
20220715一点点摆烂记录
数据架构设计
数据架构设计概述
数据仓库数据架构设计是为应用架构设计提供数据框架支撑,为应用数据资源采集、存储、处理和交换提供建设性依据。主要从数据如何分布存储,数据的流转关系,数据存储模型设计等内容进行描述。
数据总体架构
数据存储按类型分为贴源数据、标准化数据、主题数据和集市数据,各源系统项目组提供源系统数据质量标准,数据仓库项目组参考源系统标准及应用需求制定数据仓库质量标准规范,构建数据模型及质量报告,源系统项目组可查阅数据质量报告,同时也能够应用数据仓库中的信息。如下图所示: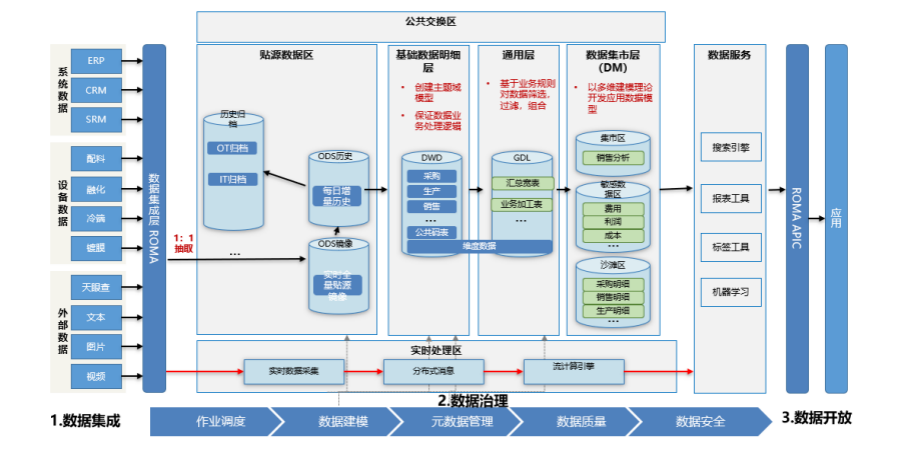
贴源层
贴源层是各源系统数据进入在数据仓库系统中数据存储的第一层,是各源系统数据进入数据仓库系统的入口,是为数据仓库其它数据层提供数据依据。贴源层需把源系统数据中初始化的数据和增量数据加工处理,保证与源系统数据一致;初始化数据与增量数据整合后保证与源系统数据一致,并提供与源系统一致数据集成的服务界面。
其主要特点:
- 把不同数据源的数据收集、加载到贴源层统一存储
- 为数据仓库内部和外部数据消费者提供统一的数据源
- 生成源系统和贴源层数据的依赖关系
- 保证源系统和贴源层数据一致性,不做清洗和转换
- 异常和错误数据处理
- 将不同来源的数据整合到统一物理技术平台和数据模型,对应用直接服务。
基础层
基础层是一个面向主题的、集成的、可变的、当前的细节数据集合。是在贴源层数据的基础上,是把不同数据源的数据收集、整理、清洗、转化后加载到一个新的数据源,是对贴源层数据进行进一步沉淀,为数据消费者提供统一数据视图。
其主要特点:
- 业务逻辑转换
- 通常和贴源层数据粒度保持一致
- 需要对贴源层数据进行过滤、清洗、转换,初步实现数据质量的标准统一
- 一般采用关系型数据库进行结构化数据存储
通用层
通用层是根据企业核心业务价值链构建最细业务粒度汇总层,包含应用层数据发布之前的聚合数据。在本层需要进行指标与维度的标准化,保证指标数据的唯一性。其主要特点:
- 指标与维度的标准化
- 数据产品发布区
- 明细数据和历史数据处理
- 宽表、汇总表模型
- 按照星型模型或雪花模型设计方式建设
应用层
以需求为导向,以分析指标为核心,满足集团部门各业务处室、专业公司和地区公司的用户应用展示需求,为最终用户提供数据服务需求。该层主要特点:
- 采用星型或雪花型模型设计方法构建数据模型
- 按需提供数据
- 数据粒度高度汇总
- 采用星型或雪花型模型设计方法构建数据模型
其中对应用层按照功能又划分:
应用区:存放和发布正式非敏感应用数据。
敏感区:存放和发布敏感数据,如薪资、工艺等信息。
沙滩区:进行数据开发、测试,不需再单独部署环境。
数据流转关系
各层之间数据流转
数据存储核心数据流转流程为贴源层的数据流转到基础层,基础层的数据流转到通用层或应用数据层,通用层的数据流转到应用数据层。数据存储各层之间的流转关系如下图所示: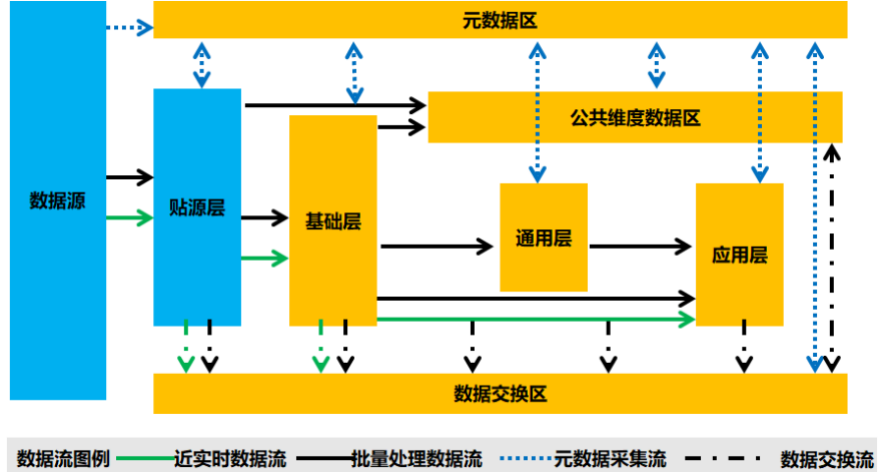
