetime Latent Patches 时空潜在补丁
Given a compressed input video, we extract a sequence of spacetime patches which act as transformer tokens. This scheme works for images too since images are just videos with a single frame. Our patch-based representation enables Sora to train on videos and images of variable resolutions, durations and aspect ratios. At inference time, we can control the size of generated videos by arranging randomly-initialized patches in an appropriately-sized grid.
给定一个压缩的输入视频,我们提取一系列的时空补丁,这些补丁作为变换器的令牌。这种方案也适用于图像,因为图像只是单帧的视频。我们基于补丁的表示使得Sora能够在不同分辨率、持续时间和宽高比的视频和图像上进行训练。在推理时,我们可以通过在适当大小的网格中排列随机初始化的补丁来控制生成视频的大小。
Scaling transformers for video generation 为视频生成扩展变换器
Sora is a diffusion model; given input noisy patches (and conditioning information like text prompts), it’s trained to predict the original “clean” patches. Importantly, Sora is a diffusion transformer. Transformers have demonstrated remarkable scaling properties across a variety of domains, including language modeling, computer vision, and image generation.
Sora是一个扩散模型;给定输入的噪声补丁(和条件信息,如文本提示),它被训练用于预测原始的“干净”补丁。重要的是,Sora是一个扩散变换器。变换器在多个领域展现了显著的扩展属性,包括语言建模、计算机视觉和图像生成。

In this work, we find that diffusion transformers scale effectively as video models as well. Below, we show a comparison of video samples with fixed seeds and inputs as training progresses. Sample quality improves markedly as training compute increases.
在这项工作中,我们发现扩散变换器作为视频模型也能有效扩展。下面,我们展示了固定种子和输入的视频样本在训练过程中的对比。随着训练计算量的增加,样本质量明显提高。

Variable durations, resolutions, aspect ratios 可变持续时间、分辨率、宽高比
Past approaches to image and video generation typically resize, crop or trim videos to a standard size – e.g., 4 second videos at 256x256 resolution. We find that instead training on data at its native size provides several benefits.
过去对图像和视频生成的方法通常会将视频调整大小、裁剪或裁切到标准尺寸——例如,256x256分辨率的4秒视频。我们发现,直接在数据的原始尺寸上进行训练提供了几个好处。
Sampling flexibility 采样灵活性
Sora can sample widescreen 1920x1080p videos, vertical 1080x1920 videos and everything inbetween. This lets Sora create content for different devices directly at their native aspect ratios. It also lets us quickly prototype content at lower sizes before generating at full resolution—all with the same model.
Sora可以采样宽屏1920x1080p视频、竖屏1080x1920视频以及它们之间的所有内容。这使得Sora能够直接以不同设备的原生宽高比创建内容。它也让我们能够在全分辨率生成之前,快速原型低尺寸的内容——所有这些都使用同一个模型。
Improved framing and composition 改进的构图和布局
We empirically find that training on videos at their native aspect ratios improves composition and framing. We compare Sora against a version of our model that crops all training videos to be square, which is common practice when training generative models. The model trained on square crops (left) sometimes generates videos where the subject is only partially in view. In comparison, videos from Sora (right)s have improved framing.
我们通过实验发现,直接在视频的原生宽高比上进行训练,可以改善构图和布局。我们将Sora与一个将所有训练视频裁剪为正方形的模型版本进行了比较,这在训练生成模型时是常见做法。在正方形裁剪(左侧)上训练的模型有时会生成主体只部分出现在视野中的视频。相比之下,Sora(右侧)的视频具有改进的构图。
Language understanding 语言理解
Training text-to-video generation systems requires a large amount of videos with corresponding text captions. We apply the re-captioning technique introduced in DALL·E 330 to videos. We first train a highly descriptive captioner model and then use it to produce text captions for all videos in our training set. We find that training on highly descriptive video captions improves text fidelity as well as the overall quality of videos.
Similar to DALL·E 3, we also leverage GPT to turn short user prompts into longer detailed captions that are sent to the video model. This enables Sora to generate high quality videos that accurately follow user prompts.
