
关注并星标
从此不迷路
计算机视觉研究院



公众号ID|ComputerVisionGzq
学习群|扫码在主页获取加入方式

论文地址:https://arxiv.org/pdf/2207.02696.pdf
代码地址:https://github.com/WongKinYiu/yolov7
计算机视觉研究院专栏
作者:Edison_G
YOLOv7相同体量下比YOLOv5精度更高,速度快120%(FPS),比YOLOX快180%(FPS),比Dual-Swin-T快1200%(FPS),比ConvNext快550%(FPS),比SWIN-L快500%(FPS)。
01
概述
前段时间才给大家分享了美团出品的Yolov6:

具体的链接如下:
链接🔗:劲爆!YOLOv6又快又准的目标检测框架开源啦(附源代码下载)
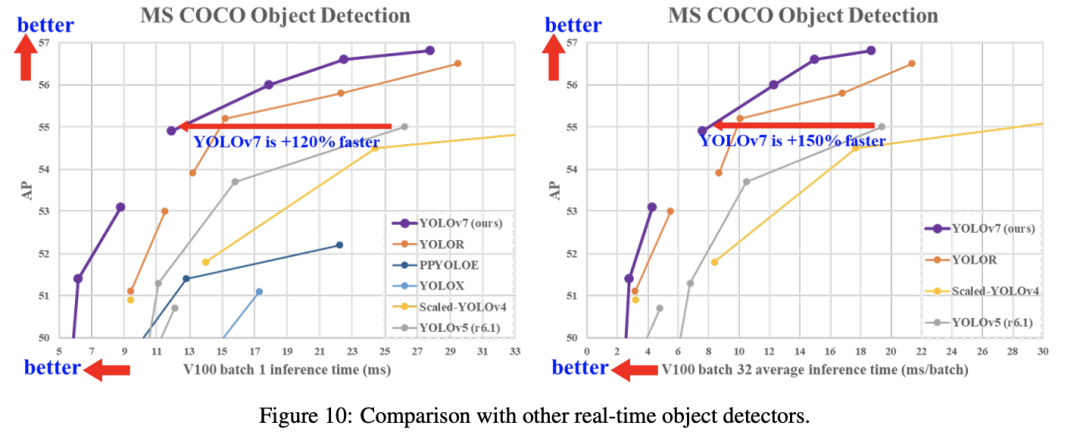
7月份又出来一个Yolov7,在5 FPS到160 FPS范围内的速度和精度达到了新的高度,并在GPU V100上具有30 FPS或更高的所有已知实时目标检测器中具有最高的精度56.8%AP。YOLOv7-E6目标检测器(56 FPS V100,55.9% AP)比基于Transform的检测器SWINL Cascade-Mask R-CNN(9.2 FPS A100,53.9% AP)的速度和准确度分别高出509%和2%,以及基于卷积的检测器ConvNeXt-XL Cascade-Mask R-CNN (8.6 FPS A100, 55.2% AP) 速度提高551%,准确率提高0.7%。
