
1. YOLOv8环境安装
YOLOv8的运行环境主要包括四部分:
1)PyCharm
PyCharm 是一款由 JetBrains 开发的 Python 集成开发环境(IDE),提供了智能代码补全、实时错误检查、快速修复等功能,帮助开发者提高 Python 编程的效率和质量。
软件链接:Download PyCharm: Python IDE for Professional Developers by JetBrainshttps://www.jetbrains.com/pycharm/download/?section=windows#section=windows
** 2)Miniconda**
Miniconda 是一个小巧的 Python 环境管理工具,它包含了 conda 软件包管理器和 Python,一旦安装了 Miniconda,就可以使用 conda 命令安装任何其他软件工具包并创建环境。
软件链接:Index of /anaconda/miniconda/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirrorhttps://mirrors.tuna.tsinghua.edu.cn/anaconda/miniconda/
3)Pytorch
PyTorch 是一个由 Facebook 开发的开源深度学习框架,它提供了灵活、直观的接口和强大的 GPU 加速,支持动态神经网络和丰富的 API 和工具,使得构建和训练复杂的机器学习模型变得更加容易。
软件链接:PyTorchhttps://pytorch.org/
4)ultralytics(YOLOv8)
YOLOv8 是一款最新的、先进的实时物体检测模型,它在前几代 YOLO 的成功基础上引入了新的功能和改进,以提高性能和灵活性,可以在从 CPU 到 GPU 的各种硬件平台上运行。
源码链接:GitHub - ultralytics/ultralytics: NEW - YOLOv8 🚀 in PyTorch > ONNX > OpenVINO > CoreML > TFLitehttps://github.com/ultralytics/ultralytics
该部分的安装可以参考
【手把手带你实战YOLOv8-入门篇】YOLOv8 环境安装_哔哩哔哩_bilibili【手把手带你实战YOLOv8-入门篇】YOLOv8 环境安装, 视频播放量 27489、弹幕量 19、点赞数 514、投硬币枚数 438、收藏人数 1106、转发人数 247, 视频作者 你可是处女座啊, 作者简介 github地址:https://github.com/zyds,相关视频:【手把手带你实战YOLOv8-入门篇】YOLOv8 模型预测,【手把手带你实战YOLOv8-入门篇】YOLOv8 模型训练,【yolov8】从0开始搭建部署YOLOv8,环境安装+推理+自定义数据集搭建与训练,一小时掌握,花3个小时,适合所有新手人群的【YOLOv8训练自己的数据集】教程,环境安装+源码解读+代码实战,分分钟学透!翻遍全网找不到比这更详细的了!(人工智能课程),五分钟学会 - YOLOv8从训练到部署与推理,从入门到精通,YOLOv8正式发布!零基础教程YOLOv8推理及训练(代码实战),【手把手带你实战YOLOv8-入门篇】YOLOv8 数据集构建,比外挂还离谱的【YOLO目标检测】自从用了YOLO玩枪战游戏,再也不用担心看不到人了!超详细YOLO目标物体检测实战教程(实战教程,快速入门!),零基础:编译器安装+深度学习环境配置+YOLOv8运行:第三部分YOLOv8运行,【手把手带你实战YOLOv5-入门篇】YOLOv5 环境安装(重置版)https://www.bilibili.com/video/BV13V4y1S7MK/?spm_id_from=333.788
