
前言
吼吼!终于来到了YOLOv5啦!
首先,一个热知识:YOLOv5没有发表正式论文哦~
为什么呢?可能YOLOv5项目的作者Glenn Jocher还在吃帽子吧,hh

目录

前期回顾:
【YOLO系列】YOLOv4论文超详细解读2(网络详解)
【YOLO系列】YOLOv4论文超详细解读1(翻译 +学习笔记)
【YOLO系列】YOLOv3论文超详细解读(翻译 +学习笔记)
【YOLO系列】YOLOv2论文超详细解读(翻译 +学习笔记)
【YOLO系列】YOLOv1论文超详细解读(翻译 +学习笔记)
 🍀本人YOLOv5源码详解系列:
🍀本人YOLOv5源码详解系列:
YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析
YOLOv5源码逐行超详细注释与解读(2)——推理部分detect.py
YOLOv5源码逐行超详细注释与解读(3)——训练部分train.py
YOLOv5源码逐行超详细注释与解读(4)——验证部分val(test).py
YOLOv5源码逐行超详细注释与解读(5)——配置文件yolov5s.yaml
YOLOv5源码逐行超详细注释与解读(6)——网络结构(1)yolo.py
YOLOv5源码逐行超详细注释与解读(7)——网络结构(2)common.py

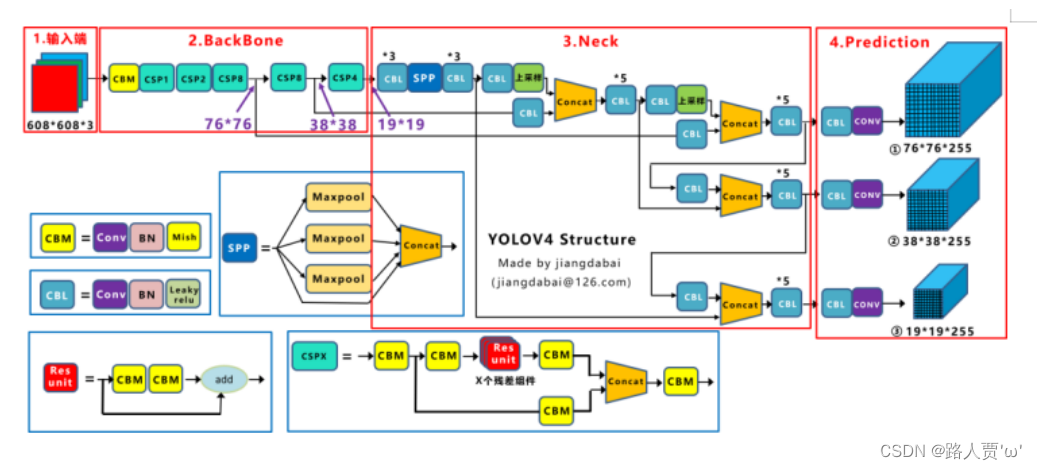
一、YOLOv5的网络结构
YOLOv5特点: 合适于移动端部署,模型小,速度快
YOLOv5有YOLOv5s、YOLOv5m、YOLOv5l、YOLOv5x四个版本。文件中,这几个模型的结构基本一样,不同的是depth_multiple模型深度和width_multiple模型宽度这两个参数。 就和我们买衣服的尺码大小排序一样,YOLOv5s网络是YOLOv5系列中深度最小,特征图的宽度最小的网络。其他的三种都是在此基础上不断加深,不断加宽。

YOLOv5s的网络结构如下:
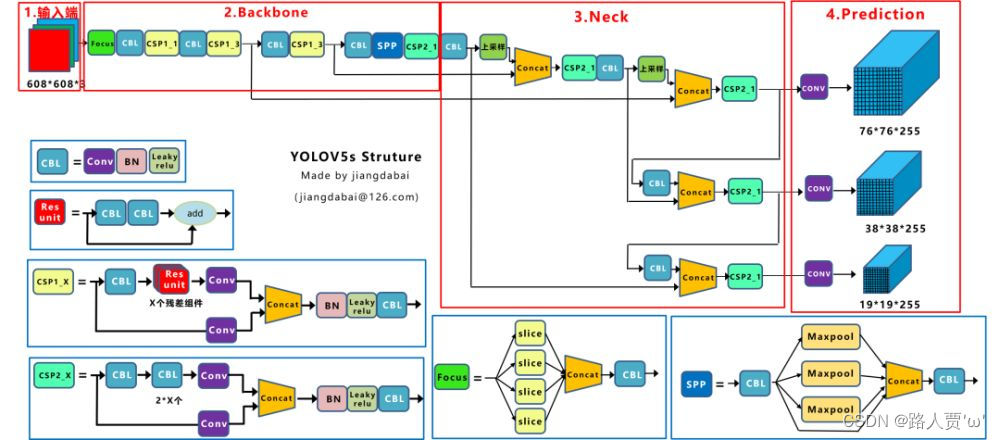
