
LLM 在多步骤问题求解上的表现已经相当不错了,但复杂逻辑链的处理仍然是个难题。模型的推理深度直接决定了它在多跳推理任务中能走多远、有多可靠。
本文介绍推理深度的核心机制,然后用四项压力测试指标对 Llama 3.2 和 Qwen 3 做个横向对比看看它们的逻辑极限在哪里。
什么是多跳推理
多跳问题要求模型沿着逻辑链一步步往下走,每一"跳"就是一次推理,把初始问题和最终答案之间的逻辑缺口补上。
下图展示了数学任务中推理深度如何随逻辑运算数量递增:
推理深度就是输入到结论之间的逻辑距离。图 A 左边的问题是
d = 2
,右边是
d = 4
。
不管什么类型的任务多跳问题都有几个共同点:答案藏在层层子问题下面;模型得在不出幻觉、不犯错的情况下跑完整条链;深度越高越难,链条中间哪怕错一步,后面就全废了。
任务复杂度与推理深度的对应关系
选什么模型架构,得先看清任务需要多少步推理。
这里把主要的 LLM 任务分成三档:浅层(
d < 3
)、中等(
d = 3–5
)、深层(
d = 6+
),每一档的工程需求差别很大。
推理深度的分类

图 B:各任务领域的推理深度
表里每个格子包含任务类型、工程需求和市面上对应的模型。从左到右模型的工作模式从简单的模式匹配变成多步骤的执行功能。
浅层推理:一次性模式匹配
浅层任务只有 1 到 2 步推理。模型做的事情很简单:输入特征,直接映射到输出标签,不需要规划,不需要推敲,就是单次推理加局部特征提取。
举几个
d = 1
的例子:表格数据上根据阈值判断交易是否欺诈;NLP 里判断评论是正面还是负面;图像分类里区分猫和狗。
这类任务用 BERT、DistilBERT 或 Gemini Flash 就够了。表格数据的话,LightGBM 这种传统树模型可能比 LLM 更合适,延迟低、精度高。
中等推理:上下文整合
中等任务的推理深度到 5,模型需要把分散的信息点拼成一个连贯结构。上下文窗口里得维护中间状态,保证最后的输出和开头逻辑上能对得上。核心是上下文综合加多点注意力。
d = 5
的例子:多时间跨度的需求预测,要考虑季节性、节假日、趋势变化;总结 50 页法律记录还得保持发言者的意图;从复杂 PDF 发票里提数据然后算税差。
GPT-45、Claude 4.5 Sonnet 这类擅长上下文理解的模型比较适合。
深层推理:系统 2 思维
深层任务推理深度 6+的最大的特点是顺序依赖——当前步骤对不对,完全取决于前面每一步有没有出问题。这意味着模型得有分支逻辑、错误检测和回溯能力,核心是测试时计算加 CoT 强化。
而
d = 10
长什么样?人形机器人在不平地面上保持平衡的同时计算抬起未知物体需要多大扭矩;调试横跨三个文件、两种语言的微服务架构 bug;从稀疏 2D 视频帧重建 NeRF。
这种任务得用系统 2 思维的模型,比如 OpenAI o1/o3 和 DeepSeek-R1——它们会在给出答案之前先把逻辑想清楚,如果没有自我纠正循环的中端模型往往走到一半就开始产生幻觉。
深层推理的工程要求
部署深层推理模型,基础设施得从简单推理转向复杂状态管理。
测试时计算这块,深层推理器和浅层模型完全不一样:它的性能随思考时间增长。DeepSeek-R1 这类模型会生成几千个内部 CoT Token,边走边验证假设、丢弃错误路径。
KV 缓存管理也是个大问题。深层任务需要很大的缓存容量来处理长上下文和推理链,得用缓存压缩或 PagedAttention 来防止灾难性遗忘。
还有反馈循环,深层推理模型会自己批评自己——比如写代码时会模拟执行、发现潜在异常,然后在内部重写逻辑块。
这里的关键是让推理预算匹配推理深度。把一个
d=10级别的推理模型用在
d=1的情感分析任务上,纯粹是浪费算力。
怎么测量 LLM 的推理极限