***恭喜恭喜,您已经成功完成以上4个内容,接下来可以进行下一步操作了!!!
2. 数据集构建
在计算机视觉中,数据集是一组用于训练、验证和测试计算机视觉模型的图像或视频。数据集通常包含大量的标注信息,如图像中物体的位置、类别等。
数据集在计算机视觉中的重要性主要体现在以下几个方面:
(1)训练模型:通过大规模的图像数据集,计算机视觉算法可以学习到图像的特征和语义信息,从而实现图像分类、目标检测、人脸识别等任务。
(2)评估模型:数据集也用于评估模型的性能。通过在相同的数据集上评估不同的模型,可以比较它们的性能。
(3)推动研究:公开的数据集可以推动计算机视觉的研究。例如,飞飞姐的ImageNet数据集的发布极大地推动了深度学习在计算机视觉中的应用。
2.1 数据准备
(1)图片类型数据:无需额外处理,直接进行标注


(2)视频类型数据:进行抽帧处理,导出为图片



# 视频抽帧处理程序
import cv2
video = cv2.VideoCapture('./DINO.mp4')
num = 0 # 计数器
save_step = 60 # 间隔帧
while True:
ret, frame = video.read()
if not ret:
break
num += 1
if num % save_step == 0:
cv2.imwrite('./train/demo_images/' + str(num) + '.jpg', frame)
2.2 数据集标注程序、网页及软件
(1)Labelimg
LabelImg是图形图像标注工,用Python编写的,并将Qt用于其图形界面,可以用于进行目标检测项目的标注工作。

labelimg教程可以参考:
使用labelImg做图像标注_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1Jp4y1k7QG/?spm_id_from=333.337.search-card.all.click&vd_source=5f4b20d0e5c3da5309d6a393f8eb94a1
(2)LabelMe
Labelme 是一个图形界面的图像标注软件。它是用 Python 语言编写的,图形界面使用的是 Qt(PyQt)。

【labelme】13分钟教会你使用labelme的超详细教程_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1xT4y1j7A9/?spm_id_from=333.337.search-card.all.click&vd_source=5f4b20d0e5c3da5309d6a393f8eb94a1
(3)MakeSense
基于JavaScript开发用于图像目标检测的标注工具,使用React+Redux进行开发,支持Windows和Linux平台运行。

