
数据仓库****理论
数据分层
1)数据明细层:DWD(Data Warehouse Detail):
该层一般保持和ODS层一样的数据粒度,并且提供一定的数据质量保证,同时为了提高数据明细层的易用性,该层会采用一些维度退化手法,将维度退化到事实表中,减少事实表和维度表的关联.另外在该层也会做一部分的数据聚合,将相同主题的数据汇集到一张表中,提高数据的可用性
2)数据中间层DWM(Data Warehouse Middle):
在DWD层的数据基础上,对数据做轻度的聚合操作,生成一系列的中间表提升公共指标的复用性,减少重复加工,直观来说,就是对通用的核心维度进行聚合操作,算出相应的统计指标
3)数据服务层:DWS(Data Warehouse Service)
又称为数据集市或者宽表,按照业务划分,例如流量,订单,用户等,生成字段比较多的宽表,用于后续的业务查询,OLAP分析,数据分析等
E T L
extract/transformation/load寻找数据,整合数据,并将它们装入数据仓库的过程。
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析的依据。
一.抽取
方法有三种:1.利用工具,例如datastage,informatic,OWB,DTS,SISS. 2,利用存储过程. 3,前两种工具结合.
抽取前的调研准备工作:1.弄清数据是从哪几个业务系统中来,各个业务系统的数据库服务器运行什么DBMS. 2.是否存在手工数据,手工数据量有多大。3.是否存在非结构化的数据。
二.清洗与转换
清洗
数据清洗的任务是过滤那些不符合要求的数据,将过滤的结果交给业务主管部门,确认是否过滤掉还是由业务单位修正之后再进行抽取。
清洗的数据种类: 1,不完整数据,2,错误数据,3重复的数据.
转换
1.不一致数据转换:编码转换(m,f;男女);字段转换(balance,bal);度量单位的转换(cm,m)
2.数据粒度的转换;业务系统数据存储非常明细的数据,而数据仓库中数据是用分析的,不需要非常明细,会将业务系统数据按照数据仓库粒度进行聚合.
3.商务规则的计算.不同企业有不同的业务规则,不同的数据指标,在ETL过程,将这些数据计算好之后存储在数据仓库中,供分析使用(比如KPI)
三.加载经过前两步处理后的数据可直接加载入数据仓库
用过什么ETL工具(informatica,ssis,owb,datastage),以及该工具简单讲述特点。
DataStage是一套专门对多种操作数据源的数据抽取、转换和维护过程进行简化和自动化,并将其输入数据集市或数据仓库目标数据库的集成工具。
它有四个组件:Administrator:用来管理project和环境变量。Manager:用于job,表定义,的引导,引出。Designer:用来设计job。Direct:用运查看job运行日志。
星形模型与雪花模型的区别?
1.星星的中心是一个大的事实表,发散出来的是维度表,每一个维度表用一个PK-FK连接到事实表,维度表之间彼此并不关联。一个事实表又包括一些度量值和维度。
2.雪花模型通过规范维度表来减少冗余度,也就是说,维度表数据已经被分组成一个个的表而不是使用一个大表。例如产品表被分成了产品大类和产品小类两个表。尽管这样做可以节省了空间,但是却增加了维度表的数量和关联的外键的个数。这就导致了更复杂的查询并降低了数据库的效率
维度建模(dimensional modeling):
是数据仓库建设中的一种数据建模方法。按照事实表,维表来构建数据仓库,数据集市。这种方法最被人广泛知晓的名字就是星型模式(Star-schema)。
什么叫查找表,为什么使用替代键?(其实目的和上面一样,从基础表到缓慢维度表的过程中的一种实现途径)
替代键(alternate key)可以是数据表内不作为主键的其他任何列,只要该键对该数据表唯一即可。换句话说,在唯一列内不允许出现数据重复的现象。
数据仓库项目最重要或需要注意的是什么,以及如何处理?
数据质量,主要是数据源数据质量分析,数据清洗转换,当然也可以定量分析
数据仓库有两个重要目的,一是数据集成,二是服务BI
数据准确性是数据仓库的基本要求,而效率是项目事实的前提,数据质量、运行效率和扩展性是数据仓库项目设计、实施高明与否的三大标志;
关系建模与维度建模
关系建模将复杂的数据抽象为两个概念——实体和关系,并使用规范化的方式表示出来。
关系模型严格遵循第三范式(3NF),数据冗余程度低,数据的一致性容易得到保证。由于数据分布于众多的表中,查询会相对复杂,在大数据的场景下,查询效率相对较低。
维度模型以数据分析作为出发点,不遵循三范式,故数据存在一定的冗余。维度模型面向业务,将业务用事实表和维度表呈现出来。表结构简单,故查询简单,查询效率较高。
拉链表:
什么是拉链表?
记录每条信息的生命周期,一旦一条记录的生命周期结束,就重新开始一条新的记录,并把当前日期放入生效开始日期。
拉链表适合于:数据会发生变化,但是变化频率并不高的维度(缓慢变化维)
如何使用拉链表?两种使用场景
- 获取全量最新的数据:结束日期=’9999-99-99’
- 获取全量历史数据:
通过生效开始日期<=某个日期 且 生效结束日期 >=某个日期 ,能够得到某个时间点的数据全量切片。
维度表和事实表
维度表:一般是对事实的描述信息。每一张维表对应现实世界中的一个对象或者概念。 例如:用户、商品、日期、地区等。
维表的特征:
Ø维表的范围很宽(具有多个属性、列比较多)
Ø跟事实表相比,行数相对较小:通常< 10万条
Ø内容相对固定:编码表
事实表中的每行数据代表一个业务事件(下单、支付、退款、评价等)。“事实”这个术语表示的是业务事件的度量值(可统计次数、个数、金额等)
每一个事实表的行包括:具有可加性的数值型的度量值、与维表相连接的外键,通常具有两个和两个以上的外键。
事实表的特征:
Ø非常的大
Ø内容相对的窄:列数较少(主要是外键id和度量值)
Ø经常发生变化,每天会新增加很多。
数据仓库中的维度和粒度
从时间的角度讲:简单说粒度就是事实表里测量值的测量‘频率’。比如说,销售库里的销售额,可以是一 天一个值,也可以是一个月一个值,甚至一年一个值,这就是相对于时间维度表的力度;可以是一个商品一个值,也可以是一类商品一个值,这就是相对于商品的粒度。
维度建模步骤:
选择业务过程→声明粒度→确认维度→确认事实
(1)选择业务过程
在业务系统中,挑选我们感兴趣的业务线,比如下单业务,支付业务,退款业务,物流业务,一条业务线对应一张事实表。
(2)声明粒度
数据粒度指数据仓库的数据中保存数据的细化程度或综合程度的级别。
声明粒度意味着精确定义事实表中的一行数据表示什么,应该尽可能选择最小粒度,以此来应各种各样的需求。
典型的粒度声明如下:
订单事实表中一行数据表示的是一个订单中的一个商品项。
支付事实表中一行数据表示的是一个支付记录。
(3)确定维度
维度的主要作用是描述业务是事实,主要表示的是“谁,何处,何时”等信息。
确定维度的原则是:后续需求中是否要分析相关维度的指标。例如,需要统计,什么时间下的订单多,哪个地区下的订单多,哪个用户下的订单多。需要确定的维度就包括:时间维度、地区维度、用户维度。
(4)确定事实
此处的“事实”一词,指的是业务中的度量值(次数、个数、件数、金额,可以进行累加),例如订单金额、下单次数等。
在DWD层,以业务过程为建模驱动,基于每个具体业务过程的特点,构建最细粒度的明细层事实表。事实表可做适当的宽表化处理。
事实表和维度表的关联比较灵活,但是为了应对更复杂的业务需求,可以将能关联上的表尽量关联上。
如何构建数据仓库?
1.系统分析,确定主题。通过与业务部门的交流,了解建立数仓要解决的问题,确认各个主题下的查询分析要求
2.选择满足数据仓库系统要求的软件平台。选择合适的软件平台,包括数据库、建模工具、分析工具等
3.建立数据仓库的逻辑模型。确定建立数据仓库逻辑模型的基本方法,基于主题视图,把主题视图中的数据定义转到逻辑数据模型中
4.逻辑数据模型转换为数据仓库数据模型
5.数据仓库数据模型优化。随着需求和数据量的变化进行调整
6.数据清洗转换和传输。业务系统中的数据加载到数据仓库之前,必须进行数据的清洗和转换,保证数据仓库中数据的一致性。
7.开发数据仓库的分析应用。满足业务部门对数据进行分析的需求。
8.数据仓库的管理。包括数据库管理和元数据管理。
Flink面试题
Flink的重启策略:
重启策略分为:固定延迟重启策略、故障率重启策略、无重启策略、后备重启策略。
1.固定延迟重启策略:
// 5表示最大重试次数为5次,10s为延迟时间
RestartStrategies.fixedDelayRestart(5,Time.of(10, TimeUnit.SECONDS))
2.故障率重启策略
// 3为最大失败次数;5min为测量的故障时间;10s为2次间的延迟时间
RestartStrategies.failureRateRestart(3,Time.of(5, TimeUnit.MINUTES),Time.of(10, TimeUnit.SECONDS))
3.无重启策略
RestartStrategies.noRestart()
- 后备(Fallback)重启策略
Flink集群规模
Flink 可以支持多少节点的集群规模?在回答这个问题时候,可以将自己生产环节中
的集群规模、节点、内存情况说明,同时说明部署模式(一般是 Flink on Yarn),除此之外,
用户也可以同时在小集群(少于 5 个节点)和拥有 TB 级别状态的上千个节点上运行 Flink
任务。
Flink 集群有哪些角色?各自有什么作用?
