
本实验是将某一层的特征图中的某一通道对其进行的可视化,有两种方式一种是使用opencv;另一种是使用tensorboard。
1.使用opencv
import cv2
import torch
import numpy as np
from PIL import Image
from torchvision import models, transforms
import warnings
import argparse
warnings.filterwarnings('ignore')
def parse_args():
parser = argparse.ArgumentParser(description='Show Feature Map by Pytorch')
parser.add_mutually_exclusive_group()
parser.add_argument('--img_root',
type=str,
default='cat.jpg',
help='image path')
parser.add_argument('--basenet',
type=str,
default='resnet50',
help='train base model')
parser.add_argument('--cuda',
type=str,
default=True,
help='if we can use cuda')
return parser.parse_args()
args = parse_args()
# img processing
def get_img_info(img_root):
img_info = Image.open(img_root).convert('RGB')
img_transforms = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
img_info = img_transforms(img_info)
# C,H,W -> 1,C,H,W
img_info = img_info.unsqueeze(0)
return img_info
# get No. K feature map
# vgg16
def model_get_feature_map_vgg(model, x):
with torch.no_grad():
feature_map = model.features(x)
return feature_map
# resnet50
def model_get_feature_map_resnet(model, x):
with torch.no_grad():
x = model.conv1(x)
x = model.bn1(x)
x = model.relu(x)
x = model.maxpool(x)
feature = x = model.layer1(x)
x = model.layer2(x)
x = model.layer3(x)
x = model.layer4(x)
return feature, x
def show_k_feature_map(feature_map, k):
feature_map = feature_map.squeeze(0)
feature_map = feature_map.cpu().numpy()
for index, feature_map_i in enumerate(feature_map):
feature_map_i = np.array(feature_map_i * 255, dtype=np.uint8)
feature_map_i = cv2.resize(feature_map_i, (224, 224), interpolation=cv2.INTER_NEAREST)
if k == index + 1:
feature_map_i = cv2.applyColorMap(feature_map_i, cv2.COLORMAP_JET)
cv2.imwrite("{}.jpg".format(str(index + 1)), feature_map_i)
if __name__ == '__main__':
img_info = get_img_info(args.img_root)
k = 10
if args.basenet == 'vgg16':
model = models.vgg16(pretrained=True)
elif args.basenet == 'resnet50':
model = models.resnet50(pretrained=True)
else:
raise ValueError("the model type is error!")
if args.cuda == torch.cuda.is_available():
img_info = img_info.cuda()
model = model.cuda().eval()
else:
img_info = img_info.cpu()
model = model.cpu().eval()
if args.basenet == 'vgg16':
feature_map = model_get_feature_map_vgg(model, img_info)
elif args.basenet == 'resnet50':
feature_map, _ = model_get_feature_map_resnet(model, img_info)
show_k_feature_map(feature_map, k)
print("finished!")
运行结果
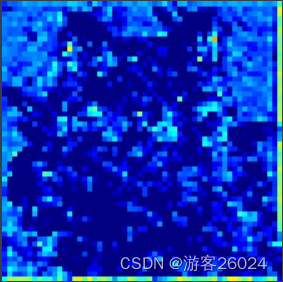
使用的resnet50作为backbone的效果更好,将layer1的特征中第一层通道(256中的第1层)转化为图像

layer1. channels1.
将layer1的特征中第一层通道(256中的第1层)转化为图像,将代码改为:
if __name__ == '__main__':
...
k=2

layer1. channels2.
layer1. channels3.
...
layer1. channels10.
...