训练文本到视频生成系统需要大量带有对应文字说明的视频。我们应用了在DALL·E 3中引入的重新标注技术到视频上。我们首先训练一个高度描述性的标题生成模型,然后用它为我们训练集中的所有视频产生文本说明。我们发现,训练在高度描述性的视频说明上,可以提高文本的忠实度以及视频的整体质量。
类似于DALL·E 3,我们也利用GPT将简短的用户提示转换成更长的详细说明,然后发送给视频模型。这使得Sora能够生成高质量的视频,准确地遵循用户的提示。
Prompting with images and videos 使用图像和视频进行提示
All of the results above and in our landing page show text-to-video samples. But Sora can also be prompted with other inputs, such as pre-existing images or video. This capability enables Sora to perform a wide range of image and video editing tasks—creating perfectly looping video, animating static images, extending videos forwards or backwards in time, etc.
上述所有结果以及我们的登录页面都展示了文本到视频的样本。但Sora也可以用其他输入进行提示,如现有的图像或视频。这一能力使Sora能够执行广泛的图像和视频编辑任务——创建完美循环的视频、为静态图像添加动画、向前或向后扩展视频等等。
Animating DALL·E images 为DALL·E图像添加动画
Sora is capable of generating videos provided an image and prompt as input. Below we show example videos generated based on DALL·E 231 and DALL·E 330 images.
Sora能够基于图像和提示生成视频。下面我们展示了基于DALL·E 2和DALL·E 3图像生成的示例视频。
Extending generated videos 扩展生成的视频
Sora is also capable of extending videos, either forward or backward in time. Below are four videos that were all extended backward in time starting from a segment of a generated video. As a result, each of the four videos starts different from the others, yet all four videos lead to the same ending.
We can use this method to extend a video both forward and backward to produce a seamless infinite loop.
Sora也能够向前或向后扩展视频。下面是四个视频,它们都是从生成视频的一个片段开始向后扩展的。结果是,这四个视频的开始各不相同,但都以相同的结局结束。
我们可以使用这种方法向前和向后扩展视频,以产生无缝的无限循环。
Video-to-video editing 视频到视频编辑
Diffusion models have enabled a plethora of methods for editing images and videos from text prompts. Below we apply one of these methods, SDEdit,32 to Sora. This technique enables Sora to transform the styles and environments of input videos zero-shot.
扩散模型已经使得从文本提示编辑图像和视频的方法层出不穷。下面我们将这些方法之一,SDEdit,应用到Sora上。这项技术使得Sora能够零次尝试转换输入视频的风格和环境。
Connecting videos 连接视频
We can also use Sora to gradually interpolate between two input videos, creating seamless transitions between videos with entirely different subjects and scene compositions. In the examples below, the videos in the center interpolate between the corresponding videos on the left and right.
我们还可以使用Sora逐渐在两个输入视频之间插值,创建完全不同的主题和场景组合视频之间的无缝过渡。在下面的例子中,中间的视频在左右对应的视频之间进行插值。
Image generation capabilities 图像生成能力
Sora is also capable of generating images. We do this by arranging patches of Gaussian noise in a spatial grid with a temporal extent of one frame. The model can generate images of variable sizes—up to 2048x2048 resolution.
Sora也能够生成图像。我们通过将高斯噪声的补丁排列在一个具有单帧时间长度的空间网格中来实现这一点。模型可以生成不同尺寸的图像——最高分辨率可达2048x2048。

Emerging simulation capabilities 新兴的模拟能力
We find that video models exhibit a number of interesting emergent capabilities when trained at scale. These capabilities enable Sora to simulate some aspects of people, animals and environments from the physical world. These properties emerge without any explicit inductive biases for 3D, objects, etc.—they are purely phenomena of scale.
我们发现,当在大规模上训练时,视频模型展现出许多有趣的新兴能力。这些能力使Sora能够模拟物理世界中的某些人、动物和环境方面。这些属性的出现,并没有对3D、对象等任何显式的归纳偏见——它们完全是规模现象的产物。
3D consistency. 3D一致性。
Sora can generate videos with dynamic camera motion. As the camera shifts and rotates, people and scene elements move consistently through three-dimensional space.
Sora能够生成具有动态相机运动的视频。随着相机的移动和旋转,人物和场景元素在三维空间中一致地移动。
Long-range coherence and object permanence. 长程连贯性和物体恒存性。
A significant challenge for video generation systems has been maintaining temporal consistency when sampling long videos. We find that Sora is often, though not always, able to effectively model both short- and long-range dependencies. For example, our model can persist people, animals and objects even when they are occluded or leave the frame. Likewise, it can generate multiple shots of the same character in a single sample, maintaining their appearance throughout the video.