Flink 程序在运行时主要有 TaskManager,JobManager,Client 三种角色。
JobManager****:集群中的管理者 Master 的角色,是整个集群的协调者,负责接收 Flink Job,协调检查点,Failover 故障恢复等,同时管理 Flink 集群中从节点 TaskManager。
TaskManager****:实际负责执行计算的 Worker,在其上执行 Flink Job 的一组 Task,每个TaskManager 负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向 JobManager 汇报。
Client:Flink 程序提交的客户端,当用户提交一个 Flink 程序时,会首先创建一个 Client,该 Client 首先会对用户提交的 Flink 程序进行预处理,并提交到 Flink 集群中处理,所以 Client 需要从用户提交的 Flink 程序配置中获取 JobManager 的地址,并建立到 JobManager 的连接,将 Flink Job 提交给 JobManager。
TODO****说说 Flink 资源管理中 Task Slot 的概念
在Flink架构角色中我们提到,TaskManager是实际负责执行计算的Worker,TaskManager 是一个 JVM 进程,并会以独立的线程来执行一个 task 或多个 subtask。为了控制一个TaskManager 能接受多少个 task,Flink 提出了 Task Slot 的概念。简单的说,TaskManager会将自己节点上管理的资源分为不同的 Slot:固定大小的资源子集。这样就避免了不同 Job的 Task 互相竞争内存资源,但是需要主要的是,Slot 只会做内存的隔离。没有做 CPU 的隔离。
说说 Flink 的常用算子?
Flink 最常用的常用算子包括:Map:DataStream → DataStream,输入一个参数产生一个参数,map 的功能是对输入的参数进行转换操作。Filter:过滤掉指定条件的数据。KeyBy:按照指定的 key 进行分组。Reduce:用来进行结果汇总合并。Window:窗口函数,根据某些特性将每个 key 的数据进行分组(例如:在 5s 内到达的数据)
TODO****说说你知道的 Flink 分区策略?
分区策略是用来决定数据如何发送至下游。目前 Flink 支持了 8 中分区策略的实现。
GlobalPartitioner 数据会被分发到下游算子的第一个实例中进行处理。****ShufflePartitioner 数据会被随机分发到下游算子的每一个实例中进行处理。RebalancePartitioner 数据会被循环发送到下游的每一个实例中进行处理。RescalePartitioner 这种分区器会根据上下游算子的并行度,循环的方式输出到下游算子的每个实例。这里有点难以理解,假设上游并行度为 2,编号为 A 和 B。下游并行度为 4,编号为 1,2,3,4。那么 A 则把数据循环发送给 1 和 2,B 则把数据循环发送给 3 和 4。假设上游并行度为 4,编号为 A,B,C,D。下游并行度为 2,编号为 1,2。那么 A 和 B 则把数据发送给 1,C 和 D 则把数据发送给 2。BroadcastPartitioner 广播分区会将上游数据输出到下 游 算 子 的 每 个 实 例 中 。 适 合 于 大 数 据 集 和 小 数 据 集 做 Jion 的 场 景 。ForwardPartitioner ForwardPartitioner 用于将记录输出到下游本地的算子实例。它要求上下游算子并行度一样。简单的说, ForwardPartitioner 用 来 做 数 据 的 控 制 台 打 印 。KeyGroupStreamPartitioner Hash 分区器。会将数据按 Key 的 Hash 值输出到下游算子实例中。CustomPartitionerWrapper ****用户自定义分区器。需要用户自己实现 Partitioner 接口,来定义自己的分区逻辑。
Flink 的并行度了解吗?Flink 的并行度设置是怎样的?
Flink 中的任务被分为多个并行任务来执行,其中每个并行的实例处理一部分数据。这
些并行实例的数量被称为并行度。我们在实际生产环境中可以从四个不同层面设置并行度:
操作算子层面(Operator Level)
执行环境层面(Execution Environment Level)
客户端层面(Client Level)
系统层面(System Level)
需要注意的优先级:算子层面>环境层面>客户端层面>系统层面。
Flink 的 Slot 和 parallelism 有什么区别?
slot 是指 taskmanager 的并发执行能力,假设我们将 taskmanager.numberOfTaskSlots 配
置为3 那么每一个 taskmanager 中分配3个 TaskSlot, 3个 taskmanager 一共有9个TaskSlot。
parallelism 是指 taskmanager 实际使用的并发能力。假设我们把 parallelism.default 设置
为 1,那么 9 个 TaskSlot 只能用 1 个,有 8 个空闲。
说说 Flink 中的广播变量,使用时需要注意什么?
Broadcast是一份存储在TaskManager内存中的只读的缓存数据.
使用场景:在执行job的过程中需要反复使用的数据,为了达到数据共享,减少运行时内存消耗,我们就用广播变量进行广播。
注意点:
1、广播变量中封装的数据集大小要适宜,太大,容易造成OOM
2、广播变量中封装的数据要求能够序列化,否则不能在集群中进行传输
说说 Flink 中的状态存储?
Flink 在做计算的过程中经常需要存储中间状态,来避免数据丢失和状态恢复。选择的
状态存储策略不同,会影响状态持久化如何和 checkpoint 交互。Flink 提供了三种状态存储
方式:MemoryStateBackend、FsStateBackend、RocksDBStateBackend。
MemoryStateBackend:内存级的状态后端,会将键控状态作为内存中的对象进行管理,将它们存储在taskManager的JVM堆上,而将checkpoint存储在jobManager的内存中。
特点:快速,低延迟,不稳定
fsStateBackend:将checkpoint存到远程的持久化文件系统中,而对本地状态跟memoryStateBackend一样,也会存在TaskManager的JVM堆上。同时拥有内存级的本地访问速度和更好的容错保证。
RockDBStateBackend:将所有的状态序列化后,存入本地的RocksDB中。
TODO****Flink 是如何做到高效的数据交换的?
在一个 Flink Job 中,数据需要在不同的 task 中进行交换,整个数据交换是有TaskManager 负责的,TaskManager 的网络组件首先从缓冲 buffer 中收集 records,然后再发送。Records 并不是一个一个被发送的,二是积累一个批次再发送,batch 技术可以更加高效的利用网络资源。
Flink 是如何做容错的?
Flink 实现容错主要靠强大的 CheckPoint 机制和 State 机制。Checkpoint 负责定时制作
分布式快照、对程序中的状态进行备份;State 用来存储计算过程中的中间状态。
Checkpoint:
Flink会在输入的数据集上间隔性地生成barrier,通过栅栏将间隔时间短内的数据划分到相应的checkpoint中。当出现异常时,operator就能从上一次快照中恢复所有算子之前的状态,从而保证数据的一致性。
Flink 分布式快照的原理是什么?
Flink 的分布式快照是根据 Chandy-Lamport 算法量身定做的。简单来说就是持续创建分布式数据流及其状态的一致快照。核心思想是在 input source 端插入 barrier,控制 barrier 的同步来实现 snapshot 的备份和 exactly-once 语义。
TODO****Flink 是如何保证 Exactly-once 语义的?
Flink 通过实现两阶段提交和状态保存来实现端到端的一致性语义。分为以下几个步骤:
开始事务(beginTransaction)创建一个临时文件夹,来写把数据写入到这个文件夹里面
预提交(preCommit)将内存中缓存的数据写入文件并关闭
正式提交(commit)将之前写完的临时文件放入目标目录下。这代表着最终的数据会有
一些延迟
丢弃(abort)丢弃临时文件
若失败发生在预提交成功后,正式提交前。可以根据状态来提交预提交的数据,也可删
除预提交的数据。
说说 Flink 的内存管理是如何做的?
Flink 并不是将大量对象存在堆上,而是将对象都序列化到一个预分配的内存块上。此外,Flink 大量的使用了堆外内存。如果需要处理的数据超出了内存限制,则会将部分数据存储到硬盘上。Flink 为了直接操作二进制数据实现了自己的序列化框架。
理论上 Flink 的内存管理分为三部分:
Network Buffers:这个是在 TaskManager 启动的时候分配的,这是一组用于缓存网络数据的内存,每个块是32K,默认分配2048个,可以通过“taskmanager.network.numberOfBuffers”修改。
Memory Manage pool:大量的 Memory Segment 块,用于运行时的算法(Sort/Join/Shuffle
等),这部分启动的时候就会分配。内存的分配支持预分配和 lazy load,默认懒加载的方式。
User Code,这部分是除了 Memory Manager 之外的内存用于 User code 和 TaskManager
本身的数据结构。
说说 Flink 的序列化如何做的?
