
文章目录
概述
定义
Apache Kylin 官网中文地址 https://kylin.apache.org/cn/
Apache Kylin 官网中文最新文档 https://kylin.apache.org/cn/docs/
Apache Kylin 源码地址 https://github.com/apache/kylin
Apache Kylin™是一个开源的、分布式的分析型数据仓库,提供Hadoop/Spark 之上的 SQL 查询接口及多维分析(OLAP)能力以支持超大规模数据,最初由 eBay 公司中国团队开发并贡献给Apache,使用神兽麒麟命名,查询速度快能在亚秒内响应。最新版本为v4.0.3
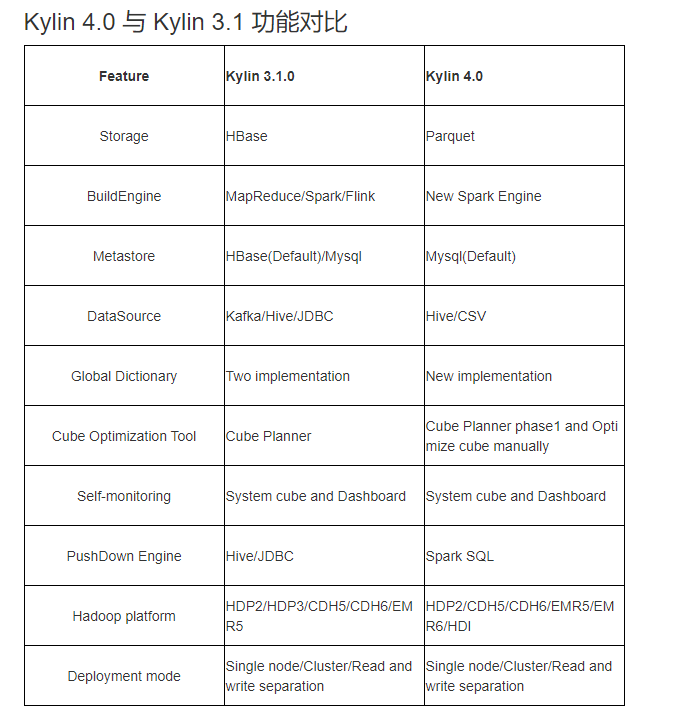
Apache Kylin4.0 是一个重大改革版本,其中4.0之前采用HBase 作为存储引擎来保存 cube 构建后产生的预计算结果,构建引擎为MR,下推引擎采用的是HIVE JDBC;4.0之后采用了全新的 Spark 构建引擎和 Parquet 作为存储,同时使用 Spark 作为查询引擎。版本功能详细对比如下:
使用 Apache Parquet + Spark 来代替 HBase 使用理由如下:
- HBase 作为 HDFS 之上面向列族的数据库,查询表现已经算是比较优秀,但是它仍然存在以下几个缺点: - HBase 不是真正的列式存储;- HBase 没有二级索引,Rowkey 是它唯一的索引;- HBase 没有对存储的数据进行编码,kylin 必须自己进行对数据编码的过程;- HBase 不适合云上部署和自动伸缩;- HBase 不同版本之间的 API 版本不同,存在兼容性问题(比如,0.98,1.0,1.1,2.0);- HBase 存在不同的供应商版本,他们之间有兼容性问题。
- Parquet针对上面问题有如下特点 - Parquet 是一种开源并且已经成熟稳定的列式存储格式;- Parquet 对云更加友好,可以兼容各种文件系统,包括 HDFS、S3、Azure Blob store、Ali OSS 等;- Parquet 可以很好地与 Hadoop、Hive、Spark、Impala 等集成;- Parquet 支持自定义索引。
特性
- 可扩展超快的基于大数据的分析型数据仓库:为减少在 Hadoop/Spark 上百亿规模数据查询延迟而设计。
- 交互式查询能力:对 Hadoop 数据实现亚秒级交互响应,在同等的数据规模比 Hive 性能更好。
- 实时 OLAP:在数据产生时进行实时处理,可在秒级延迟下进行实时数据的多维分析。
- Hadoop ANSI SQL 接口:作为一个分析型数据仓库(也是 OLAP 引擎),为 Hadoop 提供标准 SQL 支持大部分查询功能。
- 多维立方体(MOLAP Cube):能够在百亿以上数据集定义数据模型并构建立方体。
- 与BI工具无缝整合:提供与 BI 工具的整合能力,如Tableau,PowerBI/Excel,MSTR,QlikSense,Hue 和 SuperSet。
- 其他特性 - Job管理与监控- 压缩与编码- 增量更新- 利用HBase Coprocessor- 基于HyperLogLog的Dinstinc Count近似算法- 友好的web界面以管理,监控和使用立方体- 项目及表级别的访问控制安全- 支持LDAP、SSO
术语
- 数据仓库是一个各种数据(包括历史数据、当前数据)的中心存储系统,是BI(business intelligence,商业智能)的核心部件。例如数据包含来自企业各个业务系统的订单、交易、客户、采购、库存、供应商、竞争对手数据。
- 商业智能通常被理解为将企业中现有的数据转化为知识,帮助企业做出明智的业务经营决策的工具。为了将数据转化为知识,需要利用到数据仓库、联机分析(OLAP)工具和数据挖掘等技术。