测量推理深度没有万全的方法需要看具体目标。一般 4 项指标:Multi-LogiEval(准确率随推理深度增加衰减多少)、过程基准测试(模型在哪一步开始产生幻觉)、泛化性系数(模型用的是第一性原理还是模式匹配)、思考-输出比(模型给答案之前想了多久)。
1、Multi-LogiEval
Multi-LogiEval 是最常见的压力测试框架是专门用来找 LLM 推理深度的天花板的,它测的是步骤感知的准确率衰减也就是推理深度往上加的时候,模型的逻辑连贯性在哪个点开始崩。
核心指标
这个方法把准确率画成推理深度的函数,找出推理墙,也就是模型准确率(Acc@d)跌破临界阈值(比如 50%)的那个深度。
Acc@d 就是正确答案数除以总问题数:
衰减率计算的是深度增加时准确率掉了多少: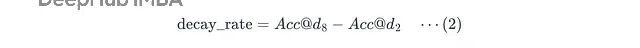
Acc@d8
和
Acc@d2
分别是模型在
d = 8
和
d = 2
时的准确率。
比如从 d = 2 开始算衰减率:d = 3 掉 20 点,d = 4 掉 30 点,d = 5 掉 32 点,d = 6 掉 40 点,d = 7 掉 55 点低于阈值这就是撞墙了,d = 8 掉 68 点。
实现方法:递增复杂度阶梯
实现这个方法要先创建同构逻辑任务:多个任务共享相同的核心概念,但随着链条延长逐步加入逻辑干扰。
拿数学问题举例,设计三个任务:基线(
d = 2
,浅层推理,建立基准准确率)、任务 A(
d = 5
,中等推理)、任务 B(
d = 8
,深层推理)。
给每个任务写提示词,配合 CoT 来定位失败节点:
逐步思考,并为你的每个计算步骤编号。
基线问题:
一列火车起始有 50 名乘客。10 人下车,5 人上车。现在火车上有多少人?
逻辑步骤(
d = 2
):起始 50,减 10 得 40,加 5 得 45。正确答案:45。
任务 A:
一列火车起始有 50 名乘客。第一站 10 人下车、5 人上车。第二站剩余乘客的 20% 下车。现在火车上有多少人?
逻辑步骤(
d = 5
):50 减 10 得 40,加 5 得 45,45 乘 0.2 得 9,45 减 9 得 36。正确答案:36。
这里加了百分比运算,模型得在执行非简单加减法时维护运行状态。
任务 B:
一列火车起始有 50 名乘客。第一站 10 人下车、5 人上车。第二站剩余乘客的 20% 下车。第三站乘客人数翻倍。最后一站 20 人下车、10 人上车。但车站工作人员决定火车上只能保留 30 人。现在必须有多少人下车?
逻辑步骤:50 减 10 得 40,加 5 得 45,45 乘 0.2 得 9,45 减 9 得 36,36 乘 2 得 72,72 减 20 得 52,52 加 10 得 62,62 减 30 得 32。正确答案:32。
步骤 5 有翻倍,步骤 8 有容量约束。顺序依赖性极高,步骤 3 错了后面全完蛋。
定量分析
每个任务跑 N=100 次迭代,生成统计显著的衰减曲线。
import re
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, pipeline, AutoConfig
model_id = 'Qwen/Qwen3-8B'
# config tokenizer
tokenizer = AutoTokenizer.from_pretrained(model_id)
# config model
config = AutoConfig.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
config=config,
trust_remote_code=True,
dtype=torch.float16,
device_map="cpu"
)