Java 本身自带的序列化和反序列化的功能,但是辅助信息占用空间比较大,在序列化对象时记录了过多的类信息。Apache Flink 摒弃了 Java 原生的序列化方法,以独特的方式处理数据类型和序列化,包含自己的类型描述符,泛型类型提取和类型序列化框架。TypeInformation 是所有类型描述符的基类。它揭示了该类型的一些基本属性,并且可以生成序列化器。TypeInformation 支持以下几种类型:
BasicTypeInfo: 任意 Java 基本类型或 String 类型
BasicArrayTypeInfo: 任意 Java 基本类型数组或 String 数组
WritableTypeInfo: 任意 Hadoop Writable 接口的实现类
TupleTypeInfo: 任意的 Flink Tuple 类型(支持 Tuple1 to Tuple25)。Flink tuples 是固定长度固定类型的 Java Tuple 实现
CaseClassTypeInfo: 任意的 Scala CaseClass(包括 Scala tuples)
PojoTypeInfo: 任意的 POJO (Java or Scala),例如,Java 对象的所有成员变量,要么是
public 修饰符定义,要么有 getter/setter 方法
GenericTypeInfo: 任意无法匹配之前几种类型的类
针对前六种类型数据集,Flink 皆可以自动生成对应的 TypeSerializer,能非常高效地对
数据集进行序列化和反序列化。
Flink 中的 Window 出现了数据倾斜,你有什么解决办法?
window 产生数据倾斜指的是数据在不同的窗口内堆积的数据量相差过多。本质上产生这种情况的原因是数据源头发送的数据量速度不同导致的。
出现这种情况一般通过两种方式来解决:
在数据进入窗口前做预聚合
重新设计窗口聚合的 key
Flink 中在使用聚合函数 GroupBy、Distinct、KeyBy 等函数时出现数据热点该如何解决?
数据倾斜和数据热点是所有大数据框架绕不过去的问题。处理这类问题主要从 3 个方
面入手:
1.在业务上规避这类问题
例如一个假设订单场景,北京和上海两个城市订单量增长几十倍,其余城市的数据量不变。这时候我们在进行聚合的时候,北京和上海就会出现数据堆积,我们可以单独数据北京和上海的数据。
2.Key 的设计上
把热 key 进行拆分,比如上个例子中的北京和上海,可以把北京和上海按照地区进行拆分聚合。
3.参数设置
Flink 1.9.0 SQL(Blink Planner) 性能优化中一项重要的改进就是升级了微批模型,即MiniBatch。原理是缓存一定的数据后再触发处理,以减少对 State 的访问,从而提升吞吐和减少数据的输出量。
Flink 任务延迟高,想解决这个问题,你会如何入手?
在 Flink 的后台任务管理中,我们可以看到 Flink 的哪个算子和 task 出现了反压。最主要的手段是资源调优和算子调优。资源调优即是对作业中的 Operator 的并发数(parallelism)、CPU(core)、堆内存(heap_memory)等参数进行调优。作业参数调优包括:并行度的设置,State 的设置,checkpoint 的设置。
Flink的状态机制?
Flink中的状态:算子状态,键控状态,状态后端
由一个任务维护,并且用来计算某个结果的所有数据都属于这个任务的状态。
可以认为状态就是一个本地变量,可以被任务的业务逻辑访问。
Flink会进行状态管理,包括状态一致性、故障处理以及高效存储和访问,以便开发人员可以专注应用程序的逻辑。
在Flink中,状态始终与特定的算子相关联,为了使运行时的Flink了解算子的状态,算子需要预先注册其状态。
算子状态:作用范围限定为算子任务,由同一并行任务所处理的所有数据都可以访问到相同的状态。状态堆同一子任务而言是共享的。算子状态不能由相同或不同算子的另一个子任务访问。
算子状态数据结构:列表状态,联合列表状态,广播状态
键控状态:根据输入数据流中定义的键key来维护和访问的。Flink为每个key维护一个状态实例,并将具有相同键的所有数据,都分区到同一个算子任务中,这个任务会维护和处理这个key对应的状态。当任务处理一条数据时,它会自动将状态的访问范围限定为当前数据的key。
键控状态数据结构:值状态(Value state),列表状态(List state),映射状态(Map state),聚合状态(Reducing state&Aggregating state)。
容错和checkpoint机制?
State的容错需要依靠checkpoint机制,这样才可以保证Exactly-once语义。
生成快照:Flink通过checkpoint机制可以实现对source中的数据和task中的state数据进行存储。
恢复快照:Flink还可以通过restore机制来恢复之前的checkpoint快照中保存的source数据和task中的state数据。
Checkpoint:为了保证state的容错性,Flink需要对state进行checkpoint。Checkpoint是Flink实现容错机制的核心功能,它能够根据配置周期性地基于stream中各个operator/task的状态来生成快照,从而将这些状态数据定期持久化存储下来。
Checkpoint机制可以与stream和state持久化存储交互的前提:
- 需要有持久化的source,它需要支持在一定时间内重放事件,这种source的典型例子就是持久化的消息队列或文件系统。2.需要有用于state的持久化存储介质,比如分布式文件系统。代码:env.enableCheckpointing(1000);
Windows的触发条件?
- watermark>=window_end_time
- 在[window_start_time,window_end_time]中有数据存在
对于乱序数据和迟到数据Flink是怎么处理的?
Watermark和window处理乱序数据。
迟到数据处理方案:
- 丢弃
- AllowedLaterness指定允许数据延迟的时间
- 利用侧输出流:sideOutputLateData收集延迟数据
定义侧输出流标签new OutputTag
调用算子.sideOutputLateData(outputTag);将侧输出流标签传入
最后可以获取侧输出流getSideOutput(outputTag);
watermark 机制?
Watermark本质上是一种时间戳。一般来讲Watermark经常和Window一起被用来处理乱序事件。数据流中的 Watermark 用于表示 timestamp 小于 Watermark 的数据, 都已经到达了,因此,window 的执行也是由 Watermark 触发的。
watermark的特点:
watermark 是一条特殊的数据记录;
watermark 必须单调递增,以确保任务的事件时间时钟在向前推进,而不是在后退; watermark 与数据的时间戳相关。
watermark 的引入:
调用assignTimestampAndWatermarks 方法,传入一个 BoundedOutOfOrdernessTimestampExtractor,就可以指定 :

对于排好序的数据,不需要延迟触发,可以只指定时间戳就行了:

Window的类型?
时间窗口:
滚动时间窗口:.timeWindow(Time.seconds(15));
滑动时间窗口:.timeWindow(Time.seconds(15),Time.seconds(5));
会话窗口:.window(EventTimeSessionWindows.withGap(Time.seconds(60)));
计数窗口:
滚动计数窗口:.countWindow(10);
滑动计数窗口:.countWindow(10,2);
Flink中在使用聚合函数 GroupBy、Distinct、KeyBy 等函数时出现数据热点该如何解决?
数据倾斜和数据热点是所有大数据框架绕不过去的问题。处理这类问题主要从3个方面入手:
在业务上规避这类问题
例如一个假设订单场景,北京和上海两个城市订单量增长几十倍,其余城市的数据量不变。这时候我们在进行聚合的时候,北京和上海就会出现数据堆积,我们可以单独数据北京和上海的数据。
Key的设计上
把热key进行拆分,比如上个例子中的北京和上海,可以把北京和上海按照地区进行拆分聚合。
参数设置
Flink 1.9.0 SQL(Blink Planner) 性能优化中一项重要的改进就是升级了微批模型,即 MiniBatch。原理是缓存一定的数据后再触发处理,以减少对State的访问,从而提升吞吐和减少数据的输出量。
公司怎么提交的实时任务?有多少个jobmanager?
我们使用 yarn session 模式提交任务。每次提交都会创建一个新的
Flink 集群,为每一个 job 提供一个 yarn-session,任务之间互相独立,互不影响,
方便管理。任务执行完成之后创建的集群也会消失。线上命令脚本如下:
bin/yarn-session.sh -n 7 -s 8 -jm 3072 -tm 32768 -qu root.. -nm - -d
其中申请 7 个 taskManager,每个 8 核,每个 taskmanager 有 32768M 内存。
我们公司一般配置一个主 Job Manager,两个备用 Job Manager,然后结合
ZooKeeper 的使用,来达到高可用。
Flink的时间语义?
EventTime:实际应用最常见的时间语义,是事件创建的时间。
IngestionTime:数据进入Flink的时间。
ProcessingTime:是每一个执行基于时间的操作的算子的本地系统时间。默认的时间。没有事件时间的情况下,或者对实时性要求超高的情况下使用。
窗口函数?