(1)输入端 : Mosaic数据增强、自适应锚框计算、自适应图片缩放
(2)Backbone : Focus结构,CSP结构
(3)Neck : FPN+PAN结构
(4)Head : GIOU_Loss
基本组件:
- Focus:基本上就是YOLO v2的passthrough。
- CBL:由Conv+Bn+Leaky_relu激活函数三者组成。
- CSP1_X:借鉴CSPNet网络结构,由三个卷积层和X个Res unint模块Concate组成。
- CSP2_X:不再用Res unint模块,而是改为CBL。
- SPP:采用1×1,5×5,9×9,13×13的最大池化的方式,进行多尺度融合。
YOLO5算法性能测试图:

二、输入端
(1)Mosaic数据增强
YOLOv5在输入端采用了Mosaic数据增强,Mosaic 数据增强算法将多张图片按照一定比例组合成一张图片,使模型在更小的范围内识别目标。Mosaic 数据增强算法参考 CutMix数据增强算法。CutMix数据增强算法使用两张图片进行拼接,而 Mosaic 数据增强算法一般使用四张进行拼接,但两者的算法原理是非常相似的。

Mosaic数据增强的主要步骤为:
(1)随机选取图片拼接基准点坐标(xc,yc),另随机选取四张图片。
(2)四张图片根据基准点,分别经过尺寸调整和比例缩放后,放置在指定尺寸的大图的左上,右上,左下,右下位置。
(3)根据每张图片的尺寸变换方式,将映射关系对应到图片标签上。
(4)依据指定的横纵坐标,对大图进行拼接。处理超过边界的检测框坐标。
采用Mosaic数据增强的方式有几个优点:
(1)丰富数据集: 随机使用4张图像,随机缩放后随机拼接,增加很多小目标,大大增加了数据多样性。
(2)增强模型鲁棒性: 混合四张具有不同语义信息的图片,可以让模型检测超出常规语境的目标。
(3)加强批归一化层(Batch Normalization)的效果: 当模型设置 BN 操作后,训练时会尽可能增大批样本总量(BatchSize),因为 BN 原理为计算每一个特征层的均值和方差,如果批样本总量越大,那么 BN 计算的均值和方差就越接近于整个数据集的均值和方差,效果越好。
