
前言
目前MySQL8.x版本数据库已经支持了很多存储引擎了,但是一般我们常用的就几种,容易形成思维固化不会轻易采取其他存储引擎,从而错失很多优化存储的功能。因此对现支持的九种数据库存储引擎的功能有个清楚的理解是个值得学习的事情。本篇文章将这八种数据库存储引擎的功能和作用以及使用场景都讲清楚。
此系列文章将被纳入我的专栏一文速学SQL各类数据库操作,基本覆盖到使用SQL处理日常业务以及常规的查询建库分析以及复杂操作方方面面的问题。从基础的建库建表逐步入门到处理各类数据库复杂操作,以及专业的SQL常用函数讲解都花费了大量时间和心思创作,如果大家有需要从事数据分析或者数据开发的朋友推荐订阅专栏,将在第一时间学习到最实用常用的知识。此篇博客篇幅较长,值得细读实践一番,我会将精华部分挑出细讲实践。博主会长期维护博文,有错误或者疑惑可以在评论区指出,感谢大家的支持。
一、支持的存储引擎
进入MySQL的数据库查看存储引擎就可以看到MySQL数据库所有支持的存储引擎:
SHOW ENGINES
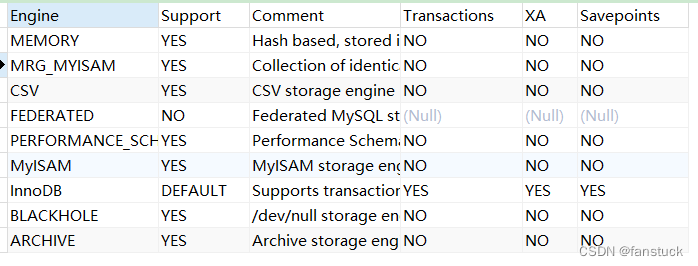
目前有一个引擎Federated不支持,我们只需要清楚其他八种数据库存储就好。
MySQL中常见的数据库引擎有MyISAM、InnoDB、Memory。那么我们就先清楚这三种引擎。
二、InnoDB引擎
InnoDB是MySQL的默认引擎,一个支持事务安全的存储引擎。mysql中数据是存储在物理磁盘上的,而真正的数据处理又是在内存中执行的。由于磁盘的读写速度非常慢,如果每次操作都对磁盘进行频繁读写的话,那么性能就会非常差。
为了上述问题,InnoDB将数据划分为若干页,以页作为磁盘与内存交互的基本单位,一般页的大小为16KB。这样的话,一次性至少读取1页数据到内存中或者将1页数据写入磁盘。通过减少内存与磁盘的交互次数,从而提升性能。
这本质上就是一种典型的缓存设计思想,一般缓存的设计基本都是从时间维度或者空间维度进行考量的:
- 时间维度:如果一条数据正在在被使用,那么在接下来一段时间内大概率还会再被使用。可以认为热点数据缓存都属于这种思路的实现。
- 空间维度:如果一条数据正在在被使用,那么存储在它附近的数据大概率也会很快被使用。InnoDB的数据页和操作系统的页缓存则是这种思路的体现。
下面是官方的InnoDB引擎结构图,主要分为内存结构和磁盘结构两大部分。
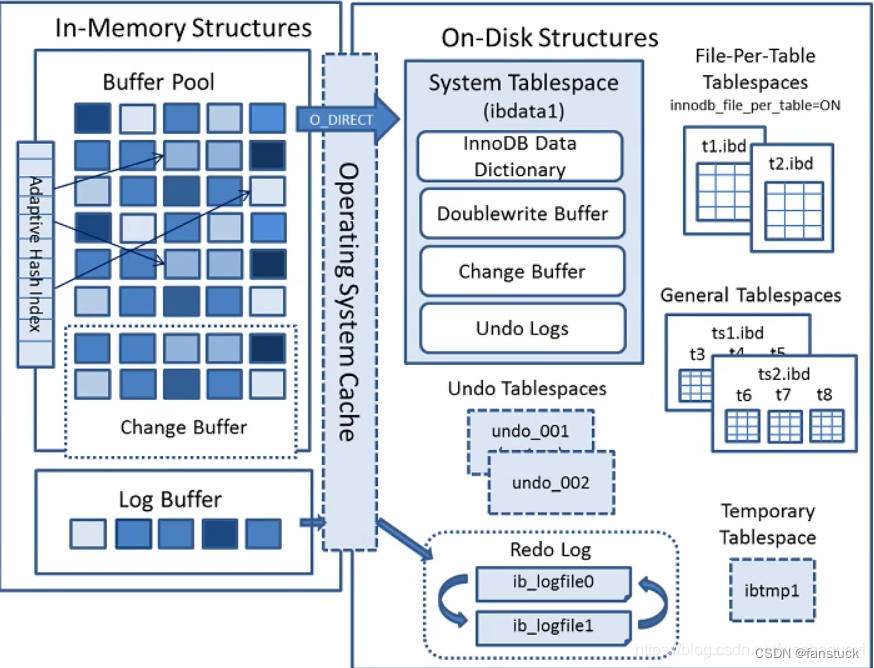
内存结构主要包括Buffer Pool、Change Buffer、Adaptive Hash Index和Log Buffer四大组件。
1.Buffer Pool
Buffer Pool由包含数据、索引、insert buffer ,adaptive hash index,lock 信息及数据字典。缓冲池,简称BP。BP以Page页为单位,默认大小16K,BP的底层采用链表数据结构管理Page。在InnoDB访问表记录和索引时会在Page页中缓存,以后使用可以减少磁盘IO操作,提升效率。
