
接着上篇文章继续写,本篇文章讲如何训练自己的数据集。
从官网下载YOLOv6源码:meituan/YOLOv6: YOLOv6: a single-stage object detection framework dedicated to industrial applications. (github.com)https://github.com/meituan/YOLOv6
一、创建文件
将tools文件夹中的train.py放主目录下,再创一个myself.yaml文件,名字可以自己起(主要是为了省事)
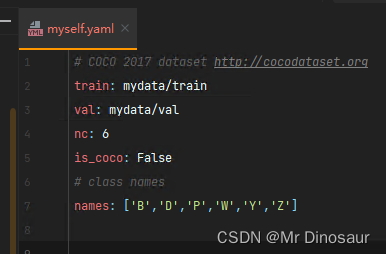
myself.yaml文件里只需要添加train和val路径就行
二、修改数据集格式
YOLOv6与YOLOv5的数据集格式不同,v6不需要使用images文件夹,将以前images中的train和val文件夹图片与labels文件放在同一个目录就可以了

三、程序修改
修改一下train.py中的路径
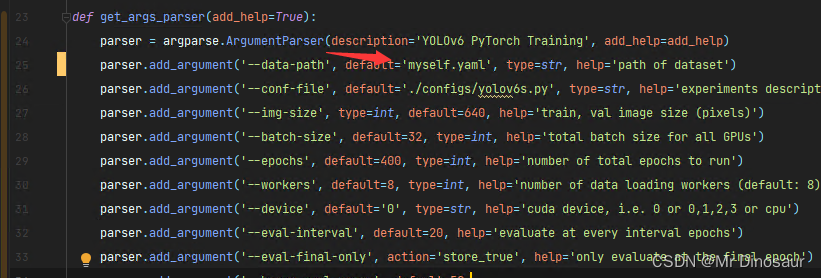
打开文件夹yolov6->data->datasets.py
将红框里的内容注释,改为蓝框(这里不知道官方什么时候能修复,哎)
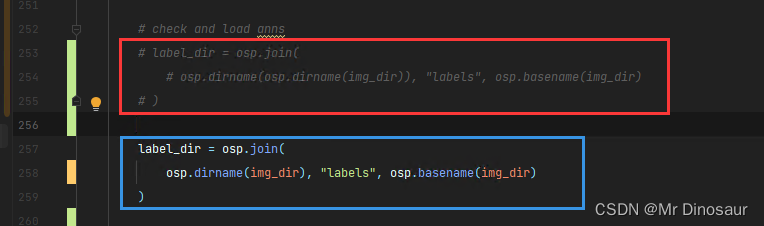
懒得动手直接复制下面的
label_dir = osp.join(
osp.dirname(img_dir), "labels", osp.basename(img_dir)
)
四、运行
直接右击运行train.py或者终端命令也可以
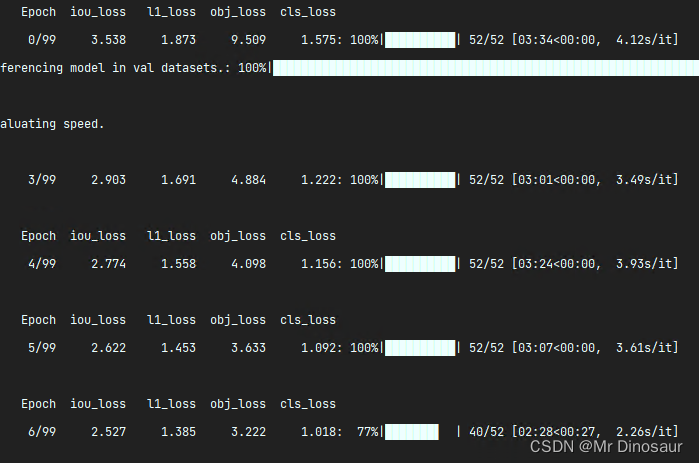
五、检测
上篇博文已经讲了如何检测自己的数据集,我看到最新版的程序bug依旧存在(时间6月30日)
由于训练的速度太慢,我只训了20epochs,检测效果较差,并且误检率和漏检都很高,之后还会再次更新