若要提取layer2的特征,将代码改为:
def model_get_feature_map_resnet(model, x):
with torch.no_grad():
x = model.conv1(x)
x = model.bn1(x)
x = model.relu(x)
x = model.maxpool(x)
x = model.layer1(x)
feature = x = model.layer2(x)
x = model.layer3(x)
x = model.layer4(x)
return feature, x
2.使用tensorboard
import torch
import numpy as np
from PIL import Image
from torchvision import models, transforms
from torch.utils.tensorboard import SummaryWriter
import warnings
import argparse
warnings.filterwarnings('ignore')
def parse_args():
parser = argparse.ArgumentParser(description='Show Feature Map by Pytorch')
parser.add_mutually_exclusive_group()
parser.add_argument('--img_root',
type=str,
default='cat.jpg',
help='image path')
parser.add_argument('--basenet',
type=str,
default='resnet50',
help='train base model')
parser.add_argument('--cuda',
type=str,
default=True,
help='if we can use cuda')
return parser.parse_args()
args = parse_args()
# img processing
def get_img_info(img_root):
img_info = Image.open(img_root).convert('RGB')
img_transforms = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225])
])
img_info = img_transforms(img_info)
# C,H,W -> 1,C,H,W
img_info = img_info.unsqueeze(0)
return img_info
# get No. K feature map
# vgg16
def model_get_feature_map_vgg(model, x):
with torch.no_grad():
feature_map = model.features(x)
return feature_map
# resnet50
def model_get_feature_map_resnet(model, x):
with torch.no_grad():
x = model.conv1(x)
x = model.bn1(x)
x = model.relu(x)
x = model.maxpool(x)
feature = x = model.layer1(x)
x = model.layer2(x)
x = model.layer3(x)
x = model.layer4(x)
return feature, x
def show_k_feature_map(feature_map, k):
writer = SummaryWriter("tensorboard")
feature_map = feature_map.squeeze(0)
feature_map = feature_map.cpu().numpy()
for index, feature_map_i in enumerate(feature_map):
feature_map_i = np.array(feature_map_i * 255, dtype=np.uint8)
feature_map_i = np.expand_dims(feature_map_i, axis=0)
if k == index + 1:
writer.add_image("feature_map", feature_map_i, k)
writer.close()
if __name__ == '__main__':
img_info = get_img_info(args.img_root)
k = 10
if args.basenet == 'vgg16':
model = models.vgg16(pretrained=True)
elif args.basenet == 'resnet50':
model = models.resnet50(pretrained=True)
else:
raise ValueError("the model type is error!")
if args.cuda == torch.cuda.is_available():
img_info = img_info.cuda()
model = model.cuda().eval()
else:
img_info = img_info.cpu()
model = model.cpu().eval()
if args.basenet == 'vgg16':
feature_map = model_get_feature_map_vgg(model, img_info)
elif args.basenet == 'resnet50':
feature_map, _ = model_get_feature_map_resnet(model, img_info)
show_k_feature_map(feature_map, k)
print("finished!")
运行结果
tensorboard --logdir=tensorboard
将layer1的特征中第10层通道(256中的第1层)转化为图像
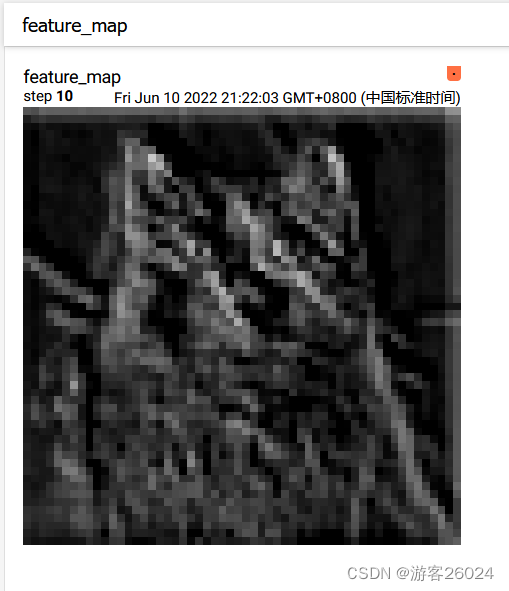
layer1. channels10.
successed!
本文转载自: https://blog.csdn.net/XiaoyYidiaodiao/article/details/125228332
版权归原作者 游客26024 所有, 如有侵权,请联系我们删除。
版权归原作者 游客26024 所有, 如有侵权,请联系我们删除。