

🏆作者简介,黑夜开发者,CSDN领军人物,全栈领域优质创作者✌,CSDN博客专家,阿里云社区专家博主,2023年6月CSDN上海赛道top4。
🏆数年电商行业从业经验,历任核心研发工程师,项目技术负责人。
🏆本文已收录于PHP专栏:数据库与数据仓库
🎉欢迎 👍点赞✍评论⭐收藏
文章目录
🚀一、关于数据仓库
数据仓库是用于存储、管理和分析组织内部和外部数据的集中化系统。它的主要作用是将多个数据源中的结构化和非结构化数据整合到一个统一的位置,以便进行跨部门的数据分析和决策支持。数据仓库还具有以下几个重要的作用:

🔎1.1 数据整合与一致性
数据仓库将来自不同数据源的数据进行整合,并保持数据的一致性和准确性,确保用户可以从一个统一的位置访问和分析数据。
🔎1.2 支持复杂查询和分析
数据仓库提供强大的查询和分析功能,使用户能够进行复杂的数据挖掘、统计分析和报表查询,以发现数据中的模式、关联和趋势。
🔎1.3 提高决策支持能力
数据仓库为组织的决策层提供实时和历史数据的分析报告,支持企业管理者做出准确的决策和制定战略。
一些成熟的大数据仓库产品包括
AWS Redshift
、
Google BigQuery
、
Microsoft Azure Synapse Analytics
、
IBM Db2 Warehouse
等,他们的主要特点如下:
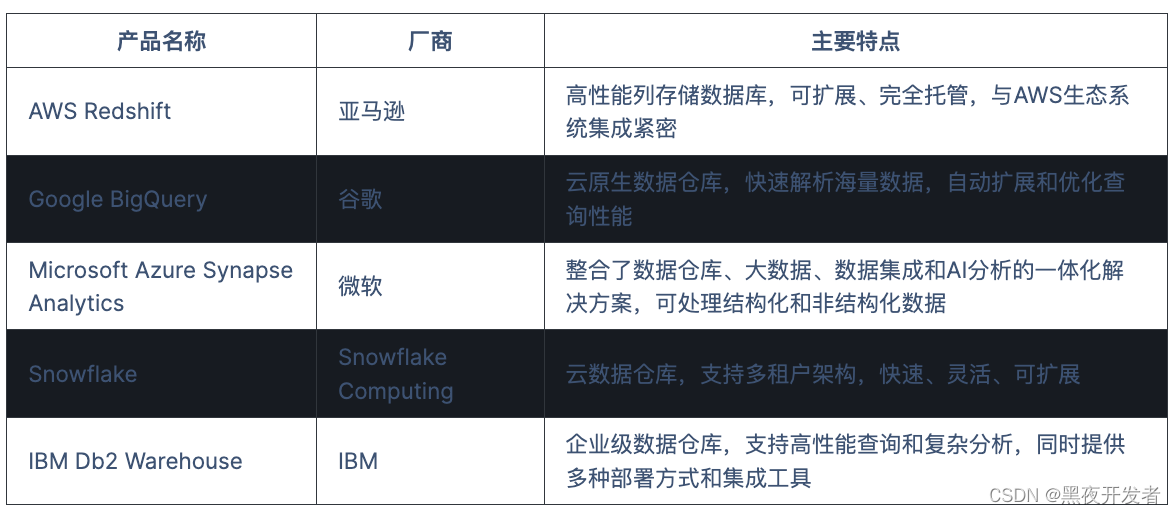
这些大数据仓库产品在架构、性能、可扩展性、集成能力、安全性等方面有所差异。具体选择哪种产品取决于组织的需求、预算、数据规模和技术栈等因素。在下表中,我们展示了这些产品的一些主要特点和区别。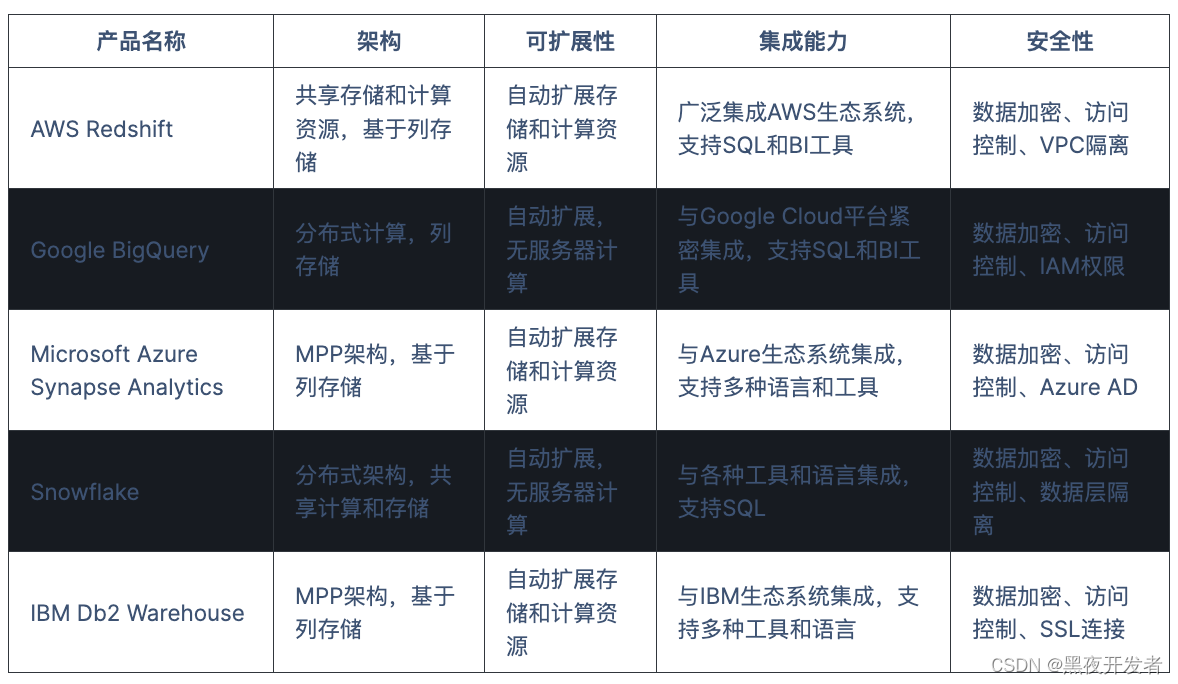