- OLAP是一种软件技术,它使分析人员能够迅速、一致、交互地从各个方面、各个维度观察信息,以达到深入理解数据的目的,OLAP也称为多维分析。
 - ROLAP(Relational OLAP):基于关系型数据库,不需要预计算。- MOLAP(Multidimensional OLAP):基于多维数据集,需要预计算。
- ROLAP(Relational OLAP):基于关系型数据库,不需要预计算。- MOLAP(Multidimensional OLAP):基于多维数据集,需要预计算。 - 星型模型:由一个或多个引用任意数量维表的事实表组成。
- 事实表:由业务流程的测量、度量或事实组成。
- 查找表:是一个数组,它用一个更简单的数组索引操作代替运行时计算。
- 维度:是一种对事实和度量进行分类的结构,以便使用户能够回答业务问题。常用的维度有人物、产品、地点和时间。
- 度量:是可以进行计算(例如总和、计数、平均、最小值、最大值)的属性。
- 连接:一个SQL连接子句组合来自关系数据库中两个或多个表的记录。
技术概念
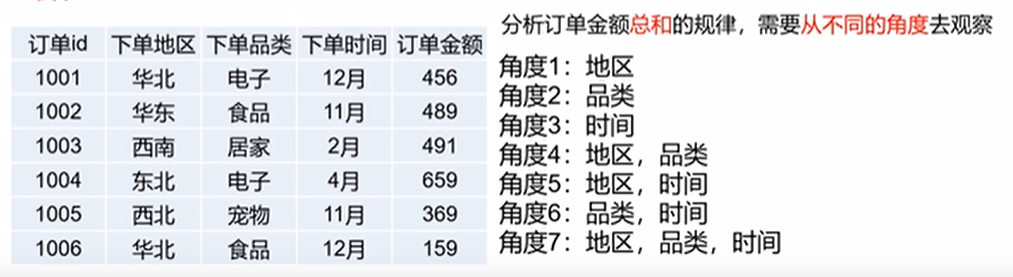
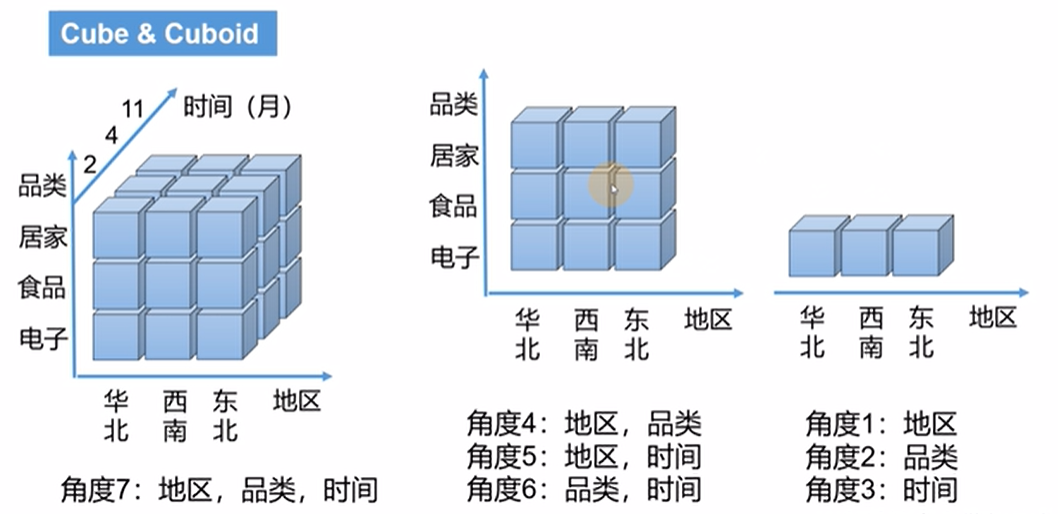
- OLAP Cube:OLAP多维数据集是用0维或多维来理解的数据数组;一个多维的数据集称为一个OLAP Cube.给定一个数据模型,我们可以对其上的所有维度进行聚合,对于 N 个维度来说,组合的所有可能性共有 2^n-1种。对于每一种维度的组合,将度量值做聚合计算,然后将结果保存 为一个物化视图,称为 Cuboid。所有维度组合的 Cuboid 作为一个整体,称为 Cube。简单点来讲:就是每一种维度的组合都叫一个Cuboid, 所有的维度的组合就叫做Cube。
 - Table:这是将蜂窝表定义为多维数据集的源,必须在构建多维数据集之前同步。- Data Model:描述了一个STAR SCHEMA数据模型,它定义了事实/查找表和筛选条件。- Cube Descriptor:它描述了多维数据集实例的定义和设置,定义使用哪个数据模型,拥有什么维度和度量,如何划分到段以及如何处理自动合并等。- Cube Instance:一个多维数据集实例,由一个多维数据集描述符构建,根据分区设置由一个或多个多维数据集段组成。- Partition:用户可以在多维数据集描述符上定义DATE/STRING列作为分区列,将一个多维数据集划分为具有不同日期周期的几个段。- Cube Segment:Cube数据的实际载体。一个构建作业为多维数据集实例创建一个新段。一旦数据在指定的数据周期内发生变化,可以对相关的数据段进行刷新,从而避免重新构建整个多维数据集。- Aggregation Group:每个聚合组是维度的子集,并在其中组合构建长方体。它的目标是修剪优化。
- Table:这是将蜂窝表定义为多维数据集的源,必须在构建多维数据集之前同步。- Data Model:描述了一个STAR SCHEMA数据模型,它定义了事实/查找表和筛选条件。- Cube Descriptor:它描述了多维数据集实例的定义和设置,定义使用哪个数据模型,拥有什么维度和度量,如何划分到段以及如何处理自动合并等。- Cube Instance:一个多维数据集实例,由一个多维数据集描述符构建,根据分区设置由一个或多个多维数据集段组成。- Partition:用户可以在多维数据集描述符上定义DATE/STRING列作为分区列,将一个多维数据集划分为具有不同日期周期的几个段。- Cube Segment:Cube数据的实际载体。一个构建作业为多维数据集实例创建一个新段。一旦数据在指定的数据周期内发生变化,可以对相关的数据段进行刷新,从而避免重新构建整个多维数据集。- Aggregation Group:每个聚合组是维度的子集,并在其中组合构建长方体。它的目标是修剪优化。 - 维度与度量- Mandotary:此维度类型用于长方体修剪,如果一个维度被指定为“强制”,那么那些没有该维度的组合将被修剪。- Hierarchy:其维度类型用于长方体修剪,如果维度A、B、C形成“层次”关系,则只保留与A、AB或ABC的组合。- Derived :在查找表中,可以从它的PK生成一些维度,因此它们与事实表中的FK之间存在特定的映射。所以这些维度是衍生的,不参与长方体的生成。- Count Distinct(HyperLogLog) :针对Immediate COUNT DISTINCT难以计算的问题,引入了一种近似算法HyperLogLog,使错误率保持在较低的水平。- Count Distinct(Precise) - Precise Count Distinct将基于RoaringBitmap预计算,目前只支持int或bigint。- Top N:例如使用这种测量类型,用户可以很容易地获得指定的顶级卖家/买家数量等。
- Cube Actions- BUILD:给定分区列的间隔,此操作是构建一个新的多维数据集段。- REFRESH:此操作将在某个分区期间重建多维数据集段,用于源表增加的情况。- MERGE:这个动作将多个连续的立方体片段合并为一个。这可以通过多维数据集描述符中的自动合并设置来实现。- PURGE*:清除-清除多维数据集实例下的段。这只会更新元数据,不会从HBase中删除多维数据集数据。
- Job Status- NEW:这表示刚刚创建了一个作业。- PENDING:这表示一个作业被作业调度器暂停并等待资源。- RUNNING:这表示一个作业正在进行中。- FINISHED:这表示一项工作已成功完成。- ERROR:这表示一个作业因错误而中止。- DISCARDED:这表示一个作业被最终用户取消了。
- Job Action- RESUME -一旦作业处于ERROR状态,该操作将尝试从最近的成功点恢复它。- DISCARD -无论作业的状态如何,用户都可以通过DISCARD动作结束作业并释放资源。
架构和组件
Kylin 提供与多种数据可视化工具的整合能力,如 Tableau、PowerBI 等,很方便使用 BI 工具对 Hadoop 数据进行分析。
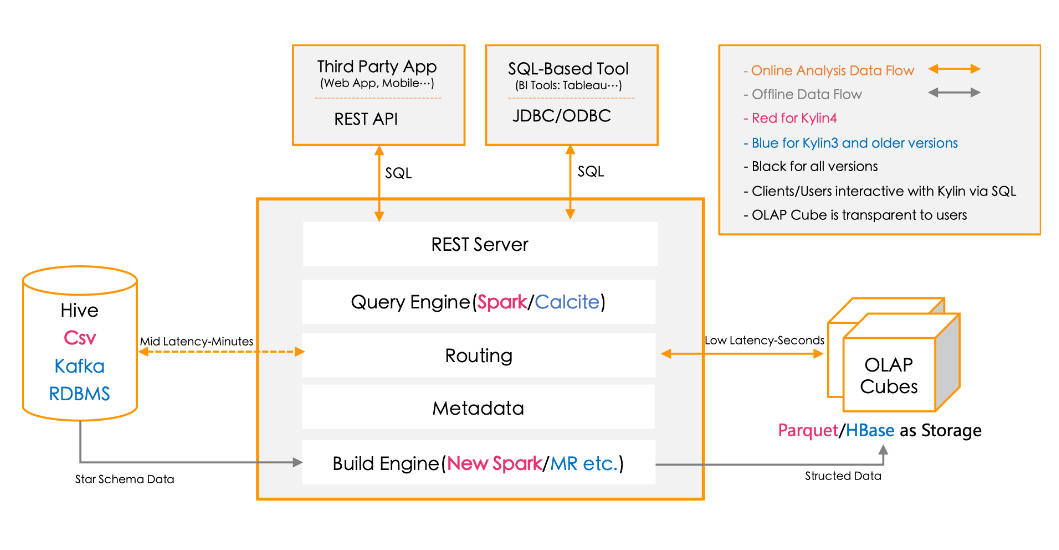
- REST Server:是面向应用程序开发的入口点,此类应用程序可以提供查询、获取结果、触发Cube构建任务、获取元数据及用户权限等,还可以通过Restful接口实现SQL查询。
- Query Engine(查询引擎):当 cube 准备就绪后,查询引擎就能够获取并解析用户查询。随后会与系统中的其它组件进行交互,从而向用户返回对应的结果。4.0版本采用Spark作为查询引擎。
- Routing(路由器):在最初设计时曾考虑过将 Kylin 不能执行的查询引导去 Hive 中继续执行,但在实践后 发现 Hive 与 Kylin 的速度差异过大,导致用户无法对查询的速度有一致的期望,很可能大 多数查询几秒内就返回结果了,而有些查询则要等几分钟到几十分钟,因此体验非常糟糕。 最后这个路由功能在发行版中默认关闭。
- Metadata(元数据管理工具):Kylin 是一款元数据驱动型应用程序。元数据管理工具是一大关键性组件,用于对保存 在 Kylin 当中的所有元数据进行管理,其中包括最为重要的 cube 元数据。其它全部组件的 正常运作都需以元数据管理工具为基础。 Kylin 4.0的元数据存储在 MySQL 中。
- Build Engine(构建引擎):Kylin4.0的构建引擎从MR改为Spark,使用户能否快速得到想要的Cube数据,构建引擎最终得到的数据存放在Parquet文件中,然后Spark更够更好读取Parquet文件数据。
生态圈
- Kylin 核心:Kylin 基础框架,包括元数据(Metadata)引擎,查询引擎,Job引擎及存储引擎等,同时包括REST服务器以响应客户端请求。
