
识别手写图片
因为这个例子是 TensorFlow 官方的例子,不会说的太详细,会加入了一点个人的理解,因为TensorFlow提供了各种工具和库,帮助开发人员构建和训练基于神经网络的模型。TensorFlow 中最重要的概念是张量(Tensor),它代表了多维数组或矩阵,因此 TensorFlow 支持各种不同类型的计算,如线性回归、逻辑回归、卷积神经网络、循环神经网络等。所以帮我们极大减少了对数学与算法基础的要求。
准备数据
这里用来识别的手写图片大致是这样的,为了降低复杂度,每个图片是 28*28 大小。

但是直接丢图片给我们的模型,模型是不认识的,所以必须要对图片进行一些处理。
如果了解线性代数,大概知道图片的每个像素点其实可以表示为一个二维的矩阵,对图片做各种变换,比如翻转啊什么的就是对这个矩阵进行运算,于是我们的手写图片大概可以看成是这样的:

这个矩阵展开成一个向量,长度是 28*28=784。我们还需要另一个东西用来告诉模型我们认为这个图片是几,也就是给图片打个 label。这个 label 也不是随便打的,这里用一个类似有 10 个元素的数组,其中只有一个是 1,其它都是 0,哪位为 1 表示对应的图片是几,例如表示数字 8 的标签值就是 ([0,0,0,0,0,0,0,0,1,0])。
这些就是单张图片的数据处理,实际上为了高效的训练模型,会把图片数据和 label 数据分别打包到一起,也就是 MNIST 数据集了。
MNIST数据集
MNIST 数据集是一个入门级的计算机视觉数据集,官网是Yann LeCun's website。 我们不需要手动去下载这个数据集, 1.0 的 TensorFlow 会自动下载。
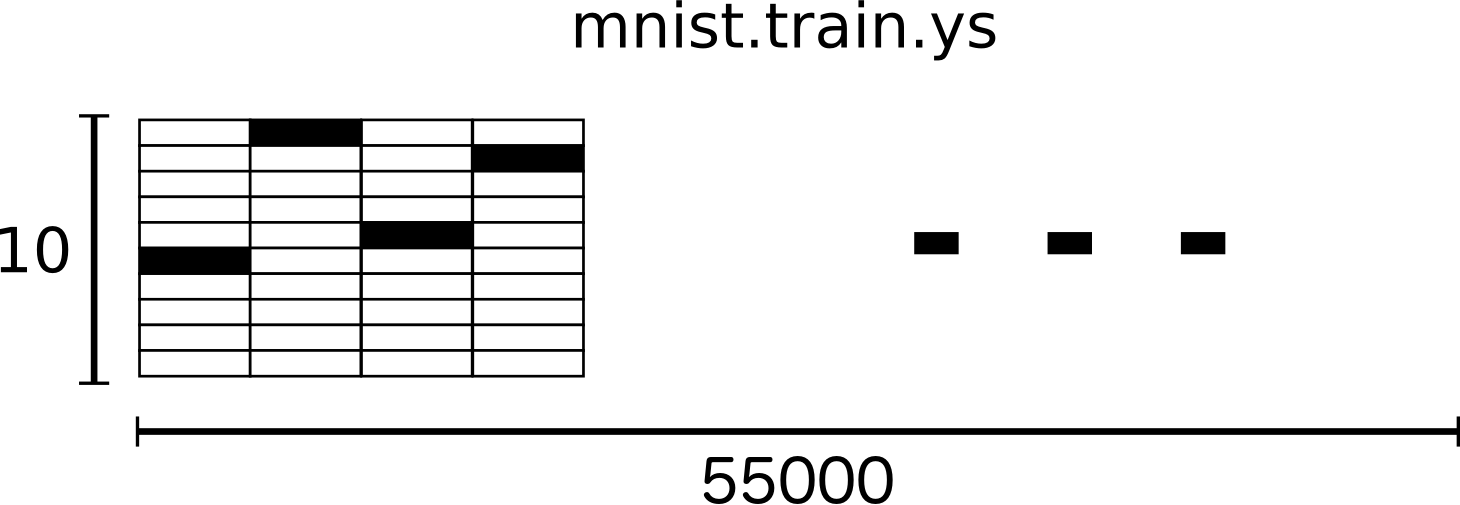
这个训练数据集有 55000 个图片数据,用张量的方式组织的,形状如 [55000,784],如下图:

还记得为啥是 784 吗,因为 28*28 的图片。
label 也是如此,[55000,10]:
这个数据集里面除了有训练用的数据之外,还有 10000 个测试模型准确度的数据。
整个数据集大概是这样的:
现在数据有了,来看下我们的模型。
Softmax 回归模型
Softmax 中文名叫归一化指数函数,这个模型可以用来给不同的对象分配概率。比如判断

的时候可能认为有 80% 是 9,有 5% 认为可能是 8,因为上面都有个圈。
我们对图片像素值进行加权求和。比如某个像素具有很强的证据说明这个图不是 1,则这个像素相应的权值为负数,相反,如果这个像素特别有利,则权值为正数。
如下图,红色区域代表负数权值,蓝色代表正数权值。
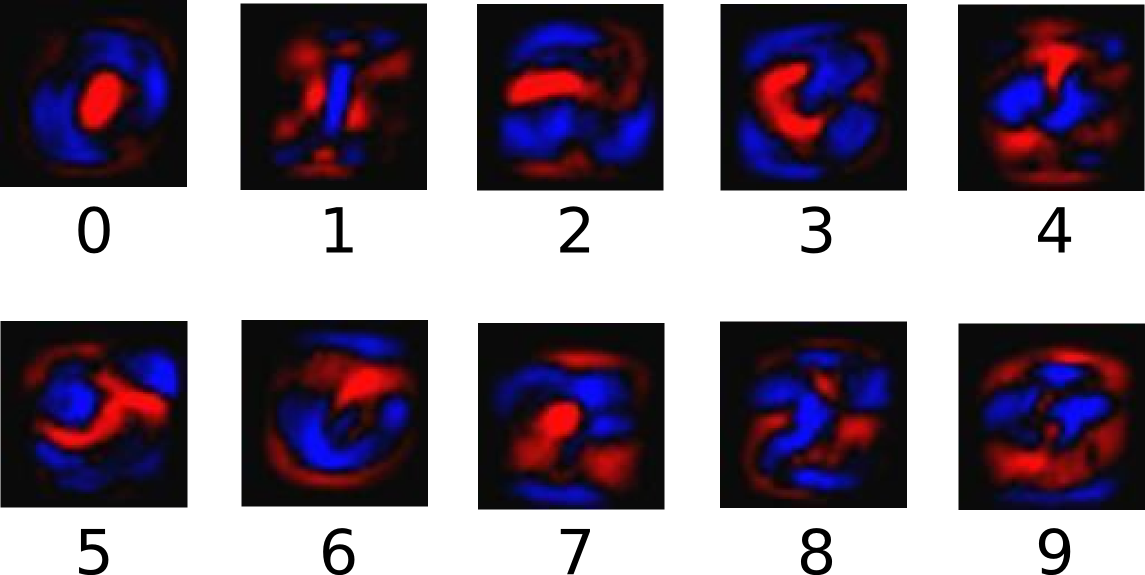
同时,还有一个偏置量(bias) 用来减小一些无关的干扰量。
Softmax 回归模型的原理大概就是这样,更多的推导过程,可以查阅一下官方文档,有比较详细的内容。
说了那么久,终于可以上代码了。
训练模型
具体引入的一些包这里就不一一列出来,主要是两个,一个是 tensorflow 本身,另一个是官方例子里面用来输入数据用的方法。
from tensorflow.examples.tutorials.mnist import input_data
import tensorflow as tf
之后就可以建立我们的模型。
# Create the model
x = tf.placeholder(tf.float32, [None, 784])
W = tf.Variable(tf.zeros([784, 10]))
b = tf.Variable(tf.zeros([10]))