增量聚合函数(incremental aggregation functions)
• 每条数据到来就进行计算,保持一个简单的状态
• ReduceFunction, AggregateFunction
➢ 全窗口函数(full window functions)
• 先把窗口所有数据收集起来,等到计算的时候会遍历所有数据
• ProcessWindowFunction,WindowFunction
Flink的执行图?
Flink 中的执行图可以分成四层:StreamGraph -> JobGraph ->
ExecutionGraph -> 物理执行图
➢ StreamGraph:是根据用户通过 Stream API 编写的代码生成的最初的图。用来
表示程序的拓扑结构。
➢ JobGraph:StreamGraph经过优化后生成了 JobGraph,提交给 JobManager
的数据结构。主要的优化为,将多个符合条件的节点 chain 在一起作为一个节点
➢ ExecutionGraph:JobManager 根据 JobGraph 生成ExecutionGraph。
ExecutionGraph是JobGraph的并行化版本,是调度层最核心的数据结构。
➢ 物理执行图:JobManager 根据 ExecutionGraph 对 Job 进行调度后,在各个
TaskManager 上部署 Task 后形成的“图”,并不是一个具体的数据结构。
Flink 的反压和 Strom 有哪些不同?
Storm 是通过监控 Bolt 中的接收队列负载情况,如果超过高水位值就会将反压信息写到 Zookeeper ,Zookeeper 上的 watch 会通知该拓扑的所有 Worker 都进入反压状态,最后 Spout 停止发送 tuple。Flink 中的反压使用了高效有界的分布式阻塞队列,下游消费变慢会导致发送端阻塞。二者最大的区别是 Flink 是逐级反压,而 Storm 是直接从源头降速。
TODO****Flink如何定位反压?
先看指标,定位问题?
再看资源,是否足够?
三看吞吐,是否反压?
四看JVM,是否OOM?
指标:
1.首先先禁用算子链,方便定位
2.通过WebUI的back pressure:Flink通过在TaskManager中采样LocalBufferPool内存块上的每个task的stackTrace实现。
3.通过指标metric:
第一个指标是否反压,isBackPressued
第二个指标是输入缓冲区的使用率:Shuffle.Netty.input.Buffers.inPoolUsage如果输入是1,输出不是1,就是造成反压的算子
资源:
一般会在这些位置出现的反压问题:
Operator的并发数(parallelism)不合理
CPU(core)不合理
堆内存(heap_memory)等参数设置不合理
并行度的设置不合理
State的设置不合理
checkpoint的设置不合理
吞吐:
1.Flink 内部是基于 producer-consumer 模型来进行消息传递的,Flink的反压设计也是基于这个模型。Flink 使用了高效有界的分布式阻塞队列,就像 Java 通用的阻塞队列(BlockingQueue)一样。下游消费者消费变慢,上游就会受到阻塞。
2.如果反压是由于数据倾斜造成的,这点我们可以通过 Web UI 各个 SubTask 的 Records Sent 和 Record Received 来确认,另外 Checkpoint detail 里不同 SubTask 的 State size 也是一个分析数据倾斜的有用指标。解决方式把数据分组的 key 进行本地/预聚合来消除/减少数据倾斜。
JVM,OOM:
用户代码的执行效率问题(频繁被阻塞或者性能问题)和TaskManager 的内存以及 GC 问题。
TaskManager JVM 各区内存不合理导致的频繁 Full GC 甚至失联。可以加上 -XX:+PrintGCDetails 来打印 GC 日志的方式来观察 GC 的问题。推荐TaskManager 启用 G1 垃圾回收器来优化 GC。
Checkpoint和Savepoint对比:
概念:Checkpoint 是 自动容错机制 ,Savepoint 程序全局状态镜像 。
目的: Checkpoint 是程序自动容错,快速恢复 。Savepoint是 程序修改后继续从状态恢复,程序升级等。
用户交互:Checkpoint 是 Flink 系统行为 。Savepoint是用户触发。
状态文件保留策略:Checkpoint默认程序删除,可以设置CheckpointConfig中的参数进行保留 。Savepoint会一直保存,除非用户删除 。
Savepoint机制?
Savepoint是检查点的一种特殊实现,底层其实就是checkpoint的机制。Savepoint是用户以手工命令的方式触发的,并将结果持久化到指定的存储路径中,目的是用户在升级和维护集群过程中保存系统中的状态数据。
Savepoint操作:(1.2版本后也可以通过Flink的web页面从savepoint中恢复应用)
1.手动触发savepoint
命令中指定jobId和savepoint的存储路径及YarnAppId
bin/flink savepoint :jobId [:targetDirectory] -yid :yarnAppId
2.取消任务并触发savepoint
bin/flink -cancel -s [:targetDirectory] : jobId
3.通过从savepoints中恢复任务
bin/flink run -s :savepointPath [:runArgs]
4.释放savepoints数据
bin/flink savepoint -d :savepointPath
通过--dispose(-d)命令释放已经存储的savepoint数据,这样存储在指定路径中的savepointPath将会被清除掉。
Flink调优
1.资源配置调优
--内存设置:
jobmanager.memory.process.size=2048mb \ JM2~4G足够
-Dtaskmanager.memory.process.size=6144mb \ 单个TM2~8G足够
-Dtaskmanager.numberOfTaskSlots=2 \ 与容器核数1core:1slot或1core:2slot 一拖1,一拖2
Flink是实时流处理,关键在于资源情况能不能抗住高峰时期每秒的数据量,通常用QPS,TPS来描述数据情况。
QPS:每秒钟的查询量
TPS:每秒钟的请求量
--并行度设置:
开发完成后,先进行压测。任务并行度给10以下,测试单个并行度的处理上限。然后 总QPS/单并行度的处理能力 = 并行度,再乘以1.2倍
--source端并行度设置:
数据源端是kafka的话,source的并行度设置为kafka对应的topic的分区数
--Transform端并行度的配置
keyby之前,并行度可以和source保持一致。
ØKeyby之后的算子,如果并发较大,建议设置并行度为 2 的整数次幂
--Sink 端并行度的配置
Source 端的数据量是最小的,拿到 Source 端流过来的数据后做了细粒度的拆分,调大sink端的并行度
如果Sink端是Kafka,可以设为Kafka对应Topic的分区数。
--RocksDB大状态调优:
--状态后端:存储本地状态,备份状态(checkpoint)
1.内存 本地 在TM上,checkpoint 在JM
2.FS 本地 在TM上,checkpoint在HDFS
3.RocksDB 本地在RocksDB,checkpoint在HDFS
Taskmanager挂掉排查思路?
一般出现TM挂掉由于内存问题oom(java heap space)导致。
Taskmanger内存问题导致频繁fgc影响心跳发送或者fgc时间过长进程退出等。可以到ssmp查看对应时间点的TaskManager的内存使用和fgc情况。
解决方法:
方法1:在ssmp任务页面调大taskmanger内存大小
方法2:分析内存占用情况,优化代码逻辑。(如state过大,本地缓存过大)
两阶段聚合解决 KeyBy 热点****?
首先把分组的 key 打散,比如加随机后缀;
对打散后的数据进行聚合;
把打散的 key 还原为真正的 key;
二次 KeyBy 进行结果统计,然后输出。
Hive面试题
TODO****hive如何优化?
(join 优化,尽量将小表放在 join 的左边,如果一个表很小可以采用 mapjoin。
排序优化,order by 一个 reduce 效率低,distirbute by +sort by 也可以实现全局排序。
使用分区,查询时可减少数据的检索,从而节省时间。)
hive建表优化:
分区
动态分区
分桶:
clustered by(id)
into 4 buckets
分桶规则:对分桶字段的值进行哈希,然后除以桶的个数求余觉得该条记录放哪个桶
应用场景:抽样查询,语法:tablesimple(bucket 1 out 4 on id)
选择合适的文件格式:行存储:textfile,sequencefile,
列存储:orc,parquent,
选择合适的压缩格式:LZO,snappy ,(gzip,bzip2...)
