
SQL的连接运算根据其特征的不同,有着不同的名称,如内连接、外连接、交叉连接等。一般来说,这些连接大都是以不同的表或视图为对象进行的,但针对相同的表或相同的视图的连接也并没有被禁止。针对相同的表进行的连接被称为“自连接”(self join)。一旦熟练掌握自连接技术,我们便能快速地解决很多问题。
理解自连接能增进我们对“面向集合”这一SQL语言重要特征的理解。面向对象语言以对象的方式来描述世界,而面向集合语言SQL以集合的方式来描述世界。自连接技术充分体现了SQL面向集合的特性。
1 可重排列、排列、组合
Products
name(商品名称) price(价格)
苹果 50
橘子 100
香蕉 80
这里所说的组合其实分为两种类型。一种是有顺序的有序对(ordered pair),另一种是无顺序的无序对(unordered pair)。有序对用尖括号括起来,如<1,2>;无序对用花括号括起来,如{1, 2}。在有序对里,如果元素顺序相反,那就是不同的对,因此<1, 2>≠<2, 1>;而无序对与顺序无关,因此{1, 2}={2, 1}。用学校里学到的术语来说,这两类分别对应着“排列”和“组合”。
用SQL生成有序对非常简单。像下面这样通过交叉连接生成笛卡儿积(直积),就可以得到有序对。
--用于获取可重排列的SQL语句
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2;
执行结果
name_1 name_2
------ ------
苹果 苹果
苹果 橘子
苹果 香蕉
橘子 苹果
橘子 橘子
橘子 香蕉
香蕉 苹果
香蕉 橘子
香蕉 香蕉
执行结果里每一行(记录)都是一个有序对。因为是可重排列,所以结果行数为3的平方=9。结果里出现了(苹果,苹果)这种由相同元素构成的对,而且(橘子,苹果)和(苹果,橘子)这种只是调换了元素顺序的对也被当作不同的对了。这是因为,该查询在生成结果集合时会区分顺序。
如何更改才能排除掉由相同元素构成的对呢?首先,为了去掉(苹果,苹果)这种由相同元素构成的对,需要像下面这样加上一个条件,然后再进行连接运算。
--用于获取排列的SQL语句
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2
WHERE P1.name <> P2.name;
执行结果
name_1 name_2
------ ------
苹果 橘子