3.3 MakeSense定义标签_哔哩哔哩_bilibili原书信息:清华大学出版社-图书详情-《TensorFlow+Android经典模型从理论到实战(微课视频版)》 http://www.tup.tsinghua.edu.cn/booksCenter/book_09703501.html第3章 EfficientDet与美食场景检测当你读完第3章时,你应该能够:l 熟悉和理解美食数据集的结构特点。l 了解解决目标检测问题的技术路线。l 掌握一种为数, 视频播放量 224、弹幕量 0、点赞数 3、投硬币枚数 0、收藏人数 4、转发人数 5, 视频作者 水木智联, 作者简介 万物智联,智联万物,相关视频:【附源码】用Python轻松破解WiFi 密码伸手就来!!再也不用担心流量不够用啦!!,【比刷剧还爽!】从入门到精通CNN、RNN、GAN、GNN、DQN、Transformer、LSTM等八大深度学习神经网络一口气学完!这不比刷剧爽多了!,2023年12月最新ChatGPT4.0国内保姆级使用教程,12月份最新ChatGPT来了,国内无限制免费使用教程!,全新YOLOV5实战课程!整整18集,大佬带你玩转YOLOV5实战项目!(含源码)—YOLOV5实战、YOLOV5、计算机视觉、目标检测,(免费) 让任何软件AI实时渲染!打通AI最后500米(一键包2.0版),普通人千万不要学Python!!!,吹爆!想学好线代一定不能错过的《线性代数可视化手册》,搞定它,你的线代就搞定了90%!,【无人驾驶项目】使用机器学习的真实世界自动驾驶车辆安全规划,入门到提高全套教程!,太稳啦!全新方法的T-Rex标注神器!通过视觉提示进行交互式目标计数!!-深度学习/机器学习/计算机视觉https://www.bilibili.com/video/BV1ss4y1u731/?spm_id_from=333.337.search-card.all.click
(4)精灵标注助手(Colabeler)
相比于Labelme,LabelImg这些标注工具,精灵标注助手强大的地方在于支持实例分割、目标检测、文本标注、音频标注和视频标注等 ,并且完全免费。

数据标注软件精灵标注助手比labelme好用_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1PW4y167Ez/?spm_id_from=333.337.search-card.all.click&vd_source=5f4b20d0e5c3da5309d6a393f8eb94a1
(5)CVAT
CVAT是一个免费的、在线的、交互式的视频注释工具,支持本地部署,无需担心数据外泄。它支持多人协作,能用于几乎所有CV相关标注任务,如点,多边形,语义分割等。