**
我们实际真的的企业业务可能非常复杂,这就需要一款非常贴合场景的数据仓库产品来更好的做数据驱动。
**
当然国内也有用到的比较多的例如
Hive
和
ClickHouse
等数据产品,都能够解决一些特定领域的问题,今天本文重点论述一下
aws
上这一款云数据仓库
Redshift
,是众多使用
aws
作为云服务并且用到数据仓库的首选产品。
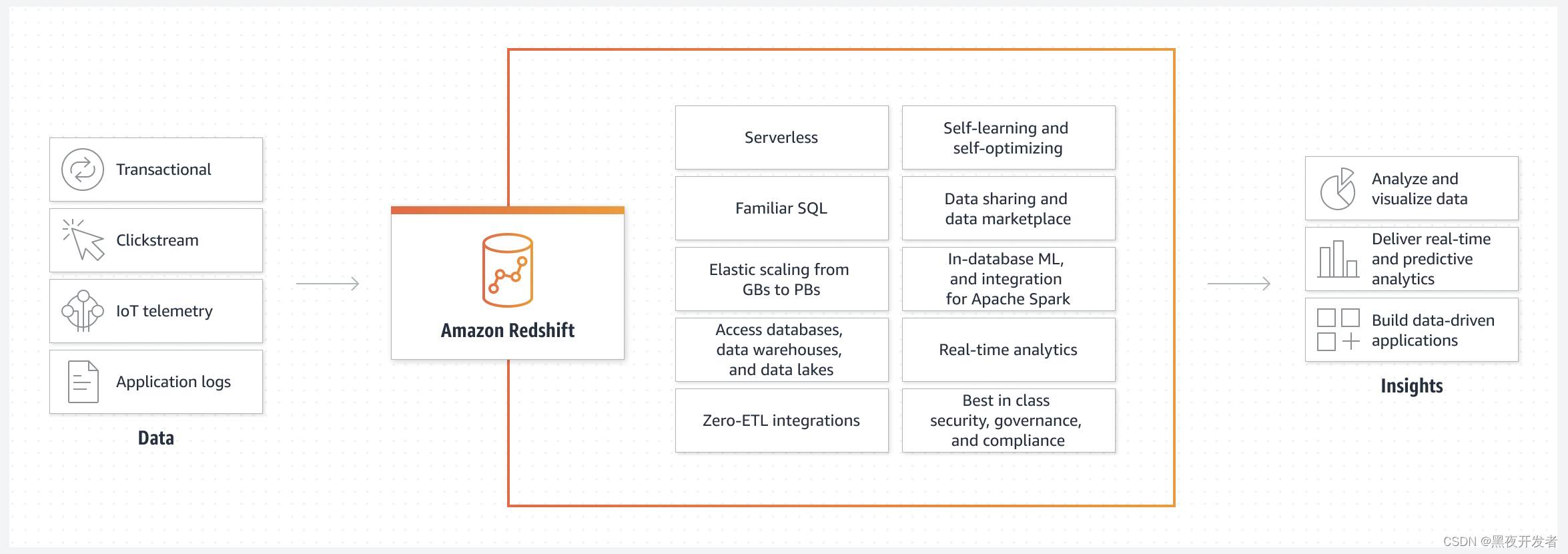
🚀二、AWS Redshift的特点
AWS Rdshift
是亚马逊网络服务
(Amazon Web Services)
提供的一种
完全托管
的云数据仓库解决方案。它是基于列存储的关系型数据库,专门用于
处理大规模数据集
。
Redshift
旨在通过实现高度可扩展的并行查询引擎,支持高性能的数据分析和报表查询。
以下是
Redshift
的主要特点和优势:
🔎2.1 高性能
Redshift
利用列存储方式、压缩、并行化查询等技术,提供了出色的查询性能。它可以在大规模数据集上执行复杂的分析查询,支持高并发访问。
🔎2.2 弹性扩展
Redshift
可以根据需求自动扩展存储和计算资源,以应对不同规模的数据工作负载。这种弹性扩展的能力使其适用于处理大量数据的情况。
🔎2.3 完全托管
Redshift
是一种完全托管的云服务,AWS负责处理硬件和软件的配置、管理和维护。用户无需关心底层的基础设施管理,可以专注于数据分析和查询。
🔎2.4 安全性