苹果 香蕉
橘子 苹果
橘子 香蕉
香蕉 苹果
香蕉 橘子
加上WHERE P1.name <> P2.name这个条件以后,就能排除掉由相同元素构成的对,结果行数为排列=6。

● P1里的“苹果”行的连接对象为P2里的“橘子、香蕉”这两行
● P1里的“橘子”行的连接对象为P2里的“苹果、香蕉”这两行
● P1里的“香蕉”行的连接对象为P2里的“苹果、橘子”这两行
相同的表的自连接和不同表间的普通连接并没有什么区别,自连接里的“自”这个词也没有太大的意义。
接下来对(苹果,橘子)和(橘子,苹果)这样只是调换了元素顺序的对进行去重。
--用于获取组合的SQL语句
SELECT P1.name AS name_1, P2.name AS name_2
FROM Products P1, Products P2
WHERE P1.name > P2.name;
执行结果
name_1 name_2
------ ------
苹果 橘子
香蕉 橘子
香蕉 苹果
在加上“不等于”这个条件后,这条SQL语句所做的是,按字符顺序排列各商品,只与“字符顺序比自己靠前”的商品进行配对,结果行数为组合C(2,3)=3。
想要获取3个以上元素的组合时,像下面这样简单地扩展一下就可以了。这次的样本数据只有3行,所以结果应该只有1行。
--用于获取组合的SQL语句:扩展成3列
SELECT P1.name AS name_1, P2.name AS name_2, P3.name AS name_3
FROM Products P1, Products P2, Products P3
WHERE P1.name > P2.name
AND P2.name > P3.name;
name_1 name_2 name_3
------- -------- --------
香蕉 苹果 橘子
使用等号“=”以外的比较运算符,如“<、>、<>”进行的连接称为“非等值连接”。这里将非等值连接与自连接结合使用了,因此称为“非等值自连接”。在需要获取列的组合时,会经常使用。
“, >”和“<”等比较运算符不仅可以用于比较数值大小,也可以用于比较字符串(比如按字典序进行比较)或者日期等。
2 删除重复行
在关系数据库的世界里,重复行和NULL一样,都不受欢迎。
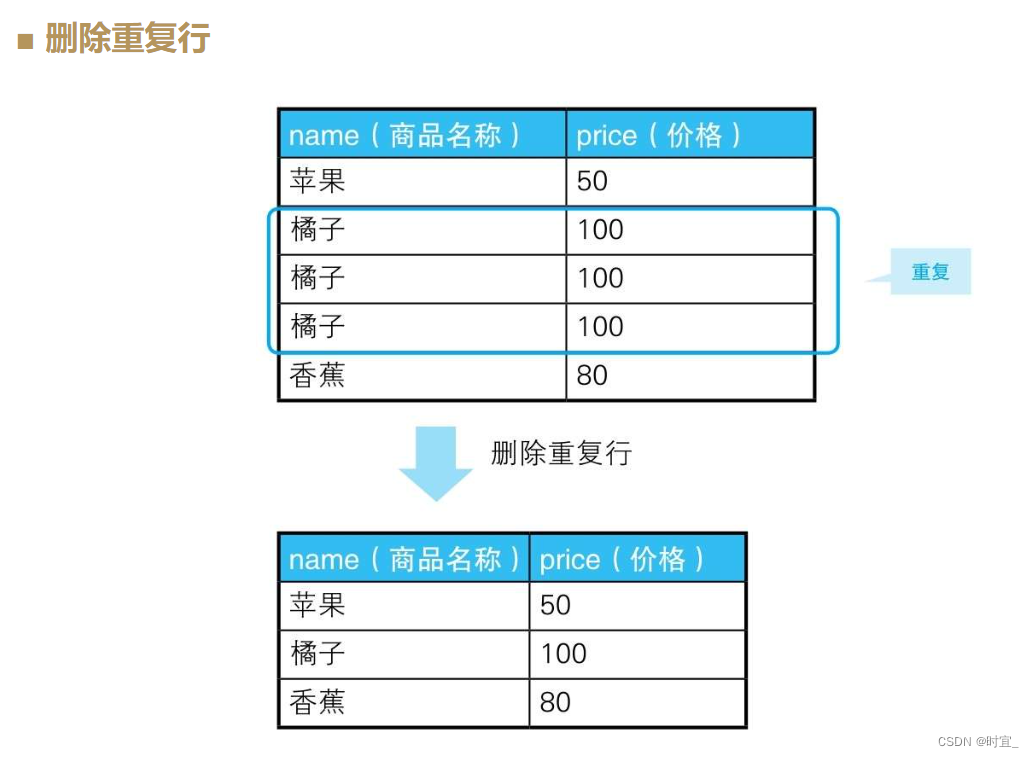