图像标注平台CVAT的安装和使用_哔哩哔哩_bilibili这个视频介绍了图像标注平台CVAT (computer vision annotation tool) 的安装和使用方法。CVAT可以使用docker工具来安装,安装基础功能很方便;如果希望安装半自动标注功能是通过配置nuclio中的serverless功能来实现的;最后简单介绍一下如何CVAT的界面标注数据。官方文档:https://opencv.github.io/cvat/docs/admi, 视频播放量 2866、弹幕量 5、点赞数 49、投硬币枚数 23、收藏人数 121、转发人数 35, 视频作者 太阳照常升起233, 作者简介 ,相关视频:医学图像分割实战:基于U-Net模型的医学细胞图像分割+基于Deeplab的医学心脏图像分割实战精讲,原理详解+项目实战,看完就能跑通!,肝脏肿瘤图像分割、心脏图像分割、细胞图像分割全详解!B站最全面的医学图像分割实战教程分享,原理详解+项目实战,看完就能跑通!,数据标注任务员,在家搬砖就能日赚100200,平台分享,2023年人工智能医学领域两大热门项目:基于Transformer的图像分割+基于Resnet的医学数据集分类【从原理到实战】,太稳啦!全新方法的T-Rex标注神器!通过视觉提示进行交互式目标计数!!-深度学习/机器学习/计算机视觉,这也太全了!Pandas、Seaborn、Numpy、Matplotlib四大Python数据科学必备工具包实战全教程学到爽!Python数据分析,WACV2024:可变性大核注意力医学图像分割,“ChatGPT超详细免费教程”无需魔法 国内直接使用,【无人驾驶项目】使用机器学习的真实世界自动驾驶车辆安全规划,入门到提高全套教程!,完全自学!跟着老师三周拿下【机器学习Halcon】从入门到实战!整整63集学到爽!含配套课程资源—机器视觉、计算机视觉、CV、人工智能、图像处理、图像匹配https://www.bilibili.com/video/BV1Yh4y1R7ZD/?spm_id_from=333.337.search-card.all.click
(6)VIA(VGG Image Annotator)
一款开源的图像标注工具,由Visual Geometry Group开发。可以在线和离线使用,可标注矩形、圆、椭圆、多边形、点和线。
神经网络训练样本制作工具 VGG Image Annotator (via) 小教程_哔哩哔哩_bilibilihttps://www.bilibili.com/video/BV1SZ4y1p7xd/?spm_id_from=333.337.search-card.all.click&vd_source=5f4b20d0e5c3da5309d6a393f8eb94a1
2.3 公开的CV数据集网站
(1)谷歌数据库:Dataset Search (google.com)
谷歌数据集搜索是一个在线工具,允许用户搜索、发现和访问各种来源的数据集,包括政府机构、学术机构、企业和个人贡献者。这些数据集涵盖广泛的主题,包括医疗保健、金融、气候、交通、社会科学和艺术。
(2)RobolFlow:All Projects | Roboflow Universe Search