(4)Mosaic 数据增强算法有利于提升小目标检测性能: Mosaic 数据增强图像由四张原始图像拼接而成,这样每张图像会有更大概率包含小目标,从而提升了模型的检测能力。
(2)自适应锚框计算
之前我们学的 YOLOv3、YOLOv4,对于不同的数据集,都会计算先验框 anchor。然后在训练时,网络会在 anchor 的基础上进行预测,输出预测框,再和标签框进行对比,最后就进行梯度的反向传播。
在 YOLOv3、YOLOv4 中,训练不同的数据集时,是使用单独的脚本进行初始锚框的计算,在 YOLOv5 中,则是将此功能嵌入到整个训练代码里中。所以在每次训练开始之前,它都会根据不同的数据集来自适应计算 anchor。
but,如果觉得计算的锚框效果并不好,那你也可以在代码中将此功能关闭哈~
自适应的计算具体过程:
①获取数据集中所有目标的宽和高。
②将每张图片中按照等比例缩放的方式到 resize 指定大小,这里保证宽高中的最大值符合指定大小。
③将 bboxes 从相对坐标改成绝对坐标,这里乘以的是缩放后的宽高。
④筛选 bboxes,保留宽高都大于等于两个像素的 bboxes。
⑤使用 k-means 聚类三方得到n个 anchors,与YOLOv3、YOLOv4 操作一样。
⑥使用遗传算法随机对 anchors 的宽高进行变异。倘若变异后的效果好,就将变异后的结果赋值给 anchors;如果变异后效果变差就跳过,默认变异1000次。这里是使用 anchor_fitness 方法计算得到的适应度 fitness,然后再进行评估。
(3)自适应图片缩放
步骤:
(1) 根据原始图片大小以及输入到网络的图片大小计算缩放比例

原始缩放尺寸是416*416,都除以原始图像的尺寸后,可以得到0.52,和0.69两个缩放系数,选择小的缩放系数。
(2) 根据原始图片大小与缩放比例计算缩放后的图片大小