重复行有多少行都没有关系。通常,如果重复的列里不包含主键,就可以用主键来处理,但像这道例题一样所有的列都重复的情况,则需要使用由数据库独自实现的行ID。这里的行ID可以理解成拥有“任何表都可以使用的主键”这种特征的虚拟列。在下面的SQL语句里,我们使用的是Oracle数据库里的rowid。
--用于删除重复行的SQL语句(1):使用极值函数
DELETE FROM Products P1
WHERE rowid < ( SELECT MAX(P2.rowid)
FROM Products P2
WHERE P1.name = P2. name
AND P1.price = P2.price ) ;
(没理解)
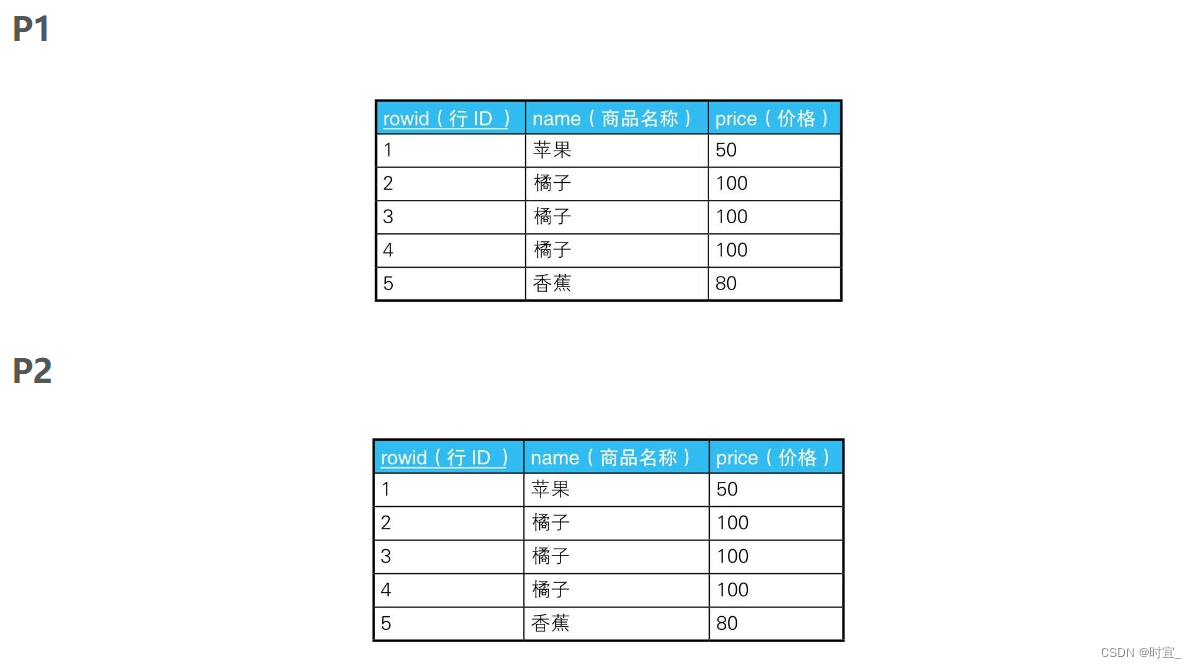
这里的重点也与前面的例题一样,对于在SQL语句里被赋予不同名称的集合,我们应该将其看作完全不同的集合。这个子查询会比较两个集合P1和P2,然后返回商品名称和价格都相同的行里最大的rowid所在的行。
于是,由于苹果和香蕉没有重复行,所以返回的行是“1:苹果”“5:香蕉”,而判断条件是不等号,所以该行不会被删除。而对于“橘子”这个商品,程序返回的行是“4:橘子”,那么rowid比4小的两行——“2:橘子”和“3:橘子”都会被删除。
(还是没理解)
通过这道例题我们明白,如果从物理表的层面来理解SQL语句,抽象度是非常低的。“表”“视图”这样的名称只反映了不同的存储方法,而存储方法并不会影响到SQL语句的执行和结果,因此无需有什么顾虑(在不考虑性能的前提下)。无论表还是视图,本质上都是集合——集合是SQL能处理的唯一的数据结构。
用前面介绍过的非等值连接的方法也可以写出与这里的执行过程一样的SQL语句。
--用于删除重复行的SQL语句(2):使用非等值连接
DELETE FROM Products P1
WHERE EXISTS ( SELECT *
FROM Products P2
WHERE P1.name = P2.name
AND P1.price = P2.price
AND P1.rowid < P2.rowid );
3 查找局部不一致的列
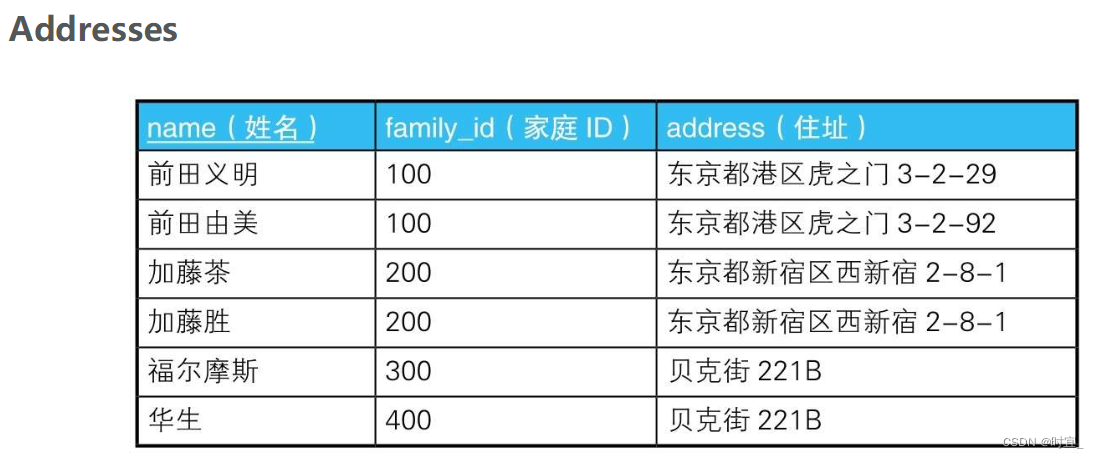
如果家庭ID一样,住址也必须一样。因此这里需要修改一下。那么我们该如何找出像前田夫妇这样的“是同一家人但住址却不同的记录”呢?
实现办法有几种,不过如果用非等值自连接来实现,代码会非常简洁。
--用于查找是同一家人但住址却不同的记录的SQL语句