对于视频生成系统来说,一个重大挑战一直是在采样长视频时保持时间上的一致性。我们发现Sora通常(虽不总是)能够有效地模拟短程和长程依赖。例如,我们的模型可以持续存在人、动物和物体,即使它们被遮挡或离开画面。同样,它可以在单个样本中生成同一角色的多个镜头,贯穿整个视频维持他们的外观。
Interacting with the world. 与世界互动。
Sora can sometimes simulate actions that affect the state of the world in simple ways. For example, a painter can leave new strokes along a canvas that persist over time, or a man can eat a burger and leave bite marks.
Sora有时可以模拟以简单方式影响世界状态的动作。例如,画家可以在画布上留下新的笔触,随时间持续存在,或者一个人可以吃汉堡并留下咬痕。
Simulating digital worlds. 模拟数字世界。
Sora is also able to simulate artificial processes–one example is video games. Sora can simultaneously control the player in Minecraft with a basic policy while also rendering the world and its dynamics in high fidelity. These capabilities can be elicited zero-shot by prompting Sora with captions mentioning “Minecraft.”
These capabilities suggest that continued scaling of video models is a promising path towards the development of highly-capable simulators of the physical and digital world, and the objects, animals and people that live within them.
Sora也能够模拟人造过程——一个例子是视频游戏。Sora可以同时控制《Minecraft》中的玩家以基本策略,同时以高保真度渲染世界及其动态。这些能力可以通过用提及“Minecraft”的字幕提示Sora来零次激发。
这些能力表明,继续扩大视频模型的规模是朝着开发高能力的物理和数字世界模拟器的有希望的路径,以及居住在其中的物体、动物和人。
Discussion 讨论
Sora currently exhibits numerous limitations as a simulator. For example, it does not accurately model the physics of many basic interactions, like glass shattering. Other interactions, like eating food, do not always yield correct changes in object state. We enumerate other common failure modes of the model—such as incoherencies that develop in long duration samples or spontaneous appearances of objects—in our landing page.
We believe the capabilities Sora has today demonstrate that continued scaling of video models is a promising path towards the development of capable simulators of the physical and digital world, and the objects, animals and people that live within them.
作为一个模拟器,Sora目前展现出许多限制。例如,它并不精确地模拟许多基本互动的物理效应,比如玻璃破碎。其他互动,如吃食物,不总是产生正确的物体状态变化。我们在我们的登录页面中列举了模型的其他常见失败模式——比如在长时间样本中发展的不连贯性或物体的自发出现。
我们相信,Sora今天所拥有的能力表明,继续扩大视频模型的规模是朝着开发能够模拟物理和数字世界及其中的物体、动物和人的有能力的模拟器的有希望的路径。
精选推荐
- ChatGPT和文心一言哪个更好用?一道题告诉你答案!
- 白嫖GPT4,Dalle3和GPT4V - 字节开发的Coze初体验!附教程及提示词Prompt
- 字节开发的Coze进阶使用:用免费的GPT4打造一个专属的新闻播报机器人!附教程及提示词Prompt
- 盘点那些免费的AI对话工具(国内篇):国内TOP3 AI聊天机器人产品介绍
- AI聊天机器人,一个就够了:文心一言、讯飞星火、通义千问AI聊天机器人深度对比(一)
- AI聊天机器人,一个就够了:文心一言、讯飞星火、通义千问AI聊天机器人深度对比(二)
- 人工智能时代的领跑者:你必须了解的全球三大AI聊天机器人!
- 抖音出的AI工具火了!自动生成抖音文案,一键脚本数字人成片!
- 2024年了你还在用百度翻译?手把手教会你使用AI翻译!一键翻译网页和PDF文件!
- 腾讯AI虽迟但到:腾讯文档AI开启公测!附申请地址及详细教程!
都读到这里了,点个赞鼓励一下吧😊👍👍👍。关注我,AI之路不迷路,原创技术文章第一时间推送🤖。
版权归原作者 木易AI信息差 所有, 如有侵权,请联系我们删除。