y = tf.matmul(x, W) + b
这里的代码都是类似占位符,要填了数据才有用。
- x 是从图片数据文件里面读来的,理解为一个常量,一个输入值,因为是 28*28 的图片,所以这里是 784;
- W 代表权重,因为有 784 个点,然后有 10 个数字的权重,所以是 [784, 10],模型运算过程中会不断调整这个值,可以理解为一个变量;
- b 代表偏置量,每个数字的偏置量都不同,所以这里是 10,模型运算过程中也会不断调整这个值,也是一个变量;
- y 基于前面的数据矩阵乘积计算。
tf.zeros 表示初始化为 0。
我们会需要一个东西来接受正确的输入,也就是放训练时准确的 label。
# Define loss and optimizer
y_ = tf.placeholder(tf.float32, [None, 10])
我们会用一个叫交叉熵的东西来衡量我们的预测的「惊讶」程度。
关于交叉熵,举个例子,我们平常写代码的时候,一按编译,一切顺利,程序跑起来了,我们就没那么「惊讶」,因为我们的代码是那么的优秀;而如果一按编译,整个就 Crash 了,我们很「惊讶」,一脸蒙逼的想,这怎么可能。
交叉熵感性的认识就是表达这个的,当输出的值和我们的期望是一致的时候,我们就「惊讶」值就比较低,当输出值不是我们期望的时候,「惊讶」值就比较高。
cross_entropy = tf.reduce_mean(
tf.nn.softmax_cross_entropy_with_logits(labels=y_, logits=y))
这里就用了 TensorFlow 实现的 softmax 模型来计算交叉熵。
交叉熵,就是我们想要尽量优化的值,让结果符合预期,不要让我们太「惊讶」。
TensorFlow 会自动使用反向传播算法(backpropagation algorithm) 来有效的确定变量是如何影响你想最小化的交叉熵。然后 TensorFlow 会用你选择的优化算法来不断地修改变量以降低交叉熵。
train_step = tf.train.GradientDescentOptimizer(0.5).minimize(cross_entropy)
这里用了梯度下降算法(gradient descent algorithm)来优化交叉熵,这里是以 0.5 的速度来一点点的优化交叉熵。
之后就是初始化变量,以及启动 Session
sess = tf.InteractiveSession() tf.global_variables_initializer().run()
启动之后,开始训练!
# Train for _ in range(1000): batch_xs, batch_ys = mnist.train.next_batch(100) sess.run(train_step, feed_dict={x: batch_xs, y_: batch_ys})
这里训练 1000 次,每次随机找 100 个数据来练习,这里的
feed_dict={x: batch_xs, y_: batch_ys}
,就是我们前面那设置的两个留着占位的输入值。
到这里基本训练就完成了。
评估模型
训练完之后,我们来评估一下模型的准确度。
# Test trained model
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
print(sess.run(accuracy, feed_dict={x: mnist.test.images,
y_: mnist.test.labels}))