Roboflow 是一个提供一站式解决方案的平台,用户可以在该平台上上传、组织、标注、增强和处理数据集,然后简化训练过程,并通过多种部署选项加速模型的部署。该平台提供了许多已经标注好的yolo格式的数据集,可直接下载使用。
(3)VisualData:VisualData Discovery - Search Engine for Computer Vision Datasets
VisualData是一个专用于搜索计算机视觉数据集和代码/模型的搜索引擎。该网站现已收集281个计算机视觉数据集,用户可以在该网站上通过简单的搜索找到适合自己项目的数据集。
(4)ImageNet:ImageNet (image-net.org)
ImageNet是市场上最大、最受欢迎的开源数据集之一。ImageNet拥有超过1400万张已手动标注的图像。数据库按WordNet层次结构予以组织,对象级标注通过边界框完成。
(5)LSUN:https://www.yf.io/p/lsun
LSUN数据集为场景理解(房间布局估计,显着性预测等)提供了许多辅助任务。
(6)COCO:COCO - Common Objects in Context (cocodataset.org)
COCO是大规模的对象检测,分割和字幕数据集,包含超过200,000张带标签的图像。
3. 模型训练
3.1 训练前准备
在机器学习中,我们通常会将数据集划分为训练集、验证集和测试集:
- 训练集:训练集用于模型的训练,即用于调整模型的参数。这就像是学生的课本,用于日常的知识巩固。
- 验证集:验证集用于模型的调整和评估。它可以用来选择和调整模型的超参数,以及对模型的能力进行初步评估。这就像是学生的周考,用来纠正和强化学到的知识。
- 测试集:测试集用于评估模型的最终性能,即模型的泛化能力。但它不能用于调整模型的参数或选择特征等算法相关的选择。这就像是学生的期末考试,用来最终评估学习效果。
在实际应用中,训练集、验证集和测试集的划分比例一般遵循6:2:2的原则。这三个数据集的数据分布应该是近似的,但它们所用的数据是不同的。这样做的目的是为了使模型的训练效果能合理地泛化至测试效果,从而推广应用至现实世界中。同时,模型在训练集、验证集和测试集上所反映的预测效果可能存在差异。
示例:杂草检测
目前已经获取到了60张杂草图片,并利用labelimg进行了杂草数据的标注。由于图片数量较少,这里将编号119+3160共计49张图片作为训练集,将编号20~30共计11张图片作为验证集。
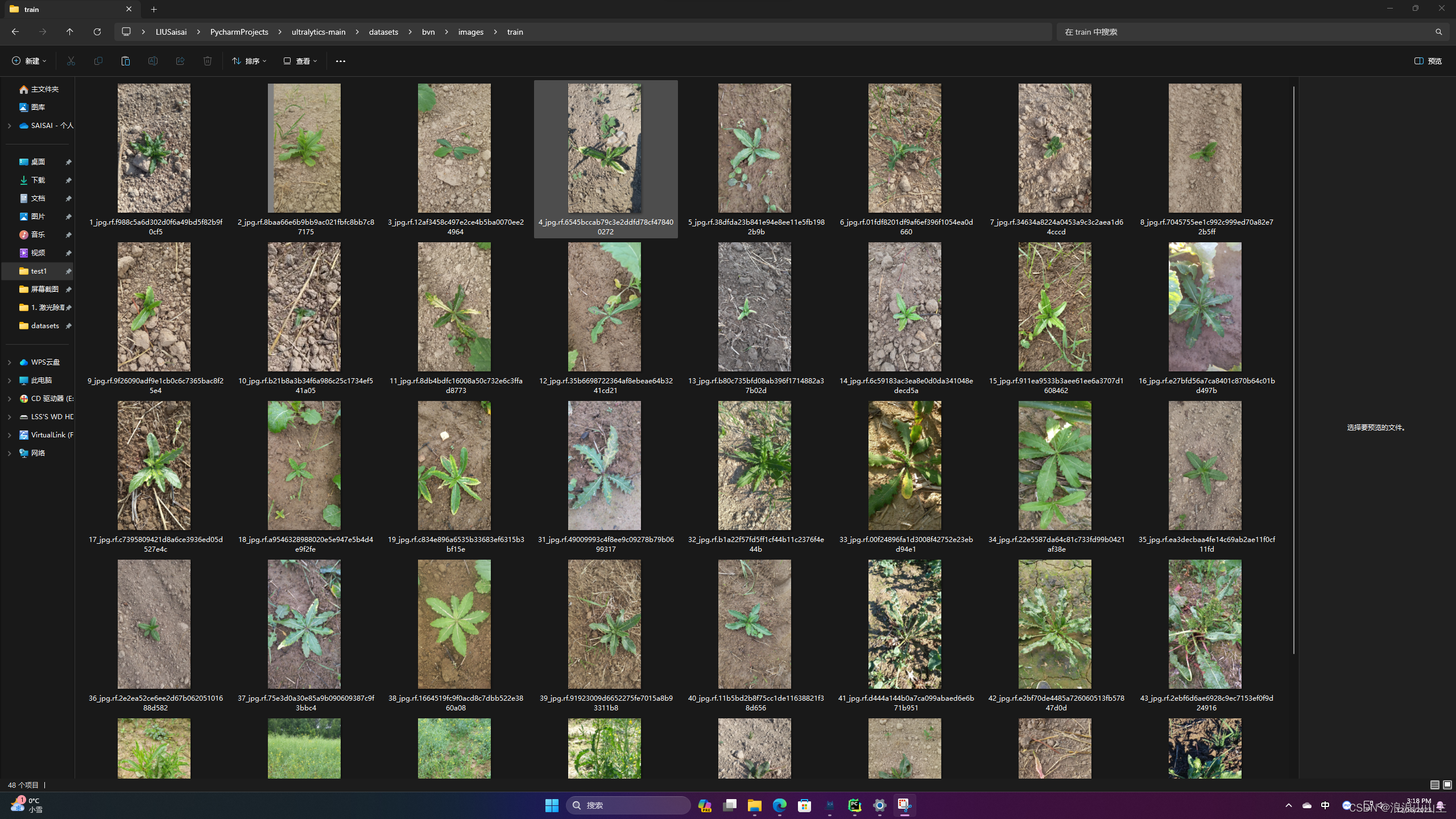

首先需要对源图片以及处理好的进行文件整理,文件的结构可以如下图所示:
bvn # 数据集名称
images # 存放图片
train # 训练集图片
val # 验证集图片
labels # 存放标签(图片中不同类别的定位数据)
train # 训练集标签文件,要与训练集图片名称一一对应