应用服务和数据之间关系
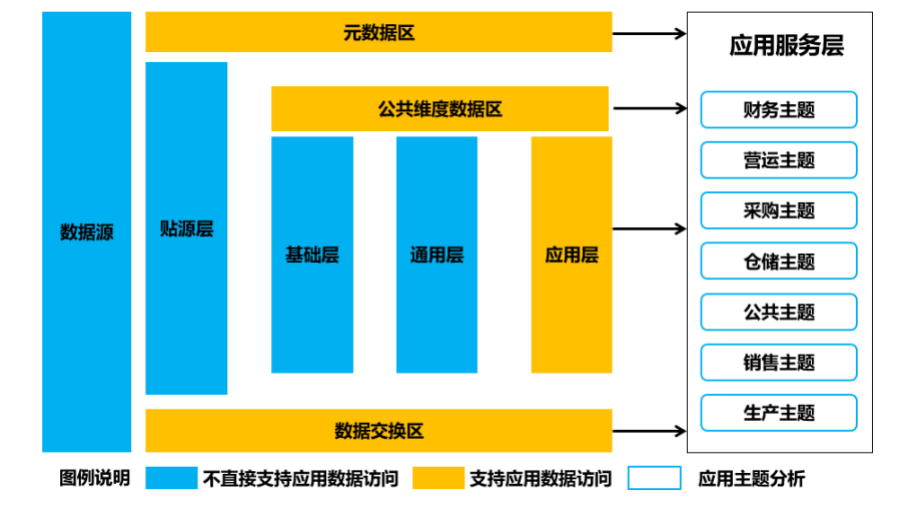
数据库
数据库程序命名规范
所有数据库对象,应该以主题开头,加上该数据库对象的作用,再以数据库对象类型结尾。
过程命名为:目标表名称_ PRO(Procedure简写)
客户基本信息的ETL过程PRD_CUST_BASE_INFO_PRO。非ETL过程,需要描述清楚过程的含义,不得超过30位字符。
自定义函数命名为:函数名称_ FUN(Function首字母),函数名称需要定义清楚自定义函数的含义,不得超过30位字符。
触发器命名为:触发器名称_ TRG(Trigger),触发器名称需要定义清楚触发器的含义,不得超过30位。
自定义变量命名为L(local variable)_变量名称,变量名称需要定义清楚变量的含义。
输入参数命名为P_参数名。
输出参数命名为X_参数名。
局部变量命名为L_参数名。
全局变量命名为L_参数名。
函数返回值命名为R_参数名。
注释规范
注释是程序开发的必不可少的一部分,好的注释能在程序异常时快速定位问题,从而解决问题。对于较为复杂的数据操作流程应有充分的注释,注明实现的功能,业务逻辑关系、输入输出关系等内容多行注释。
程序注释包括如下部分:
- 程序说明,描述程序用途
- 开发人员名称
- 程序开发日期
- 源数据表,描述程序中所涉及的来源表、中间表
- 目标表,即结果表
- 参数信息 历史版本,通过查看历史版本,可明确程序的版本变更情况。
书写规范
SQL编写时,统一使用大写。对于注释缩进、对齐,可在程序开发时使用PLSQL Developer的美化功能使程序完成缩进。多数据表连接时,定义表别名引用所用的字段列。
- 简化关键SQL 关键SQL语句,尽量简化,避免包含太多的子查询,避免执行错误的可能,原则上不能超过两层。如存在子查询的嵌套情况,可采用中间表过渡的方式代替子查询。
- 避免使用游标 游标在数据库中的使用是耗费资源的,并且在大部分的情况下为了保证执行效率都会和索引配合使用,需要额外的资源开销。
- 避免复杂SQL语句使用自定义函数 自定义函数和游标的效果和效率是一样的,带SQL语句的自定义函数的性能与游标同样差,需要避免使用,可采取中间表或者关联来代替。
- 复合和计算的结果 对于复合和计算所得出的结果,统一命名别名。数值做除法运算时须对被除数进行非0的判断。
- 避免成立或不成立表达式 避免在条件语句(WHERE)后使用成立表达式(1=1),或不成立表达式(1=2)。
- 避免DBlink DBlink能够方便使用数据表,但因为DBlink的Session是基于连接池的管理中可能会引起被连接的数据库的Session泛滥,从而消耗进程资源,并且DBlink没有详细的日志记录,不易排查问题。
