
前言
Pandas数据分析系列专栏已经更新了很久了,基本覆盖到使用pandas处理日常业务以及常规的数据分析方方面面的问题。从基础的数据结构逐步入门到处理各类数据以及专业的pandas常用函数讲解都花费了大量时间和心思创作,如果大家有需要从事数据分析或者大数据开发的朋友推荐订阅专栏,将在第一时间学习到Pandas数据分析最实用常用的知识。此篇博客篇幅较长,涉及到处理文本数据(str/object)等各类操作,值得细读实践一番,我会将Pandas的精华部分挑出细讲实践。博主会长期维护博文,有错误或者疑惑可以在评论区指出,感谢大家的支持。
一、文本数据类型
Pandas用来代表文本数据类型有两种:
- object:一般为NumPy的数组
- string:最常规的文本数据
我们最常用的还是使用string来存储文本文件,但是使用dataframe和series进行数据处理转换的时候object数据类型又用的多。在Pandas1.0版本之前只有object类型,这会导致字符数据和非字符数据全部都以object方式存储,导致处理混乱。而后续版本优化加入了String更好的区分了处理文本数据的耦合问题。目前的object类型依旧是文本数据和数组类型的string数据,但是Pandas为了后续的兼容性依旧将object类型设为默认的文本数据存储类型。
二、文本转换
例如我们新建一个Series:
pd.Series(['a','b','c'])

默认创建为object类型,当然可以指定为string类型:
pd.Series(["a", "b", "c"], dtype="string")

亦或是:
pd.Series(["a", "b", "c"], dtype=pd.StringDtype())

若开始没有指定则可以使用astype方法强制转换:
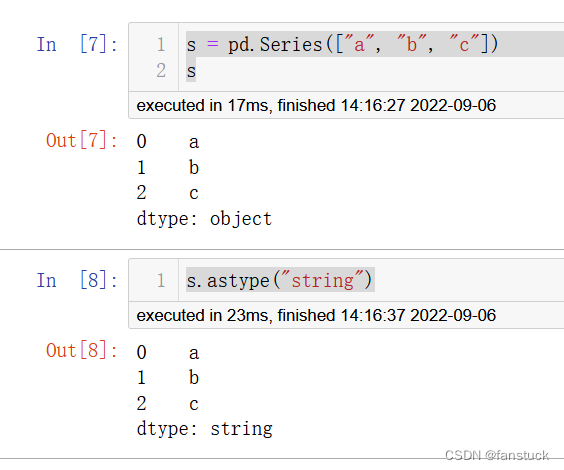
s = pd.Series(["a", "b", "c"])
s.astype("string")
三、Object与String的差别
对于StringDtype,返回数值输出的字符串操作方法将始终返回可为空的整数数据类型,而不是int或float数据类型,具体取决于NA值的存在。返回布尔输出的方法将返回可为空的布尔数据类型。
我们用案例展示一遍就明白了:
s = pd.Series(["a", None, "b"], dtype="string")
s

s.str.count("a")
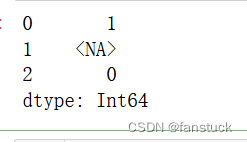
s.dropna().str.count("a")

以上都是string数据类型处理后的结果,我们与之对比一下object就会发现:
s2 = pd.Series(["a", None, "b"], dtype="object")
s2

s2.str.count("a")

可以发现object与string不同的是聚合后显示的数据类型,前者是float后者则是int。
s2.dropna().str.count("a")

而当去掉NA时候则为int,这和string一样。当存在NA值时,输出数据类型为float64。
s.str.isdigit()
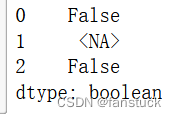
s.str.match("a")

有些字符串方法,如Series.str.decode()在StringArray上不可用,因为StringArray只保存字符串,而不是字节。在比较操作中,数组。StringArray和由StringArray支持的序列将返回一个具有BooleanDtype的对象,而不是bool dtype对象。StringArray中缺少的值将在比较操作中传递,而不是像numpy.nan那样总是比较不相等的值。
四、String处理方法
序列和索引都配备了一组字符串处理方法,可以轻松地对数组的每个元素进行操作。最重要的是这些方法自动排除丢失的/NA值。这些方法通过str属性访问,通常名称与等效(标量)内置字符串方法匹配:
1.大小写转换
这里我们创建测试用例:
s=pd.Series(['A','b','C',np.nan,'ABC','abc','AbC'],dtype='string')
小写转换lower()
s.str.lower()

大写转换upper()
s.str.upper()

2.元素长度
输出每个元素的长度len()就可以做到:
s.str.len()

3.字符串空格去除
这种方法有三种控制形式,这里我们创建一个覆盖测试用例全面的数据集:
s=pd.Index([' A','A ',' A ','A'],dtype='string')

全部去除strip()
s.str.strip()
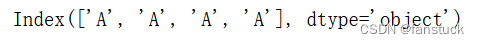
只去除左边lstrip()
s.str.lstrip()
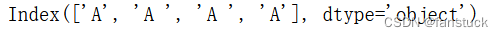
只去除右边rstrip()
s.str.rstrip()

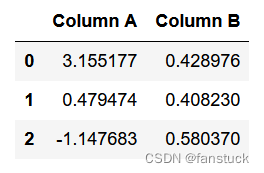
索引上的字符串方法对于处理或转换DataFrame列特别有用。例如,可能有带有前导或尾随空格的列:
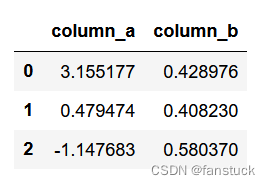
df = pd.DataFrame(
np.random.randn(3, 2), columns=[" Column A ", " Column B "], index=range(3)
)
我们将列索引提取之后使用str类方法就可以处理转换:
df.columns.str.strip()
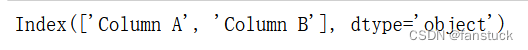
也可以自由进行大小写转换:
df.columns.str.lower()
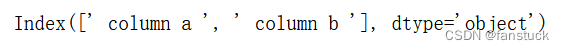
组合一起来用的话,还可以搭配其他函数实现复杂的转换效果:
df.columns = df.columns.str.strip().str.lower().str.replace(" ", "_")
开篇文章不讲过多,下篇文章我们再去了解一些基础的方法。
点关注,防走丢,如有纰漏之处,请留言指教,非常感谢
以上就是本期全部内容。我是fanstuck ,有问题大家随时留言讨论 ,我们下期见。
版权归原作者 fanstuck 所有, 如有侵权,请联系我们删除。