
第1章 Canal 简介
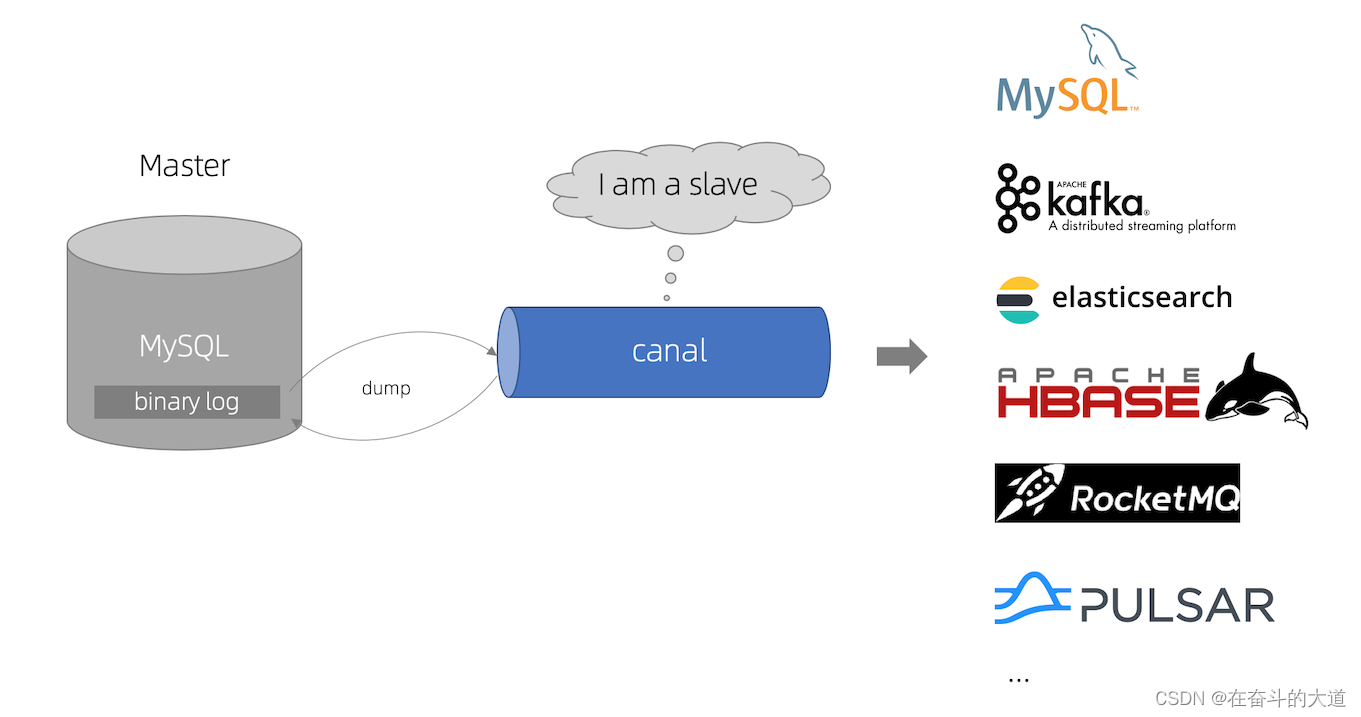
canal [kə'næl],译意为水道/管道/沟渠,主要用途是基于 MySQL 数据库增量日志解析,提供增量数据订阅和消费
工作原理
canal 模拟 MySQL slave 的交互协议,伪装自己为 MySQL slave ,向 MySQL master 发送 dump 协议
MySQL master 收到 dump 请求,开始推送 binary log 给 slave (即 canal )
canal 解析 binary log 对象(原始为 byte 流)
第2章 Canal 快速开始
环境准备
主机环境:Windows 11
数据库版本:MySQL-8数据库
Canal版本:canal.deployer-1.1.6
MySQL8准备
(1)检查MySQL 的binlog功能是否有开启
-- 是否开启binlog
show VARIABLES like 'log_bin';
(2)如果显示状态为OFF表示该功能未开启,开启binlog功能
1,修改 mysql 的配置文件 my.cnf
**/**/my.cnf
末尾追加内容:
#binlog文件名
log-bin=mysql-bin
#选择row模式
binlog_format=ROW
#mysql实例id,不能和canal的slaveId重复
server_id=1
2,windows 重启 mysql
(3)在mysql里面添加以下的相关用户和权限
CREATE USER 'canal'@'%' IDENTIFIED BY 'canal';
GRANT SHOW VIEW, SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO
'canal'@'%';
FLUSH PRIVILEGES;
Windows 安装Canal
下载地址
Canal Git 地址:https://github.com/alibaba/canal/releases
解压及配置
解压canal.deployer-1.1.6.tar.gz,我们可以看到里面有四个文件夹:

Canal 启动配置
(1)打开配置文件conf/example/instance.properties
#################################################
## v1.0.26版本后会自动生成slaveId,所以可以不用配置
# canal.instance.mysql.slaveId=0
# enable gtid use true/false
canal.instance.gtidon=false
# 数据库地址
canal.instance.master.address=127.0.0.1:3306
# binlog日志名称
canal.instance.master.journal.name=mysql-bin.000001
# binlog偏移量
canal.instance.master.position=913
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=mysql\\.slave_.*
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=example
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,topic2:mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.enableDynamicQueuePartition=false