Redshift
提供了一系列安全性功能,包括数据加密、访问控制和网络隔离。这有助于保护数据的机密性和完整性。
🔎2.5 一体化分析解决方案
Redshift
可以与其他 AWS 服务(如
S3
和
Glue
)以及第三方工具(如
Tableau
和
PowerBI
)无缝集成,为用户提供一体化的分析解决方案。
🚀三、RedShift的常见实践问题解答
🔎3.1 RedShift和MySQL有什么不同?

下面是使用Markdown表格展示Redshift和MySQL的不同之处:
方面RedshiftMySQL架构列存储行存储主要用途数据仓库解决方案,大规模数据分析和报表查询在线事务处理(OLTP)和常规关系型数据库需求数据处理能力处理大规模数据集和复杂查询,适用于数据分析和报表低延迟和高并发处理能力,适用于在线交互式应用和事务处理扩展性自动扩展存储和计算资源,弹性扩展能力需手动进行水平或垂直扩展托管方式由AWS完全托管,无需自行管理和维护可自行部署在服务器上,也可选择云托管服务数据一致性较弱的数据一致性和事务支持强大的事务支持和数据一致性保证
需要注意的是,
Redshift
和
MySQL
使用的查询语言不同。
Redshift
使用的是类似于
PostgreSQL
的
SQL
方言,而
MySQL
使用的是标准的
SQL
语言。不过大部分情况下是通用的。
🔎3.2 RedShift实现怎删改查怎么写?
这个和主流的关系型数据库差不多。大家可以参见我这一篇文章AWS RedShift实战应用SQL大全及经验分享。
🔎3.3 怎么把MySQL的数据放进RedShift?