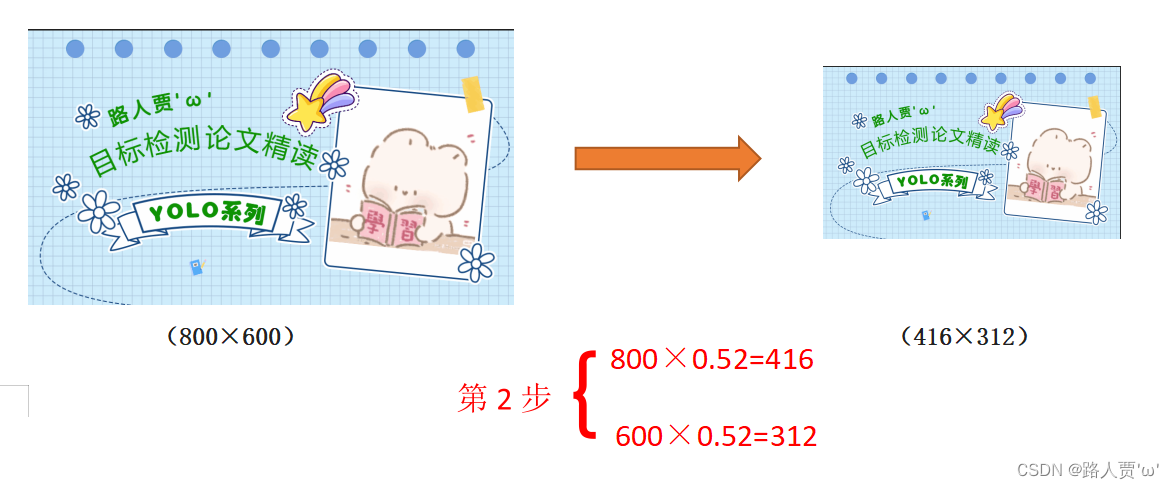
原始图片的长宽都乘以最小的缩放系数0.52,宽变成了416,而高变成了312。
(3) 计算黑边填充数值
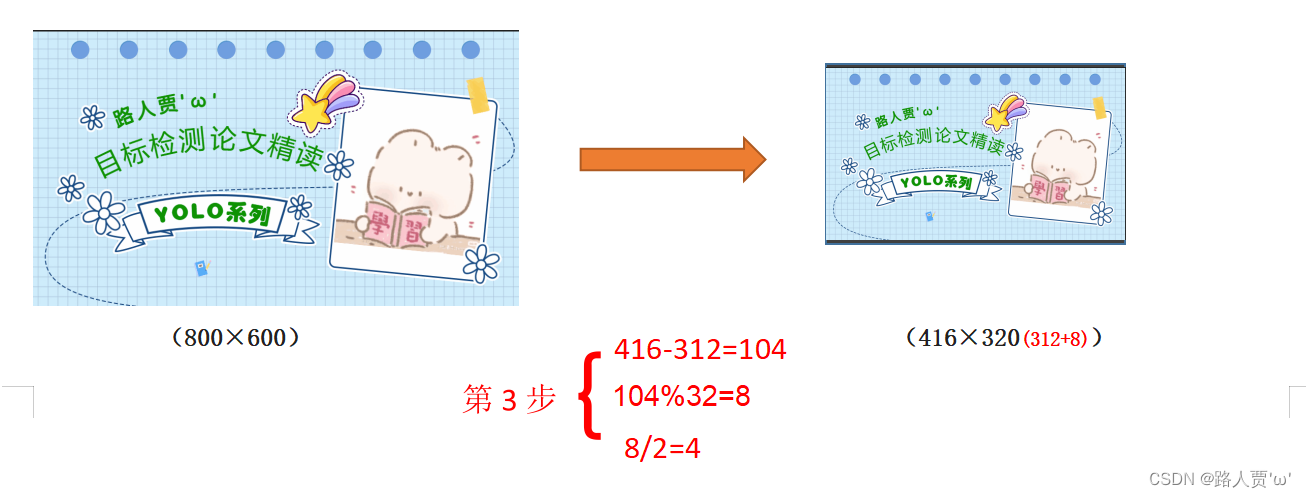
将416-312=104,得到原本需要填充的高度。再采用numpy中np.mod取余数的方式,得到8个像素,再除以2,即得到图片高度两端需要填充的数值。
注意:
(1)Yolov5中填充的是灰色,即(114,114,114)。
(2)训练时没有采用缩减黑边的方式,还是采用传统填充的方式,即缩放到416*416大小。只是在测试,使用模型推理时,才采用缩减黑边的方式,提高目标检测,推理的速度。
(3)为什么np.mod函数的后面用32?
因为YOLOv5的网络经过5次下采样,而2的5次方,等于32。所以至少要去掉32的倍数,再进行取余。以免产生尺度太小走不完stride(filter在原图上扫描时,需要跳跃的格数)的问题,再进行取余。
三、Backbone
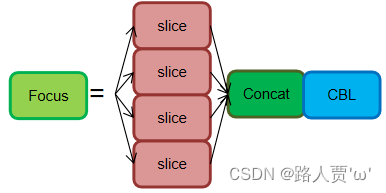
(1)Focus结构
Focus模块在YOLOv5中是图片进入Backbone前,对图片进行切片操作,具体操作是在一张图片中每隔一个像素拿到一个值,类似于邻近下采样,这样就拿到了四张图片,四张图片互补,长得差不多,但是没有信息丢失,这样一来,将W、H信息就集中到了通道空间,输入通道扩充了4倍,即拼接起来的图片相对于原先的RGB三通道模式变成了12个通道,最后将得到的新图片再经过卷积操作,最终得到了没有信息丢失情况下的二倍下采样特征图。
以YOLOv5s为例,原始的640 × 640 × 3的图像输入Focus结构,采用切片操作,先变成320 × 320 × 12的特征图,再经过一次卷积操作,最终变成320 × 320 × 32的特征图。
切片操作如下:
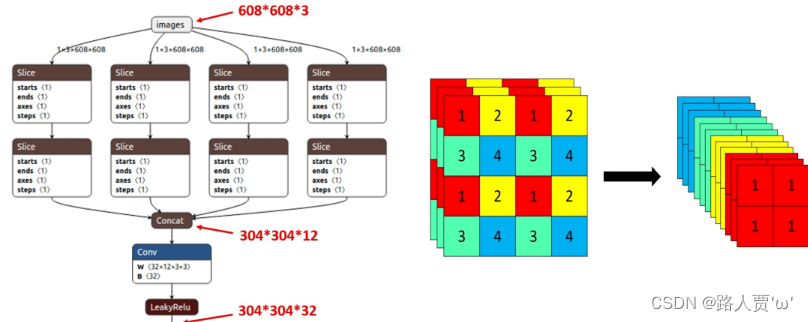
作用: 可以使信息不丢失的情况下提高计算力