HQL语法优化:
1.列裁剪和分区裁剪
2.group by:map端相同的key发往一个reduce,某一key数据过多就会出现数据倾斜。
数据倾斜:1.开启map端聚合:set hive.map.aggr=true;
2.在数据倾斜的时候进行负载均衡:set hive.groupby.skewindata=true;
3.开启矢量计算:在计算类似scan,filter,aggregation的时候,开启vectorization技术以设置批 处理的增量大小为1024行单次来达到比单条记录单次获得更高的效率。
set hive.vectorized.execution.enabled=true;
set hive.vectorized.execution.reduce.enabled=true;
4.left semi join 代替in/exists
5.谓词下推,默认是开启的,不做操作。set hive.optimize.ppd=true;
将sql语句中的where谓词逻辑都尽可能提前执行,减少下游处理的数据量。
6.开启mapjoin:
set hive.auto.convert.join=true;把小表全部加载到内存在map端进行join,避免reducer处理。
7.大表join大表时,创建分桶表并开启桶join:
创建分桶表:
clustered by(id)
sorted by(id)
into 6 buckets
开启桶join:
set hive.optimize.bucketmapjoin=true;
set hive.optimize.bucketmapjoin.sortedmerge=true;
set hive.input.format=org.apache.hadoop.hive.ql.io.BucketizedHiveInputFormat;
8.避免笛卡儿积:设定严格模式:set mapred.mode=strict;
其他优化:
9.开启mapjoin,set hive.auto.convert.join=true(默认为true)
把小表全部加载到内存在 map 端进行 join,避免 reducer 处理。
- 小文件合并
在 Map 执行前合并小文件,减少 Map 数。CombineHiveInputFormat 具有对小文件进行合并的功能(系统默认的格式)
// 输出合并小文件
SET hive.merge.mapfiles = true; -- 默认 true,在 map-only 任务结束时合并小文件
SET hive.merge.mapredfiles = true; -- 默认 false,在 map-reduce 任务结束时合并小文件
SET hive.merge.size.per.task = 268435456; -- 默认 256M
SET hive.merge.smallfiles.avgsize = 16777216; -- 当输出文件的平均大小小于 16m 该值时,启动一个独立的 map-reduce 任务进行文件 merge
小文件问题的解决方案:
从小文件产生的途径就可以从源头上控制小文件数量,方法如下:
使用Sequencefile作为表存储格式,不要用textfile,在一定程度上可以减少小文件;
减少reduce的数量(可以使用参数进行控制);
少用动态分区,用时记得按distribute by分区;
对于已有的小文件,我们可以通过以下几种方案解决:
使用hadoop archive命令把小文件进行归档;
重建表,建表时减少reduce数量;
通过参数进行调节,设置map/reduce端的相关参数
- 开启map端combiner(不影响最终业务逻辑)
set hive.map.aggr=true;
TODO****Hive的数据倾斜问题:
倾斜原因:
key分布不均
业务数据本身的特性
sql语句造成数据倾斜
1)group by
注:group by 优于 distinct group
情形:group by 维度过小,某值的数量过多
后果:处理某值的 reduce 非常耗时
解决方式:采用 sum() group by 的方式来替换 count(distinct)完成计算。
2)count(distinct)
count(distinct xx)
情形:某特殊值过多
后果:处理此特殊值的 reduce 耗时;只有一个 reduce 任务
解决方式:count distinct 时,将值为空的情况单独处理,比如可以直接过滤空值的行,
在最后结果中加 1。如果还有其他计算,需要进行 group by,可以先将值为空的记录单独处
理,再和其他计算结果进行 union。
3.开启MapJoin参数设置
set hive.auto.convert.join=true(默认为true)
可以用MapJoin把小表全部加载到内存在map端进行join
4.不同的数据类型关联产生数据倾斜
情形:比如用户表中 user_id 字段为 int,log 表中 user_id 字段既有 string 类型也有 int 类
型。当按照 user_id 进行两个表的 Join 操作时。
后果:处理此特殊值的 reduce 耗时;只有一个 reduce 任务
默认的 Hash 操作会按 int 型的 id 来进行分配,这样会导致所有 string 类型 id 的记录都分配
到一个 Reducer 中。
解决方式:把数字类型转换成字符串类型
select * from users a
left outer join logs b
on a.usr_id =**** cast(b.user_id as string)****
5.开启数据倾斜时负载均衡
set hive.groupby.skewindata=true;
思想:就是先随机分发并处理,再按照 key group by 来分发处理。
6.控制空值分布
将为空的 key 转变为字符串加随机数或纯随机数,将因空值而造成倾斜的数据分发到多个 Reducer。
注:对于异常值如果不需要的话,最好是提前在 where 条件里过滤掉,这样可以使计算量大大减少。
可以使用 case when 对空值赋上随机值。此方法比直接写 is not null 更好,因为case when 的 job 数为 1,is not null的job数为 2.
解决方案:
1)参数调节:
①开启 Map 端聚合参数设置
hive.map.aggr=true
当选项设定为true,生成的查询计划会有两个MR Job.相同的 Group By Key 有可能被分发到不同的 Reduce 中,从而达到负载均衡的目的;
②开启MapJoin参数设置
s****et hive.auto.convert.join=true(默认为true)
可以用MapJoin把小表全部加载到内存在map端进行join
2)SQL调节
(1)小表join大表
(2)大表join大表
空key过滤:… where id is not null
空key转换:空 key 赋一个随机值,
(3)选用join key 分布最均匀的表作为驱动表。
(4) count distinct大量相同特殊值:count distinct时,将值为空的情况单独处理。若还有其他计算,需要进行group by,可以先将值为空的记录单独处理,再和其他计算结果进行union.
答案二:
1.单表数据倾斜优化:
当任务中存在 GroupBy 操作同时聚合函数为 count 或者 sum 可以设置参数来处理数据
倾斜问题。
是否在 Map 端进行聚合,默认为 True set hive.map.aggr = true;
在 Map 端进行聚合操作的条目数目 set hive.groupby.mapaggr.checkinterval = 100000;
****有数据倾斜的时候进行负载均衡(默认是 false) set hive.groupby.skewindata = true; ****
增加 Reduce 数量(多个 Key 同时导致数据倾斜):默认是 256MB
Join 数据倾斜优化
join 的键对应的记录条数超过这个值则会进行分拆,值根据具体数据量设置
set hive.skewjoin.key=100000;
如果是 join 过程出现倾斜应该设置为 true
set hive.optimize.skewjoin=false;
如果开启了,在 Join 过程中 Hive 会将计数超过阈值 hive.skewjoin.key(默认 100000)的
倾斜 key 对应的行临时写进文件中,然后再启动另一个 job 做 map join 生成结果。通过
hive.skewjoin.mapjoin.map.tasks 参数还可以控制第二个 job 的 mapper 数量,默认 10000。 set hive.skewjoin.mapjoin.map.tasks=10000;
hive、hbase的小文件如何处理?
小文件是如何产生的?
动态分区插入数据,产生大量的小文件,从而导致map数量剧增。
reduce数量越多,小文件也越多。
数据源本身就包含大量的小文件。
小文件问题的影响:
从Hive的角度看,小文件会开很多map,一个map开一个JVM去执行,所以这些任务的初始化,启动,执行会浪费大量的资源,严重影响性能。
在HDFS中,每个小文件对象约占150byte,如果小文件过多会占用大量内存。这样NameNode内存容量严重制约了集群的扩展。
小文件问题的解决方案:
从小文件产生的途径就可以从源头上控制小文件数量,方法如下:
使用Sequencefile作为表存储格式,不要用textfile,在一定程度上可以减少小文件;
减少reduce的数量(可以使用参数进行控制);
少用动态分区,用时记得按distribute by分区;
对于已有的小文件,我们可以通过以下几种方案解决:
使用hadoop archive命令把小文件进行归档;
重建表,建表时减少reduce数量;
通过参数进行调节,设置map/reduce端的相关参数
hive 内部表和外部表的区别?
未被external修饰的是内部表(managed table),被external修饰的为外部表(external table);
内部表数据由Hive自身管理,外部表数据由HDFS管理;
内部表数据存储的位置是hive.metastore.warehouse.dir(默认:/user/hive/warehouse),外部表数据的存储位置由自己制定(如果没有LOCATION,Hive将在HDFS上的/user/hive/warehouse文件夹下以外部表的表名创建一个文件夹,并将属于这个表的数据存放在这里);
删除内部表会直接删除元数据(metadata)及存储数据;删除外部表仅仅会删除元数据,HDFS上的文件并不会被删除;
对内部表的修改会将修改直接同步给元数据,而对外部表的表结构和分区进行修改,则需要修复(MSCK REPAIR TABLE table_name;)
修改外部表想要生效,需要先把外部表转内部表,然后修改,再转外部表。
hive 是如何实现分区的?
建表语句:
create table tablename (id) partitioned by (dt string)
增加分区:
alter table tablenname add partition (dt = ‘2016-03-06’)
删除分区:
alter table tablename drop partition (dt = ‘2016-03-06’)
hive有哪些方式保存元数据?
存储于 derby数据库,此方法只能开启一个hive客户端,不推荐使用
存储于mysql数据库中,可以多客户端连接,推荐使用
hive 中的压缩格式 RCFile、 TextFile、 SequenceFile 各有什么区别?
TextFile:默认格式,数据不做压缩,磁盘开销大,数据解析开销大
SequenceFile:Hadoop API提供的一种二进制文件支持,使用方便,可分割,可压缩,支持三种压缩,NONE,RECORD,BLOCK。
RCFILE:是一种行列存储相结合的方式。首先,将数据按行分块,保证同一个 record 在同一个块上,避免读一个记录读取多个block。其次,块数据列式存储,有利于数据压缩和快速的列存取。数据加载的时候性能消耗大,但具有较好的压缩比和查询响应
row_number(),rank(),dense_rank()区别?