#canal.mq.partitionsNum=3
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################
知识点拓展:查看MySQL 的binlog日志名称 和binlog 偏移量
# 查看当前服务器使用的biglog文件及大小
show binary logs;
# 查看最新一个binlog日志文件名称和Position
show master status;
# 查看 binlog 日志列表
show master logs;
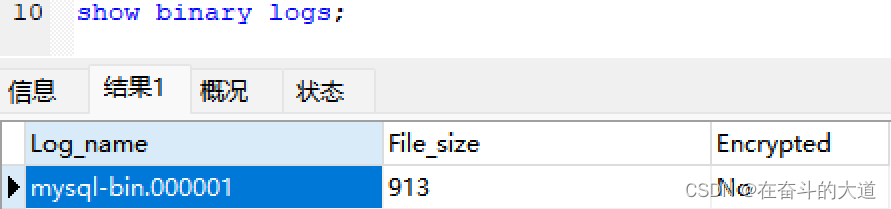
(2)Canal 启动
切换至Canal项目bin 文件夹(D:\Canal\canal.deployer-1.1.6\bin),双击启动startup.bat
(3)查看Canal server 日志
切换至Canal项目logs/canal 文件夹

查看logs/canal/canal.log 日志内容
2023-02-06 15:45:55.188 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## set default uncaught exception handler
2023-02-06 15:45:55.193 [main] INFO com.alibaba.otter.canal.deployer.CanalLauncher - ## load canal configurations
2023-02-06 15:45:55.198 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## start the canal server.
2023-02-06 15:45:55.358 [main] INFO com.alibaba.otter.canal.deployer.CanalController - ## start the canal server[192.168.43.80(192.168.43.80):11111]
2023-02-06 15:45:56.260 [main] INFO com.alibaba.otter.canal.deployer.CanalStarter - ## the canal server is running now ......
(4)查看Canal instance 日志
切换至Canal项目logs/example文件夹
2023-02-06 17:06:18.146 [main] INFO c.a.otter.canal.instance.spring.CanalInstanceWithSpring - start CannalInstance for 1-example
2023-02-06 17:06:18.148 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table filter : ^.*\..*$
2023-02-06 17:06:18.148 [main] WARN c.a.o.canal.parse.inbound.mysql.dbsync.LogEventConvert - --> init table black filter : ^mysql\.slave_.*$
2023-02-06 17:06:18.148 [main] INFO c.a.otter.canal.instance.core.AbstractCanalInstance - start successful....