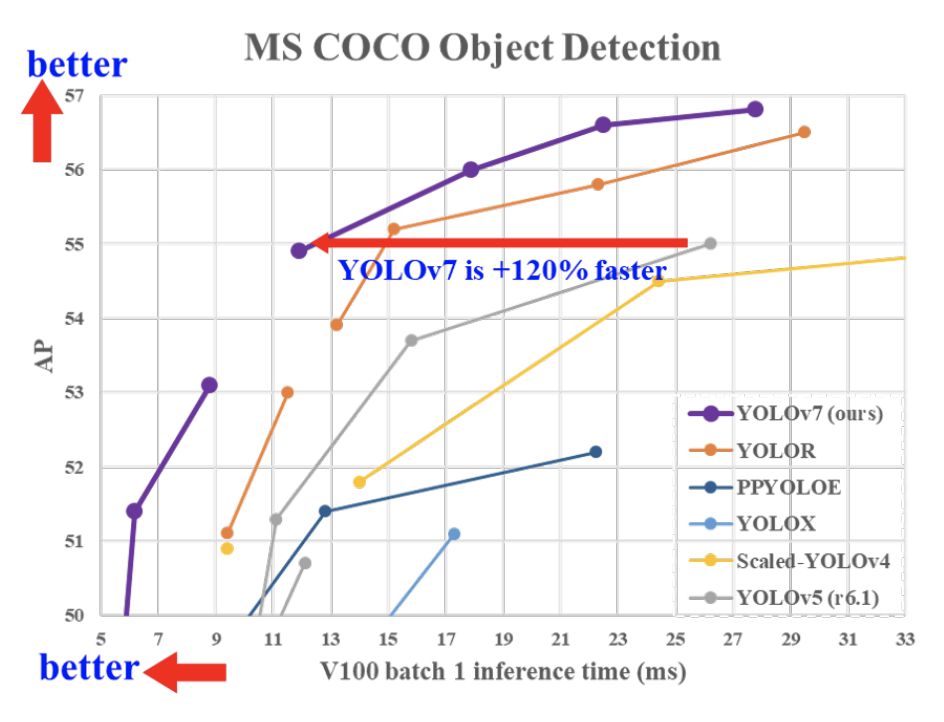
以及YOLOv7的表现优于:YOLOR、YOLOX、Scaled-YOLOv4、YOLOv5、DETR、Deformable DETR , DINO-5scale-R50, ViT-Adapter-B和许多其他目标检测器在速度和准确度上。
此外,研究者只在MS COCO数据集上从头开始训练YOLOv7,而不使用任何其他数据集或预训练的权重。
02
背景
最近,模型重参数化(model re-parameterization)和动态标签分配(dynamic label assignment)已成为网络训练和目标检测的重要课题。主要是在上述新概念提出之后,目标检测器的训练演变出了很多新的问题。
在今天分享中,研究者将介绍其发现的一些新问题,并设计解决这些问题的有效方法。对于模型重参数化,研究者用梯度传播路径的概念分析了适用于不同网络层的模型重参数化策略,并提出了有计划的重参数化模型。
此外,当发现使用动态标签分配技术时,具有多个输出层的模型的训练会产生新的问题。即:“如何为不同分支的输出分配动态目标?” 针对这个问题,研究者提出了一种新的标签分配方法,称为从粗到细的引导式标签分配。
03
新框架详细分析
扩展的高效层聚合网络