- 禁用无字段的查询、插入语句 禁止使用无字段项的查询和插入语句,如“SELECT * FROM TABLE”;“INSERT INTO TABLE”,需明确所查询和插入的字段列。
模型设计规范
基础层:按系统进行数据整合,对系统共用数据进行溯源,并从源头提取需要的实体和属性至基础层。
通用层:加工应用层所应用到的通用指标和公共维度。通用指标判断标准是大于等于2个报表应用的指标。
应用层:根据业务应用划分主题,包括有货品等。
模型建设思路
借鉴行业数据模型的最佳实践与规范,结合数据仓库总体架构规划,从建模策略、建模阶段、建模方法和建模原则四个角度开展数据仓库应用建模工作。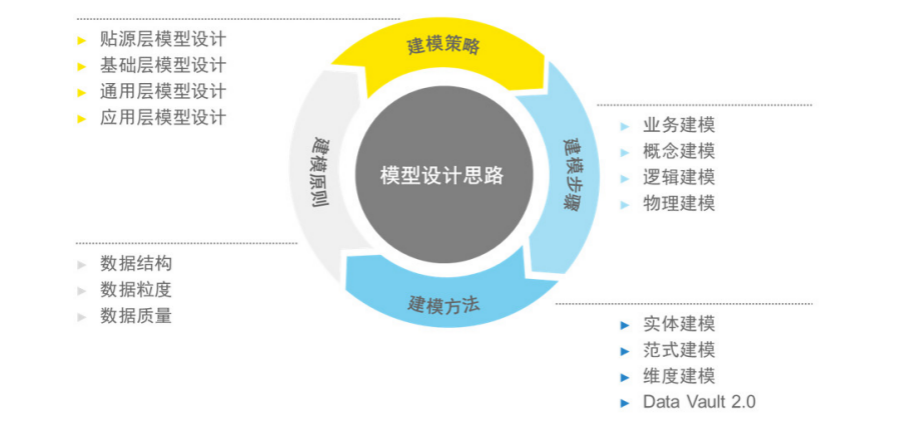
建模步骤
模型建设过程中分业务建模、概念建模、逻辑建模和物理建模四个步骤,具体内容如下图所示
建模原则
贴源层
所有实体表物理或者逻辑集中到同一数据库或者模式集中管理。
实体表数据结构与数据来源保持一致,添加或产生增量标识、采集时间戳和数据来源标识等元数据信息。
缓存层数据尽量保持原始交易数据原貌,原则上不做清洗和转换(由于数据质量问题导致加载失败等除外),以便于支持源系统数据质量稽核和审计等。
存储层要保存最细粒度的,通常会保留专业系统或运营系统的当前在线数据
基础层
将各个源数据按照主题域进行分类组织,采用规范、标准的统一数据模型进行整合和集中存储。
基础层结构化数据模型以UDM( Universal Data Modeling)为指导,以扩展E/R元模型为基础,参照标准数据模型进行客户化,遵循3NF范式原则减少数据冗余。
基础层建模基于业务概念抽象和数据驱动,提供标准规范、应用中性、共享的整合数据模型。
基础层结构化数据模型设计要充分考虑未来可能的扩展需求,模型架构要具有足够的灵活性和扩展性,使逻辑数据模型是一个相对稳定的、全面的、灵活可扩展的数据模型。
基础层结构化数据模型必须进行企业级的标准化(模式标准、代码标准等),存储的数据要进行清洗和转换。
基础层结构化数据要保存最细粒度的详细数据,包括当前业务的在线数据和历史数据。
基础层结构化数据按需保留历史轨迹(针对需要历史轨迹的关键实体做历史拉链),但不建议大规模保留数据的历史轨迹版本,否则后期的运维、存储和运算加工的效率和复杂度都会大幅增加。
基础层非结构化数据以数据资源目录为基础,将文件按数据资源目录路径存放到分布式文件存储中。
通用层
通用层模型设计基于各专业领域的业务对象和业务事件,采用维度总线架构思想来构建。业务对象通常用维度实现,业务事件通常用事实表实现,按照事实表的不同类型分为累计快照事实表、周期快照事实表和交易基础事实表。
通用层模型设计面向用户的运营管理、统计分析和查询搜索,是公共维度和共性基础指标的实现载体,支持90%以上的共性应用需求。
通用层模型设计采用维度化的逆范式设计模式,通常采用以下方式:
- 预连接处理:按照总线架构维度和事实表的要求,将分散在多张相关实体表的数据属性进行预连接操作,使相关的维度尽可能组织在特定的维表或者事实表。