SELECT DISTINCT A1.name, A1.address
FROM Addresses A1, Addresses A2
WHERE A1.family_id = A2.family_id
AND A1.address <> A2.address ;

和前面的住址表那道题的结构完全一样。家庭ID→价格;住址→商品名称
--用于查找价格相等但商品名称不同的记录的SQL语句
SELECT DISTINCT P1.name, P1.price
FROM Products P1, Products P2
WHERE P1.price = P2.price
AND P1.name <> P2.name;
执行结果
name price
------ ------
苹果 50
葡萄 50
草莓 100
橘子 100
香蕉 100
请注意,这里与住址表那道例题不同,如果不加上DISTINCT,结果里就会出现重复行。关键在于价格相同的记录的条数。而就住址表来说,如果前田家有孩子,那么不在代码中加上DISTINCT的话,结果里才会出现重复行。不过,这道例题使用的是连接查询,如果改用关联子查询,就不需要DISTINCT了。
4 排序
按照价格从高到低的顺序,对下面这张表里的商品进行排序。我们让价格相同的商品位次也一样,而紧接着它们的商品则有两种排序方法,一种是跳过之后的位次,另一种是不跳过之后的位次。
首先想到的肯定是窗口函数
--排序:使用窗口函数
SELECT name, price,
RANK() OVER (ORDER BY price DESC) AS rank_1,
DENSE_RANK() OVER (ORDER BY price DESC) AS rank_2
FROM Products;
执行结果
name price rank_1 rank_2
------- ------ ------- -------
橘子 100 1 1
西瓜 80 2 2
苹果 50 3 3
香蕉 50 3 3
葡萄 50 3 3
柠檬 30 6 4
但是,RANK函数还属于标准SQL中较新的功能,目前只有个别数据库实现了它,还不能用于MySQL数据库。(这我不知道现在可不可以了)
考虑不依赖具体数据库,使用非等值自连接(真的很常用)来实现:
--排序从1开始。如果已出现相同位次,则跳过之后的位次
SELECT P1.name,
P1.price,