- 扩展:支持额外功能和特性的插件。
- 整合:与调度系统,ETL,监控等生命周期管理系统的整合。
- 用户界面:在Kylin核心之上扩展的第三方用户界面。
- 驱动:ODBC 和 JDBC 驱动以支持不同的工具和产品,比如Tableau。
部署
Docker部署
为了让用户轻松试用麒麟,并方便开发人员在修改源代码后进行验证和调试。可以通过麒麟的docker镜像快速部署。该镜像包含麒麟所依赖的每个服务:
- JDK 1.8
- Hadoop 2.8.5
- Hive 1.2.1
- Spark 2.4.7
- Kafka 1.1.1
- MySQL 5.1.73
- Zookeeper 3.4.6
# 拉取镜像,dcoker hub上已有kylin 5.0.0版本镜像,二进制未更新docker pull apachekylin/apache-kylin-standalone:5.0.0
# 运行容器docker run -d\-m 8G \-p7070:7070 \-p8088:8088 \-p50070:50070 \-p8032:8032 \-p8042:8042 \-p2181:2181 \
apachekylin/apache-kylin-standalone:5.0.0
以下服务在容器启动时自动启动:NameNode、 DataNode、ResourceManager、NodeManager、Kylin,相关web UI地址如下:
- Kylin Web UI: http://127.0.0.1:7070/kylin/login
- Hdfs NameNode Web UI: http://127.0.0.1:50070
- Yarn ResourceManager Web UI: http://127.0.0.1:8088
基于hadoop环境安装
前置条件
- HDFS,YARN,MapReduce,Hive,Zookeeper 等服务的 Hadoop 集群;建议单独部署在Hadoop client 节点上,该节点上 Hive,HDFS 等命令行已安装好;运行 Kylin 的 Linux 账户要有访问 Hadoop 集群的权限,包括创建/写入 HDFS 文件夹,Hive 表的权限。
- 硬件要求:运行 Kylin 的服务器建议最低配置为 4 core CPU,16 GB 内存和 100 GB 磁盘。
- 操作系统要求:Linux only、CentOS 6.5+ 或Ubuntu 16.0.4+。
- 安装环境软件要求 - Hadoop: cdh5.x, cdh6.x, hdp2.x, EMR5.x, EMR6.x, HDI4.x- Hive: 0.13 - 1.2.1+- Spark: 2.4.7/3.1.1- Mysql: 5.1.7 及以上- JDK: 1.8+
安装
- 下载解压文件
# 下载最新版本v4.0.3 for Apache Spark 3.1.xwget https://dlcdn.apache.org/kylin/apache-kylin-4.0.3/apache-kylin-4.0.3-bin-spark3.tar.gz
# 解压文件tar-zxvf apache-kylin-4.0.3-bin-spark3.tar.gz
# 进入kylin根目录cd apache-kylin-4.0.3-bin-spark3
# 根目录结构说明如下
bin:启动/停止Kylin服务、备份/恢复元数据的shell脚本,以及一些实用脚本。
conf: XML配置文件,这些xml文件的功能可以在配置页面中找到。
lib:对外使用的Kylin jar文件,如Hadoop作业jar、JDBC驱动程序、HBase协处理器jar等。
meta_backups:执行" bin/metastore.sh backup "命令时的默认备份文件夹;