扩展的高效层聚合网络。 提出的扩展ELAN(E-ELAN)完全没有改变原有架构的梯度传输路径,而是使用组卷积来增加添加特征的基数,并以shuffle和merge cardinality的方式组合不同组的特征 . 这种操作方式可以增强不同特征图学习到的特征,提高参数的使用和计算。
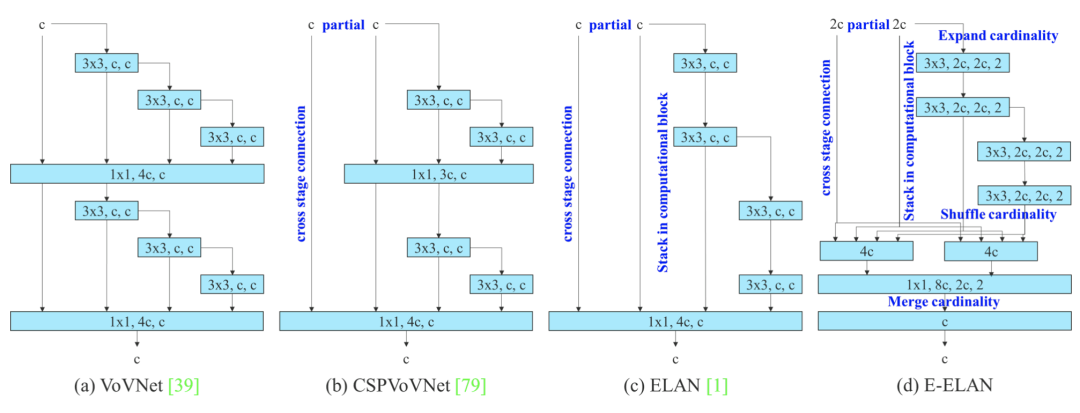
在大多数关于设计高效架构的文献中,主要考虑因素不超过参数的数量、计算量和计算密度。有人从内存访问成本的特点出发,分析了输入/输出通道比、架构的分支数量以及element-wise操作对网络推理速度的影响。有些人在执行模型缩放时还考虑了激活,即更多地考虑卷积层输出张量中的元素数量。
基于concatenate模型的模型缩放
模型缩放的主要目的是调整模型的一些属性,生成不同尺度的模型,以满足不同推理速度的需求。
例如EfficientNet的缩放模型考虑了宽度、深度和分辨率。对于Scale-yolov4,其缩放模型是调整阶段数。有些研究者分析了卷积和群卷积对参数量和计算量的影响,并据此设计了相应的模型缩放方法。
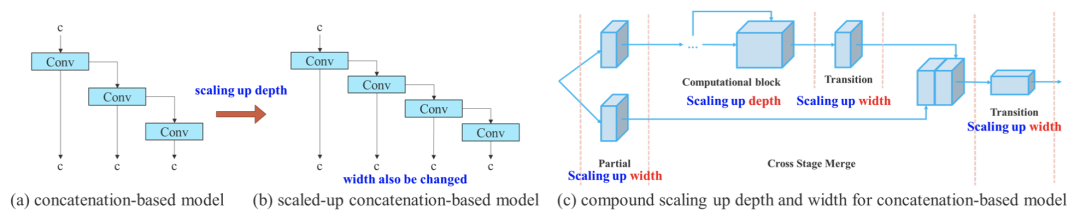
基于串联模型的模型缩放。从(a)到(b),我们观察到当在基于串联的模型上执行深度缩放时,计算块的输出宽度也会增加。这种现象会导致后续传输层的输入宽度增加。因此,研究者提出(c),即在对基于concatenation的模型进行模型缩放时,只需要对计算块中的深度进行缩放,其余传输层进行相应的宽度缩放。