tf.argmax 给出某个tensor对象在某一维上的其数据最大值所在的索引值。因为我们的 label 只有一个 1,所以 tf.argmax(_y, 1) 就是 label 的索引,也就是表示图片是几。把计算值和预测值 equal 一下就可以得出模型算的是否准确。
下面的 accuracy 计算的是一个整体的精确度。
这里填入的数据不是训练数据,是测试数据和测试 label。
最终结果,我的是 0.9151,91.51% 的准确度。官方说这个不太好,如果用一些更好的模型,比如多层卷积网络等,这个识别率可以到 99% 以上。
官方的例子到这里就结束了,虽然说识别了几万张图片,但是我一张像样的图片都没看到,于是我决定想办法拿这个模型真正找几个图片测试一下。
用模型测试
看下上面的例子,重点就是放测试数据进去这里,如果我们要拿图片测,需要先把图片变成相应格式的数据。
sess.run(accuracy, feed_dict={x: mnist.test.images,
y_: mnist.test.labels})
看下这里 mnist 是从 tensorflow.examples.tutorials.mnist 中的 input_data 的 read_data_sets 方法中来的。
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
Python 就是好,有啥不懂看下源码。源码的在线地址在这里
打开找 read_data_sets 方法,发现:
from tensorflow.contrib.learn.python.learn.datasets.mnist import read_data_sets
在这个文件里面。
def read_data_sets(train_dir,
fake_data=False,
one_hot=False,
dtype=dtypes.float32,
reshape=True,
validation_size=5000):
...
...
...
train = DataSet(train_images, train_labels, dtype=dtype, reshape=reshape)
validation = DataSet(validation_images,
validation_labels,
dtype=dtype,
reshape=reshape)
test = DataSet(test_images, test_labels, dtype=dtype, reshape=reshape)
return base.Datasets(train=train, validation=validation, test=test)
可以看到,最后返回的都是是一个对象,而我们用的 feeddict={x: mnist.test.images, y: mnist.test.labels} 就是从这来的,是一个 DataSet 对象。这个对象也在这个文件里面。
class DataSet(object):
def __init__(self,
images,
labels,
fake_data=False,
one_hot=False,
dtype=dtypes.float32,
reshape=True):
"""Construct a DataSet.
one_hot arg is used only if fake_data is true. `dtype` can be either
`uint8` to leave the input as `[0, 255]`, or `float32` to rescale into
`[0, 1]`.