ROW_NUMBER()函数作用就是将select查询到的数据进行排序,每一条数据加一个序号,他不能用做于学生成绩的排名,一般多用于分页查询。
RANK()函数,顾名思义排名函数,可以对某一个字段进行排名,这里为什么和ROW_NUMBER()不一样那,ROW_NUMBER()是排序,当存在相同成绩的学生时,ROW_NUMBER()会依次进行排序,他们序号不相同,而Rank()则不一样出现相同的,他们的排名是一样的。
DENSE_RANK()函数也是排名函数,和RANK()功能相似,也是对字段进行排名。
hive的开窗函数有哪些?
开窗函数一般用于数据分析,计算基于组的某种聚合值。
跟聚合函数的区别在于:对于每个组返回多行,而聚合函数对于每个组只返回一行。
开窗函数指定了分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变化而变化!
基础结构:分析函数(如:sum(),max(),row_number()...) + 窗口子句(over函数)
例如:sum() over(partition by user_id order by order_time desc)
over函数写法: over(partition by cookieid order by createtime) 先根据cookieid字段分区,相同的cookieid分为一区,每个分区内根据createtime字段排序(默认升序)
注:不加 partition by 的话则把整个数据集当作一个分区,不加 order by的话会对某些函数统计结果产生影响,如sum()
分析函数有:avg(),min(),max(),sum()
排序函数:row_number(), rank(), dense_rank()
Over函数?
OVER():指定分析函数工作的数据窗口大小,这个数据窗口大小可能会随着行的变而变化。
CURRENT ROW:当前行
n PRECEDING:往前 n 行数据
n FOLLOWING:往后 n 行数据
UNBOUNDED:起点,
UNBOUNDED PRECEDING 表示从前面的起点,
UNBOUNDED FOLLOWING 表示到后面的终点
LAG(col,n,default_val):往前第 n 行数据
LEAD(col,n, default_val):往后第 n 行数据
NTILE(n):把有序窗口的行分发到指定数据的组中,各个组有编号,编号从 1 开始,对
于每一行,NTILE 返回此行所属的组的编号。注意:n 必须为 int 类型。
自定义过的udf函数,简述定义步骤
1.extends UDF,实现evaluate()
2.add JAR /home/hadoop/hivejar/udf.jar;
3.create temporary function tolowercase as 'com.ghgj.hive.udf.ToLowerCase';
4.使用
5.drop temporary function tolowercase;
自定义函数分类?
(1)UDF(User-Defined-Function)
一进一出
(2)UDAF(User-Defined Aggregation Function)
聚集函数,多进一出
类似于:count/max/min
(3)UDTF(User-Defined Table-Generating Functions)
一进多出
如 lateral view explode()
Hive 分区表与分桶表区别
分区在HDFS上的表现形式是一个目录, 分桶是一个单独的文件
分区: 细化数据管理,直接读对应目录,缩小mapreduce程序要扫描的数据量
分桶:1、提高join查询的效率(用分桶字段做连接字段)2、提高采样的效率
Hive导入数据的五种方式
- Load方式,可以从本地或HDFS上导入,本地是copy,HDFS是移动
本地:load data local inpath ‘/root/student.txt’ into table student;
HDFS:load data inpath ‘/user/hive/data/student.txt’ into table student;
- Insert方式,往表里插入
insert into table student values(1,’zhanshan’);
- As select方式,根据查询结果创建表并插入数据
create table if not exists stu1 as select id,name from student;
- Location方式,创建表并指定数据的路径
create external if not exists stu2 like student location '/user/hive/warehouse/student/student.txt';
- Import方式,先从hive上使用export导出在导入
import table stu3 from ‘/user/export/student’;
Hive导出数据的五种方式
- Insert方式,查询结果导出到本地或HDFS
Insert overwrite local directory ‘/root/insert/student’ select id,name from student;
Insert overwrite directory ‘/user/ insert /student’ select id,name from student;
- Hadoop命令导出本地
hive>dfs -get /user/hive/warehouse/student/ 000000_0 /root/hadoop/student.txt
- hive Shell命令导出
]$ bin/hive -e ‘select id,name from student;’ > /root/hadoop/student.txt
- Export导出到HDFS
hive> export table student to ‘/user/export/student’;
- Sqoop导出
Order By,Sort By,Distrbute By,Cluster By的区别
Order By(全局排序)
Order by 会对输入做全局排序,因此只有一个reduce,所以当输入的数据规模较大时,会导致计算的时间较长。在Hive严格模式下,使用order by必须指定limit
Sort By(每个MapReduce排序)
sort by并不是全局排序,其在数据进入reducer前完成排序, sort by只保证每个reduce的输出有序,不保证全局有序。不受hive严格模式影响
Distrbute By(每个分区排序)
distribute by 和group by
都是按照key值划分数据
都是使用reduce操作
唯一不同,distribute by 只是单纯的分散数据,而group by 把相同key的数据聚集到一起,后续必须是聚合操作
Cluster By
当 distribute by 和 sorts by字段相同时,可以使用 cluster by 方式代替。cluster by除了具有 distribute by 的功能外还兼具 sort by 的功能。但是排序只能是 升序 排序,不能像distribute by 一样去指定排序的规则为 ASC 或者 DESC 。
介绍下平时常用的函数?
行转列函数:
Concat(str1,str2,str3)如果有一个参数为null,则返回null
Concat(aaa, ‘ ’ , b b b ) a a a ’, bbb) aaa ’,bbb)aaabbb
Concat_ws(分隔符,str…),分隔符为null,返回null,拼接字符为null,就忽略
列转行函数:
炸裂函数explode(col),可以将map或者array拆成多行
LATERAL VIEW
LATERAL VIEW 可以和explode联合使用,将一行数据拆成多行,并且做聚合。
窗口函数:
Rank:排序,相同的序号一样,但总数不变,所以他可能有序号跳的情况12245
Row_number:顺序记录,1 2 345
Dense_rank:相同的序号一样,但会变少,不会跳12234
列举8个常用的配置参数
0-hive.fetch.task.conversion=more;将hive拉取的模式设置为more模式
1-hive.exec.mode.local.auto 决定 Hive 是否应该自动地根据输入文件大小,在本地运行(在GateWay运行) ;
2-hive.auto.convert.join :是否根据输入小表的大小,自动将 Reduce 端的 Common Join 转化为 Map Join,从而加快大表关联小表的 Join 速度。 默认:false。
3-mapred.reduce.tasks :所提交 Job 的 reduer 的个数,使用 Hadoop Client 的配置。 默认是-1,表示Job执行的个数交由Hive来分配;
mapred.map.tasks:设置提交Job的map端个数;
4-hive.map.aggr=true 开启map端聚合;
hive.groupby.skewindata=true :决定 group by 操作是否支持倾斜的数据。
原理是,在Group by中,对一些比较小的分区进行合并,默认是false;
5-hive.merge.mapredfiles :是否开启合并 Map/Reduce 小文件,对于 Hadoop 0.20 以前的版本,起一首新的 Map/Reduce Job,对于 0.20 以后的版本,则是起使用 CombineInputFormat 的 MapOnly Job。 默认是:false;
6-hive.mapred.mode :Map/Redure 模式,如果设置为 strict,将不允许笛卡尔积。 默认是:'nonstrict';
7-hive.exec.parallel :是否开启 map/reduce job的并发提交。
默认Map/Reduce job是顺序执行的,默认并发数量是8,可以配置。默认是:false;
8-hive.exec.dynamic.partition =true:是否打开动态分区。 需要打开,默认:false;
set hive.exec.dynamic.partition.mode=nonstirct
** hive架构:**
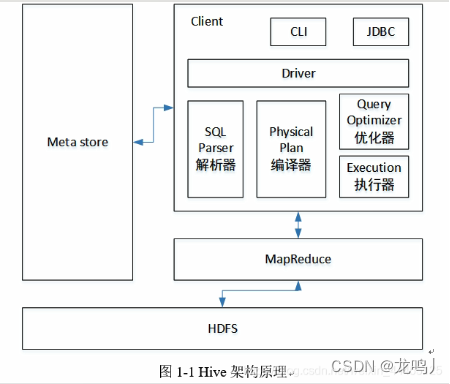
驱动器:Driver
(1)解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第
三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL
语义是否有误。
(2)编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
(3)优化器(Query Optimizer):对逻辑执行计划进行优化。
(4)执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来
说,就是 MR/Spark。
Hive与Mysql的区别?
存储位置:Hive在Hadoop上;Mysql将数据存储在设备或本地系统中;
数据更新:Hive不支持数据的改写和添加,是在加载的时候就已经确定好了;数据库可以CRUD;
索引:Hive无索引,每次扫描所有数据,底层是MR,并行计算,适用于大数据量;MySQL有索引,适合在线查询数据;
执行:Hive底层是MarReduce;MySQL底层是执行引擎;
可扩展性:Hive:大数据量,慢慢扩去吧;MySQL:相对就很少了
说说对Hive桶表的理解?
桶表是对数据进行哈希取值,然后放到不同文件中存储。数据加载到桶表时,会对字段取hash值,然后与桶的数量取模。把数据放到对应的文件中。物理上,每个桶就是表(或分区)目录里的一个文件,一个作业产生的桶(输出文件)和reduce任务个数相同。桶表专门用于抽样查询,是很专业性的,不是日常用来存储数据的表,需要抽样查询时,才创建和使用桶表。
hbase****面试题
https://blog.csdn.net/shujuelin/article/details/89035272
HBase中的数据为何不直接存放于HDFS之上?