(SELECT COUNT(P2.price)
FROM Products P2
WHERE P2.price > P1.price) + 1 AS rank_1
FROM Products P1
ORDER BY rank_1;
执行结果
name price rank
----- ------ ------
橘子 100 1
西瓜 80 2
苹果 50 3
葡萄 50 3
香蕉 50 3
柠檬 30 6
去掉标量子查询后边的+1,就可以从0开始给商品排序,如果修改成COUNT(DISTINCT P2.price),那么存在相同位次的记录时,就可以不跳过之后的位次,而是连续输出(相当于DENSE_RANK函数)。由此可知,这条SQL语句可以根据不同的需求灵活地进行扩展,实现不同的排序方式。(这也不理解)

这条SQL语句会生成这样几个“同心圆状的”递归集合,然后数这些集合的元素个数。正如“同心圆状”这个词的字面意思那样,这几个集合之间存在如下包含关系。
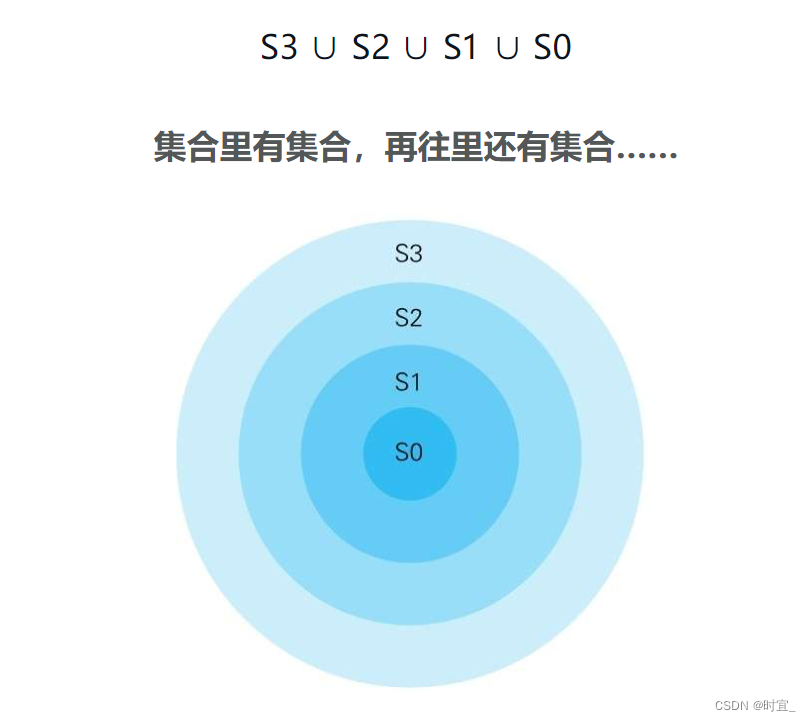
实际上,“通过递归集合来定义数”这个想法并不算新颖。有趣的是,它和集合论里沿用了100多年的自然数(包含0)的递归定义(recursive definition)在思想上不谋而合。研究这种思想的学者形成了几个流派,其中和这道例题的思路类型相同的是计算机之父、数学家冯·诺依曼提出的想法。冯·诺依曼首先将空集定义为0,然后按照下面的规则定义了全体自然数。
0 = φ
1 = {0}
2 = {0, 1}
3 = {0, 1, 2}
·
·
·
定义完0之后,用0来定义1,然后用0和1来定义2,再用0、1和2来定义3……以此类推。这种做法与上面例题里的集合S0~S3在生成方法和结构上都是一样的(正是为了便于比较,例题里的位次才从0开始)。这道题很好地直接结合了SQL和集合论,而联系二者的正是自连接。
(鼓掌)
顺便说一下,这个子查询的代码还可以像下面这样按照自连接的写法来改写。
--排序:使用自连接
SELECT P1.name,
MAX(P1.price) AS price,
COUNT(P2.name) +1 AS rank_1
FROM Products P1 LEFT OUTER JOIN Products P2
ON P1.price < P2.price
GROUP BY P1.name
ORDER BY rank_1;
(啊我没看懂!)