"""
...
...
这个对象很长,我就只挑重点了,主要看构造方法。一定要传入的有 images 和 labels。其实这里已经比较明朗了,我们只要把单张图片弄成 mnist 格式,分别传入到这个 DataSet 里面,就可以得到我们要的数据。
网上查了下还真有,代码地址,对应的文章:www.jianshu.com/p/419557758…,文章讲的有点不清楚,需要针对 TensorFlow 1.0 版本以及实际目录情况做点修改。
直接上我修改后的代码:
from PIL import Image
from numpy import *
def GetImage(filelist):
width=28
height=28
value=zeros([1,width,height,1])
value[0,0,0,0]=-1
label=zeros([1,10])
label[0,0]=-1
for filename in filelist:
img=array(Image.open(filename).convert("L"))
width,height=shape(img);
index=0
tmp_value=zeros([1,width,height,1])
for i in range(width):
for j in range(height):
tmp_value[0,i,j,0]=img[i,j]
index+=1
if(value[0,0,0,0]==-1):
value=tmp_value
else:
value=concatenate((value,tmp_value))
tmp_label=zeros([1,10])
index=int(filename.strip().split('/')[2][0])
print "input:",index
tmp_label[0,index]=1
if(label[0,0]==-1):
label=tmp_label
else:
label=concatenate((label,tmp_label))
return array(value),array(label)
这里读取图片依赖 PIL 这个库,由于 PIL 比较少维护了,可以用它的一个分支 Pillow 来代替。另外依赖 numpy 这个科学计算库,没装的要装一下。