2023-02-06 17:06:18.201 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> begin to find start position, it will be long time for reset or first position
2023-02-06 17:06:18.316 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - prepare to find start position mysql-bin.000001:4:1675666212000
2023-02-06 17:06:18.809 [destination = example , address = /127.0.0.1:3306 , EventParser] WARN c.a.o.c.p.inbound.mysql.rds.RdsBinlogEventParserProxy - ---> find start position successfully, EntryPosition[included=false,journalName=mysql-bin.000001,position=4,serverId=1,gtid=<null>,timestamp=1675666212000] cost : 608ms , the next step is binlog dump
2023-02-06 17:06:33.829 [MultiStageCoprocessor-other-example-0] WARN com.taobao.tddl.dbsync.binlog.LogDecoder - Skipping unrecognized binlog event Unknown type:41 from: mysql-bin.000003:157
2023-02-06 17:06:48.835 [MultiStageCoprocessor-other-example-0] WARN com.taobao.tddl.dbsync.binlog.LogDecoder - Skipping unrecognized binlog event Unknown type:41 from: mysql-bin.000003:157
(5)Canal 停止
直接关闭Canal 服务运行窗口即可。
第3章 Docker 安装Canal
第一步:查看本地镜像、检查Canal镜像和下载Canal 镜像
# 查看本地镜像
docker images
# 检索Kafka镜像
docker search canal
# 下载Kafka 镜像指定版本
docker pull canal/canal-server:latest
第二步:docker 启动Canal
docker run --name canal -d canal/canal-server
知识点拓展:拷贝Canal 容器内部配置文件拷贝到外部
语法:docker cp [容器索引]:[内部路径] [外部路径]
实例:
docker cp canal:/home/admin/canal-server/conf/canal.properties /home/canal
docker cp canal:/home/admin/canal-server/conf/example/instance.properties /home/canal
第三步:修改Canal 配置文件instance.properties
# 编辑配置文件
vi /home/canal/instance.properties
编辑内容:
#################################################
## v1.0.26版本后会自动生成slaveId,所以可以不用配置
# canal.instance.mysql.slaveId=0
# enable gtid use true/false
canal.instance.gtidon=false
# 数据库地址
canal.instance.master.address=127.0.0.1:3306
# binlog日志名称
canal.instance.master.journal.name=mysql-bin.000001
# binlog偏移量
canal.instance.master.position=913
canal.instance.master.timestamp=
canal.instance.master.gtid=
# rds oss binlog
canal.instance.rds.accesskey=
canal.instance.rds.secretkey=
canal.instance.rds.instanceId=
# table meta tsdb info
canal.instance.tsdb.enable=true
#canal.instance.tsdb.url=jdbc:mysql://127.0.0.1:3306/canal_tsdb
#canal.instance.tsdb.dbUsername=canal
#canal.instance.tsdb.dbPassword=canal
#canal.instance.standby.address =
#canal.instance.standby.journal.name =
#canal.instance.standby.position =
#canal.instance.standby.timestamp =
#canal.instance.standby.gtid=
# username/password
canal.instance.dbUsername=root
canal.instance.dbPassword=123456
canal.instance.connectionCharset = UTF-8
# enable druid Decrypt database password
canal.instance.enableDruid=false
#canal.instance.pwdPublicKey=MFwwDQYJKoZIhvcNAQEBBQADSwAwSAJBALK4BUxdDltRRE5/zXpVEVPUgunvscYFtEip3pmLlhrWpacX7y7GCMo2/JM6LeHmiiNdH1FWgGCpUfircSwlWKUCAwEAAQ==
# table regex
canal.instance.filter.regex=.*\\..*
# table black regex
canal.instance.filter.black.regex=mysql\\.slave_.*