# config llm pipeline
generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
# prompt
messages = [{"role": "user", "content": prompt}]
formatted_prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
# iteration
n_iterations = 20
for i in range(n_iterations):
# call generator
output_list = generator(
formatted_prompt,
max_new_tokens=512,
do_sample=True,
temperature=0.7
)
# extract answer
output = output_list[0]['generated_text']
answer_part = output.replace(formatted_prompt, "")
matches = re.findall(r"The correct answer: (\d+)", answer_part)
# count success
if matches and int(matches[-1]) == answers[d]: success_count += 1
# calc acc_d score
acc = success_count / n_iterations
生产环境做基准测试时一般设
temperature=0保证可重复性。但压力测试随机失败的话,会故意在 0.7 到 1.2 之间进行调整。
结果如下: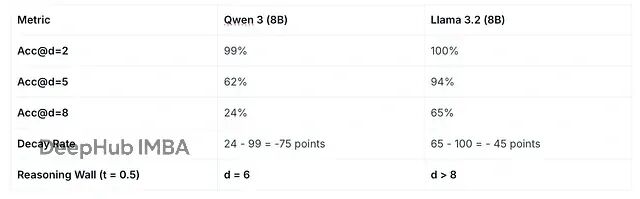
表 1. Multi-LogiEval 压力测试结果
Llama 3.2 的推理深度明显强于 Qwen 3。两个模型在 2 步逻辑上都接近满分但到 8 步的时候,Qwen 3 垮了,Llama 3.2 还能保持 65%。Qwen 3 的衰减率很惨,Llama 3.2 则相对稳定,逻辑持久力明显更强。
推理墙在中端模型里很常见。它们往往在
d = 5左右出现断崖式下跌(比如从 80% 掉到 40%),而 OpenAI o3 或 DeepSeek-R1 这类推理模型能把平稳线拉得更长。
扩展评估
为了排除提示运气,可以生成 20 个逻辑阶梯变体:把"火车乘客"换成"仓库库存"或"网络缓冲区数据包"。
然后观察失败模式是一致的还是随机的。如果模型在所有 20 个变体的
d = 4
处都失败,说明演绎状态管理有结构性缺陷。如果失败点随机分布,那问题可能是上下文窗口噪声或注意力漂移,就是模型在同一提示的不同迭代中没法稳定地检索相关信息。
随机失败能暴露逻辑极限的底层机制。
"中间丢失"注意力:模型抓不住长上下文窗口中间位置的信息。解决办法是提示工程——把关键数据挪到开头或结尾,重复关键指令,或者让模型执行任务前先总结一遍上下文。
Token 竞争:不相关的 Token 抢走了注意力权重,特别是在高噪声环境下。解决办法是用严格格式(比如
### DATA ###)或约束语(
DO NOT …),再配合少样本采样。
Softmax 方差:浮点数的微小波动可能让模型漏掉之前抓到的逻辑连接。解决办法是贪婪解码或者直接把温度降到 0。
Multi-LogiEval 的优势
这个方法能精确定位推理墙在哪里;涵盖 30 多条推理规则,评估比较全面;而且是零样本测试,测的是模型的内在推理能力而不是从少样本提示里抄答案的能力。
局限性
