
YOLO系列目标检测算法目录 - 文章链接
- YOLO系列目标检测算法总结对比- 文章链接
- YOLOv1- 文章链接
- YOLOv2- 文章链接
- YOLOv3- 文章链接
- YOLOv4- 文章链接
- Scaled-YOLOv4- 文章链接
- YOLOv5- 文章链接
- YOLOv6- 文章链接
- YOLOv7- 文章链接
- PP-YOLO- 文章链接
- PP-YOLOv2- 文章链接
- YOLOR- 文章链接
- YOLOS- 文章链接
- YOLOX- 文章链接
- PP-YOLOE- 文章链接
本文总结:
- Backbone设计:多分支比单分支性能好但耗时增加,借鉴RepVGG思路提出EfficientRep。对于小型模型,训练部分使用RepBlock,推理时合并多分支为RepConv。对于大型模型,直接扩展RepBlock会造成计算成本指数级增长,于是提出了SCPStackRep Block,用在训练部分,在推理时合并成RepConv堆。
- Neck设计:借鉴YOLOv4/v5的PAN,提出了Rep-PAN,将PAN的CSPBlock替换为RepBlock(小型模型)或者CSPStackBlock(大型模型),可根据需求调整相应的宽度和深度。
- Head设计:采用decoupled head(表示为DH)+ anchor-free + hybrid channel(HC)形式。
- 激活函数SiLU精度高成本低,但部署有TensorRT时ReLU有更大的速度优势,最终选择使用RepConv/ReLU在YOLOv6-N/T/S/M中,用于更高的推理速度;在大型型号YOLOv6-L中使用Conv/SiLU组合加速训练并提高性能。
- 采用ATSS作为训练初期阶段的warm-up标签分配策略,之后使用TAL进行标签分配。
- 分类loss使用VariFocal Loss(VFL);对于框回归,YOLOv6-N和YOLOv 6-T使用SIoU Loss,其余使用GIoU Loss,另外YOLOv6-M/L中加入Dostronition Focal Loss(DFL);取消Object Loss。
- 更多的训练轮次能得到更好的收敛效果,所以训练周期采用400个epoch。
- 推理时图片resize操作会在四周填充灰色的padding,这种操作有助于检测图像边缘目标,但会降低推理速度。发现这可能和训练时的Mosaic数据增强有关,实验结果表明,当在训练最后一轮关闭Mosaic(称为fade strategy),使用灰度边界填充会达到最佳效果。
- 训练后量化(post-training quantization,PTQ)和量化感知训练(quantization-aware training,QAT)。
YOLOv6各算法中各部件总结如下:
算法名称BackboneNeckHead卷积/激活函数cls lossreg loss深度系数宽度系数标签分配epochsYOLOv6nEfficientRepRepPANNeckEffiDeHeadRepConv/ReLUVFL
SIoU
DFL=False
0.330.25
3epoch前:ATSS
其他epoch:TAL
400YOLOv6tEfficientRepRepPANNeckEffiDeHeadRepConv/ReLUVFL
SIoU
DFL=False
0.330.375
3epoch前:ATSS
其他epoch:TAL
400YOLOv6sEfficientRepRepPANNeckEffiDeHeadRepConv/ReLUVFL
GIoU
DFL=False
0.330.50
3epoch前:ATSS
其他epoch:TAL
400YOLOv6m
CSPRepBackbone
(csp_e=2/3)