Planned re-parameterized convolution
尽管RepConv在VGG基础上取得了优异的性能,但当将它直接应用于ResNet、DenseNet和其他架构时,它的精度将显著降低。作者使用梯度流传播路径来分析重参数化的卷积应该如何与不同的网络相结合。作者还相应地设计了计划中的重参数化的卷积。
RepConv实际上结合了3×3卷积,1×1卷积,和在一个卷积层中的id连接。通过分析RepConv与不同架构的组合及其性能,作者发现RepConv中的id连接破坏了ResNet中的残差和DenseNet中的连接,为不同的特征图提供了更多的梯度多样性。
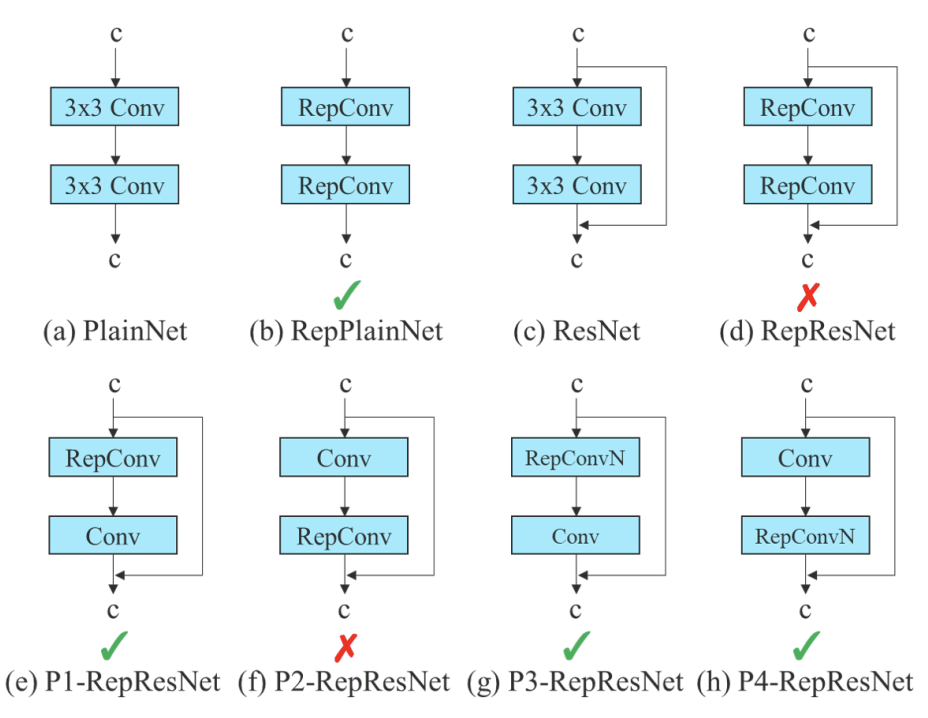
提出的重参数化模型。在提出的计划重参数化模型中,我们发现一个带有残差或串联连接的层,其RepConv不应该有恒等连接。在这些情况下,它可以被不包含身份连接的 RepConvN 替换。
Coarse for auxiliary and fine for lead loss
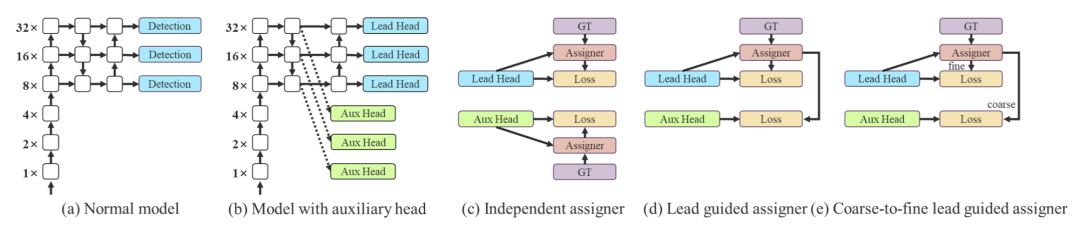
Coarse for auxiliary and fine for lead head label assigner
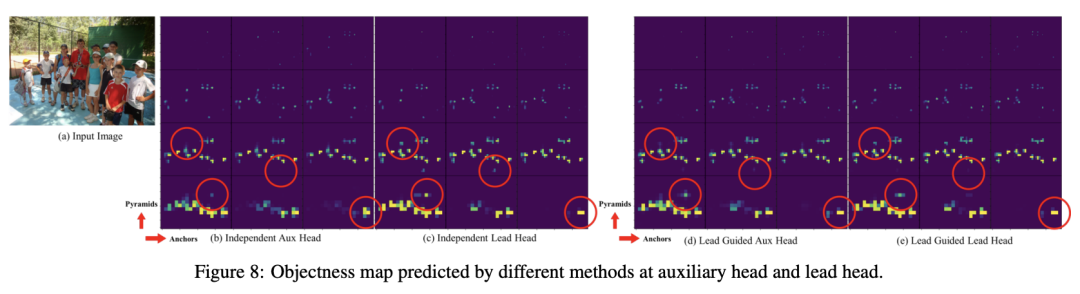