HBase中存储的海量数据记录,通常在几百Bytes到KB级别,如果将这些数据直接存储于HDFS之上,会导致大量的小文件产生,为HDFS的元数据管理节点(NameNode)带来沉重的压力。
文件能否直接存储于HBase里面?
如果是几MB的文件,其实也可以直接存储于HBase里面,我们暂且将这类文件称之为小文件,HBase提供了一个名为MOB的特性来应对这类小文件的存储。但如果是更大的文件,强烈不建议用HBase来存储
介绍HBase数据模型:
RowKey:唯一一行记录的主键,HBase的数据是按照RowKey的字典顺序进行全局排序的,所有的查询都只能依赖于这一个排序维度。
Region:Region是HBase中负载均衡的基本单元,当一个Region增长到一定大小以后,会自动分裂成两个。
ColumnFamily:一个Region中的数据列的纵向切割,称之为一个ColumnFamily.每一个列,都必须归属于一个ColumnFamily,这个归属关系是在写数据时指定的,而不是建表时预先定义。
KeyValue:每一行中的每一列数据,都被包装成独立的拥有特定结构的KeyValue,KeyValue中包含了丰富的自我描述信息,会带来显著的数据膨胀。
基于数据模型介绍HBase的适用场景
快速介绍集群关键角色以及集群部署建议
RegionServer与DataNode联合部署,RegionServer与DataNode按1:1比例设置。
这种部署的优势在于,RegionServer中的数据文件可以存储一个副本于本机的DataNode节点中,从而在读取时可以利用HDFS中的”短路径读取(Short Circuit)“来绕过网络请求,降低读取时延。
如果是基于物理机部署,每一台物理机节点上可以设置几个RegionServers/DataNodes来提升资源使用率。
HBase 适用于怎样的情景?
半结构化或非结构化数据
记录非常稀疏
多版本数据
超大数据量
HBase 特性:
强一致性读写: HBase 不是 "最终一致性(eventually consistent)" 数据存储. 这让它很适合高速计数聚合类任务。
自动分片(Automatic sharding): HBase 表通过region分布在集群中。数据增长时,region会自动分割并重新分布。
RegionServer 自动故障转移
Hadoop/HDFS 集成: HBase 支持本机外HDFS 作为它的分布式文件系统。
MapReduce: HBase 通过MapReduce支持大并发处理, HBase 可以同时做源和目标.
Java 客户端 API: HBase 支持易于使用的 Java API 进行编程访问.
Thrift/REST API: HBase 也支持Thrift 和 REST 作为非Java 前端.
Block Cache 和 Bloom Filters: 对于大容量查询优化, HBase支持 Block Cache 和 Bloom Filters。
运维管理: HBase提供内置网页用于运维视角和JMX 度量.
HBase写入数据流程:
写流程:
1)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,
查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以
及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
3)与目标 Region Server 进行通讯;
4)将数据顺序写入(追加)到 WAL;
5)将数据写入对应的 MemStore,数据会在 MemStore 进行排序;
6)向客户端发送 ack;
7)等达到 MemStore 的刷写时机后,将数据刷写到 HFile。
**HBase读流程 **
1)Client 先访问 zookeeper,获取 hbase:meta 表位于哪个 Region Server。
2)访问对应的 Region Server,获取 hbase:meta 表,根据读请求的 namespace:table/rowkey,
查询出目标数据位于哪个 Region Server 中的哪个 Region 中。并将该 table 的 region 信息以
及 meta 表的位置信息缓存在客户端的 meta cache,方便下次访问。
3)与目标 Region Server 进行通讯;
4)分别在 Block Cache(读缓存),MemStore 和 Store File(HFile)中查询目标数据,并将
查到的所有数据进行合并。此处所有数据是指同一条数据的不同版本(time stamp)或者不
同的类型(Put/Delete)。
5) 将从文件中查询到的数据块(Block,HFile 数据存储单元,默认大小为 64KB)缓存到
Block Cache。
6)将合并后的最终结果返回给客户端。
HBase文件合并StoreFile Compaction :
由于memstore每次刷写都会生成一个新的HFile,且同一个字段的不同版本(timestamp)
和不同类型(Put/Delete)有可能会分布在不同的HFile中,因此查询时需要遍历所有的HFile。
为了减少 HFile 的个数,以及清理掉过期和删除的数据,会进行 StoreFile Compaction。
Compaction 分为两种,分别是 Minor Compaction 和 Major Compaction。Minor Compaction
会将临近的若干个较小的 HFile 合并成一个较大的 HFile,但不会清理过期和删除的数据。
Major Compaction 会将一个 Store 下的所有的 HFile 合并成一个大 HFile,并且会清理掉过期
和删除的数据。
scan 'stu' ,{RAW=>TRUE,VERSIONS=>10}
Region Split 时机:
1.当1个region中的某个Store下所有StoreFile的总大小超过hbase.hregion.max.filesize,
该 Region 就会进行拆分(0.94 版本之前)。
2.当 1 个 region 中 的某 个 Store 下所有 StoreFile 的总 大 小超过 Min(R^2 *
"hbase.hregion.memstore.flush.size",hbase.hregion.max.filesize"),该 Region 就会进行拆分,其
中 R 为当前 Region Server 中属于该 Table 的个数(0.94 版本之后)。
HBase优化:
RowKey 设计
一条数据的唯一标识就是 RowKey,那么这条数据存储于哪个分区,取决于 RowKey 处
于哪个一个预分区的区间内,设计 RowKey 的主要目的 ,就是让数据均匀的分布于所有的
region 中,在一定程度上防止数据倾斜。接下来我们就谈一谈 RowKey 常用的设计方案。
1.生成随机数、hash、散列值
比如: 原本 rowKey 为 1001 的,SHA1 后 变 成 : dd01903921ea24941c26a48f2cec24e0bb0e8cc7 原本 rowKey 为 3001 的,SHA1 后 变 成 : 49042c54de64a1e9bf0b33e00245660ef92dc7bd 原本 rowKey 为 5001 的 , SHA1 后 变 成 : 7b61dec07e02c188790670af43e717f0f46e8913 在做此操作之前,一般我们会选择从数据集中抽取样本,来决定什么样的 rowKey 来 Hash 后作为每个分区的临界值。
2.字符串反转
20170524000001 转成 10000042507102 20170524000002 转成 20000042507102 这样也可以在一定程度上散列逐步 put 进来的数据。
3.字符串拼接
20170524000001_a12e 20170524000001_93i7
rowkey的设计原则?
建议使用String如果不是特殊要求,RowKey最好都是String。 方便线上使用Shell查数据、排查错误 更容易让数据均匀分布 不必考虑存储成本 RowKey的长度尽量短。如果RowKey太长话,第一是,存储开销会增加,影响存储效率;第二是,内存中Rowkey字段过长,内存的利用率会降低,这会降低索引命中率。
一般的做法是: 时间使用Long来表示 尽量使用编码压缩 RowKey尽量散列RowKey的设计,最重要的是要保证散列,这样就会保证所有的数据都不都是在一个region上,避免做读写的时候负载将会集中在个别region上面。
1、关于rowkey的实际设计:
1)最大有利于查询的原则:需要将查询的必须字段设计在rowkey里面,频率越高的字段放在前面;
2)对于tall table 模式的rowkey需要满足唯一性原则:例如使用系统中已有的主键,如用户ID,流水号等来做前缀(一般都需要反转),对于通过定长的字段拼接的rowkey,不需要使用分隔符
3)rowkey的长度在满足业务前提下尽量短的原则:有些很长的分类字段考虑使用编码来表示。
4)rowkey的设计保持散列性原则:要避免出现region的热点情况,一般可以通过加salt的方式、反转rowkey,或者加md5值等技术手段来避免region的热点问题。
2、关于列簇的设计
列族和列名尽量短小
某些字段(如枚举)可以考虑通过列名来存储
数据非永久保留的,建议设置TTL来定期的清理数据
对于业务数据量巨大,且读写请求较低的业务,可以考虑对数据进行压缩,比如采用LZO压缩。
3、关于表的预分区的设计
为了避免HBase region在后续随着业务数据的增长自动split的现象带来业务的影响,以及避免出现热点region,对于数据量较大,且读写请求较高的表都需要做预分区设计。
设计方法如下:
1)反转后的rowkey的首位字符或者前两位字符作为split key
2)rowkey做md5值或者Hash值后的首位字符或者前两位字符作为split key
3)通过salt值来做split key
4)split key的数量:业务方提供数据量和请求量,由HBase平台组决定需要做多少预分区(split key +1)
Spark面试题
spark提交作业的参数?
executor-cores —— 每个executor使用的内核数,默认为1,官方建议2-5个,我们企业是4个
num-executors —— 启动executors的数量,默认为2
executor-memory —— executor内存大小,默认1G
driver-cores —— driver使用内核数,默认为1
driver-memory —— driver内存大小,默认512M
简述Spark的宽窄依赖,以及Spark如何划分stage,每个stage又根据什么决定task个数?