不足:Focus 对某些设备不支持且不友好,开销很大,另外切片对不齐的话模型就崩了。
后期改进: 在新版中,YOLOv5 将Focus 模块替换成了一个 6 x 6 的卷积层。两者的计算量是等价的,但是对于一些 GPU 设备,使用 6 x 6 的卷积会更加高效。
(2)CSP结构
YOLOv4网络结构中,借鉴了CSPNet的设计思路,在主干网络中设计了CSP结构。
YOLOv5与YOLOv4不同点在于,YOLOv4中只有主干网络使用了CSP结构。 而YOLOv5中设计了两种CSP结构,以YOLOv5s网络为例,CSP1_ X结构应用于Backbone主干网络,另一种CSP2_X结构则应用于Neck中。
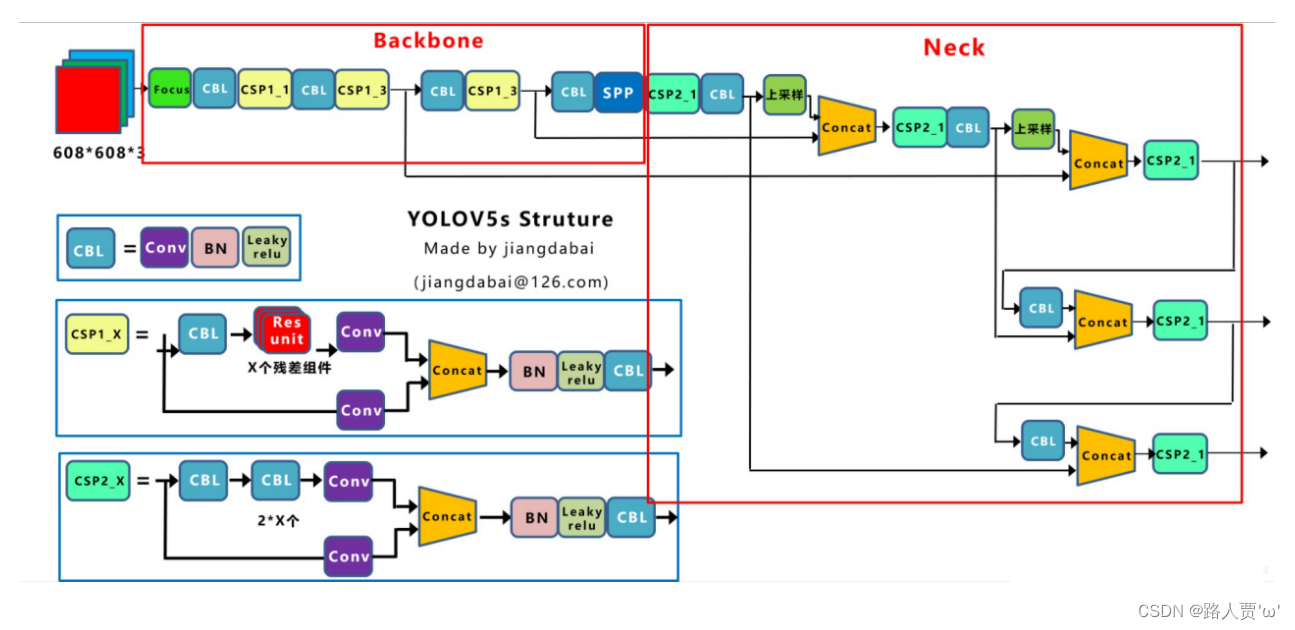
四、Neck
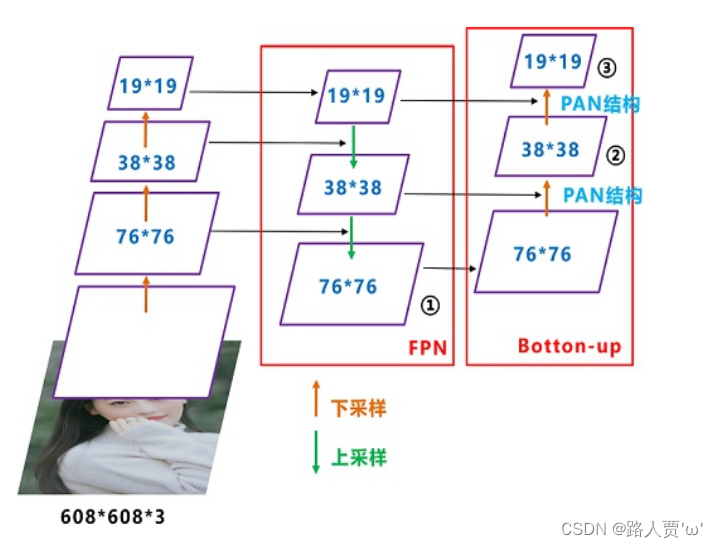
YOLOv5现在的Neck和YOLOv4中一样,都采用FPN+PAN的结构。但是在它的基础上做了一些改进操作:YOLOV4的Neck结构中,采用的都是普通的卷积操作,而YOLOV5的Neck中,采用CSPNet设计的CSP2结构,从而加强了网络特征融合能力。
结构如下图所示,FPN层自顶向下传达强语义特征,而PAN塔自底向上传达定位特征:
五、Head
(1)Bounding box损失函数
YOLO v5采用CIOU_LOSS 作为bounding box 的损失函数。(关于IOU_ Loss、GIOU_ Loss、DIOU_ Loss以及CIOU_Loss的介绍,请看YOLOv4那一篇:【YOLO系列】YOLOv4论文超详细解读2(网络详解))
(2)NMS非极大值抑制
NMS 的本质是搜索局部极大值,抑制非极大值元素。
非极大值抑制,主要就是用来抑制检测时冗余的框。因为在目标检测中,在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,所以我们需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。