# table field filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.field=test1.t_product:id/subject/keywords,test2.t_company:id/name/contact/ch
# table field black filter(format: schema1.tableName1:field1/field2,schema2.tableName2:field1/field2)
#canal.instance.filter.black.field=test1.t_product:subject/product_image,test2.t_company:id/name/contact/ch
# mq config
canal.mq.topic=example
# dynamic topic route by schema or table regex
#canal.mq.dynamicTopic=mytest1.user,topic2:mytest2\\..*,.*\\..*
canal.mq.partition=0
# hash partition config
#canal.mq.enableDynamicQueuePartition=false
#canal.mq.partitionsNum=3
#canal.mq.dynamicTopicPartitionNum=test.*:4,mycanal:6
#canal.mq.partitionHash=test.table:id^name,.*\\..*
#################################################
第四步:基于Canal 外部配置文件,重新Canal 容器实例
docker run --name canal -p 11111:11111 -d -v /home/canal/instance.properties:/home/admin/canal-server/conf/example/instance.properties -v /home/canal/canal.properties:/home/admin/canal-server/conf/canal.properties canal/canal-server
可选指令:
- 关闭Canal 容器
docker stop canal
- 移除Canal 容器
docker rm canal
第4章 基于Canal 和Kafka,实现MySQL的Binlog 近实时同步
搭建一套可以用的组件需要部署MySQL、Zookeeper、Kafka和Canal四个中间件的实例。
Docker 安装MySQL
请参考:Docker 安装MySQL
CentOS-7安装ZooKeeper
Canal和Kafka集群都依赖于Zookeeper做服务协调,为了方便管理,一般会独立部署Zookeeper服务或者Zookeeper集群。
midkr /data/zk
# 创建数据目录
midkr /data/zk/data
cd /data/zk
wget http://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.6.0/apache-zookeeper-3.6.0-bin.tar.gz
tar -zxvf apache-zookeeper-3.6.0-bin.tar.gz
cd apache-zookeeper-3.6.0-bin/conf
cp zoo_sample.cfg zoo.cfg && vim zoo.cfg
把zoo.cfg文件中的dataDir设置为/data/zk/data,然后启动Zookeeper:
[root@localhost conf]# sh /data/zk/apache-zookeeper-3.6.0-bin/bin/zkServer.sh start
/usr/bin/java
ZooKeeper JMX enabled by default
Using config: /data/zk/apache-zookeeper-3.6.0-bin/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
注意一点,要启动此版本的Zookeeper服务必须本地安装好JDK8+。启动的默认端口是2181,启动成功后的日志如下:
CentOS-7 安装Kafka
Kafka是一个高性能分布式消息队列中间件,它的部署依赖于Zookeeper。笔者在此选用2.4.0并且Scala版本为2.13的安装包:
mkdir /data/kafka
mkdir /data/kafka/data
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.4.0/kafka_2.13-2.4.0.tgz
tar -zxvf kafka_2.13-2.4.0.tgz
解压后/data/kafka/kafka_2.13-2.4.0/config/server.properties配置中对应的zookeeper.connect=localhost:2181已经符合需要,不必修改,需要修改日志文件的存放目录log.dirs为/data/kafka/data。然后启动Kafka服务:
sh /data/kafka/kafka_2.13-2.4.0/bin/kafka-server-start.sh /data/kafka/kafka_2.13-2.4.0/config/server.properties
知识拓展:kafka 后台进行运行设置
Kafka启动后一旦退出控制台就会结束Kafka进程,可以添加-daemon参数用于控制Kafka进程后台不挂断运行。
sh /data/kafka/kafka_2.13-2.4.0/bin/kafka-server-start.sh -daemon /data/kafka/kafka_2.13-2.4.0/config/server.properties
CentOS-7 安装Canal
CentOS 安装Canal 核心步骤
mkdir /data/canal
cd /data/canal
# 这里注意一点,Github在国内被墙,下载速度极慢,可以先用其他下载工具下载完再上传到服务器中
wget https://github.com/alibaba/canal/releases/download/canal-1.1.6/canal.deployer-1.1.6.tar.gz
tar -zxvf canal.deployer-1.1.6.tar.gz
Canal 解压后目录说明:
- bin # 运维脚本
- conf # 配置文件