这里就是把图片读取,并按 mnist 格式化,label 是取图片文件名的第一个字,所以图片要用数字开头命名。
如果懒得 PS 画或者手写的画,可以把测试数据集的数据给转回图片,实测成功,参考这篇文章:如何用python解析mnist图片
新建一个文件夹叫 test_num,里面图片如下,这里命名就是 label 值,可以看到 label 和图片是对应的:

开始测试:
print("Start Test Images")
dir_name = "./test_num"
files = glob2.glob(dir_name + "/*.png")
cnt = len(files)
for i in range(cnt):
print(files[i])
test_img, test_label = GetImage([files[i]])
testDataSet = DataSet(test_img, test_label, dtype=tf.float32)
res = accuracy.eval({x: testDataSet.images, y_: testDataSet.labels})
print("output: ", res)
print("----------"
这里用了 glob2 这个库来遍历以及过滤文件,需要安装,常规的遍历会把 Mac 上的 .DS_Store 文件也会遍历进去。
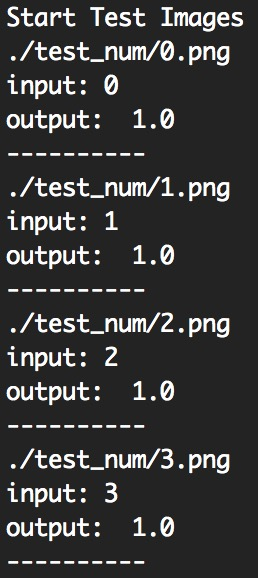
可以看到我们打的 label 和模型算出来的是相符的。
然后我们可以打乱文件名,把 9 说成 8,把 0 也说成 8:

可以看到,我们的 label 和模型算出来的是不相符的。
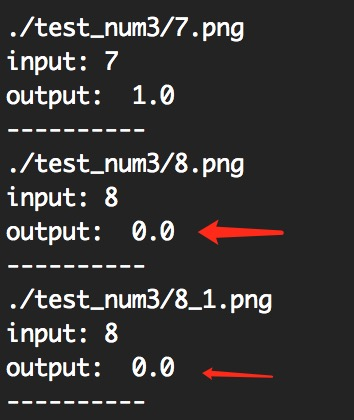
恭喜,到着你就完成了一次简单的人工智能之旅。
总结
从这个例子中我们可以大致知道 TensorFlow 的运行模式:
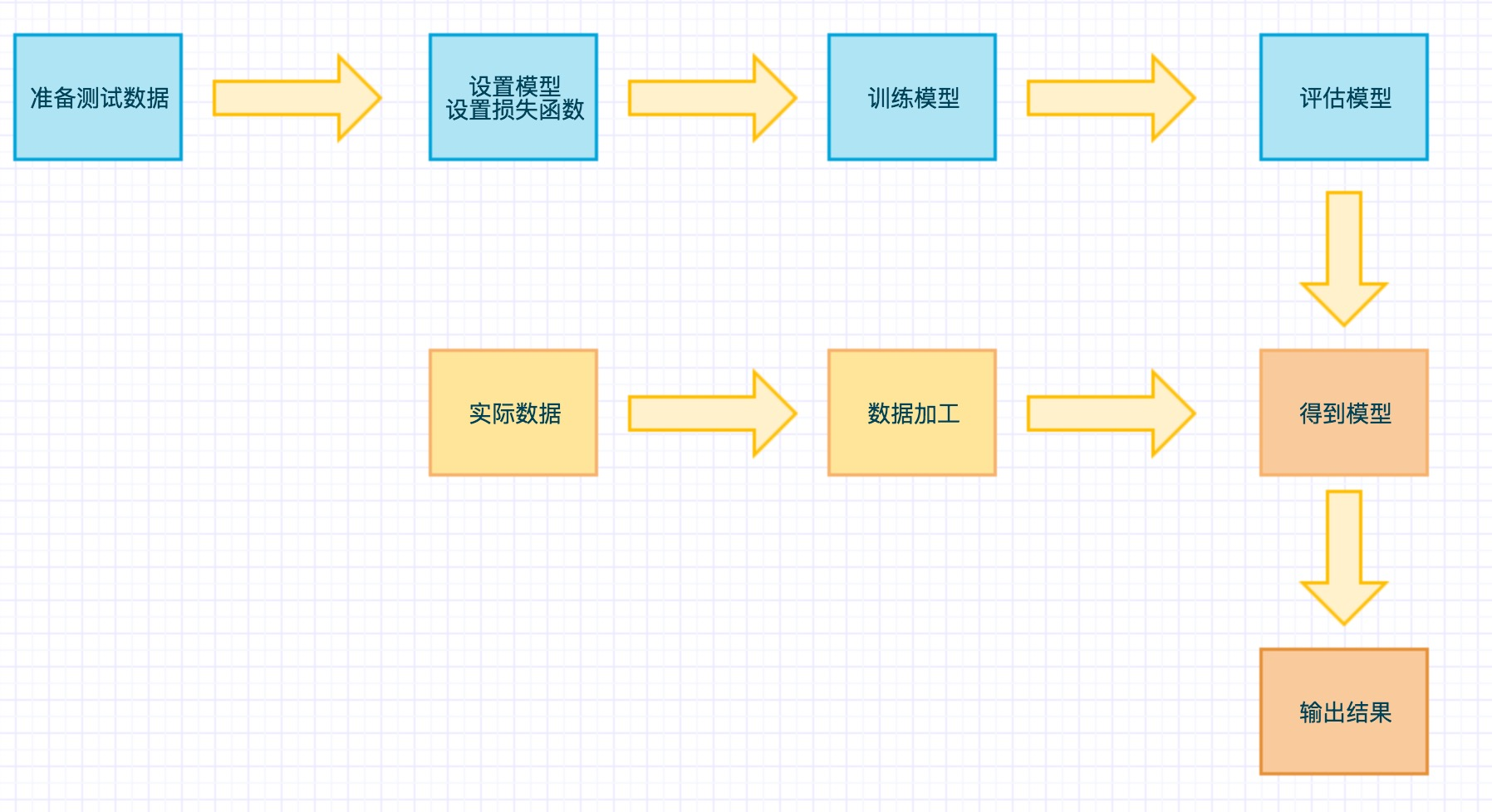
例子中是每次都要走一遍训练流程,实际上是可以用 tf.train.Saver() 来保存训练好的模型的。这个入门例子完成之后能对 TensorFlow 有个感性认识。
TensorFlow 没有那么神秘,没有我们想的那么复杂,也没有我们想的那么简单,并且还有很多数学知识要补充呢。
版权归原作者 人工智能MOS 所有, 如有侵权,请联系我们删除。