RedShift
和
AWS s3
结合的非常好,可以利用
mydumper
将
MySQL
数据导出后,处理成一定规则的数据文件,传输到
s3
,然后通过
Copy
命令直接拷贝到
RedShift
。拷贝的命令如下:
copy student_score from's3://xxxx/student_score/'
access_key_id ''
secret_access_key ''
ACCEPTINVCHARS AS' ' TRUNCATECOLUMNS IGNOREBLANKLINES delimiter'\t'
gzip region 'us-east-1'-- 其中注意delimiter要根据实际文件里面的分隔符来确定
🔎3.4 RedShift为什么很多时候会插入失败?
Redshift
提倡大批次处理插入,如果批次太小很频繁可能会导致写入失败,这个时候建议先将数据放入缓冲区或者文件,然后文件积累到一定量,在通过上面说到的
Copy
命令到数据库,这才是一个最佳实践。
🔎3.5 RedShift如何进行查询优化?
首先查询的时候要保证表的量够小,所以要使用一些任务调度的方式,将大表转化成小表,尤其是行为数据这种表,实际上很多业务查询的时候用不到这一整张表,这个时候需要我们独立成特定的小表。另外注意要关注整个数仓的负载,当别的任务执行过多的时候,当前任务的算力必然会被分担。
🔎3.6 RedShift能做实时数仓与实时计算么?
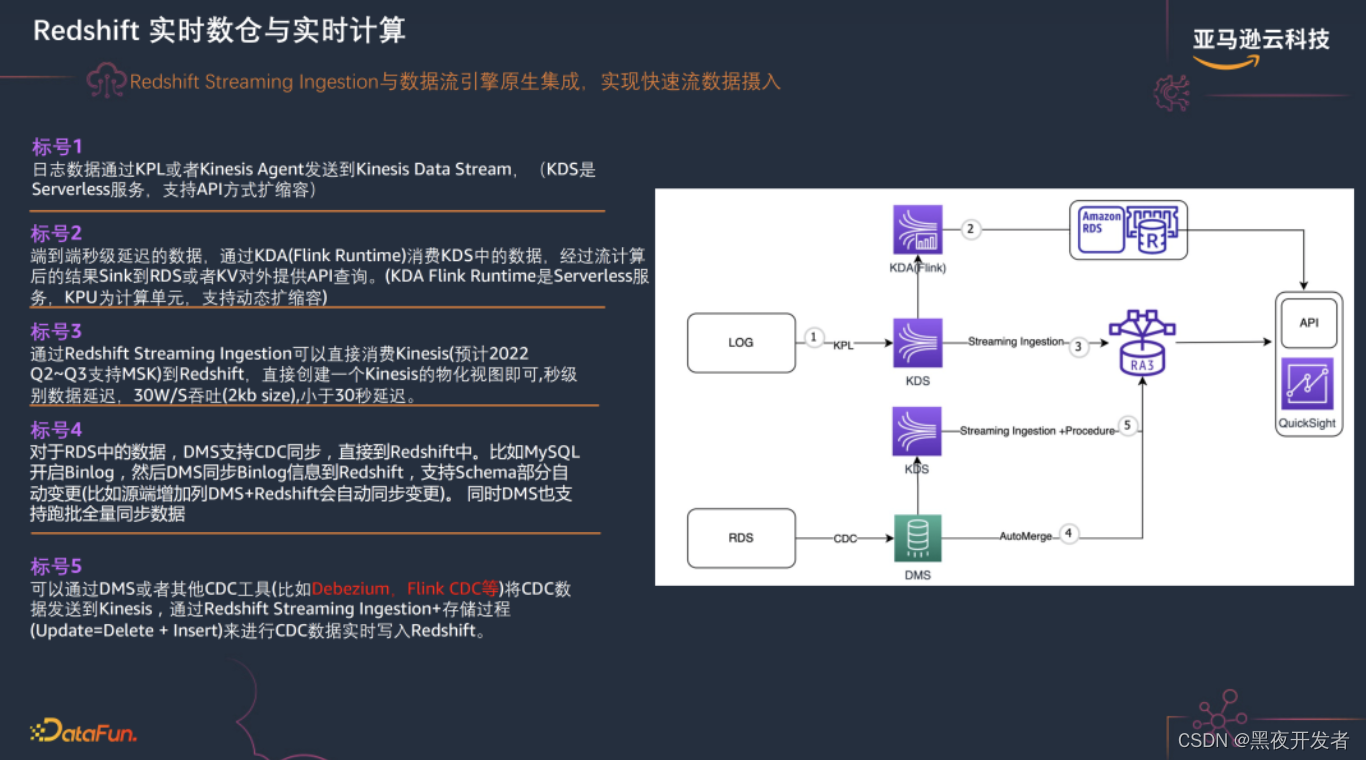
当然这是可以的,不过要借助一些其他的工具和技术来实现。毕竟数据从产生到进入数据仓库还是要经过一系列的过程。下面是一些实践的用法:
🔎3.7 电商网站可以用Redshift存储数据么?