算法流程:
1.对所有预测框的置信度降序排序
2.选出置信度最高的预测框,确认其为正确预测,并计算他与其他预测框的 IOU
3.根据步骤2中计算的 IOU 去除重叠度高的,IOU > threshold 阈值就直接删除
4.剩下的预测框返回第1步,直到没有剩下的为止
** SoftNMS:**
当两个目标靠的非常近时,置信度低的会被置信度高的框所抑制,那么当两个目标靠的十分近的时候就只会识别出一个 BBox。为了解决这个问题,可以使用 softNMS。
它的基本思想是用稍低一点的分数来代替原有的分数,而不是像 NMS 一样直接置零。

六、训练策略
(1)多尺度训练(Multi-scale training)。 如果网络的输入是416 x 416。那么训练的时候就会从 0.5 x 416 到 1.5 x 416 中任意取值,但所取的值都是32的整数倍。
(2)训练开始前使用 warmup 进行训练。 在模型预训练阶段,先使用较小的学习率训练一些epochs或者steps (如4个 epoch 或10000个 step),再修改为预先设置的学习率进行训练。
(3)使用了 cosine 学习率下降策略(Cosine LR scheduler)。
(4)采用了 EMA 更新权重(Exponential Moving Average)。 相当于训练时给参数赋予一个动量,这样更新起来就会更加平滑。
(5)使用了 amp 进行混合精度训练(Mixed precision)。 能够减少显存的占用并且加快训练速度,但是需要 GPU 支持。
总结一下,YOLO v5和前YOLO系列相比的改进:
- (1) 增加了正样本:方法是邻域的正样本anchor匹配策略。
- (2) 通过灵活的配置参数,可以得到不同复杂度的模型
- (3) 通过一些内置的超参优化策略,提升整体性能
- (4) 和yolov4一样,都用了mosaic增强,提升小物体检测性能

版权归原作者 路人贾'ω' 所有, 如有侵权,请联系我们删除。