与正常模型(a)相比,(b)中的模式具有辅助中心。与通常的独立标签分配器 (c) 不同,研究者提出 (d) 引导头引导标签分配器和 (e) 粗到细引导头引导标签分配器。所提出的标签分配器通过前导头预测和GT实况进行优化,以同时获得训练前导头和辅助头的标签。详细的从粗到细的实现方法和约束设计细节将在附录中详述。
04
实验及可视化
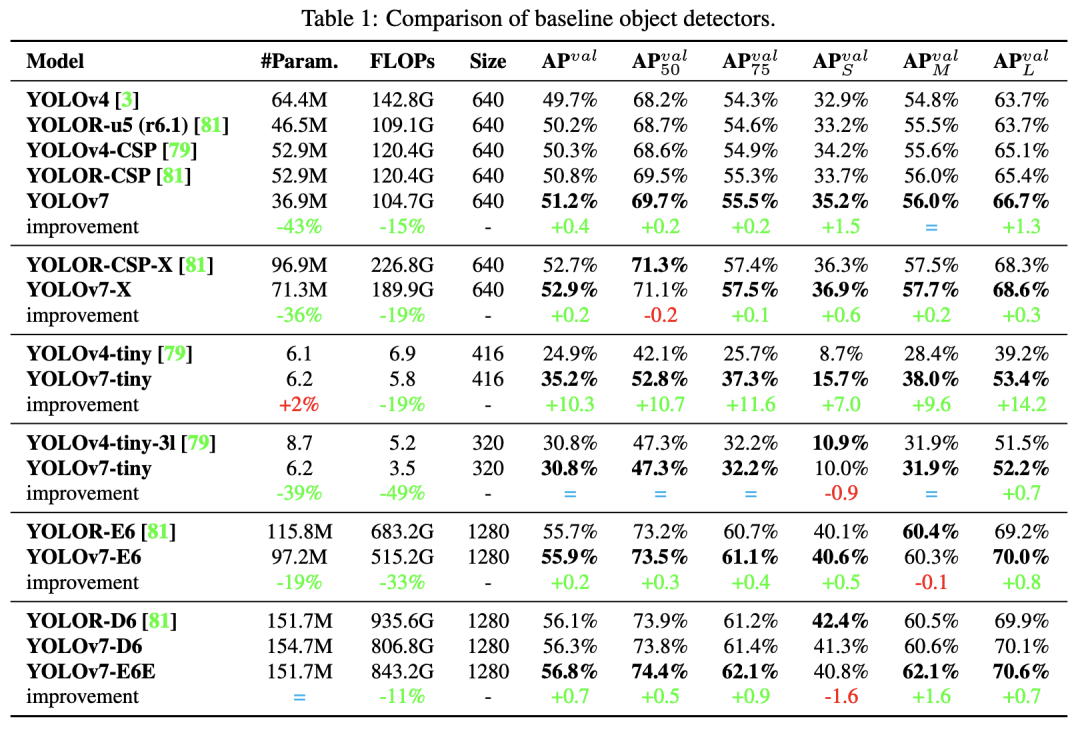
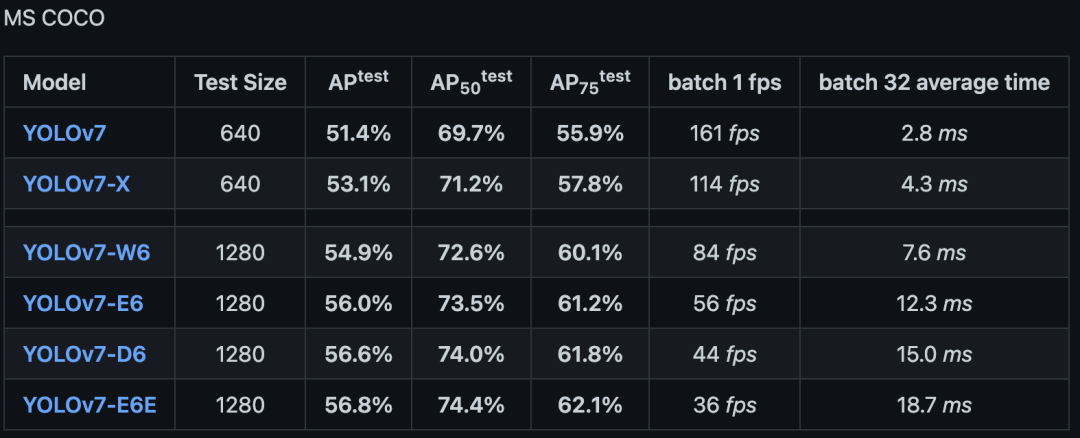
如上表所述:
- 与YOLOv4相比,YOLOv7的参数减少了75%,计算量减少了36%,AP提高了1.5%
- 与最先进的YOLOR-CSP相比,YOLOv7的参数少了43% ,计算量少了15%,AP高了0.4%
- 在小模型的性能中,与YOLOv4-tiny相比,YOLOv7-Tiny减少了39%的参数量和49%的计算量,但保持相同的AP
- 在云GPU模型上,YOLOv7模型仍然具有更高的AP,同时减少了19%的参数量和33%的计算量
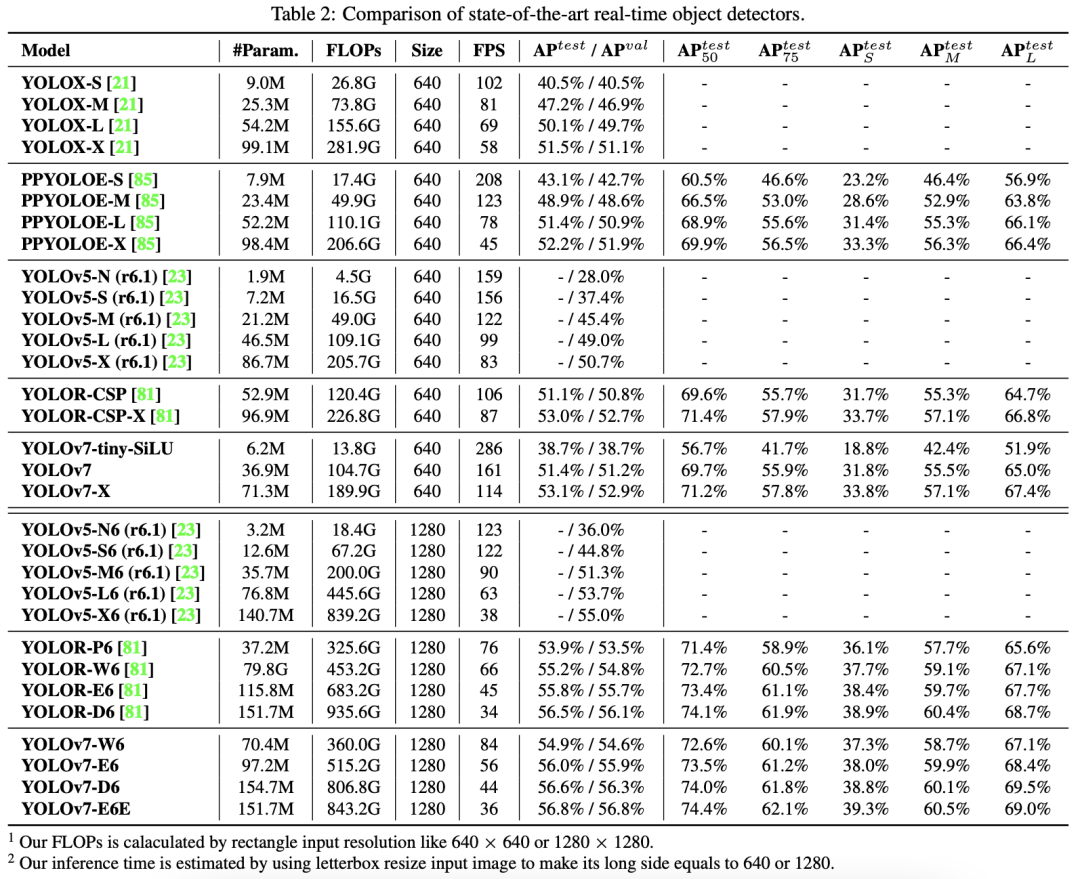
将所提出的方法与通用GPU上或边缘GPU上最先进的的目标检测器进行了比较,结果如下表所示:
**© THE END **
转载请联系本公众号获得授权

计算机视觉研究院学习群等你加入!
ABOUT
计算机视觉研究院