CSPRepPANNeck
(csp_e=2/3)
EffiDeHeadRepConv/ReLUVFL
GIoU
DFL=True
0.600.75
3epoch前:ATSS
其他epoch:TAL
400YOLOv6l
CSPRepBackbone
(csp_e=1/2)
CSPRepPANNeck
(csp_e=1/2)
EffiDeHeadConv/SiLUVFL
GIoU
DFL=True
1.01.0
3epoch前:ATSS
其他epoch:TAL
400
深度学习知识点总结
专栏链接:
https://blog.csdn.net/qq_39707285/article/details/124005405
**
此专栏主要总结深度学习中的知识点,从各大数据集比赛开始,介绍历年冠军算法;同时总结深度学习中重要的知识点,包括损失函数、优化器、各种经典算法、各种算法的优化策略Bag of Freebies (BoF)等。
**
本章目录
8. YOLO系列目标检测算法-YOLOv6
论文《YOLOv6: A Single-Stage Object Detection Framework for Industrial Applications》2022.9.7。
8.1 概述
YOLOv6 是美团视觉智能部研发的一款目标检测框架,致力于工业应用。本框架同时专注于检测的精度和推理效率,在工业界常用的尺寸模型中:YOLOv6-nano 在 COCO 上精度可达 35.0% AP,在 T4 上推理速度可达 1242 FPS;YOLOv6-s 在 COCO 上精度可达 43.1% AP,在 T4 上推理速度可达 520 FPS。在部署方面,YOLOv6 支持 GPU(TensorRT)、CPU(OPENVINO)、ARM(MNN、TNN、NCNN)等不同平台的部署,极大地简化工程部署时的适配工作。目前,项目已开源至Github,传送门:YOLOv6。
精度与速度远超 YOLOv5 和 YOLOX 的新框架。目标检测作为计算机视觉领域的一项基础性技术,在工业界得到了广泛的应用,其中 YOLO 系列算法因其较好的综合性能,逐渐成为大多数工业应用时的首选框架。至今,业界已衍生出许多 YOLO 检测框架,其中以 YOLOv5、YOLOX 和 PP-YOLOE最具代表性,但在实际使用中,我们发现上述框架在速度和精度方面仍有很大的提升的空间。基于此,我们通过研究并借鉴了业界已有的先进技术,开发了一套新的目标检测框架——YOLOv6。该框架支持模型训练、推理及多平台部署等全链条的工业应用需求,并在网络结构、训练策略等算法层面进行了多项改进和优化,在 COCO 数据集上,YOLOv6 在精度和速度方面均超越其他同体量算法,相关结果如下图 1 所示: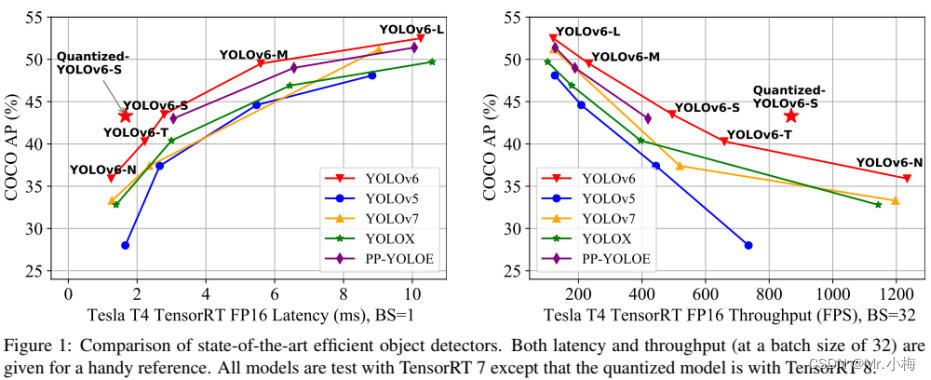
上图展示了不同尺寸网络下各检测算法的性能对比,曲线上的点分别表示该检测算法在不同尺寸网络下(s/tiny/nano)的模型性能,从图中可以看到,YOLOv6 在精度和速度方面均超越其他 YOLO 系列同体量算法。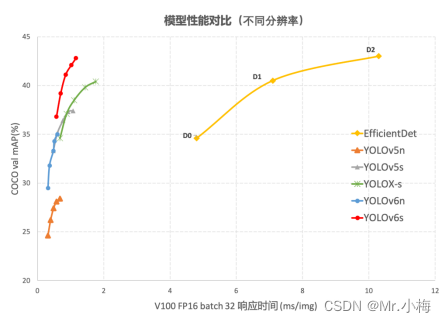
上图展示了输入分辨率变化时各检测网络模型的性能对比,曲线上的点从左往右分别表示图像分辨率依次增大时(384/448/512/576/640)该模型的性能,从图中可以看到,YOLOv6 在不同分辨率下,仍然保持较大的性能优势。
本小节《概述》转自URL
8.2 YOLO系列问题分析及解决
8.2.1 问题分析
根据经验分析以往YOLO系列及最新算法,观察到了几个重要因素,这些因素促使重新完善YOLO框架:
- RepVGG的重参数化算法是一种优越的技术,尚未在检测中得到充分利用。而且,RepVGG Block的模型缩放不切实际,本文认为小型和大型网络之间的网络设计保持一致是不必要的。普通单路径架构对于小型网络是更好的选择,但是对于更大的模型,参数的指数增长和单路径架构的计算成本使其不可行;
- 基于重参数化的检测器的量化也需要细致的处理,否则,由于其在训练和推理期间的不同处理,很难处理性能退化的问题。
- 以前的算法[YOLOX,YOLOv5,YOLOv7,PP-YOLOE]较少关注部署,其延迟通常在高成本机器(如V100)上进行比较。在实际服务环境中,存在硬件差距。
- 先进的特定策略,如标签分配和损失函数设计,考虑到架构差异,需要进一步验证使用;
- 对于部署,可以对训练策略进行调整,以提高准确性性能,但不增加推理成本,如知识蒸馏。
8.2.2 解决办法
通过对以上问题的分析,提出了YOLOv6,在精度和速度方面实现了迄今为止最好的折衷。另外为了提高推理速度而不使性能有有太多退化,研究了最前沿的量化方法,包括训练后量化(post-training quantization,PTQ)和量化感知训练(quantization-aware training,QAT),并将其整合在YOLOv6中。
YOLOv6的关键点总结如下:
- 为不同场景中的工业应用量身定制了一系列不同规模的网络。不同规模的架构各不相同,以实现最佳的速度和精度权衡,其中小型模型采用简单的单路径backbone,大型模型构建在高效的多分支块上。
- 为YOLOv6在分类任务和回归任务中都加入了自蒸馏策略。同时,动态调整来自teacher和标签的信息,以帮助student模型能在所有训练阶段更有效地学习知识。
- 广泛验证了比较先进的技术,例如标签分配、损失函数和数据增强技术等,并有选择地采用它们以进一步提高性能。
- 在RepOptimizer优化器和通道蒸馏的帮助下,对检测任务的量化方案进行了改革,得到了一个具有43.3%COCO AP和869FPS吞吐量的快速准确检测器(batchsize为32)。
8.3 关键技术介绍
YOLOv6主要从以下几个方面进行改进,网络设计、标签分配、损失函数、数据增强、工业便利化改进、量化和部署。
8.3.1 网络设计
一阶段目标检测算法通常由backbone、neck和head组成。
backbone主要决定特征表示能力,同时,其设计对推理效率有着至关重要的影响,因为它承担了大量的计算成本。
neck用于将低层物理特征与高层语义特征聚合,然后在各级建立金字塔特征图。
head由多个卷积层组成,并根据neck部的多级特征预测最终检测结果。从结构的角度来看,它可以分为anchor-based和anchor-free,或者更确切地说,分为参数耦合head和参数解耦head。
在YOLOv6中,提出了两个缩放的可重参数化backbone和neck,以适应不同尺寸的模型,以及一个**具有混合通道(hybrid-channel)策略的高效解耦head(decoupled head)**。总体结构图如图2所示。
8.3.1.1 backbone
backbone的设计中,多分支的网络(ResNet,DenseNet,GoogLeNet,)相比单分支(ImageNet,VGG)的通常能够有更好的分类性能。但是,它通常伴随着并行性的降低,并导致推理延迟的增加。相反,像VGG这样的普通单路径网络具有高并行性和较少内存占用的优点,从而导致更高的推理效率。最近在RepVGG中,提出了一种结构重参数化方法,将训练时多分支拓扑与推理时平面结构解耦(训练时是多分支,推理时转化为单分支),以实现更好的速度-精度权衡。
RepVGG融合过程如下图所示: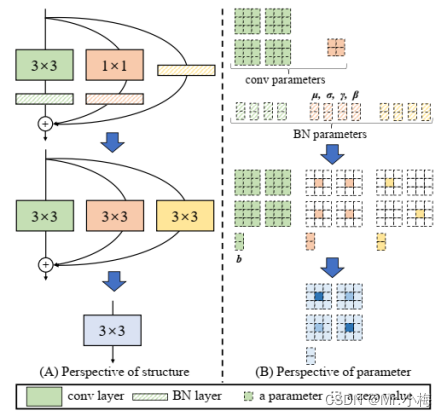
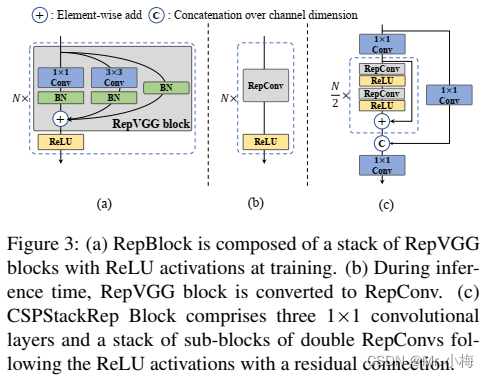
