
先看效果
首先,找到一篇论文先,我这里随便找了一篇pdf格式的论文

那么,我现在让他担任一个研究论文的智能助手,当然大家可以自定义自己的prompt

开始问答
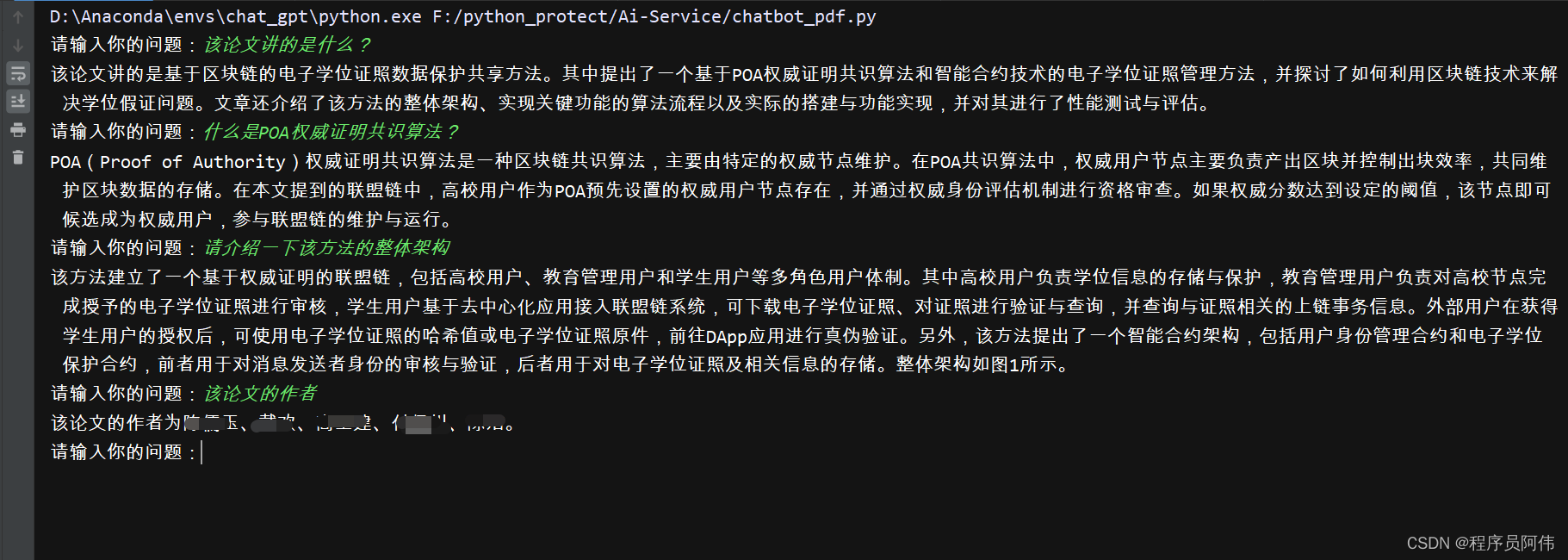
可以看到效果很强
实现原理
- 提取 pdf 文本,以便后续处理。
- 由于 OpenAI API 对 Token 数量有限制,我们需要将 PDF 文本切分成小于 Token 限制的片段。
- 将每个片段使用 OpenAI 的 Embedding API 生成向量并保存到数据库(Postgres)中
- 开始提问题
- 将用户提出的问题转换为向量。
- 使用余弦相似度算法将用户提出的问题向量与数据库中的向量进行比较,找到与问题最相似的文本片段。
- 将片段文本喂给 ChatGPT,让它基于这些片段回答用户提出的问题。
代码资源,我放在网盘了,大家需要的自提
链接:https://pan.baidu.com/s/1Os_DR8lC9gBtc2ONNN5YJg?pwd=6666
提取码:6666
--来自百度网盘超级会员V1的分享
环境安装
python环境3.7+的,我这里是3.8
pip install -r requirements.txt
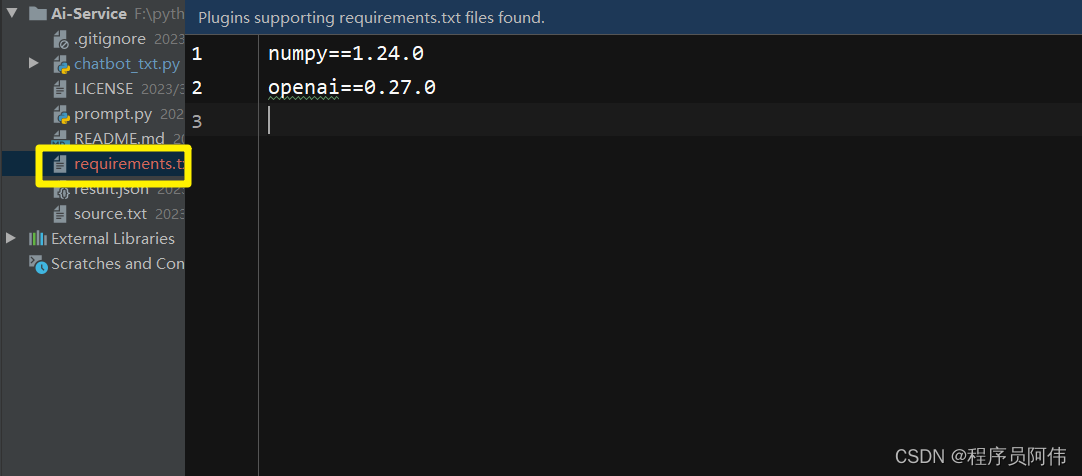
如果说,运行发生ssl错误的话
可以对urllib3进行降级
pip install urllib3==1.25.11
执行代码是这个
然后的话,大家就需要特殊上网了,因为本质上还是使用到openai的

使用前的话,我们需要将自己的语料喂给openai,只需要喂一次就行,如果更换语料的话就需要重新喂了
喂养,第二次使用就可以注释掉
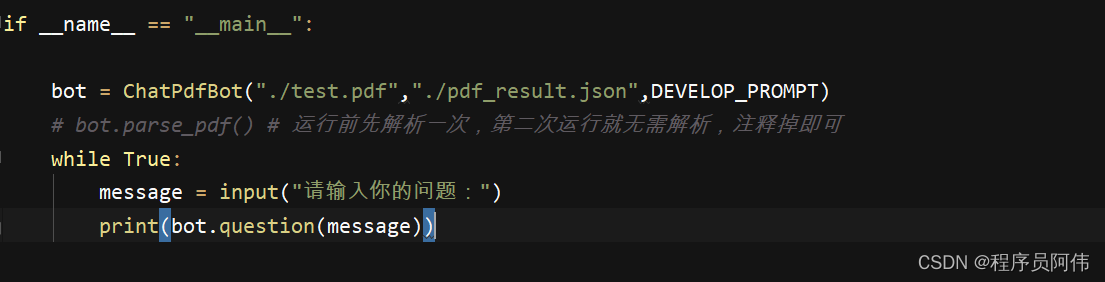
另外运行前需要将自己的key更改成自己的

应用场景
可以通过这种上传文件的方式,解决openai的token的字数限制问题,让我们的文档变成一个帮助你学习的助手,当然其他的一些可以用来创业的想法,大家可以自行的去研究。
本文转载自: https://blog.csdn.net/m0_55868614/article/details/129639067
版权归原作者 程序员阿伟 所有, 如有侵权,请联系我们删除。
版权归原作者 程序员阿伟 所有, 如有侵权,请联系我们删除。