计算机视觉研究院主要涉及深度学习领域,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。研究院接下来会不断分享最新的论文算法新框架,我们这次改革不同点就是,我们要着重”研究“。之后我们会针对相应领域分享实践过程,让大家真正体会摆脱理论的真实场景,培养爱动手编程爱动脑思考的习惯!
VX:2311123606

往期推荐
🔗
- AI助力社会安全,最新视频异常行为检测方法框架
- ONNX 浅析:如何加速深度学习算法工程化?
- 劲爆!YOLOv6又快又准的目标检测框架开源啦(附源代码下载)
- FastestDet:比yolov5更快!更强!全新设计的超实时Anchor-free目标检测算法(附源代码下载)
- 目前精度最高效率最快存储最小的目标检测模型(附源码下载)
- CVPR小目标检测:上下文和注意力机制提升小目标检测(附论文下载)
- Double-Head:检测头上再创新,提升精度(附原论文下载)
- 海康研究院出品:具有场景自适应概念学习的无监督目标检测(附论文下载)
- 新技术:高效的自监督视觉预训练,局部遮挡再也不用担心!
- VS Code支持配置远程同步了
- 改进的阴影抑制用于光照鲁棒的人脸识别
- 基于文本驱动用于创建和编辑图像(附源代码)
- 基于分层自监督学习将视觉Transformer扩展到千兆像素图像
- 霸榜第一框架:工业检测,基于差异和共性的半监督方法用于图像表面缺陷检测
- CLCNet:用分类置信网络重新思考集成建模(附源代码下载)
版权归原作者 计算机视觉研究院 所有, 如有侵权,请联系我们删除。