sample_cube:用于创建样例多维数据集及其表的文件。
spark: spark由$KYLIN_HOME/bin/download.sh下载。
tomcat:运行Kylin应用程序的tomcat web服务器。
tool:命令行工具的jar文件。
# 配置麒麟环境变量vim /etc/profile
exportKYLIN_HOME=/home/commons/apache-kylin-4.0.3-bin-spark3
# 执行环境变量生效source /etc/profile
- 下载和配置Spark。
# 前面用apache-kylin-4.0.3-bin-spark3使用spark3需要下载spark-3.1.1版本wget https://archive.apache.org/dist/spark/spark-3.1.1/spark-3.1.1-bin-hadoop3.2.tgz
# 解压tar-xvf spark-3.1.1-bin-hadoop3.2.tgz
# 进入目录mv spark-3.1.1-bin-hadoop3.2 spark-yarn
# 由于需要用到yarn作为资源管理器,配置spark使用yarn的资源vim conf/spark-env.sh
YARN_CONF_DIR=/home/commons/hadoop/etc/hadoop
并将MySQL连接驱动拷贝到spark的jars目录下,让spark能够正常连接MySQL。

将可使用的hive-site.xml拷贝到spark的conf目录,用于spark操作hive的元数据等。
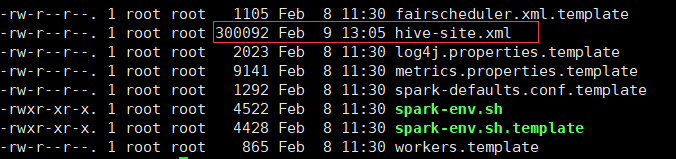
将上面spark-yarn目录分发到所有的yarn的node manager上,并且修改所有node manager的spark环境变量
vim /etc/profile
exportSPARK_HOME=/home/commons/spark-yarn
exportPATH=$SPARK_HOME/bin:$PATH# 执行环境变量生效source /etc/profile
- 配置MySQL元数据- 创建数据库及用户
-- 创建一个kylin数据库CREATEDATABASE kylin DEFAULTCHARACTERSET utf8mb4 COLLATE utf8mb4_bin;-- 创建一个kylin用户CREATEUSER'kylin'@'%' IDENTIFIED BY'kylin';-- 向用户授予刚刚创建的数据库的所有权限GRANTALLPRIVILEGESON kylin.*TO kylin@'%'WITHGRANTOPTION;ALTERUSER'kylin'@'%' IDENTIFIED WITH mysql_native_password BY'kylin';FLUSH PRIVILEGES;- 下载MySQL JDBC驱动程序(MySQL -connector-java-.jar),这里使用MySQL8,驱动程序mysql-connector-java-8.0.28.jar,并将其放在$KYLIN_HOME/ext/目录下,先 mkdir ext创建ext文件夹 - 如果需要加密数据库用户密码,可使用kylin自带工具加密mysql密码,并在kylin.metadata.url中增加passwordEncrypted=true
- 如果需要加密数据库用户密码,可使用kylin自带工具加密mysql密码,并在kylin.metadata.url中增加passwordEncrypted=truejava-classpath kylin-server-base-4.0.3.jar\:kylin-core-common-4.0.3.jar\:spring-beans-5.2.22.RELEASE.jar\:spring-core-5.2.22.RELEASE.jar\:commons-codec-1.6.jar \org.apache.kylin.rest.security.PasswordPlaceholderConfigurer \AES kylin - 修改kylin的配置文件,vim conf/kylin.properties