根据以上分析的鼓舞,设计了一个高效的重参数化的backbone,命名为EfficientRep。对于小型模型,backbone的主要组成部分是训练阶段的RepBlock,如图3(a)所示。并且在推理阶段,每个RepBlock被转换为具有ReLU激活函数的3×3卷积层的堆叠(表示为RepConv),如图3(b)所示。通常,3×3卷积在主流GPU和CPU上高度优化,并且具有更高的计算密度。因此,主干网的效率是充分的利用硬件的计算能力,从而显著降低了推理延迟,同时增强了表示能力。
然而,我们注意到,随着模型尺寸的进一步扩展,单路径普通网络的计算成本和参数数量呈指数增长。为了更好地平衡计算成本和准确性,修改了CSPStackRep Block以构建中大型网络的backbone。如图3(c)所示,CSPStackRep Block由三个1×1卷积层和由两个具有残差连接的RepVGG block(训练阶段)或RepConv(推理阶段)组成的子块堆叠组成。此外,采用了CSP来提高性能,而不需要过多的计算成本。与CSPRepResStage(PP-YOLOE)相比,它具有更简洁的外观,并考虑了准确性和速度之间的平衡。
EfficientRep Backbone具体设计结构图如下图所示: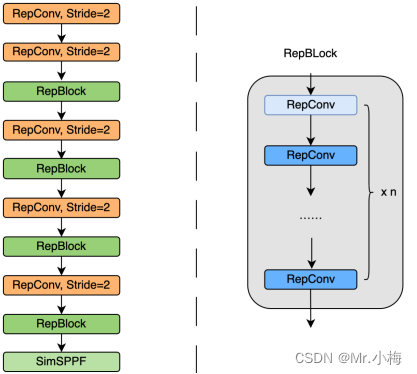
该插图转自URL
8.3.1.2 neck
采用来自YOLOv4和YOLOv5的改进的PAN结构作为我们检测neck的基础。此外,将YOLOv5中使用的CSPBlock替换为RepBlock(适用于小型模型)或CSPStackRep Block(用于大型模型),并相应调整宽度和深度。YOLOv6的neck表示为Rep-PAN。结构图如下图所示: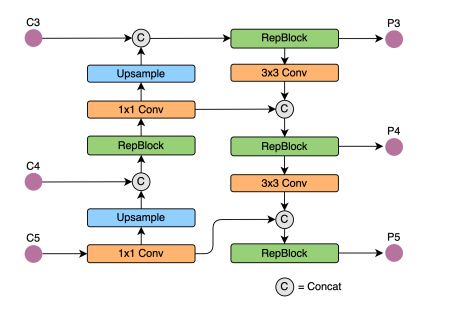
该插图转自URL
8.3.1.3 head
Efficient decoupled head:YOLOv5的检测头是一个耦合头,在分类和定位分支之间共享参数,而FCOS和YOLOX中的对应部分将两个分支解耦,并在每个分支中引入另外两个3×3卷积层以提高性能。
在YOLOv6中,采用了一种混合通道(hybrid-channel)策略,以构建更高效的解耦头。具体而言,将中间3×3卷积层的数量减少到只有一个。head的宽度由backbone和neck的宽度乘数共同缩放。这些修改进一步降低了计算成本,以实现更低的推理延迟。
Anchor-free:anchor-free检测器因其更好的泛化能力和解码预测结果的简单性而脱颖而出。其后处理的时间成本显著降低。有两种类型的anchor-free检测器:point-based(YOLOX,FCOS)和keypoing-based(CenterNet)。在YOLOv6中,采用了anchor-free point-based范式。
8.3.1.4 实验
8.3.1.4.1 backbone和neck
探讨了单路径结构和多分支结构对backbone和neck的影响,以及CSPStackRep块的通道系数(channel coefficient表示为CC)。本节实验所有模型均采用TAL作为标签分配策略,VFL作为分类损失,GIoU和DFL作为回归损失。结果如表2所示。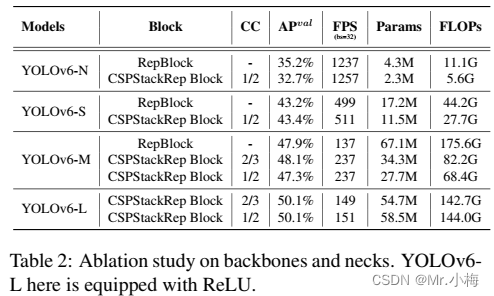
从结果可以发现,不同规模的模型的最佳网络结构应该用不同的解决方案。
对于YOLOv6-N,单路径结构在精度和速度方面都优于多分支结构。尽管单路径结构具有比多分支结构更多的FLOPs和参数,由于相对较低的内存占用和较高的并行度,它也可以运行的更快。