缓冲池简单来说就是一块内存区域,通过内存的速度来弥补磁盘速度较慢对数据库性能的影响。在数据库中进行读取页的操作,首先将从磁盘读到的页存放在缓冲池中,这个过程称为将页"FIX"在缓冲池中。下一次再读取相同的页时,首先判断该页是否在缓冲池中。若在缓冲池中,称该页在缓冲池中被命中。直接读取该页。否则读取磁盘上的页。对于数据库中页的修改操作,则首先修改在缓冲池中的页,然后再以一定的频率刷新到磁盘上。这里需要注意的是,页从缓冲池刷新回磁盘的操作并不是每次页发生更新时触发,而是通过一种称为Checkpoint的机制刷新回磁盘。同样这也是为了提高数据库的整体性能。
传统LUR算法
缓冲池是通过LRU(Latest Recent Used,最近最少使用)算法来进行管理的,即最频繁使用的页在LRU列表的最前段,而最少使用的页在LRU列表的尾端,当缓冲池不能存放新读取到的页时,首先释放LRU列表尾端的页:
(1)页已经在缓冲池里,那就只做“移至”LRU头部的动作,而没有页被淘汰;
(2)页不在缓冲池里,除了做“放入”LRU头部的动作,还要做“淘汰”LRU尾部页的动作;
但是InnoDB的LUR算法并不是传统的LUR算法。
这里有两个问题:
(1)预读失效;
(2)缓冲池污染;
我们先了解什么是预读;
预读
磁盘读写,并不是按需读取,而是按页读取,一次至少读一页数据(一般是4K),如果未来要读取的数据就在页中,就能够省去后续的磁盘IO,提高效率。数据访问,通常都遵循“集中读写”的原则,使用一些数据,大概率会使用附近的数据,这就是所谓的“局部性原理”,它表明提前加载是有效的,确实能够减少磁盘IO。
预读失效
由于预读(Read-Ahead),提前把页放入了缓冲池,但最终MySQL并没有从页中读取数据,称为预读失效。
要优化预读失效,思路是:
(1)让预读失败的页,停留在缓冲池LRU里的时间尽可能短;
(2)让真正被读取的页,才挪到缓冲池LRU的头部;
以保证,真正被读取的热数据留在缓冲池里的时间尽可能长。
具体方法是:
(1)将LRU分为两个部分:
新生代(new sublist)老生代(old sublist)
(2)新老生代收尾相连,即:新生代的尾(tail)连接着老生代的头(head);
(3)新页(例如被预读的页)加入缓冲池时,只加入到老生代头部:
如果数据真正被读取(预读成功),才会加入到新生代的头部如果数据没有被读取,则会比新生代里的“热数据页”更早被淘汰出缓冲池
新老生代改进版LRU仍然解决不了缓冲池污染的问题。
2.Log Buffer
Log Buffer用来缓存重做日志。
InnoDB有两个非常重要的日志:undo log、redo log
(1)通过undo log可以看到数据较早版本,实现MVCC,或回滚事务等功能。
(2)通过redo log用来保证事务持久性。
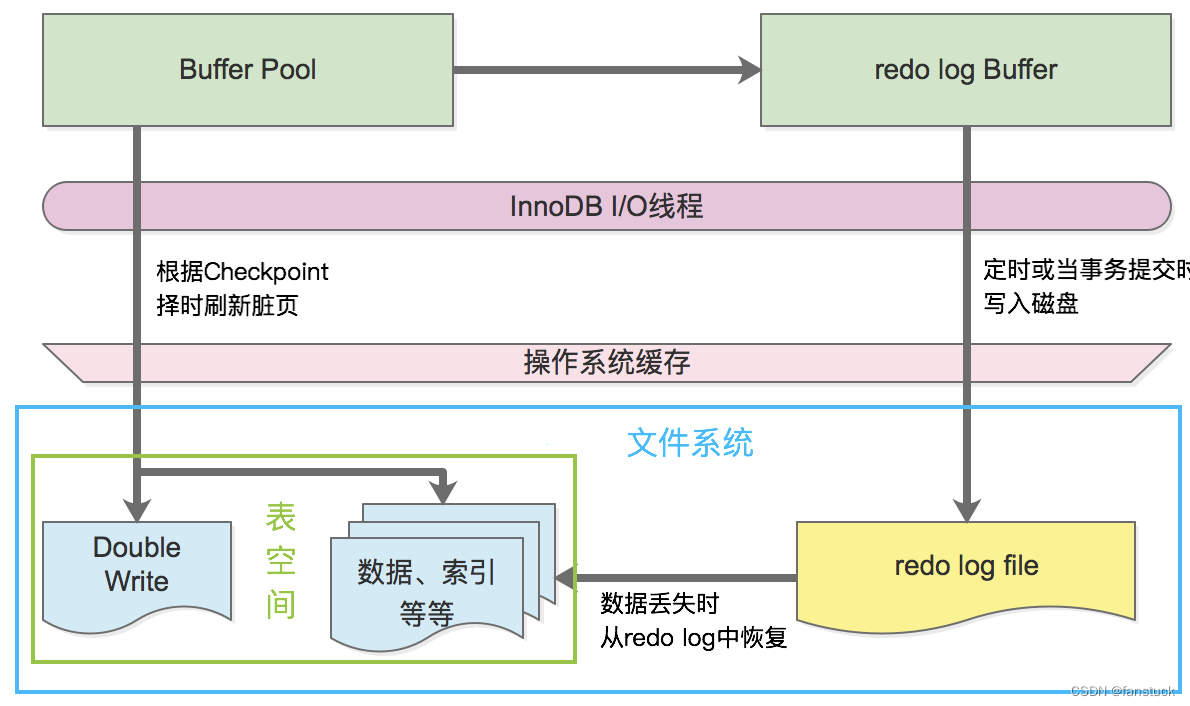
redo日志缓冲区是内存存储区域,用于保存要写入磁盘上的日志文件的数据。日志缓冲区大小由innodb_log_buffer_size 变量定义,默认大小为16MB。
日志缓冲区的内容定期刷新到磁盘。较大的日志缓冲区可以运行大型事务,而无需在事务提交之前将重做日志数据写入磁盘。因此,如果有更新,插入或删除许多行的事务,则增加日志缓冲区的大小可以节省磁盘I/O。