kylin.metadata.url=kylin_metadata@jdbc,url=jdbc:mysql://mysqlserver:3306/kylin,username=kylin,password=kylin,maxActive=10,maxIdle=10,driverClassName=com.mysql.cj.jdbc.Driver
# HDFS工作空间
kylin.env.hdfs-working-dir=/kylin
# kylin在zookeeper的工作目录
kylin.env.zookeeper-base-path=/kylin
# 不使用kylin自带的zookeeper
kylin.env.zookeeper-is-local=false
# 外部zookeeper连接字符串配置
Kylin.env.zookeeper-connect-string=zk1:2181,zk2:2181,zk3:2181
# SPARK BUILD ENGINE CONFIGS,hadoop conf目录位置
kylin.env.hadoop-conf-dir=/home/commons/hadoop/etc/hadoop
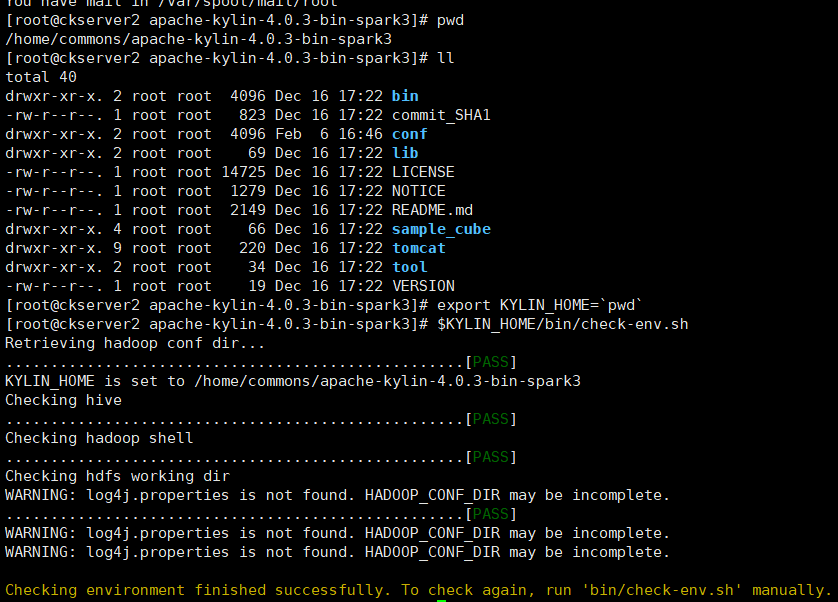
- 环境检查,Kylin运行在Hadoop集群上,对各个组件的版本、访问权限和CLASSPATH有一定的要求。
# 为了避免遇到各种环境问题,可以运行$KYLIN_HOME/bin/check-env.sh脚本进行环境检查,查看是否存在问题。如果识别出任何错误,脚本将打印出详细的错误消息。如果没有错误消息,说明您的环境适合Kylin操作。$KYLIN_HOME/bin/check-env.sh
- 由于hadoop和hive依赖冲突报类找不到
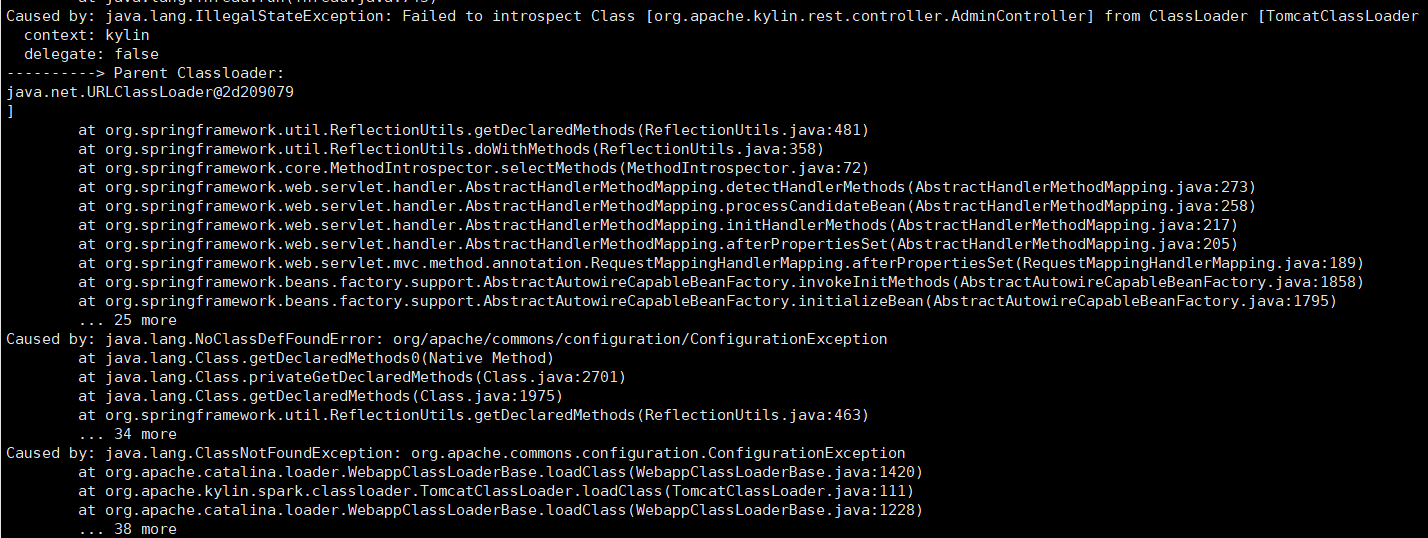
- 将commons-configuration-1.6.jar上传到$KYLIN_HOME/tomcat/webapps/kylin/WEB-INF/lib/下。

- 启动Kylin
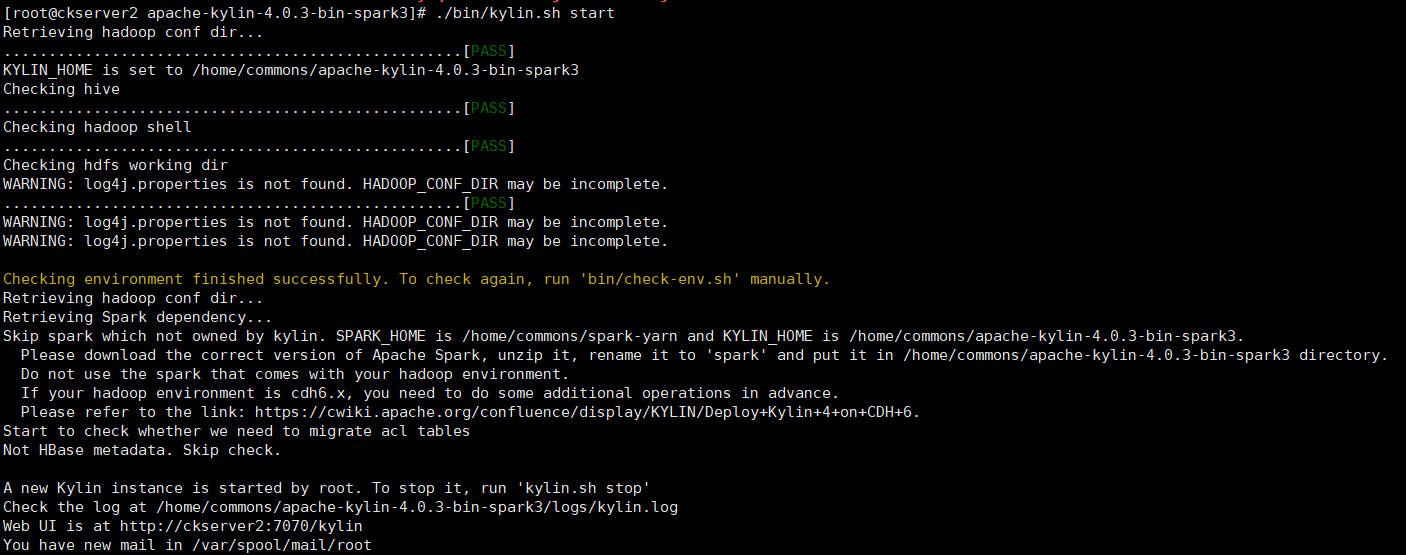
# 启动$KYLIN_HOME/bin/kylin.sh start
# 麒麟启动的默认端口为7070。可以使用$KYLIN_HOME/bin/kylin-port-replace-util.sh set number修改端口。修改后的端口号为“7070 +编号”。$KYLIN_HOME/bin/kylin-port-replace-util.sh set number 1# 停止$KYLIN_HOME/bin/kylin.sh start
# 重启$KYLIN_HOME/bin/kylin.sh restart
# 可以查看运行日志tail-f logs/kylin.log

使用步骤
Apache Kylin™ 令使用者仅需三步就可实现超大数据集上的亚秒级查询。
- 定义数据集上的一个星型或雪花模型。
- 在定义的数据表上构建cube。
- 使用标准 SQL 通过 ODBC、JDBC 或 RESTFUL API 进行查询,仅需亚秒级响应时间即可获得查询结果。
官方样例Cube说明
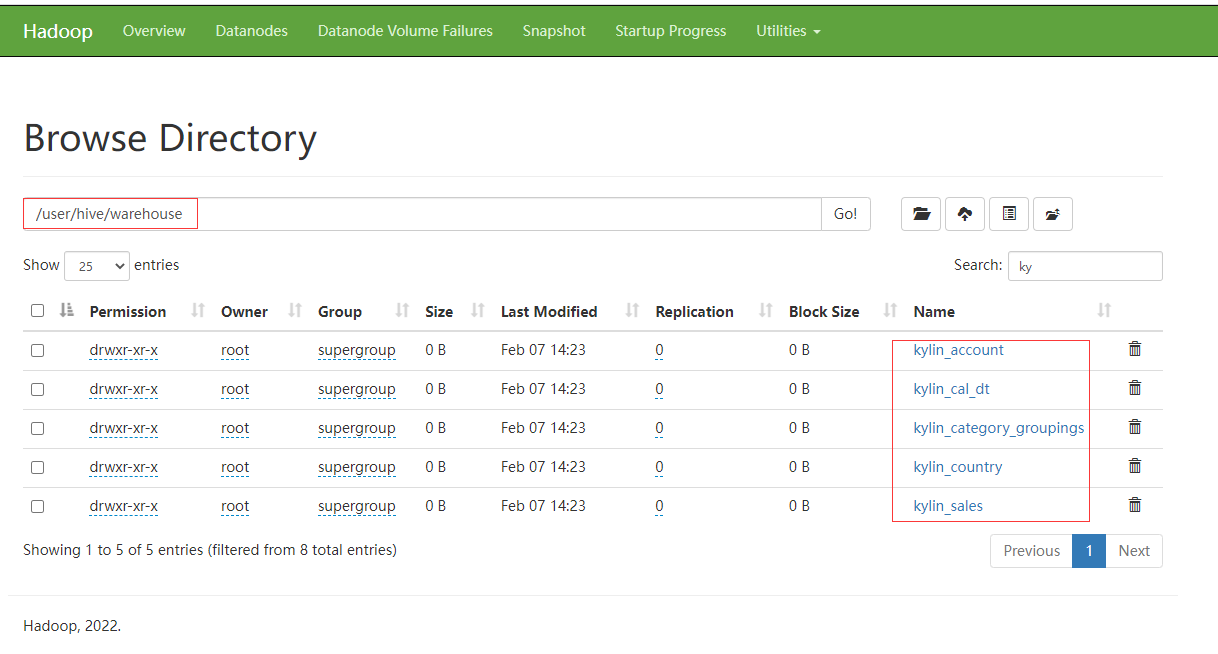
# 使用Kylin安装目录下示例快速体验Kylin,先执行一个脚本来创建一个示例多维数据集$KYLIN_HOME/bin/sample.sh
执行脚本完成后,查看hive default默认数据库下已经有相应的