对于YOLOv6-S,这两种block的结果差不多。当涉及到更大的模型时,多分支结构在精度和速度上实现了更好的性能。最后,为YOLOv6-M选择通道系数为2/3的多分支,为YOLOv6-L选择通道系数1/2的多分支。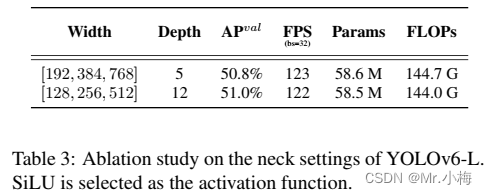
此外,还研究了neck的宽度和深度对YOLOv6-L的影响。表3中的结果表明,**在相同速度下,细长neck的性能比宽浅neck好0.2%**。
8.3.1.4.2 卷积层和激活函数的组合
YOLO系列激活函数各不相同,如ReLU、LReLU、Swish、SiLU、Mish等。在这些激活函数中,SiLU是使用最多的。一般来说,SiLU的精度更高,不会造成太多额外的计算成本。然而,在工业应用中,特别是在部署具有TensorRT加速的模型时,ReLU具有更大的速度优势,因为它融合到了卷积中。
此外,进一步验证了RepConv/普通卷积(表示为Conv)和ReLU/SiLU/LReLU组合在不同大小网络中的有效性,以实现更好的折衷。如表4所示,带有SiLU的Conv在精度上表现最佳,而RepConv和ReLU的组合实现了更好的权衡。所以建议用户在对延迟敏感的应用程序中使用RepConv和ReLU。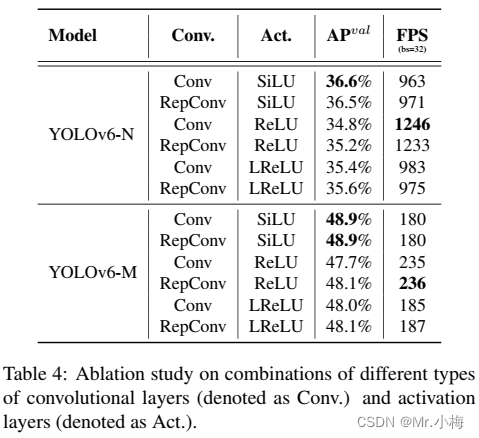
本文选择使用RepConv/ReLU在YOLOv6-N/T/S/M中,用于更高的推理速度;在大型型号YOLOv6-L中使用Conv/SiLU组合加速训练并提高性能。
8.3.1.4.3 其他设计
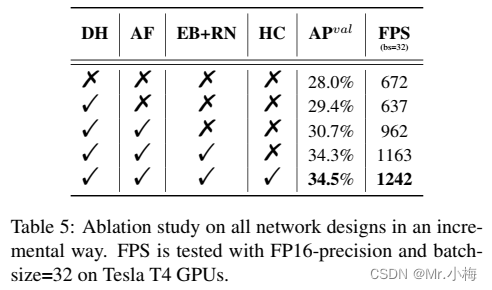
选择YOLOv5-N作为基线,并逐步添加其他组件。结果如表5所示。
- 使用解耦头(decoupled head,表示为DH),模型精度提高了1.4%,时间成本增加了5%。
- 使用anchor-free模式比anchor-based的快51%,因为其少3倍多的预定义锚,这样输出的维度就更少。
- backbone(EfficientRep backbone)和neck(Rep-PAN-neck)的统一修改(表示为EB+RN)带来了3.6%的AP改进,运行速度提高了21%。最后,优化的解耦头(hybrid channel,混合通道,HC)在精度和速度上分别提高了0.2%的AP和6.8%的FPS。
8.3.2 标签分配
标签分配负责在训练阶段将标签分配给预定义的anchors。以前的算法提出的各种标签分配策略,从简单的基于IoU的策略和内部GT方法(FCOS)到其他更复杂的方案。(随后会有专门一遍文章来讲标签分配。)接下来介绍SimOTA和Task alignment learning。
SimOTA:OTA将目标检测中的标签分配视为最佳传输的问题。它从全局角度定义了每个GT目标的正/负训练样本。SimOTA是OTA的简化版本,它减少了额外的超参数并保持了性能。在YOLOv6的早期版本中,SimOTA被用作标签分配方法。然而,在实践中,发现引入SimOTA会减缓训练过程。而且,陷入不稳定训练的情况经常出现。因此,本文设计了一个SimOTA的替代品。
Task alignment learning:任务对齐学习(TAL)在TOOD中首次提出,其中设计了分类分数和预测框质量的统一度量。IoU度量被替换为分配目标标签。在一定程度上,任务(分类和框回归)的错位问题得到了缓解。TOOD的另一个主要贡献是关于任务对齐头(task-aligned head,T-head)。T-head堆叠卷积层以构建交互特征,在其上使用任务对齐预测器(Task-Aligned-Predictor,TAP)。PP-YOLOE通过将T-head中的层注意力替换为轻量级ESE attention,形成ET-head。然而,我们发现ET-head会降低我们模型中的推理速度,并且不会带来精度增益。因此,我们保留了高效去耦头的设计。
