
SeleniumWire快速爬取数据
一、安装所需的库
在终端使用pip进行安装 pip install xxx
import tkinter
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
二、设置浏览器启动选项
这里我使用的是Chrome,其中列举了几个常用的option,供大家学习使用
- option = webdriver.ChromeOptions():设置Chrome启动选项
- option.add_argument(‘headless’):不打开浏览器进行数据爬取,因为没有可视化过程,所以推荐整个流程开发完毕后,在使用此条代码。
- option.add_experimental_option(“prefs”, {“profile.managed_default_content_settings.images”: 2}):如果网页中的图片对你没有太大作用,可以不加载网页图片,以提高爬取速度。
- option.add_experimental_option(“detach”, True):防止程序执行完浏览器自动关闭
- 配置浏览器路径和驱动路径(若使用已安装的浏览器,则不需要配置,需要手动安装chromedriver) option.binary_location = r’./chrome-win64/chrome.exe’ driver_path = r"./chromedriver-win64/chromedriver.exe"
- driver = webdriver.Chrome(service=Service(driver_path), options=option):加载以上配置,若第5步未配置,则使用driver = webdriver.Chrome(options=option)即可
- driver.maximize_window():最大化浏览器
- driver.implicitly_wait(60):设置隐式等待时长为60s,以后在更新Selenium的三种等待方式
option = webdriver.ChromeOptions()
option.add_argument('headless')# 不使用浏览器ui
option.add_experimental_option("prefs",{"profile.managed_default_content_settings.images":2})# 不加载网页图片
option.add_experimental_option("detach",True)#
option.binary_location =r'./chrome-win64/chrome.exe'
driver_path =r"./chromedriver-win64/chromedriver.exe"
driver = webdriver.Chrome(service=Service(driver_path), options=option)
driver.maximize_window()
driver.implicitly_wait(60)
三、使用账号密码登录网址
如果爬取的网站需要登陆,可使用selenium.find_element进行登录
# 登录
driver.get("your url")# 登录的url
driver.find_element(by=By.ID, value='mobile').send_keys('your username')
driver.find_element(by=By.ID, value='passwd').send_keys('your password')
driver.find_element(by=By.ID, value='submitButton').click()# 这里是你登录之后的操作'''your code '''
四、seleniumwire.requests爬取数据
- for request in driver.requests为固定写法,其含义为:获取Network中的所有请求的url,然后进行遍历 2.if request.method == ‘POST’ and request.url == ‘your url’:当遍历的请求满足你设置的条件,例如为POST请求和指定的url,执行response。 这里的url是你需要爬取的网址,在所有的请求中,你需要查看哪个请求是你需要的

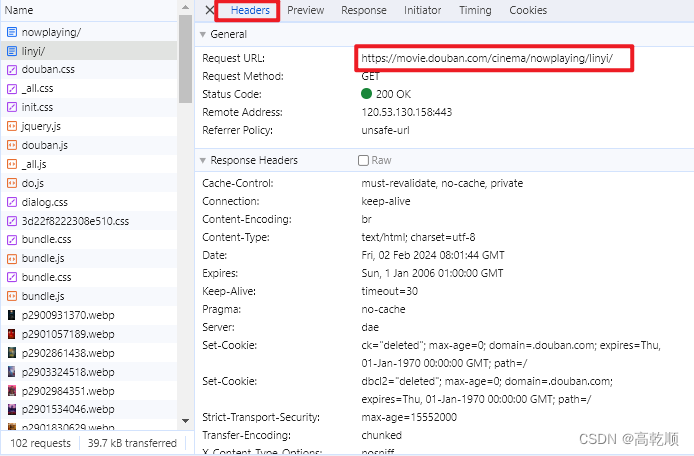
3.data = request.response.body:通过request返回response请求的body
4.html一般会将网页的数据进行压缩以节省空间,如果为Gzip压缩方式,可用以下固定的方式解压缩,最终的htmls为字符串形式。
5.driver.requests.clear():将每次的请求关闭,以释放资源。
# 使用seleniumwire.requests爬取数据for request in driver.requests:if request.method =='POST'and request.url =='your url':
data = request.response.body
buff = BytesIO(data)
f = gzip.GzipFile(fileobj=buff)
htmls = f.read().decode('utf-8')print('response data: ', htmls)
driver.requests.clear()
五、数据清洗和保存
返回的response是页面中的所有数据,数据清洗可使用正则表达式,也可使用beautifulsoup,这两种方法之后在进行汇总
# 正则表达式清洗数据
data_code = re.findall(r'data_code\D+(\d+)', htmls)
pay_time = re.findall('"pay_time":"(.*?)"', htmls)
vehicle_id = re.findall('"vehicle_id":"(.*?)"', htmls)
pay_type = re.findall(r'pay_type\D+(\d+)', htmls)# pandas保存数据到Excel中
data ={'数据编号': data_code,'时间': pay_time,'标识': vehicle_id,'类型': pay_type}
df = pd.DataFrame(data)
df.index +=1
df.to_excel('data.xlsx')
代码汇总
import tkinter
from seleniumwire import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
# 配置chrome
option = webdriver.ChromeOptions()
option.add_argument('headless')
option.add_experimental_option("prefs",{"profile.managed_default_content_settings.images":2})
option.add_experimental_option("detach",True)
option.binary_location =r'./chrome-win64/chrome.exe'
driver_path =r"./chromedriver-win64/chromedriver.exe"
driver = webdriver.Chrome(service=Service(driver_path), options=option)
driver.maximize_window()
driver.implicitly_wait(60)# 登录
driver.get("your url")# 登录界面的url
driver.find_element(by=By.ID, value='mobile').send_keys('your username')
driver.find_element(by=By.ID, value='passwd').send_keys('your password')
driver.find_element(by=By.ID, value='submitButton').click()# 这里是你登录之后的操作,可使用find_element转到需要爬取的数据界面'''your code '''# 使用seleniumwire.requests爬取数据for request in driver.requests:if request.method =='POST'and request.url =='your url':
data = request.response.body
buff = BytesIO(data)
f = gzip.GzipFile(fileobj=buff)
htmls = f.read().decode('utf-8')print('response data: ', htmls)
driver.requests.clear()# 使用正则表达式对数据进行清洗
data_code = re.findall(r'data_code\D+(\d+)', htmls)
pay_time = re.findall('"pay_time":"(.*?)"', htmls)
vehicle_id = re.findall('"vehicle_id":"(.*?)"', htmls)
pay_type = re.findall(r'pay_type\D+(\d+)', htmls)# 将采集的数据保存到Excel中
data ={'数据编号': data_code,'时间': pay_time,'标识': vehicle_id,'类型': pay_type}
df = pd.DataFrame(data)
df.index +=1
df.to_excel('data.xlsx')
tkinter.messagebox.showinfo(title='提示', message='已采取完毕')
本文转载自: https://blog.csdn.net/weixin_43882148/article/details/135972630
版权归原作者 高乾顺 所有, 如有侵权,请联系我们删除。
版权归原作者 高乾顺 所有, 如有侵权,请联系我们删除。