五、总结
对于YOLOv6我真是无力吐槽了,bug太多了,并且功能不够完善,各种报错,各种问题,简直就拿我们当小白鼠,哎!
bug1:
无法使用单类别数据集(在这个坑里差点没出来)
bug2:
训练时无法充分利用GPU(问题很致命,速度慢的我要裂开)
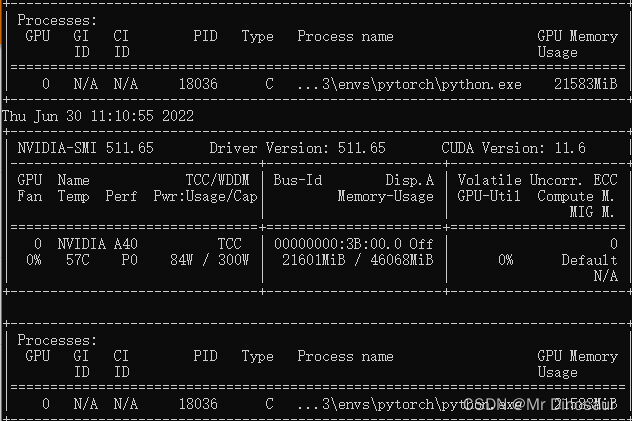
bug3:
每训练一个批次就自动新建一个文件夹(我感觉这是在逗我)

bug4:
目前无法查看精度和召回,map上涨速度特慢(等人家作者优化吧)
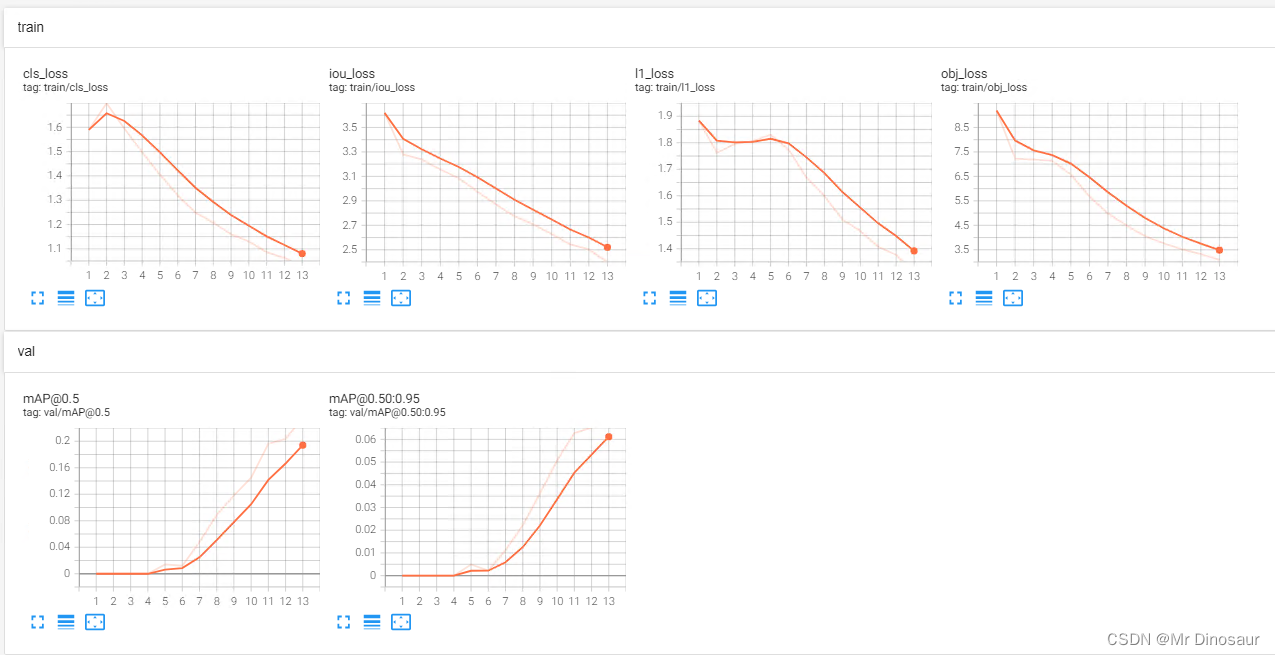
这些都还只是训练时候的bug......

如果训练时有各种报错欢迎评论区留言,本博文持续更新中
本文转载自: https://blog.csdn.net/qq_58355216/article/details/125525243
版权归原作者 Mr Dinosaur 所有, 如有侵权,请联系我们删除。
版权归原作者 Mr Dinosaur 所有, 如有侵权,请联系我们删除。