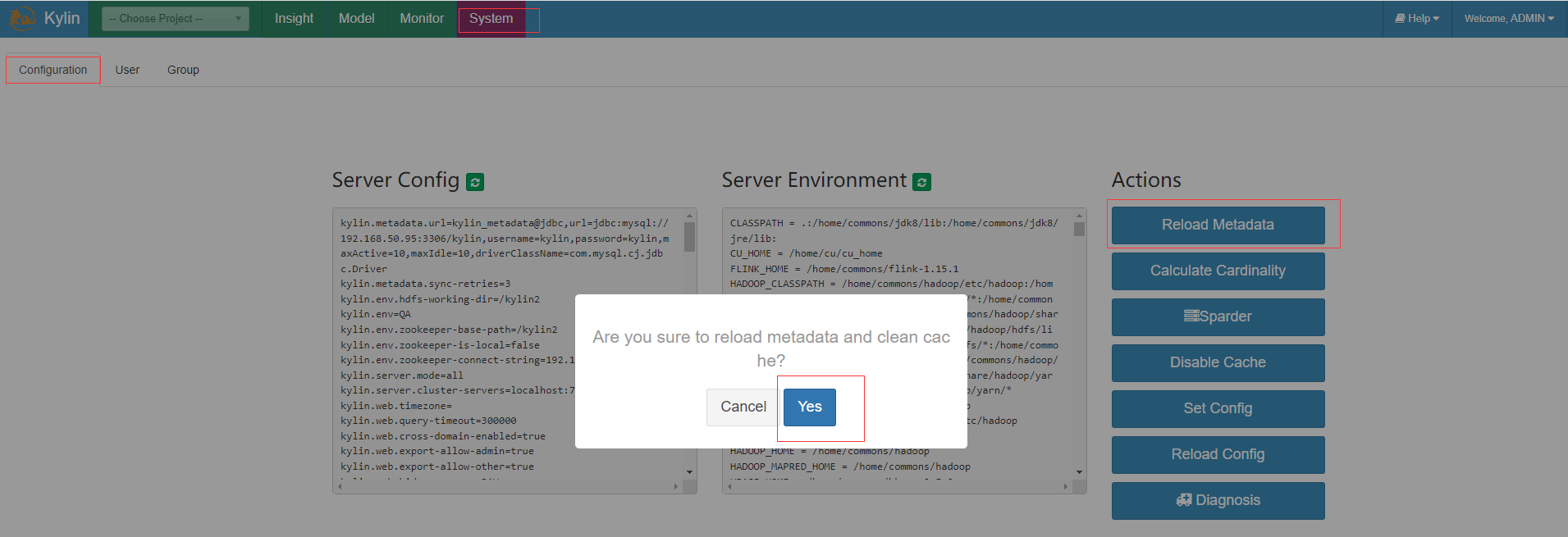
通过kylin的WebUI click System -> Configuration -> Reload Metadata 加载元数据信息
重新加载元数据后,可以在左上角的project中看到一个名为learn_kylin的项目,这个项目包含一个批处理多维数据集kylin_sales_cube和一个流数据集kylin_streaming_cube。
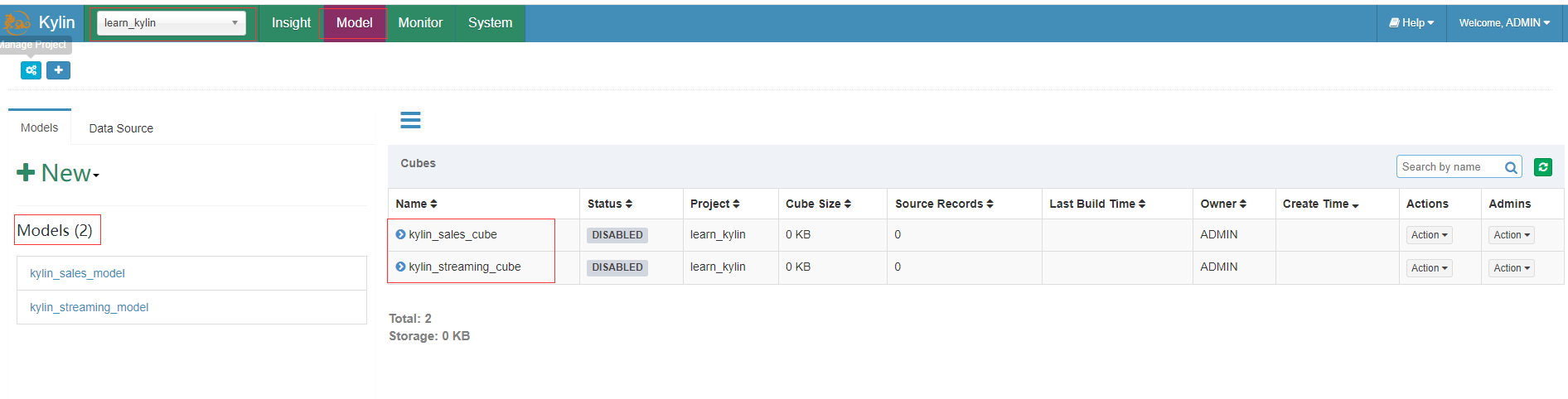
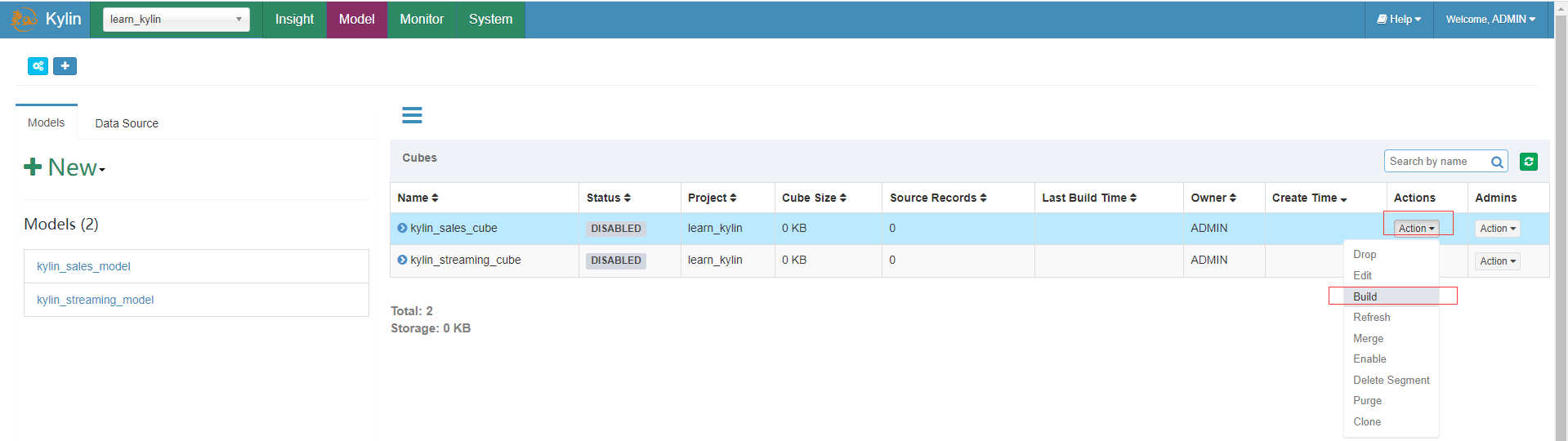
可以直接构建kylin_sales_cube,并且可以在构建完成后查询它。
示例演示
准备演示数据
- hive中创建kylin数据库,并创建dept部门表和emp员工表
createdatabase kylin;use kylin;create external tableifnotexists dept(
deptno int,
dname string,
loc int)row format delimited fieldsterminatedby'\t';create external tableifnotexists emp(
empno int,
ename string,
job string,
mgr int,
hiredate string,
sal double,
comm double,
deptno int)row format delimited fieldsterminatedby'\t';
- 制作示例数据
mkdir tmpdata
# 制作部门表(dept.txt)数据vim tmpdata/dept.txt
100 ACCOUNTING 1700200 RESEARCH 1800300 SALES 1900400 OPERATIONS 1700# 制作员工表(emp.txt)数据vim tmpdata/emp.txt
1336 SMITH CLERK 18692016-01-03 2800.01000.02001466 ALLEN SALESMAN 16652016-03-08 5600.01500.03001488 WARD SALESMAN 16652016-03-10 4375.02500.03001533 JONES MANAGER 18062016-04-18 10412.56000.02001621 MARTIN SALESMAN 16652016-10-14 4375.07000.03001665 BLAKE MANAGER 18062016-05-17 9975.04000.03001749 CLARK MANAGER 18062016-06-25 8575.03500.01001755 SCOTT ANALYST 15332022-05-05 10500.06800.02001806 KING PRESIDENT NULL 2016-12-03 17500.020000.01001811 TURNER SALESMAN 16652016-09-24 5250.03000.03001843 ADAMS CLERK 17552022-06-08 3850.02500.02001867 JAMES CLERK 16652016-12-19 3325.02400.03001869 FORD ANALYST 15332016-12-19 10500.08000.02001901 MILLER CLERK 17492017-02-08 4550.03200.0100
- 加载示例数据到hive相应表中
load data local inpath '/home/commons/apache-kylin-4.0.3-bin-spark3/tmpdata/dept.txt' into table dept;