性能在墙那里直接断崖,但基准测试不告诉你模型过了极限之后怎么修。逻辑链是人工生成的,为了控制深度可能显得不太自然。还有个问题是算术混淆——模型撞墙可能不是因为丢了逻辑,而是算错了一步。步骤 4 错了是因为数学算错,虽然错误一路传到最后,但模型其实一直在老老实实地执行逻辑。
用在哪里
模型选型的时候Multi-LogiEval 能看出哪个模型在长链思维上更有耐力。
做架构分析时可以看增加参数量到底有没有增加推理深度:70B 模型是真的比 8B 更聪明,还是只是记住了更多事实。
部署自主智能体之前Multi-LogiEval 能预估智能体在 10 步工作流程的第 7 步挂掉的概率。
2、过程基准测试
过程基准测试用更大的语言模型做 LLM-as-a-Judge给 CoT 里的每一步打分。
核心指标
它算的是逐步有效性分数: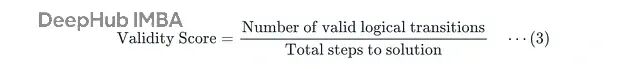
下表是
d = 8
的任务 B 的结果: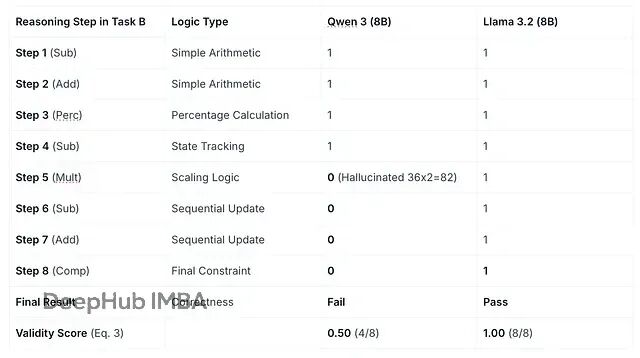
表 2. Qwen 3 和 Llama 3.2 在任务 B 上的逐步有效性热力图
Judge 给每一步打分:有效是 1,无效是 0。
Qwen 3 在步骤 5 出了幻觉,所以它的推理深度被 Judge 卡在 4。步骤 5 之后就算偶然蒙对了,Judge 也不认,因为这些答案建立在幻觉前提上。最终 Qwen 3 拿了 4/8没过,而Llama 3.2 全程正确,满分通过。
优势
能精确定位失败节点;提供模型实际推理深度的清晰画面;过滤掉侥幸猜对的情况,区分真懂逻辑和纯靠蒙;给 RLHF 提供更好的奖励信号,因为奖励的是具体的逻辑行为。
局限性
计算成本高——评估一条 10 步推理链的每一步,可能比标准基准测试贵 10 倍还慢。结果质量取决于 Judge 模型的能力,如果 Judge 不够强可能漏掉微妙的逻辑谬误。链条太长的话Judge 自己也可能跟丢早期约束,导致评估本身出问题。
用在哪里
医疗或工程这种安全关键领域,计算的每一步都要验证,过程基准测试能确保中间没有隐藏错误。
AI 辅导场景下,系统得能准确告诉学生哪一步错了,比如"步骤 1 到 3 是对的,但步骤 4 乘百分比时算错了"。
法律分析、财务预测这类逻辑密集型工作流程,一个逻辑步骤出错(比如误读税法条款)就能让整份报告作废。
还能检测数据污染——如果最终答案对了但中间步骤是错的,说明模型可能只是记住了训练数据里的答案。
3、泛化系数
泛化性系数测的是推理有多脆弱:如果模型太依赖模式匹配,换个说法它就可能会崩掉。
拿任务 B 举例,把"火车乘客"改成"仓库库存",其他逻辑完全一样,这就是扰动测试: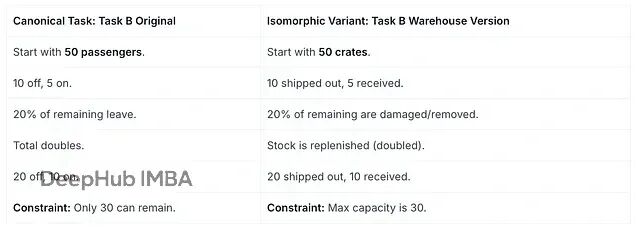
表 3. 任务 B 同构变体的扰动测试
核心指标
泛化性系数
ρ
的计算公式: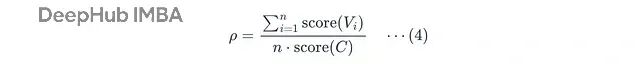
C
是原始任务,
V_i
是第 i 个同构变体,
n
是变体总数,
score
是二元指标(成功 1,失败 0)。
这个公式的目标是区分真正的推理和模式匹配,跑
n = 10
个同构变体的扰动测试就能看出来。
ρ = 1.0
说明模型完全不受措辞影响,逻辑扎实。
0.5 < ρ < 1.0
说明模型有点脆,能理解逻辑但容易被注意力漂移带偏。
ρ = 0.0
说明模型大概率只是记住了规范答案,根本不会推理。
扰动测试结果:
表 4. 扰动测试结果
Qwen 3 系数低说明它大概率在做模式匹配:能认出火车类型的应用题,但换成仓库场景就不行了。真实推理深度比基准测试里表现出来的要浅。
Llama 3.2 系数高,说明它用的是第一性原理逻辑,把乘客和货物都当成抽象变量处理。它是真的在执行逻辑步骤,而不是在熟悉的题型格式里预测下一个最可能的 Token。
优势