innodb_flush_log_at_trx_commit :控制如何将日志缓冲区的内容写入并刷新到磁盘。
innodb_flush_log_at_timeout :控制日志刷新频率。
如果磁盘I/O导致性能问题,则需要观察事务,例如涉及许多BLOB条目的事务。只要InnoDB日志缓冲区已满,便会将其刷新到磁盘,因此增加缓冲区大小可以减少I/O。
日志文件的缺省数量为两个: ib_logfile0 和 ib_logfile1 。
日志具有固定大小,默认大小取决于MySQL版本。
3.Adaptive Hash Index
Adaptive Hash Index自适应hash索引是一种键值对的存储结构,存储的是热点页所在的记录。InnoDB存储引擎会自动根据访问的频率和模式 来为某些页建立哈希索引。
B+树索引自适应Hash索引查询时间复杂度O(树的高度)O(1)是否持久化是,并通过日志保证完整性否,仅在内存索引对象页热点页所在的记录
上面的图就是区分B+树索引和自适应hash索引的区别。 通过参数innodb_adaptive_hash_index来禁用或启动此特性,默认为开启。
4.Change Buffer
Change Buffer:MySQL中数据分为内存和磁盘两个部分;在buffer pool中缓存热的数据页和索引页,减少磁盘读;通过change buffer就是为了缓解磁盘写的一种手段。
当需要更新一个数据页时,如果数据页在内存中就直接更新。如果数据页不在内存中。在不影响数据一致性的前下,InooDB 会将这些更新操作缓存在 change buffer 中,这样就不需要从磁盘中读入这个数据页了。在下次查询需要访问这个数据页的时候,将数据页读入内存,然后执行 change buffer 中与这个页有关的操作。通过这种方式就能保证这个数据逻辑的正确性。
虽然名字叫作 change buffer,实际上它是可以持久化的数据。也就是说,change buffer 在内存中有拷贝,也会被写入到磁盘上(ibdata)。
将 change buffer 中的操作合并到原数据页,得到最新结果的过程称为 merge。以下情况会触发merge:
- 访问这个数据页;
- 后台master线程会定期 merge;
- 数据库缓冲池不够用时;
- 数据库正常关闭时;
- redo log写满时;
change buffer就是在非唯一普通索引页不在buffer pool中时,对页进行了写操作的情况下,先将记录变更缓冲,等未来数据被读取时,再将 change buffer 中的操作merge到原数据页的技术。在MySQL5.5之前,叫插入缓冲(insert buffer),只针对insert做了优化;现在对delete和update也有效,叫做写缓冲(change buffer)。
参阅
mysql存储引擎InnoDB详解,从底层看清InnoDB数据结构
Mysql5.7 自适应hash索引 Adaptive hash index
change buffer(写缓冲)
缓冲池(buffer pool),这次彻底懂了!!!
版权归原作者 fanstuck 所有, 如有侵权,请联系我们删除。