
文章目录
1. 前言
Pytorch2.0和GPT4、文心一言同一时间段发布,可谓是热闹至极,我看了看Pytorch 2.0的文档,一句话概括下,2.0的功能介绍,核心就是
torch.compile
:
opt_module = torch.Compile(module)
加入这行代码就能优化你的模型,优化后的模型和往常使用方式一样,推理速度会提升,比较重要的一点是,可以用于训练或者部署,训练可以传梯度,这次是带有AOTautograd的。然而需要注意的是,这行代码(编译)本身会消耗不少时间。
Pytorch官方在A100上测试了三个模型仓库的模型,加速比如下: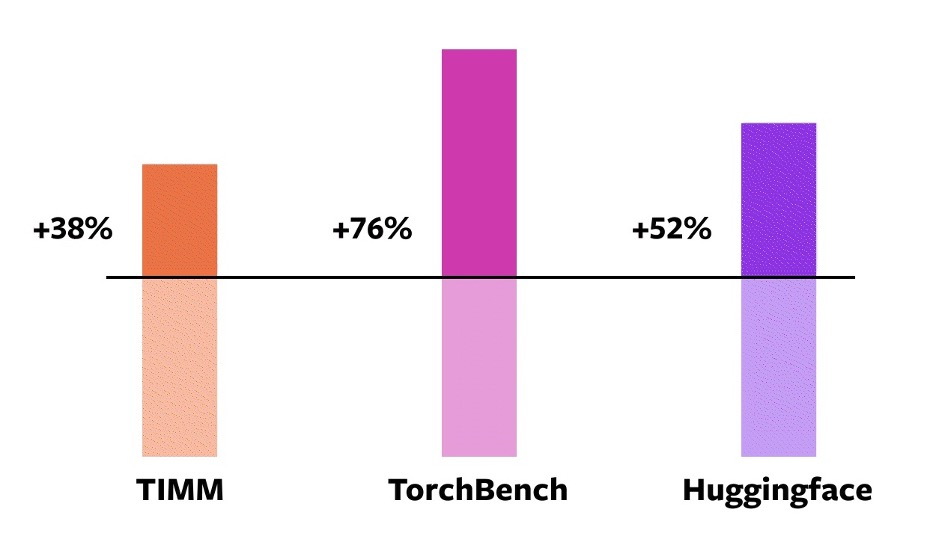
Speedups for torch.compile against eager mode on an NVIDIA A100 GPU
看起来很不错。那废话不多说,来看看怎么用。
2. 安装和使用Pytorch 2.0
要安装pytorch2.0首先得上pytorch官网:
需要注意的是,Pytorch 2.0只支持python3.8以上的版本,老环境记得升级一下。
按照官方提供的渠道安装完torch之后,就可以应用到自己的代码里了。这里我简单写一个用来做图像分类的神经网络。
import torch
import torch.nn as nn
import torch._dynamo
# ------ 加入这行,查看编译步骤 ------ #
torch._dynamo.config.verbose=True# ------ 加入这行,跳过异常 ------ #
torch._dynamo.config.suppress_errors =TrueclassThdCNN(nn.Module):# 网络结构deffit(**args):# 训练和测试
model= ThdCNN(image_size, num_classes)# 声明和定义神经网络# ------ 加入这行代码,model可选:default(compile), reduce-overhead, max-autotune ------ #
opt_model = torch.compile(model, mode="default")
optimizer = torch.optim.Adam(opt_model.parameters())# 定义优化器
fit(opt_model,**args)# 训练和测试
我对三种加速模式进行了一个Epoch的测试(编译用时+训练和测试用时),结果如下:
模型无加速default(compile)reduce-overheadmax-autotuneCNN(CPU)101s8s+78s8s+85s9s+81sCNN(CUDA)92s7s+77s8s+75s8s+71s
可能是由于模型太小了,所以三种加速模式的效果差距不大,但按照官方的描述,三种模式的适用情况应该是:
- default(compile):针对大模型优化,编译时间短,没有额外的内存使用;
- reduce-overhead:针对小模型优化,用于减少框架开销,会使用一些额外的内存;
- max-autotune:模型整体优化,用于生成最优模型,但编译时间长。
3. 结语
Pytorch2.0与1.x是完全兼容的,因此基本上不会出现迁移错误,不过新特性还有很多没有玩明白的特性,所以在写代码的时候如果出现其他问题,可以参照 故障排除 解决。
compile的控制参数:
def torch.compile(model: Callable,*,
mode: Optional[str]="default",
dynamic:bool=False,
fullgraph:bool=False,
backend: Union[str, Callable]="inductor",# advanced backend options go here as kwargs**kwargs
)-> torch._dynamo.NNOptimizedModule
- mode 指定编译器在编译时应该优化什么,包括efault(compile), reduce-overhead, max-autotune。
- dynamic 是否启用动态形状追踪。
- fullgraph 类似于 Numba 的nopython. 是否将模型分解成几个子图。
- backend要使用的后端。默认情况下,使用 TorchInductor,所有的后端可以通过
torchdynamo.list_backends()查看。
本文转载自: https://blog.csdn.net/baishuiniyaonulia/article/details/129613933
版权归原作者 白水baishui 所有, 如有侵权,请联系我们删除。
版权归原作者 白水baishui 所有, 如有侵权,请联系我们删除。