- 预计算处理:按照总线架构维度和事实表的要求,对事实表中的基础指标进行加工计算。
- 汇总处理:针对共性的复杂指标,按照对应的维度进行提前聚合处理,以保证共性复杂指标逻辑,避免重复加工,提供数据一致性和响应效率。
通用层模型的粒度尽可能保留到最细交易粒度(汇总处理除外),以保持模型间的连通性,并能够最大程度、最快速地响应新需求。
应用层
应用数据层模型采用维度建模方法,以需求驱动的方式进行设计。
应用数据层模型维度要与通用层模型维度保持一致性,即可以直接引用通用层模型中维度,又可以从通用层模型中维度衍生出子维度;
应用数据层模型通常采用关系型星型/雪花型实现;
应用数据层的数据绝大多数来自于通用层,以达到避免公共逻辑重复加工计算,保证数据一致性,提升新需求响应时效;部分需求用到的非公共维度/基础指标通用层不支持,需要从基础层直接加工计算,这类应用应该控制在应用总量的10%以内;少部分实时应用,采用从基础层加工实时数据+从通用层加工T+1数据相结合的模式;
应用数据层要根据应用需求决定,是保留历史快照数据不变,还是回溯重算历史数据以及回溯时长等。
所以,在实施过程中,根据数据仓库存储多层建设,并分别选择核心的建模方法,以规避各种建模方法的缺陷,扬长避短,既保障数据仓库数据仓库应用模型建设的延续性,又要平衡ETL运行效率和前端应用展现性能。
贴源层设计
贴源层通过从各个业务系统抽取源数据,分别对应于技术架构中的源业务系统和逻辑架构中的源数据。
基础层设计
根据数据仓库应用的需求,阶段性将所需数据进行清洗、转换、整合到数据仓库基础层中。基础层按需获取贴源层整合后的数据,再获取根据数据采集频率更新的增量数据。
基础层的第一个职能是对源系统进行整合,第二个职能是对数据进行清洗和初步加工。
数据清洗将不需要的和不符合规范的数据进行处理。数据清洗一般放在抽取的环节进行,这样可以节约后续的计算和存储成本;当源数据为数据库时候,其他抽取数据的SQL中就可以进行很多数据清洗的工作。
基于现有业务过程的开展,在数据的定义和分类过程,完成数据标准化。从业务出发进行梳理,明确业务主题的概念、本质、内涵,以及其在现有的业务系统的分类体系,再结合技术实现的特点对数据进行技术定义、拆分、整合。
根据数据仓库应用需求,对源系统整合至基础层的表进行字段裁剪、数据过滤。数据保存的粒度与贴源层明细数据粒度保持一致。
字段裁剪是基于需求字段和数据质量高的字段进行字段裁剪。
数据过滤是对基础层源系统整合的数据按照数据仓库应用需求对数据进行过滤,依据只保留指标加工所需要的明细级数据的过滤规则。
通用层设计
根据通用层建设特点和要求,结合数据仓库应用应用需求,将所需数据进行清洗、转换、整合到数据仓库通用层目标表中。
通用层模型设计采用维度化的逆范式设计模式,通常采用预连接处理、预计算处理和汇总处理。
版权归原作者 happyhwq 所有, 如有侵权,请联系我们删除。