此外,我们观察到TAL比SimOTA能带来更多的性能改进,并能稳定训练。因此,我们采用TAL作为YOLOv6中的默认标签分配策略。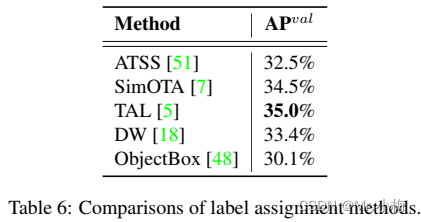
在表6中,分析了主流标签分配策略的有效性。在YOLOv6N上进行了实验。如预期的,可以观察到SimOTA和TAL是最佳两种策略。与ATSS相比,SimOTA可使AP增加2.0%,TAL可使AP比SimOTA高0.5%。考虑到TAL的稳定训练和更好的精度性能,我们采用TAL作为标签分配策略。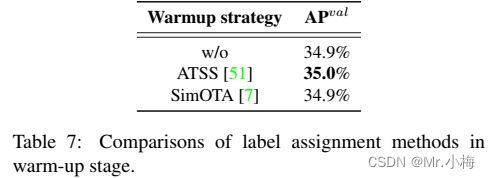
此外,TOOD的实现采用ATSS作为早期训练阶段的warm-up标签分配策略。我们还保留了warm-up策略,并对其进行了进一步的探索。详细信息如表7所示,可以发现,在没有warm-up或通过其他策略(即SimOTA)预热的情况下,它也可以实现类似的性能。
8.3.3 损失函数
详细的损失函数介绍详见文章《深度学习知识点总结:损失函数总结_Mr.小梅的博客-CSDN博客_深度学习损失函数总结》。
目标检测包括两个自任务:分类和定位,对应于两个损失函数:classification loss和box regression loss。对于每个子任务,近年来提出了各种损失函数。在本节中,将介绍这些损失函数,并描述如何为YOLOv6选择最佳损失函数。
在目标检测框架中,损失函数由分类损失、框回归损失和可选对象损失组成,其可公式如下: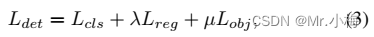
其中L_cls、L_reg和L_obj分别分类损失、回归损失和对象损失。λ和µ是超参数。
8.3.3.1 Classification Loss
改进分类器的性能是优化检测器的关键部分。Focal Loss修改了传统的交叉熵损失,以解决正负样本或难易样本之间的类不平衡问题。为了解决训练和推理之间质量估计和分类的不一致使用,Quality Focal Loss(QFL)进一步扩展了Focal Loss,将分类分数和本地化质量联合表示用于分类监督。而VariFocal Loss(VFL)源于Focal Loss,但它不对称地处理正样本和负样本。通过考虑不同重要程度的正样本和负样本,它平衡了来自两个样本的学习信号。Poly Loss将常用的分类损失分解为一系列加权多项式基。它在不同的任务和数据集上调整多项式系数,通过实验证明其优于交叉熵损失和Focal Loss。
评估了YOLOv6上的所有高级分类损失,以最终采用VFL(VariFocal Loss)。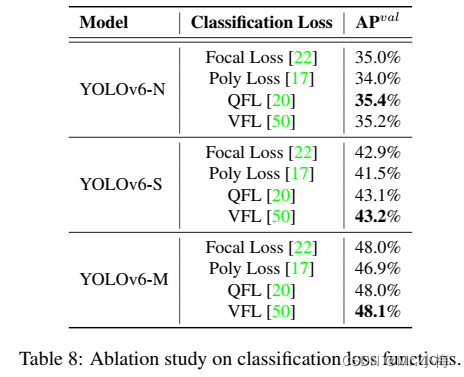
在YOLOv6-N/S/M上实验了Focal Los、Polyloss、QFL和VFL。如表8所示,与Focal Loss相比,VFL对YOLOv6-N/S/M分别带来0.2%/0.3%/0.1%的AP改善。所以,本文选择VFL作为分类损失函数。
8.3.3.2 Box Regression Loss
框回归损失为精确定位边界盒提供了重要的学习信号。L1 Loss是早期工作中的原始框回归损失。逐渐地,各种精心设计的框回归损失如IoU系列Loss和Probability Loss如雨后春笋般涌现。
IoU-series Loss: IoU Loss将预测框的四个边界作为一个整体单位进行回归。由于其与评价指标的一致性,已被证明是有效的。IoU有许多变体,如GIoU、DIoU、CIoU、α-IoU和SIoU等,形成相关损失函数。对GIoU、CIoU和SIoU进行了实验。SIoU应用于YOLOv6-N和YOLOV 6-T,而其他的使用GIoU。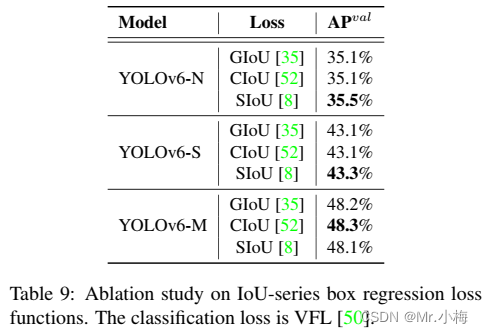
