
概述
最近替换视频中的人脸比较火,涉及的技术主要是图像生成,主要采用生成式对抗网络(GAN, Generative Adversarial Networks )深度学习模型。GAN是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。
本文基于Deepfakes Faceswap实现了一个简单的图片换脸过程。
GAN
生成式对抗网络(GAN, Generative Adversarial Networks )是一种深度学习模型,是近年来复杂分布上无监督学习最具前景的方法之一。模型通过框架中(至少)两个模块:生成模型(Generative Model)和判别模型(Discriminative Model)的互相博弈学习产生相当好的输出。原始 GAN 理论中,并不要求 G 和 D 都是神经网络,只需要是能拟合相应生成和判别的函数即可。但实用中一般均使用深度神经网络作为 G 和 D 。一个优秀的GAN应用需要有良好的训练方法,否则可能由于神经网络模型的自由性而导致输出不理想。
机器学习的模型可大体分为两类,生成模型(Generative Model)和判别模型(Discriminative Model)。判别模型需要输入变量 ,通过某种模型来预测 。生成模型是给定某种隐含信息,来随机产生观测数据。举个简单的例子,
- 判别模型:给定一张图,判断这张图里的动物是猫还是狗
- 生成模型:给一系列猫的图片,生成一张新的猫咪(不在数据集里)
对于判别模型,损失函数是容易定义的,因为输出的目标相对简单。但对于生成模型,损失函数的定义就不是那么容易。我们对于生成结果的期望,往往是一个暧昧不清,难以数学公理化定义的范式。所以不妨把生成模型的回馈部分,交给判别模型处理。这就是Goodfellow他将机器学习中的两大类模型,Generative和Discrimitive给紧密地联合在了一起 。
GAN的基本原理其实非常简单,这里以生成图片为例进行说明。假设我们有两个网络,G(Generator)和D(Discriminator)。正如它的名字所暗示的那样,它们的功能分别是:
- G是一个生成图片的网络,它接收一个随机的噪声z,通过这个噪声生成图片,记做G(z)。
- D是一个判别网络,判别一张图片是不是“真实的”。它的输入参数是x,x代表一张图片,输出D(x)代表x为真实图片的概率,如果为1,就代表100%是真实的图片,而输出为0,就代表不可能是真实的图片。
在训练过程中,生成网络G的目标就是尽量生成真实的图片去欺骗判别网络D。而D的目标就是尽量把G生成的图片和真实的图片分别开来。这样,G和D构成了一个动态的“博弈过程”。
最后博弈的结果是什么?在最理想的状态下,G可以生成足以“以假乱真”的图片G(z)。对于D来说,它难以判定G生成的图片究竟是不是真实的,因此D(G(z)) = 0.5。
这样我们的目的就达成了:我们得到了一个生成式的模型G,它可以用来生成图片。
Goodfellow从理论上证明了该算法的收敛性 ,以及在模型收敛时,生成数据具有和真实数据相同的分布(保证了模型效果)。
目前GAN最常使用的地方就是图像生成,如超分辨率任务,语义分割等等。
常见的图像生成器
一、NVIDIA StyleGAN
https://github.com/NVlabs/stylegan