val # 验证集标签文件,要与验证集图片名称一一对应
3.2 Pycharm杂草识别教程
**Step1: **首先,先从Ultralytics官方网站上下载源码(这一步是方便后续操作)并解压。
**Step2: **新建Pycharm项目,命名为ultralytics-main。在资源管理器中打开ultralytics-main目录,将Step1中的文件复制粘贴到该目录下。完成后的Pycharm页面如下图所示:
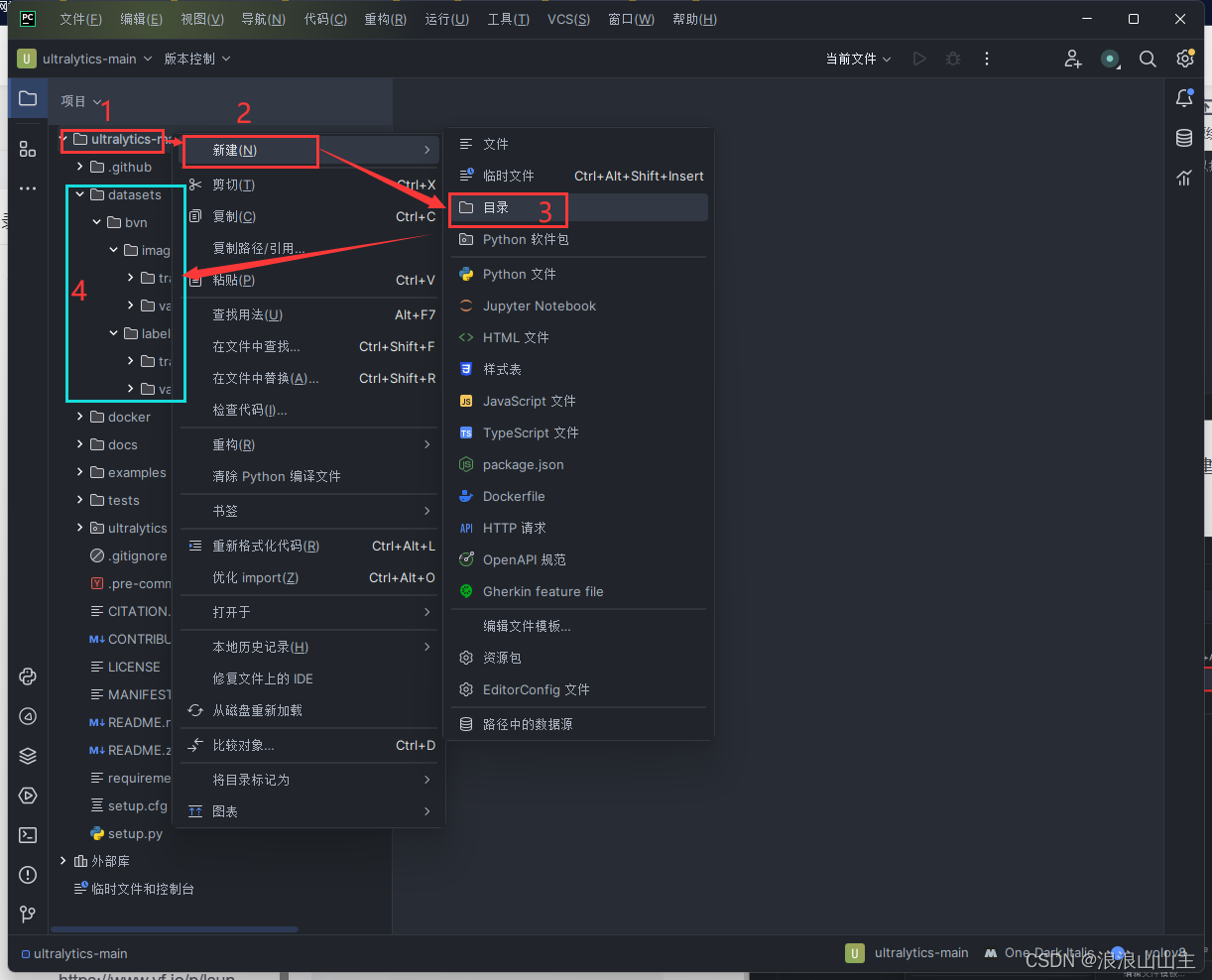
**Step3: **Pycharm环境中,在项目ultralytics-main下新建目录datasets(不可改变名称,否则后续操作会报错),在资源管理器中打开datasets目录,将含有训练集和验证集的文件夹bvn复制粘贴到该目录下。完成后的页面如下图所示:
**Step4: **创建配置文件。在项目ultralytics-main下新建文件yolo-bvn.yaml,键入以下内容。
path: bvn # 数据集目录
train: images/train # 训练集图片目录
val: images/val # 验证集图片目录
test: # 没有设置测试集图片,此处为空即可
# Classes
names:
0: bodyak
1: osot
2: shchavel
**Step5: **通过代码运行。在项目ultralytics-main下新建文件yolov8-train.py文件,键入以下内容。
from ultralytics import YOLO
# load a model
model = YOLO('yolov8n.pt')
# Train the model
model.train(data='yolo-bvn.yaml', workers=0, epochs=50, batch=16)
# windows平台,此处的workers必须设置为0,否则报错。
**Step6: **选择在当前文件运行。运行完成后项目里会出现“runs”文件夹。在runs_ detect_ train_ weights中包含了计算得到的最优模型和最后的模型。

Step7: 验证模型的准确性。选择验证集中的一张照片,验证所得到的最优模型的准确性。在pycharm终端中输入:
yolo detect predect model=runs/detect/train11/weights/best.pt source=./25.jpg show=True


4. 结语
目标检测只是计算视觉中很小的一部分,还有分类、动态跟踪、定位等一系列的工作。我这是个新手,上面的内容虽然看似简单,但却花费了我一个月时间去购置主机、配置yolov8环境、搜寻数据集、标注、跑程序等。接下来我会继续更新关于杂草识别与定位的个人研究内容,欢迎大家持续关注。
版权归原作者 浪浪山山主 所有, 如有侵权,请联系我们删除。