load data local inpath '/home/commons/apache-kylin-4.0.3-bin-spark3/tmpdata/emp.txt' into table emp;
创建项目
点击左上角的+来创建一个Project,输出项目名称和描述点击提交按钮

选择数据源
- 选择加载数据源方式,选择第二个可以从hive中加载数据,第三个可以从 csv 文件加载数据。

- 同步要作为数据源的表,上面点击后第一次需要加载元数据会有点慢,加载过后续就快了
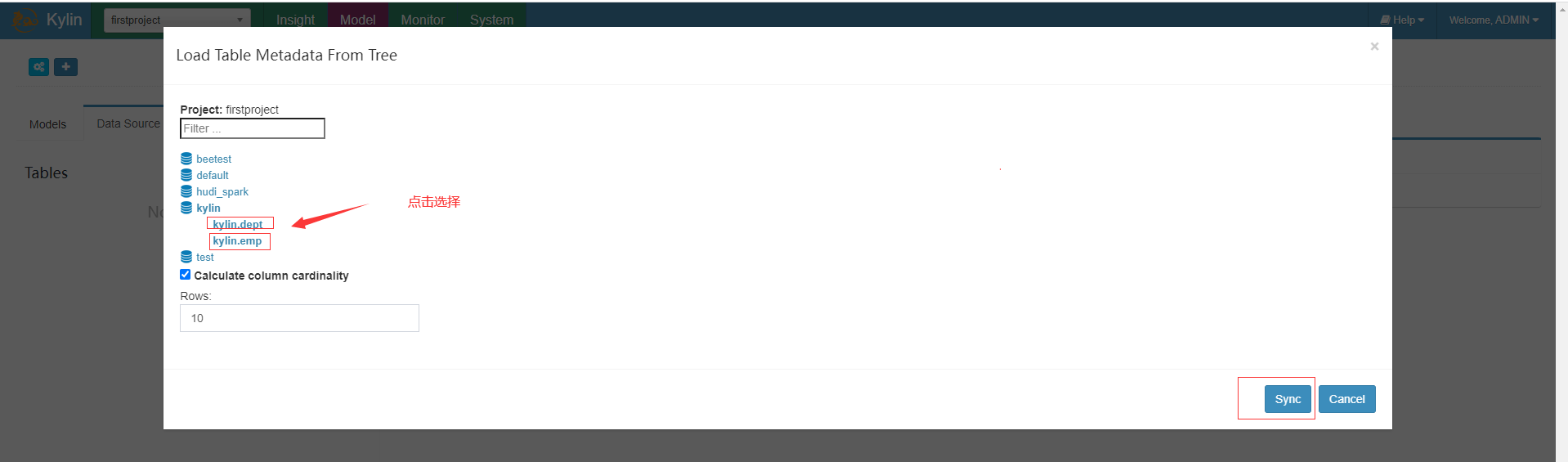
- 加载
创建Model
在Models页面的左边点击New按钮后点击New Model,填写Model名称及描述后Next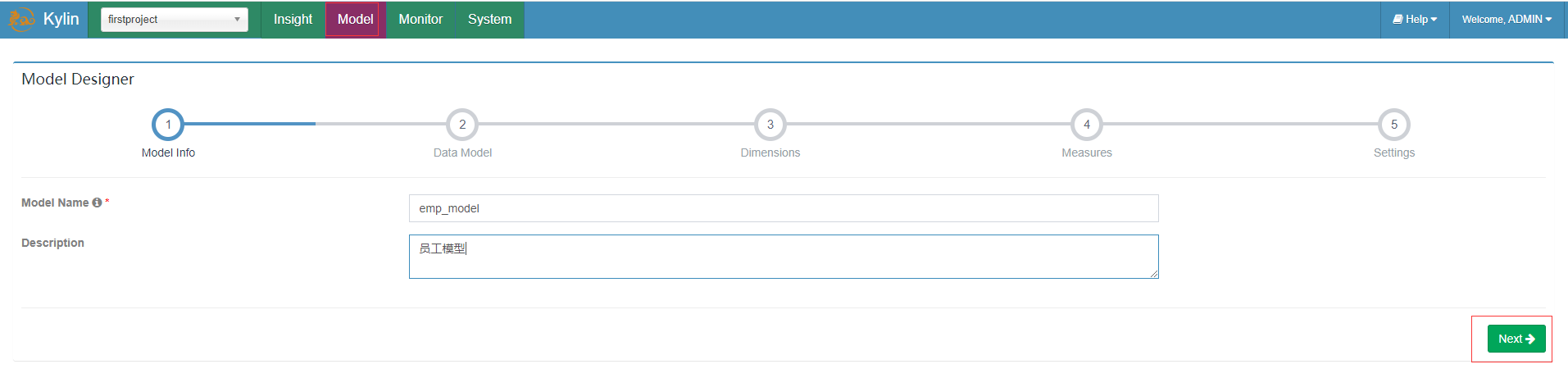
选择员工作为Fact Table事实表,添加部门作为Lookup Table维度表
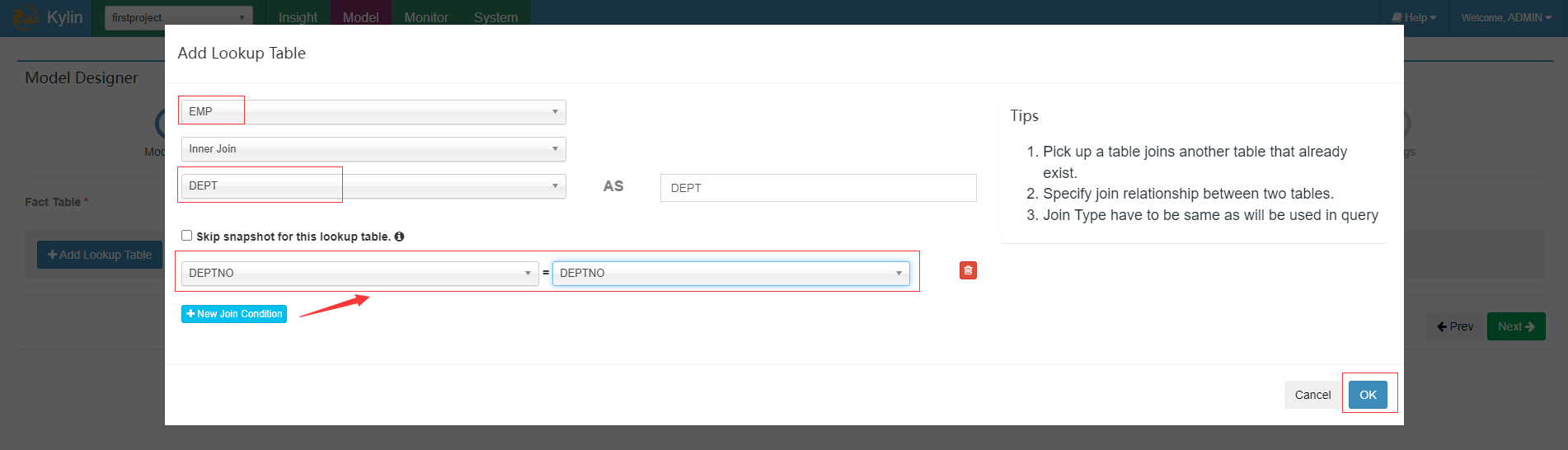
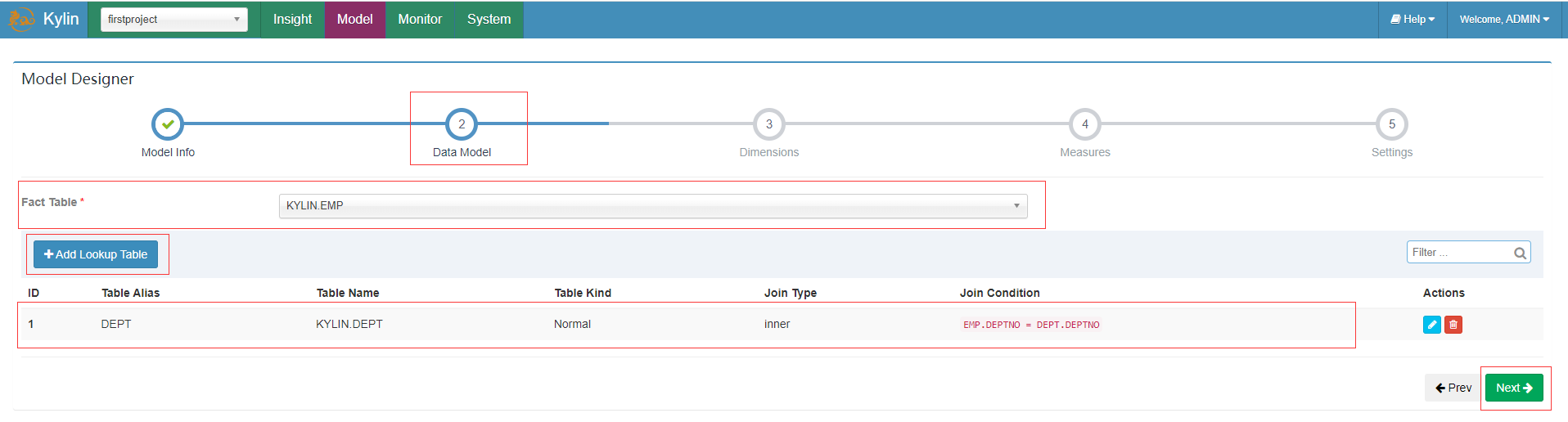
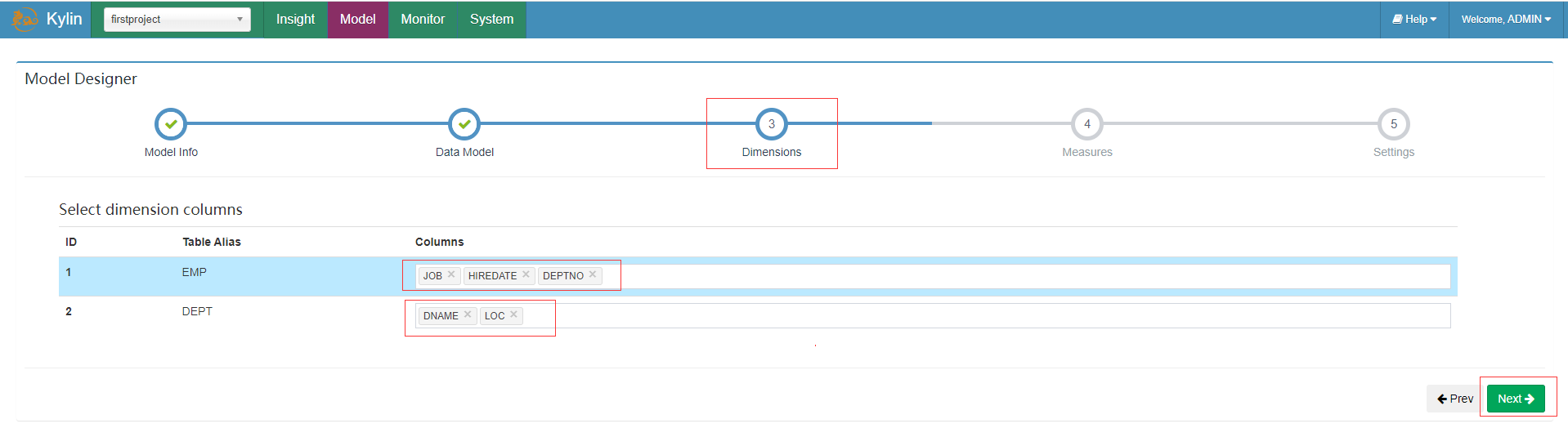
选择维度信息
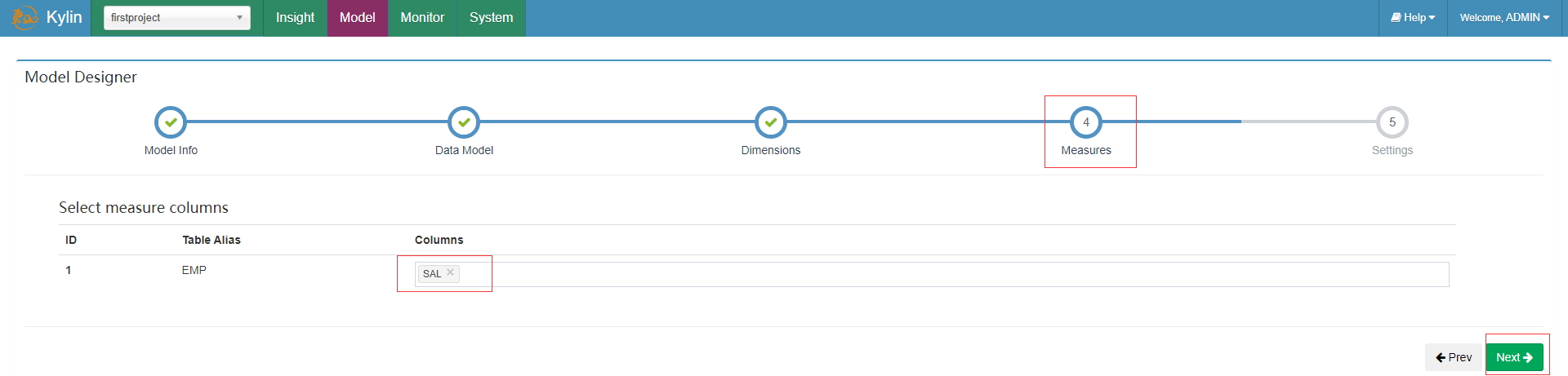
选择度量信息
添加分区信息(这里没有做分区表)及过滤条件这里我们暂时不填写保持默认,点击“Save”并确认保存模型。
创建Cube
在Models页面的左边点击New按钮后点击New Cube,选择员工Model及填写Cube Name,点击next
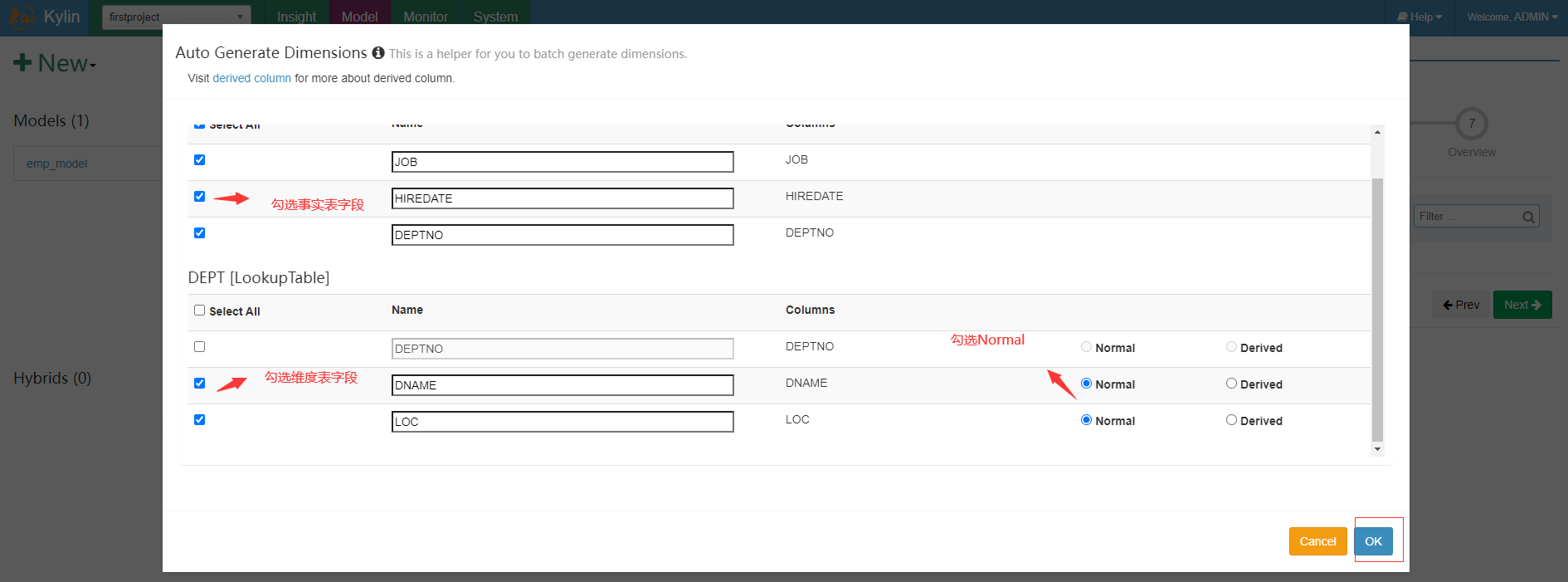
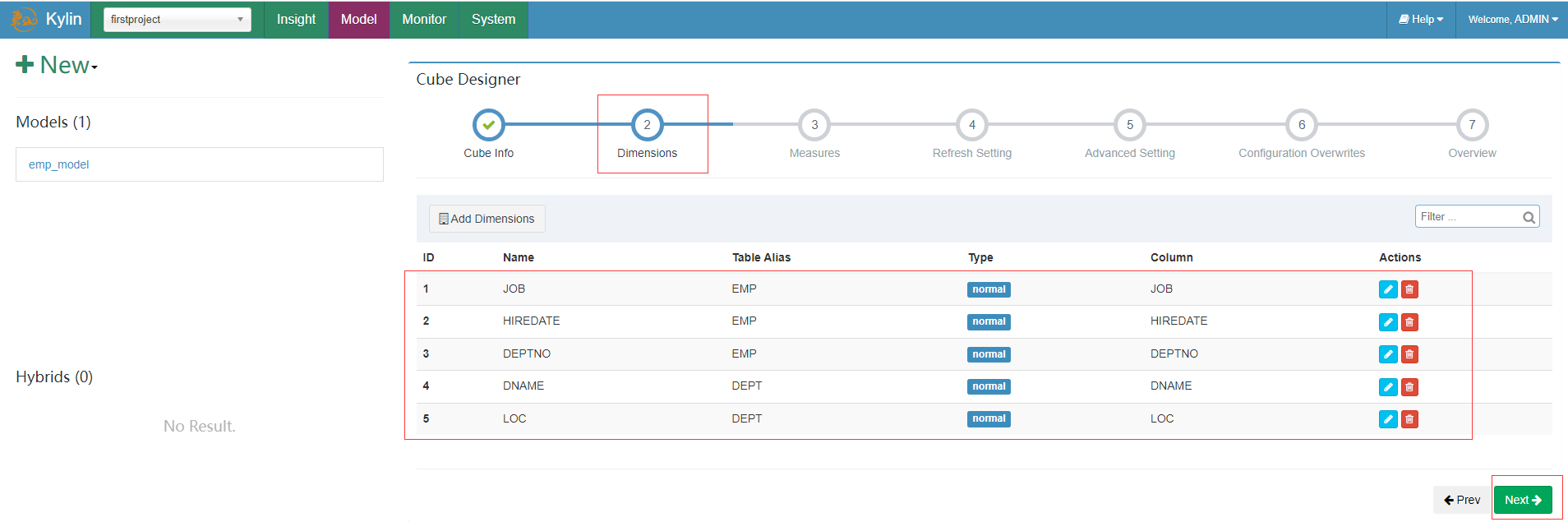
添加真正维度字段,(将来会影响 Cuboid 的个数,并且只能从 model 维度字段里面选择),点击ok并点击下一步
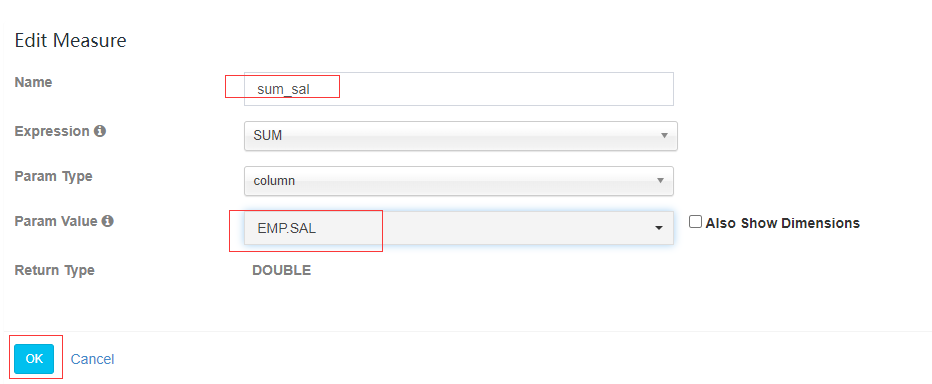
添加真正度量值字段(将来预计算的字段值,只能从 model 度量值里面选择),点击度量添加按钮“+ Measure”,填写信息并点击ok,并选择next
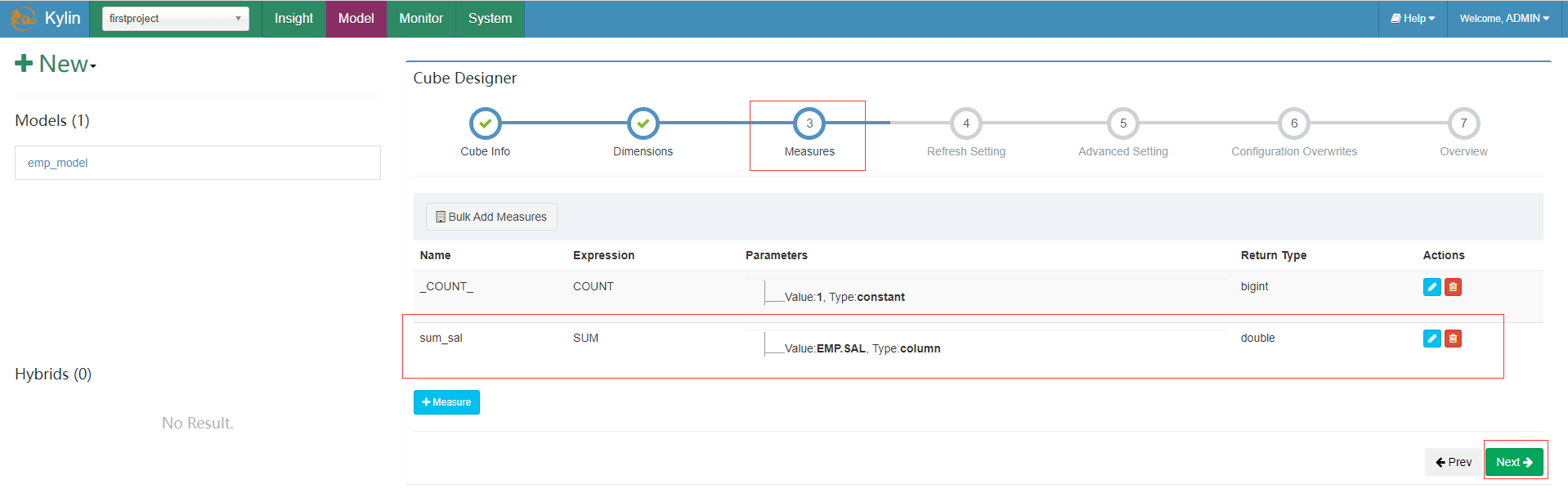
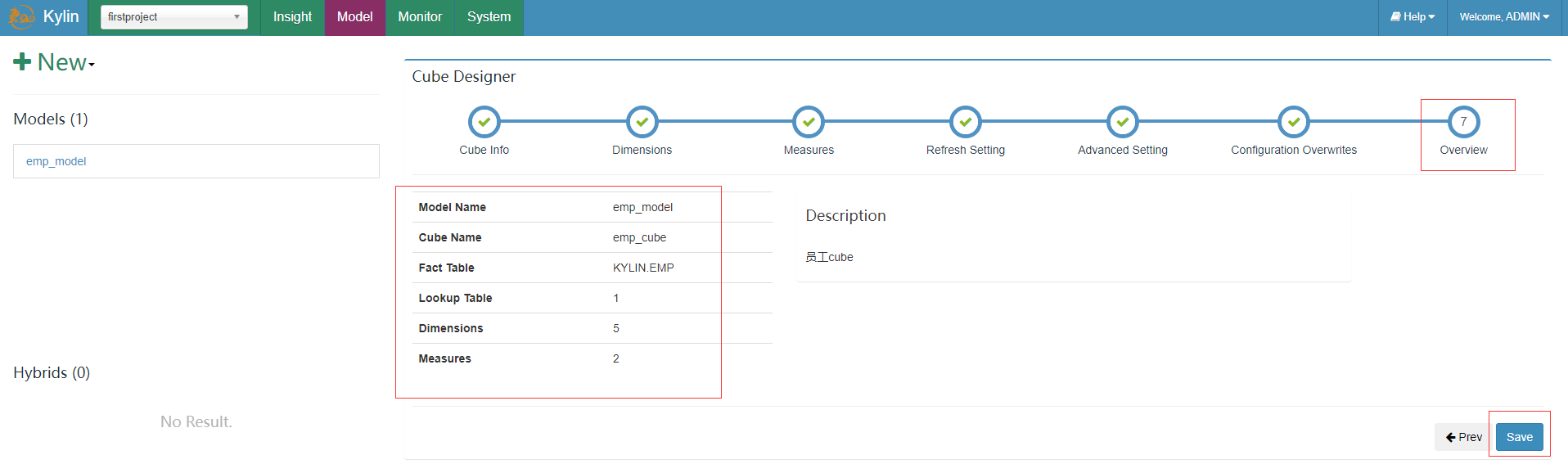
接着刷新设置、高级设置、配置覆盖都先保持默认的,最后查看概览点击save按钮并确定保存
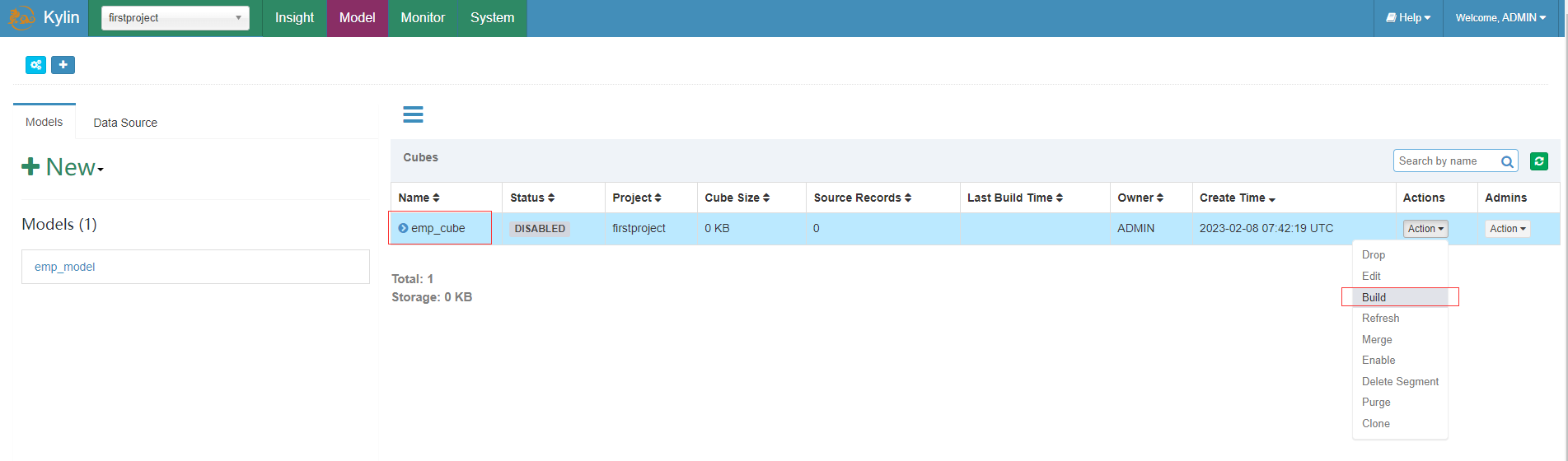
Cube构建
在上面创建的cube上点击build构建action动作,并确认开始构建
查看当前正在构建的情况
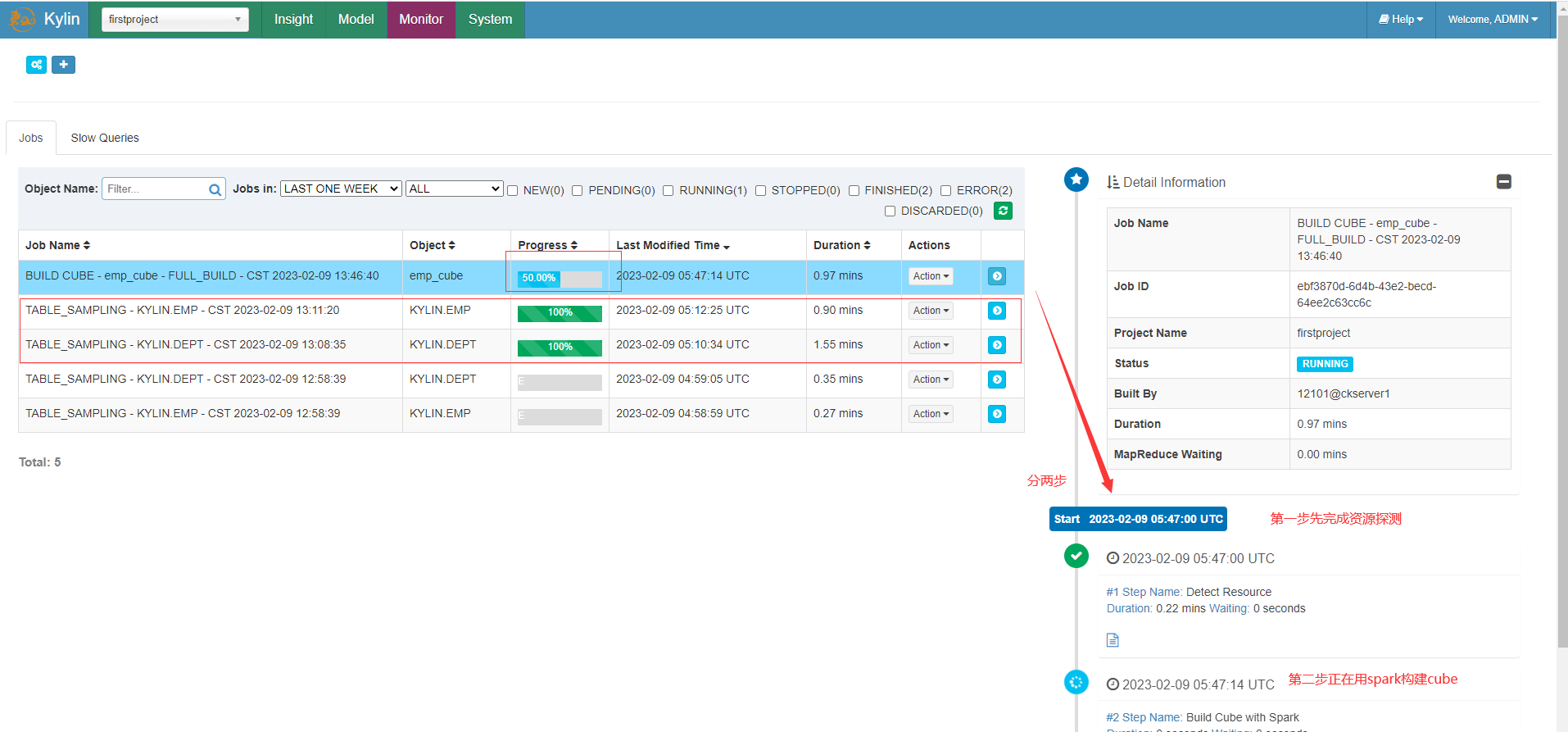
等待一会后构建完成
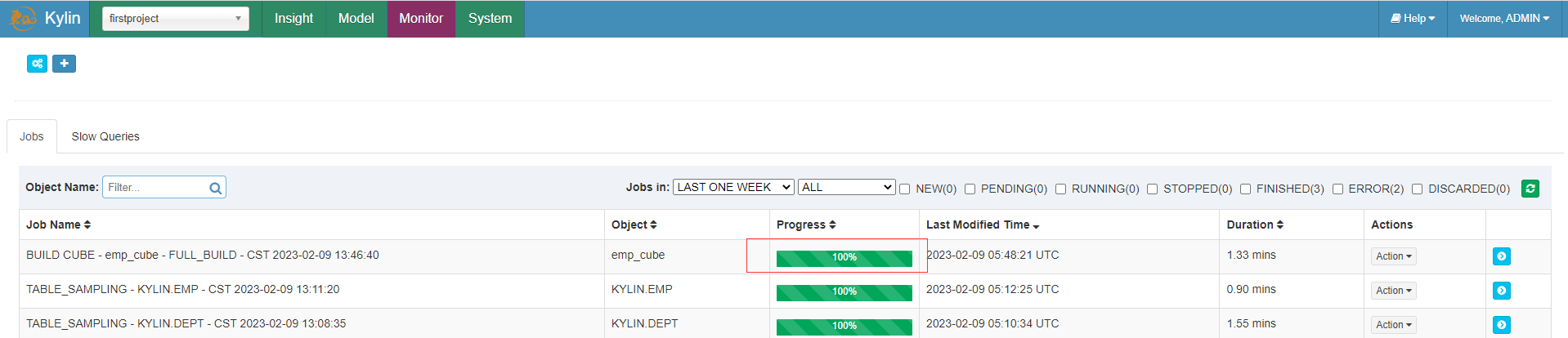
与Hive查询对比
在Insight洞察页面新查询框中输入sql语句
select dept.dname,sum(emp.sal)from emp join dept on emp.deptno = dept.deptno groupby dept.dname;
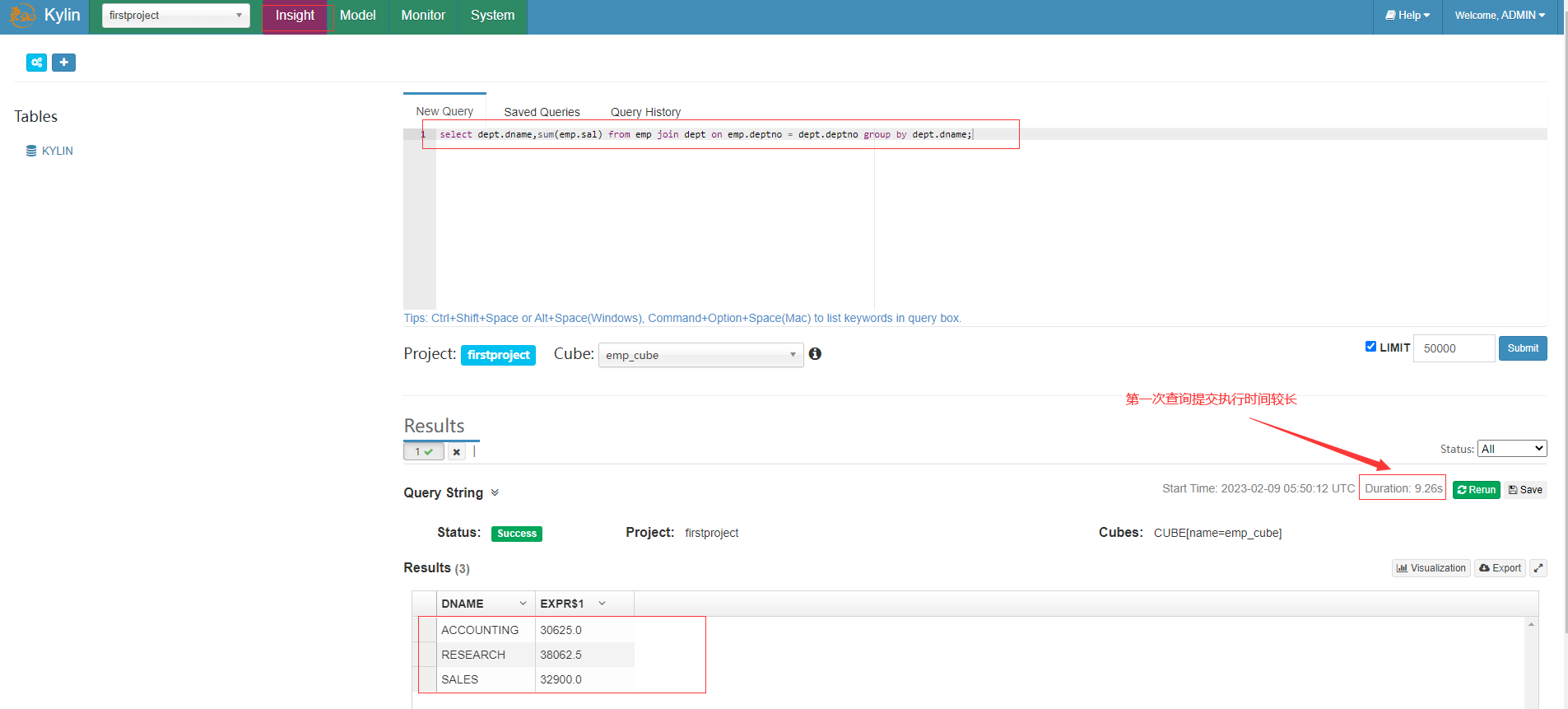
第一次之后的查询都是秒级响应

相比下面在hive中执行查询快了非常多

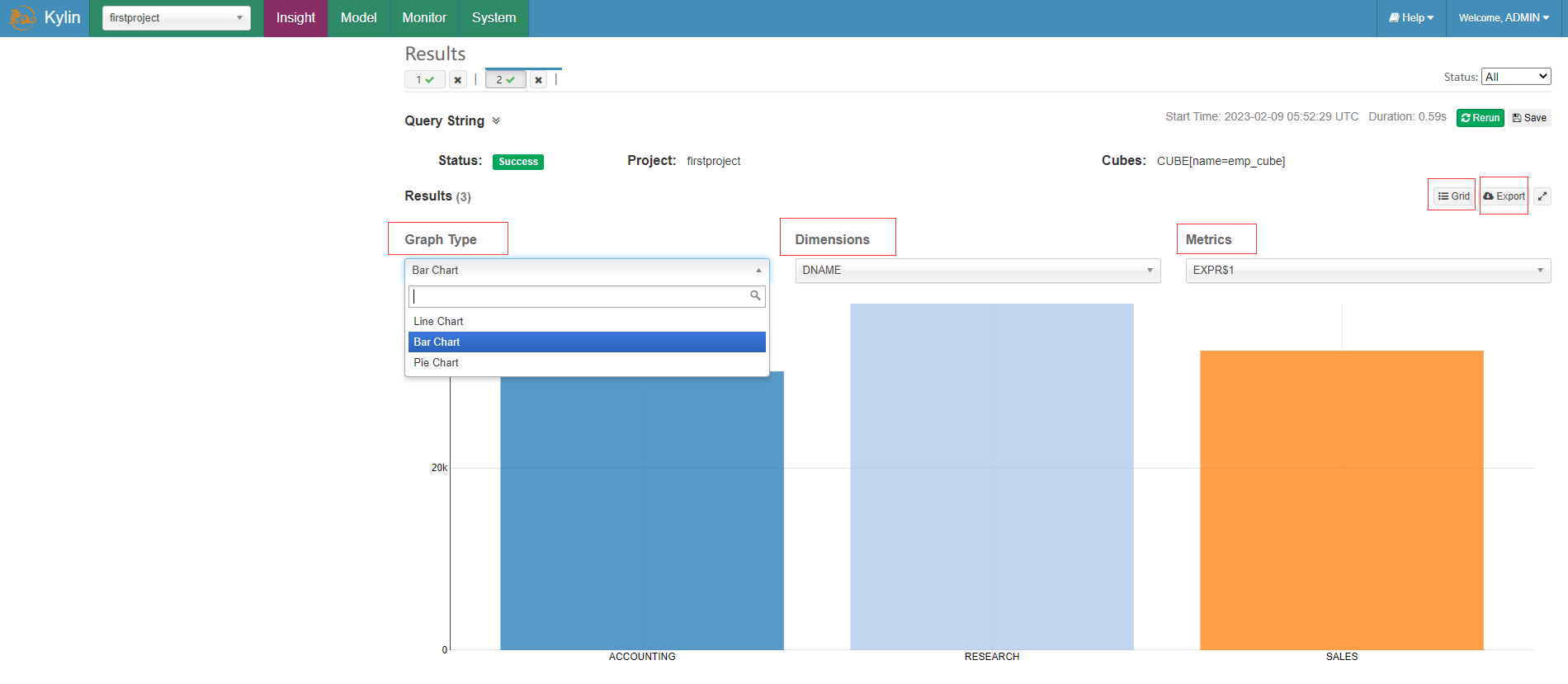
可以针对查询结果点击Grid按钮实现图形可视化,选择图标类型、维度和度量信息展示,还可以选择导出csv文件结果
- 本人博客网站IT小神 www.itxiaoshen.com
版权归原作者 IT小神 所有, 如有侵权,请联系我们删除。