这是英伟达2018年底发布的最新研究成果。十天前,英伟达正式给这个模型命名为StyleGAN。顾名思义,GAN的生成器,是借用风格迁移的思路重新发明的。
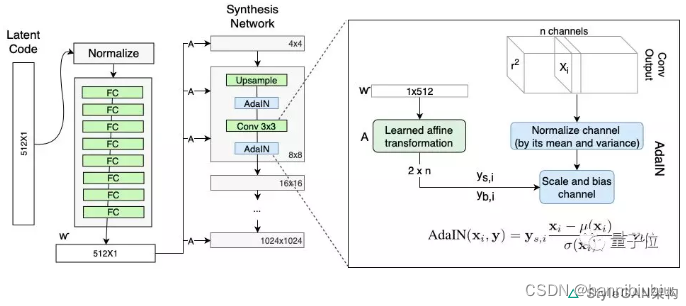
这个开源实现可以用Linux跑,也可以用Windows跑,但墙裂推荐大家用Linux跑,为性能和兼容性着想。此外还需要Python 3.6和TensorFlow 1.10以上 (支持GPU CUDA9.0+,cuDNN 7.3.1+) 。
和官方代码实现一起发布的,还有Flickr高清人脸数据集。那些几可乱真的人脸,就是StyleGAN吃了这个数据集,才生成的。当然,StyleGAN不止能生成人脸,英伟达还提供了猫、汽车、卧室的预训练模型。
二、Deepfakes Faceswap
https://github.com/deepfakes/faceswap
原理与GAN及下方的NVIDIA StyleGAN、CycleGAN基本一致不再赘述。
实现方法:
yum install cmake bzip2
pip install tqdm psutil pathlib numpy opencv-python scikit-image scikit-learn matplotlib ffmpy nvidia-ml-py3 h5py Keras cmake dlib face-recognition flask
#0.download准备照片
# python ~/project/piglab/machinelearning/lib/download_image.py
# 1.extract提取
# python faceswap.py extract -i ./data/photo/huangrong/ -o ./data/extract/huangrong/
# python faceswap.py extract -i ./data/photo/guojing/ -o ./data/extract/guojing/
# python faceswap.py extract -i ./data/photo/zhu/ -o ./data/extract/zhu/
# python faceswap.py extract -i ./data/photo/yan/ -o ./data/extract/yan/
# 2.train训练 (AB参数:模型用于输入A,输出B)
# python faceswap.py train -A ./data/extract/huangrong/ -B ./data/extract/zhu/ -m ./models/huangrong2zhu/
# python faceswap.py train -A ./data/extract/guojing/ -B ./data/extract/yan/ -m ./models/guojing2yan/
# 3.convert替换
# python faceswap.py convert -i ./data/test/ -o ./data/output/ -m ./models/huangrong2zhu/
# 9.视频<->图片互转
# ffmpeg -i ./data/video/shediao.mp4 ./data/photo/shediao/video-%d.png
# ffmpeg -i ./data/photo/shediao/video-%0d.png -c:v libx264 -vf "fps=25,format=yuv420p" ./data/video/shediao-out.mp4
三、CycleGAN
https://github.com/PaddlePaddle/models/tree/develop/fluid/PaddleCV/gan/cycle_gan
CycleGAN是发表于ICCV17的一篇GAN工作,可以让两个domain的图片互相转化。传统的GAN是单向生成,而CycleGAN是互相生成,网络是个环形,所以命名为Cycle。并且CycleGAN一个非常实用的地方就是输入的两张图片可以是任意的两张图片,也就是unpaired。

上图是一个单向GAN的示意图。我们希望能够把domain A的图片(命名为a)转化为domain B的图片(命名为图片b)。为了实现这个过程,我们需要两个生成器GABGAB和GBAGBA,分别把domain A和domain B的图片进行互相转换。图片A经过生成器GABGAB表示为Fake Image in domain B,用GAB(a)GAB(a)表示。而GAB(a)GAB(a)经过生辰器GBAGBA表示为图片A的重建图片,用GBA(GAB(a))GBA(GAB(a))表示。最后为了训练这个单向GAN需要两个loss,分别是生成器的重建loss和判别器的判别loss。以上就是A→B单向GAN的原理。
环形GAN:
CycleGAN其实就是一个A→B单向GAN加上一个B→A单向GAN。两个GAN共享两个生成器,然后各自带一个判别器,所以加起来总共有两个判别器和两个生成器。一个单向GAN有两个loss,而CycleGAN加起来总共有四个loss。CycleGAN论文的原版原理图和公式如下,其实理解了单向GAN那么CycleGAN已经很好理解。

效果:

版权归原作者 Yang_Fr0t 所有, 如有侵权,请联系我们删除。