去掉这条SQL语句里的聚合并展开成下面这样,就可以更清楚地看出同心圆状的包含关系(为了看得更清楚,我们从表中去掉价格重复的行,只留下橘子、西瓜、葡萄和柠檬这4行)。
--不聚合,查看集合的包含关系
SELECT P1.name, P2.name
FROM Products P1 LEFT OUTER JOIN Products P2
ON P1.price < P2.price;
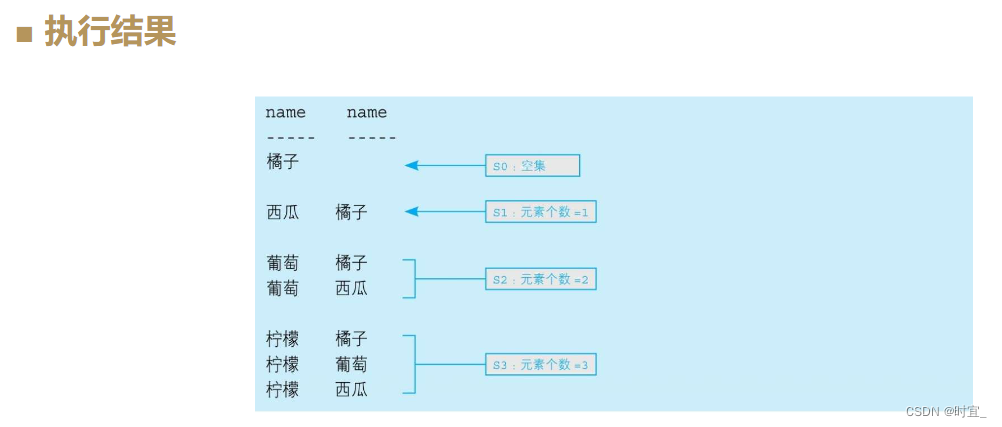
集合每增大1个,元素也增多1个,通过数集合里元素的个数就可以算出位次。
这个查询里还有一个特别的技巧,也许大家已经注意到了。那就是前面的例题里用的连接都是标准的内连接,而这里用的却是外连接。如果将外连接改为内连接看一看,马上就会明白这样做的原因。
--排序:改为内连接
SELECT P1.name,
MAX(P1.price) AS price,
COUNT(P2.name) +1 AS rank_1
FROM Products P1 INNER JOIN Products P2
ON P1.price < P2.price
GROUP BY P1.name
ORDER BY rank_1;
执行结果
--没有第1名!
name price rank_1
------ ------- --------
西瓜 80 2
葡萄 50 3
苹果 50 3
香蕉 50 3
柠檬 30 6
没错,第1名“橘子”竟然从结果里消失了。关于这一点大家思考一下就能理解了。没有比橘子价格更高的水果,所以它被连接条件P1.price < P2.price排除掉了。外连接就是这样一个用于将第1名也存储在结果里的小技巧(这个小技巧在1-6节还会再次发挥重要作用)。
(啊,我还是没有完全理解,感觉会又不太会!原来sql可以这名难)
小结
自连接是不亚于CASE表达式的重要技术,请一定熟练掌握。最后说一个需要注意的地方,与多表之间进行的普通连接相比,自连接的性能开销更大(特别是与非等值连接结合使用的时候),因此用于自连接的列推荐使用主键或者在相关列上建立索引。本节例题里出现的连接大多使用的是主键。
1.自连接经常和非等值连接结合起来使用。
2.自连接和GROUP BY结合使用可以生成递归集合。
3.将自连接看作不同表之间的连接更容易理解。
4.应把表看作行的集合,用面向集合的方法来思考。
5.自连接的性能开销更大,应尽量给用于连接的列建立索引。
———————————————————————————————————————————
更多内容点击主页查看~
版权归原作者 好大一个绿菠萝 所有, 如有侵权,请联系我们删除。