这是检测数据污染最有效的方法。对多个同构版本取平均分,能揭示模型在不可预测场景下的真实推理深度。而且跨语言、跨领域通用——医疗诊断、Python 编码都能测。
局限性
完美的扰动很难造。有些变体可能触发安全护栏,或者难度意外变高。测试量也大——要拿到统计显著的系数,得准备 5000 道题(每题 5 个变体)而不是 1000 道。还有个问题是模型可能因为非逻辑原因失败,比如它觉得仓库版本措辞更正式,反而发挥更好。
用在哪里
企业部署 AI 工作流程时,比如发票摘要,来自航运公司和本地供应商的发票长得不一样,但 AI 得都能处理。泛化性系数能确认模型不会被不同术语绕晕。
材料科学、化学这类单位经常变的领域,密度算
g/cm^3
或
kg/m^3
都得能算对。
模型在原版准确率 95%、扰动版只有 40%?这就是过拟合的明证。
自动代码生成的话,变量名叫
list_a
还是
user_inventory_data
都得能处理。
4、思考-输出比
思考-输出比通过模型给答案之前生成了多少隐藏 Token 来衡量推理深度。
核心指标
公式很简单,内部推理 Token 数除以最终答案 Token 数: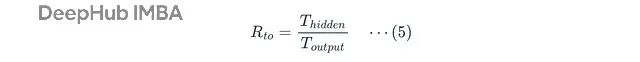
T_{hidden}
是在
<think>
标签里生成的 Token 数,
T_{output}
是用户看到的答案 Token 数。
R_to > 10
是深层推理任务,
R_to = 1.0
是标准解释,
R_to < 0.1
是直接回答、几乎没思考。
Qwen 3 和 Llama 3.2 在任务 B 上的表现:
表 5. 思考-输出比比较
Qwen 3 每输出 1 个词,内部生成了 7 个 Token。正是这些隐藏工作让一个 8B 小模型在崩溃之前能达到任务 B 的推理深度。
Llama 3.2 则是零隐藏 Token,直接出答案。
优势
这是模型"认知努力"的直接指标,推理模型用隐藏 Token 回溯,监控这些能看出模型有没有在给答案之前发现并修正自己的错误。做推理效率调优时能确保模型想得够久所以答对,但又不至于太久导致成本爆炸或延迟太高。还能检测假推理——真正的推理模型思考长度会随问题难度动态变化,而不是永远套一个 CoT 模板。
局限性
很多商业模型不暴露隐藏 Token所以这个指标一开始就没法算,另外还有沉思循环的问题——模型卡在逻辑循环里会消耗大量内部 Token,响应质量没变好。推理深度高了之后有些模型会开始为内部效率优化而不是人们可读性优化,内部 Token 里会出现混合语言甚至乱码。
用在哪里
评估系统 2 思维能力——那些号称能做博士级科学题、高级编码、法律分析的模型。
做成本效益分析时,如果 7B 模型思考-输出比很高但准确率和 70B 模型一样,那 7B 模型可能更聪明但更慢、单次查询更贵。
调试逻辑崩溃时,能看出模型什么时候撞墙然后放弃了。
总结
四项指标对 Qwen 3 和 Llama 3.2 在任务 B 上的深层推理能力做了全面评估。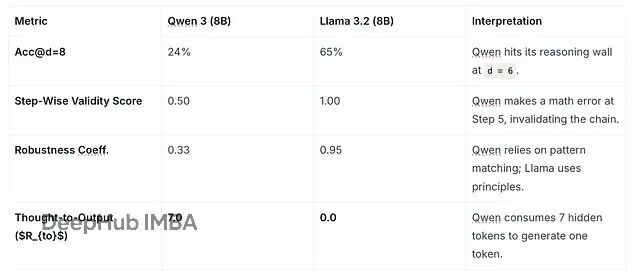
表 6. 压力测试结果
Llama 3.2 是直觉型推理器,推理能力直接烧进了预训练权重里(
T_{hidden} = 0
),所以能用第一性原理解决问题。
Qwen 3 是系统 2 推敲型,得跟自己"对话"才能解复杂题(
R_to = 7
)。但它撑不住太深的推理(推理墙 = 6,
acc@d=8 = 24%
)——虽然步骤 5 崩掉是因为算术错误,不是逻辑问题。
选型建议:Llama 3.2(8B)适合对速度和稳定性要求高的生产环境,它的推理不受措辞影响。Qwen 3(8B)适合研究场景或复杂的多步骤提示任务,前提是能接受隐藏 Token 带来的延迟。做数学题的话记得给它配个外部计算器工具,防止低级算术错误。
By Kuriko IWAI