窄依赖:父RDD的一个分区只会被子RDD的一个分区依赖
宽依赖:父RDD的一个分区会被子RDD的多个分区依赖(涉及到shuffle)
RDD在Lineage依赖方面分为两种Narrow Dependencies与Wide Dependencies,用来解决数据容错时的高效性以及划分任务时候起到重要作用
那Stage是如何划分的呢?
根据RDD之间的依赖关系的不同将Job划分成不同的Stage,遇到一个宽依赖则划分一个Stage。
每个stage又根据什么决定task个数?
Stage是一个TaskSet,将Stage根据分区数划分成一个个的Task。
Repartition和Coalesce 的关系与区别,能简单说说吗?
1)关系:
两者都是用来改变RDD的partition数量的,repartition底层调用的就是coalesce方法:coalesce(numPartitions, shuffle = true)
2)区别:
repartition一定会发生shuffle,coalesce 根据传入的参数来判断是否发生shuffle。
一般情况下增大rdd的partition数量使用repartition,减少partition数量时使用coalesce。
Spark中的缓存(cache和persist)与checkpoint机制,并指出两者的区别和联系
位置
Persist 和 Cache将数据保存在内存,Checkpoint将数据保存在HDFS
生命周期
Persist 和 Cache 程序结束后会被清除或手动调用unpersist方法,Checkpoint永久存储不会被删除。
RDD依赖关系
Persist 和 Cache,不会丢掉RDD间的依赖链/依赖关系,CheckPoint会斩断依赖链。
Spark中共享变量(广播变量和累加器)的基本原理与用途
累加器(accumulator)是Spark中提供的一种分布式的变量机制,其原理类似于mapreduce,即分布式的改变,然后聚合这些改变。累加器的一个常见用途是在调试时对作业执行过程中的事件进行计数。
广播变量是在每个机器上缓存一份,不可变,只读的,相同的变量,该节点每个任务都能访问,起到节省资源和优化的作用。它通常用来高效分发较大的对象。
Spark调优?
资源参数调优
num-executors:设置Spark作业总共要用多少个Executor进程来执行
executor-memory:设置每个Executor进程的内存
executor-cores:设置每个Executor进程的CPU core数量
driver-memory:设置Driver进程的内存
spark.default.parallelism:设置每个stage的默认task数量
开发调优
1.避免创建重复的RDD
2.尽可能复用同一个RDD
3.对多次使用的RDD进行持久化
4.尽量避免使用shuffle类算子
5.使用map-side预聚合的shuffle操作
*6.使用高性能的算子:*
①使用reduceByKey/aggregateByKey替代groupByKey
②使用mapPartitions替代普通map
③使用foreachPartitions替代foreach
④使用filter之后进行coalesce操作
⑤使用repartitionAndSortWithinPartitions替代repartition与sort类操作
广播大变量
在算子函数中使用到外部变量时,默认情况下,Spark会将该变量复制多个副本,通过网络传输到task中,此时每个task都有一个变量副本。如果变量本身比较大的话(比如100M,甚至1G),那么大量的变量副本在网络中传输的性能开销,以及在各个节点的Executor中占用过多内存导致的频繁GC(垃圾回收),都会极大地影响性能。
使用Kryo优化序列化性能
优化数据结构
在可能以及合适的情况下,使用占用内存较少的数据结构,但是前提是要保证代码的可维护性。
Spark 中的数据倾斜问题****?
Spark 数据倾斜的几种场景以及对应的解决方案,包括避免数据源倾斜,调整并行度,使用自定义 Partitioner,使用 Map 侧 Join 代替 Reduce 侧 Join(内存表合并),给倾斜 Key 加上随机前缀等。
具体解决方案:
1. 调整并行度分散同一个 Task 的不同 Key
Spark 在做 Shuffle 时,默认使用 HashPartitioner对数据进行分区。如果并行度设置的不合适,可能造成大量不相同的 Key 对应的数据被分配到了同一个 Task 上,造成该 Task 所处理的数据远大于其它 Task,从而造成数据倾斜。
2. 自定义Partitioner: 使用自定义的 Partitioner(默认为 HashPartitioner),将原本被分配到同一个 Task 的不同 Key 分配到不同 Task。
3. 将 Reduce side(侧) Join 转变为 Map side(侧) Join: 通过 Spark 的 Broadcast 机制,将 Reduce 侧 Join 转化为 Map 侧 Join,避免 Shuffle 从而完全消除 Shuffle 带来的数据倾斜。可以看到 RDD2 被加载到内存中了。
4. 为 skew 的 key 增加随机前/后缀: 为数据量特别大的 Key 增加随机前/后缀,使得原来 Key 相同的数据变为 Key 不相同的数据,从而使倾斜的数据集分散到不同的 Task 中,彻底解决数据倾斜问题。Join 另一则的数据中,与倾斜 Key 对应的部分数据,与随机前缀集作笛卡尔乘积,从而保证无论数据倾斜侧倾斜 Key 如何加前缀,都能与之正常 Join。
5. 大表随机添加 N 种随机前缀,小表扩大 N 倍: 如果出现数据倾斜的 Key 比较多,上一种方法将这些大量的倾斜 Key 分拆出来,意义不大(很难一个 Key 一个 Key 都加上后缀)。此时更适合直接对存在数据倾斜的数据集全部加上随机前缀,然后对另外一个不存在严重数据倾斜的数据集整体与随机前缀集作笛卡尔乘积(即将数据量扩大 N 倍),可以看到 RDD2 扩大了 N 倍了,再和加完前缀的大数据做笛卡尔积。
Spark有哪些聚合类的算子,我们应该尽量避免什么类型的算子?
在我们的开发过程中,能避免则尽可能避免使用 reduceByKey、join、distinct、repartition 等会进行 shuffle 的算子,尽量使用 map 类的非 shuffle 算子。这样的话,没有 shuffle 操作或者仅有较少 shuffle 操作的 Spark 作业,可以大大减少性能开销。
Spark作业提交流程是怎么样的****?
答案一:
1.任务提交后先会和ResourceManager 通讯申请启动ApplicationMaster,
2.随后ResourceManager 分配 container,在合适的 NodeManager 上启动 ApplicationMaster,此时的ApplicationMaster 就是Driver。
3.Driver 启动后向 ResourceManager 申请Executor 内存,ResourceManager 接到ApplicationMaster 的资源申请后会分配container,然后在合适的NodeManager 上启动Executor 进程。
4.Executor 进程启动后会向Driver 反向注册,Executor 全部注册完成后Driver 开始执行main 函数,
5.之后执行到 Action 算子时,触发一个 Job,并根据宽依赖开始划分 stage,每个stage 生成对应的TaskSet,之后将 task 分发到各个Executor 上执行。
答案二:
1.spark-submit 提交代码,执行 new SparkContext(),在 SparkContext 里构造 DAGScheduler 和 TaskScheduler。
2.TaskScheduler 会通过后台的一个进程,连接 Master,向 Master 注册 Application。
3.Master 接收到 Application 请求后,会使用相应的资源调度算法,在 Worker 上为这个 Application 启动多个 Executer。
4.Executor 启动后,会自己反向注册到 TaskScheduler 中。 所有 Executor 都注册到 Driver 上之后,SparkContext 结束初始化,接下来往下执行我们自己的代码。
5.每执行到一个 Action,就会创建一个 Job。Job 会提交给 DAGScheduler。
6.DAGScheduler 会将 Job划分为多个 stage,然后每个 stage 创建一个 TaskSet。
7.TaskScheduler 会把每一个 TaskSet 里的 Task,提交到 Executor 上执行。
8.Executor 上有线程池,每接收到一个 Task,就用 TaskRunner 封装,然后从线程池里取出一个线程执行这个 task。(TaskRunner 将我们编写的代码,拷贝,反序列化,执行 Task,每个 Task 执行 RDD 里的一个 partition)
reduceByKey与groupByKey的区别,哪一种更具优势?
reduceByKey:按照key进行聚合,在shuffle之前有combine(预聚合)操作,返回结果是RDD[k,v]。
groupByKey:按照key进行分组,直接进行shuffle
reduceByKey比groupByKey,更建议使用。但是需要注意是否会影响业务逻辑。
如何使用Spark实现TopN的获取(描述思路或使用伪代码)?
方法1:
(1)按照key对数据进行聚合(groupByKey)
(2)将value转换为数组,利用scala的sortBy或者sortWith进行排序(mapValues)
注意:当数据量太大时,会导致OOM
方法2:
(1)取出所有的key
(2)对key进行迭代,每次取出一个key利用spark的排序算子进行排序
方法3:
(1)自定义分区器,按照key进行分区,使不同的key进到不同的分区
(2)对每个分区运用spark的排序算子进行排序
版权归原作者 龙鸣丿 所有, 如有侵权,请联系我们删除。