IoU系列损失函数和概率损失函数都在YOLOv6-N/S/M上进行了实验。最新的IoU系列损失函数用于YOLOv6N/S/M。表9中的实验结果表明,对于YOLOv6-N和YOLOv 6-T,SIoU Loss优于其他Loss,而对于YOLOv6-M,CIoU Loss表现更好。
Probability Loss:Dostronition Focal Loss(DFL)将框位置的基本连续分布简化为离散化概率分布。它考虑了数据中的模糊性和不确定性,而不引入任何其他先验,这有助于提高框定位精度,特别是当GT框的边界模糊时。基于DFL,DFLv2开发了一个轻量级子网络,以利用分布统计和实际定位质量之间的密切相关性,进一步提高检测性能。然而,DFL通常输出比一般盒回归多17倍的回归值,导致大量开销。额外的计算成本显著阻碍了小模型的训练。而DFLv2由于额外的子网络而进一步增加了计算负担。在本文的实验中,DFLv2在我们的模型上带来了与DFL类似的性能增益。因此,我们仅在YOLOv6-M/L中采用DFL。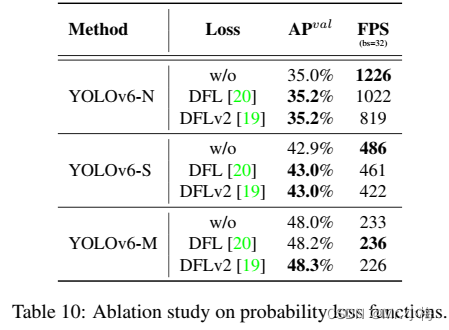
对于概率损失,如表10所示,对于YOLOv6-N/S/M,引入DFL可分别获得0.2%/0.1%/0.2%的性能增益。然而,对于小模型,推理速度受到很大影响。因此,DFL仅在YOLOv6-M/L中引入。
8.3.3.3 Object Loss
FCOS中首次提出了Object Loss,以降低低质量边界框的分数,以便在后处理中过滤掉它们。在YOLOX中也使用了它来加速收敛并提高网络精度。作为一个像FCOS和YOLOX这样的anchor-free框架,本文尝试将Object Loss引入YOLOv6。不幸的是,它没有带来很多积极的效果。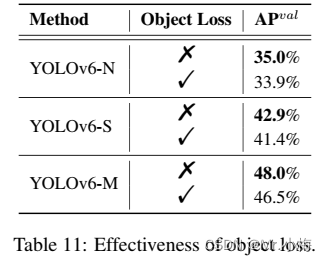
如表11所示,还对YOLOv6进行了Object Loss实验。从表11可以看出,Object Loss对YOLOv6-N/S/M网络有负面影响,其中最大减少量为1.1%。负增益可能来自TAL中Object分支和其他两个分支之间的冲突。具体地说,在训练阶段,预测框和GT之间的IoU以及分类分数被用于共同构建度量作为分配标签的标准。引入的Object分支将要对齐的任务的数量从两个扩展到三个,这显然增加了难度。基于实验结果和该分析,然后在YOLOv6中去除Object Loss。
8.3.4 工业便利化改进(Industry-handy improvements)
下面的技巧可以在实际实践中使用。它们不是为了进行实验比较,而是在没有太多繁琐的工作的情况下稳定地产生性能增益。
8.3.4.1 更多的训练轮次
实验结果表明,随着训练时间的增加,检测器的性能不断提高。我们将训练时间从300个周期延长到400个周期,以达到更好的收敛。
在实践中,更多的训练周期是进一步提高准确性的简单而有效的方法。表12显示了针对300和400个epochs训练的小型模型的结果。可以观察到,针对更长时间epoch的训练分别用于YOLOv6-N、T和S,显著提高了AP 0.4%、0.6%和0.5%。考虑到可接受的成本和产生的增益,对于YOLOv6,训练400个epochs是更好的收敛方案。
8.3.4.2 自蒸馏
8.3.4.3 图像的灰度边界(Gray border of images)
注意到,在评估YOLOv5和YOLOv7中的模型性能时,在每个图像周围放置了half-stride灰色边界(就是resize图片时四周填充了灰度的padding)。虽然没有添加有用的信息,但它有助于检测图像边缘附近的对象。这个技巧也适用于YOLOv6。