完全
OK
的,
Redshift
的查询是要先解释查询语句才能进行查询,查询的速度还是比较慢的,比
MySQL
或者说
Clickhoue
慢的多,当然这个说法不一定准确,但你应该能了解我的意思,所以给网站服务一般还是不能直接查
Redshift
,还是得依赖一些缓存作为支撑,不过这个取决于具体的业务设计。行为数据如何进库,参考我上面提到的方式。
🔎3.8 Redshift支持多大规模的存储?
AWS
官方宣传的是
PB级别
的存储,目前我们的规模在几百TB,每天支撑数百亿级别的数据清洗,数据分析,数据挖掘任务,还是比较可以的,对大量报表以及系统业务做到了不错的支撑。
🔎3.9 如何维护数据库的数据正确性?
如果要把业务数据库的数据放进
Redshift
,可以通过在业务库放一个
last_update_time
字段,通过这个字段的变化来
增量同步
数据进去,如果实在不放心,也可以每天进行一次
全量数据覆盖
,先删除再写入,这样配合起来用,同时也可以抽样进行两边的数据对比,进行一个数据监控。
🚀四、常见的一些数据库操作分享
🔎4.1 创建表
Redshift有自己独特的建表语句,大体上看上去,和常见的关系型数据库差不多,另外它可以定义索引,但是不具备索引约束
CREATETABLE"public"."users"("user_id""int4","name""varchar","gender""int4","age""numeric")WITH OIDS;
🔎4.2 数据的增删改查
增删改查和MySQL差不多
-- 增加数据insertinto users(user_id, name, gender, age)values(1,'xiaomin','男','12');--查询数据select*from users where name='xiaoming';--修改数据update users set age=13where name ='xiaoming';--删除数据deletefrom users where name='xiaoming';
🔎4.3 判断语句
case when很多时候用来代替if,下面演示统计学生的name,如果为null或空字符串,用unkonw显示
selectcasewhen name isnullthen'unkown'when name =''then'unkown'else name endas name
from users
🔎4.4 类型转化
Redshift是强类型的,这点和MySQL还是有些区别,因为其底层是Java的,所以查询及匹配要求类型对应。
cast(create_time astimestamp)-- 字符串转化为时间戳
cast(student_id as interger)-- 将字符串转化为整形
🔎4.5 数值运算
下面演示了一个求客单价的逻辑,用户总用的消费金额/总共用户数得到客单价,最后再四舍五入规范一下数据。
-- 这里演示类型转化的除法运算,以及保留两位小数的用法select
cast(total_amount asnumeric)/cast(total_users asnumeric)as avg_user_amount,round(avg_user_amount,2)as avg_user_amount1
from ···
🔎4.6 字符串操作
字符串拼接,下面用
||
将三个字符串进行顺序组合。
select id ||'-'|| name ||'-'|| age from id_name_age
字符串截取,下面演示了获取用户名前5个字符的写法。
select substring(name,0,5)from users
大小写转化,下面演示了将用户名转化为小写
select lower(name)as name, age from users
🚀五、总结
本文从主流的数据仓库出发进行讲解,然后重点分析了一下
AWS Redshift
这款产品的特点,及其在数据分析领域的优劣势。然后根据平时在工作用的实际应用实践,给出了常见的一些疑惑问题解答。最后通过一些日常使用的SQL分享,让大家来初识这一款数据仓库。如果想要深入学习大数据或者数据挖掘,可以继续去官网学习相关技术。

**
高山仰止,景行行止,学无止境,感谢阅读,我们下次见。
**
版权归原作者 黑夜开发者 所有, 如有侵权,请联系我们删除。