然而,额外的灰度像素明显降低了推理速度。如果没有灰色边界,YOLOv6的性能会恶化,这也是YOLOv5和YOLOv7中遇到的情况。我们假设该问题与Mosaic增强中的灰色边界填充有关。为了验证,进行了在最后一个epoch时关闭Mosaic增强的实验(又名衰退策略,fade strategy)。在这方面,我们改变了灰度边界的面积,并将具有灰度边界的图像直接调整为目标图像大小。结合这两种策略,我们的模型可以在不降低推理速度的情况下保持甚至提高性能。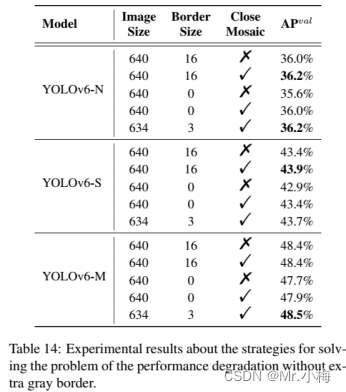
实验结果如表14所示。在这些实验中,YOLOv6-N和YOLOV-S训练400个周期,YOLOv6-M训练300个周期。可以观察到,当去除灰色边界时,在没有关闭Mosaic衰落策略的情况下,YOLOv6-N/S/M的精度降低了0.4%/0.5%/0.7%。然而,当关闭Mosaic衰落策略时,性能退化变为0.2%/0.5%/0.5%。可以发现,一方面,性能下降的问题得到了缓解。另一方面,无论是否填充灰色边界,小模型(YOLOv6-N/S)的精度都会提高。
将输入图像限制为634×634,并在边缘周围添加3像素宽的灰色边界。使用该策略,最终图像的大小为预期的640×640。表14中的结果表明,当最终图像尺寸从672减小到640时,YOLOv6-N/S/M的最终性能甚至更精确0.2%/0.3%/0.1%。
8.3.4.4 量化和部署
对于工业部署,通常采用量化来进一步加快运行时间,而不会影响性能。训练后量化(post-training,PTQ)仅使用小的校准集直接量化模型。而量化感知训练(quantization-aware training,QAT)使用训练集,其通常与蒸馏联合使用,进一步提高了性能。然而,由于在YOLOv6中大量使用了重参数化块,先前的PTQ技术无法产生高性能,而在训练和推理期间匹配伪量化器时,很难结合QAT。接下来介绍部署过程中的陷阱和解决方法。
8.3.4.4.1 重参数化优化器
RepOptimizer提议在每个step中进行梯度重参数化。该技术很好地解决了基于重参数化的模型的量化问题。因此,本文以这种方式重建了YOLOv6的重参数化Block,并使用RepOptimizer优化器对其进行训练,以获得PTQ-friendly权重。特征图的分布大大缩小(如图6),这大大利于量化过程。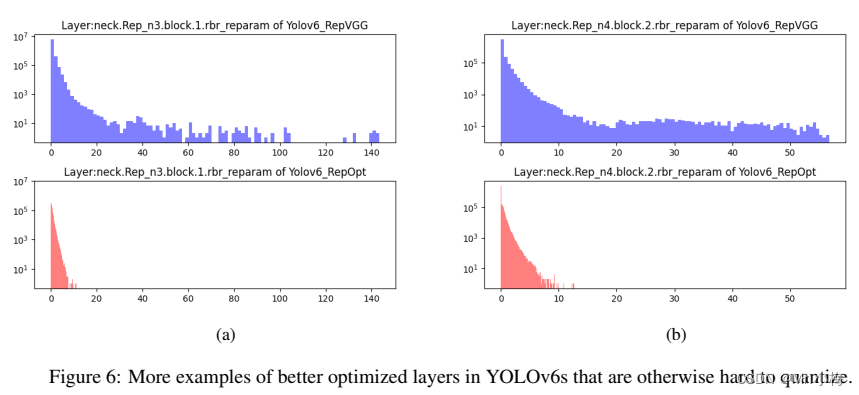
8.3.4.4.2 Sensitivity Analysis
通过将量化敏感操作部分转换为浮点计算,进一步提高了PTQ性能。为了获得灵敏度分布,通常使用几种度量,均方误差(MSE)、信噪比(SNR)和余弦相似性。通常,为了进行比较,可以选择输出特征映射(在激活某一层之后)来计算这些度量,包括量化和不量化。作为替代方案,也可以通过打开和关闭特定层的量化来计算验证AP。
8.3.4.4.3 基于通道蒸馏的量化感知训练
在PTQ不足的情况下,本文提出使用量化感知训练(quantization-aware training,QAT)来提高量化性能。为了解决训练和推理过程中伪量化器的不一致性问题,有必要在RepOptimizer优化器上建立QAT。此外,如图5所示,在YOLOv6框架内采用了通道式蒸馏(后来称为CW蒸馏)。这也是一种自蒸馏方法,其中teacher网络是FP32精度中的student本身。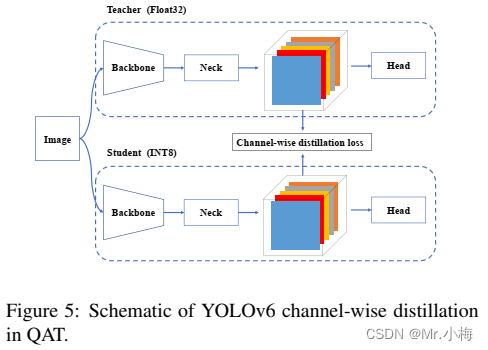
8.3.5 结论
简而言之,考虑到持续的工业需求,提出了YOLOv6,仔细分析了迄今为止目标检测器组件的所有进步。结果在精度和速度上都超过了其他可用的实时目标检测器。为了便于工业部署,还为YOLOv6提供了一种定制的量化方法,从而提供了前所未有的快速检测器。
版权归原作者 Mr.小梅 所有, 如有侵权,请联系我们删除。