canal_local.properties # canal本地配置,一般不需要动
canal.properties # canal服务配置
logback.xml # logback日志配置
metrics # 度量统计配置
spring # spring-实例配置,主要和binlog位置计算、一些策略配置相关,可以在canal.properties选用其中的任意一个配置文件
example # 实例配置文件夹,一般认为单个数据库对应一个独立的实例配置文件夹
instance.properties # 实例配置,一般指单个数据库的配置
- lib # 服务依赖包
- logs # 日志文件输出目录
在开发和测试环境建议把logback.xml的日志级别修改为DEBUG方便定位问题。这里需要关注canal.properties和instance.properties两个配置文件。canal.properties文件中,需要修改:
去掉canal.instance.parser.parallelThreadSize = 16这个配置项的注释,也就是启用此配置项,和实例解析器的线程数相关,不配置会表现为阻塞或者不进行解析。
canal.serverMode配置项指定为kafka,可选值有tcp、kafka和rocketmq(master分支或者最新的的v1.1.5-alpha-1版本,可以选用rabbitmq),默认是kafka。
canal.mq.servers配置需要指定为Kafka服务或者集群Broker的地址,这里配置为127.0.0.1:9092
canal.mq.servers在不同的canal.serverMode有不同的意义。
kafka模式下,指Kafka服务或者集群Broker的地址,也就是bootstrap.servers
rocketmq模式下,指NameServer列表
rabbitmq模式下,指RabbitMQ服务的Host和Port
本文Kafka实例配置:
找到canal.deployer-1.1.6/conf目录下的canal.properties配置文件:
# tcp, kafka, RocketMQ 这里选择kafka模式
canal.serverMode = kafka
# 解析器的线程数,打开此配置,不打开则会出现阻塞或者不进行解析的情况
canal.instance.parser.parallelThreadSize = 16
# 配置MQ的服务地址,这里配置的是kafka对应的地址和端口
canal.mq.servers = 127.0.0.1:9092
# 配置instance,在conf目录下要有example同名的目录,可以配置多个
canal.destinations = example
其他配置项可以参考下面两个官方Wiki的链接:
Canal-Kafka-RocketMQ-QuickStart
AdminGuide
instance.properties一般指一个数据库实例的配置,Canal架构支持一个Canal服务实例,处理多个数据库实例的binlog异步解析。instance.properties需要修改的配置项主要包括:
canal.instance.mysql.slaveId需要配置一个和Master节点的服务ID完全不同的值,这里笔者配置为654321。
配置数据源实例,包括地址、用户、密码和目标数据库:
canal.instance.master.address,这里指定为127.0.0.1:3306。
canal.instance.dbUsername,这里指定为canal。
canal.instance.dbPassword,这里指定为QWqw12!@。
新增canal.instance.defaultDatabaseName,这里指定为test(需要在MySQL中建立一个test数据库,见前面的流程)。
Kafka相关配置,这里暂时使用静态topic和单个partition:
canal.mq.topic,这里指定为test,也就是解析完的binlog结构化数据会发送到Kafka的命名为test的topic中。
canal.mq.partition,这里指定为0。
本文MySQL8实例配置:
配置instance,找到/conf/example/instance.properties配置文件:
## mysql serverId , v1.0.26+ will autoGen(自动生成,不需配置)
# canal.instance.mysql.slaveId=0
# position info
canal.instance.master.address=127.0.0.1:3306
# 在Mysql执行 SHOW MASTER STATUS;查看当前数据库的binlog
canal.instance.master.journal.name=mysql-bin.000006
canal.instance.master.position=4596
# 账号密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=Canal@****
canal.instance.connectionCharset = UTF-8
#MQ队列名称
canal.mq.topic=canaltopic
#单队列模式的分区下标
canal.mq.partition=0
配置工作做好之后,可以启动Canal服务:
sh /data/canal/bin/startup.sh
# 查看服务日志
tail -100f /data/canal/logs/canal/canal
# 查看实例日志 -- 一般情况下,关注实例日志即可
tail -100f /data/canal/logs/example/example.log
启动正常后,见实例日志如下:

数据演示
在test数据库创建一个订单表
use `test`;
CREATE TABLE `order`
(
id BIGINT UNIQUE PRIMARY KEY AUTO_INCREMENT COMMENT '主键',
order_id VARCHAR(64) NOT NULL COMMENT '订单ID',
amount DECIMAL(10, 2) NOT NULL DEFAULT 0 COMMENT '订单金额',
create_time DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
UNIQUE uniq_order_id (`order_id`)
) COMMENT '订单表';
INSERT INTO `order`(order_id, amount) VALUES ('20230207093012', 1999);
UPDATE `order` SET amount = 2000 WHERE order_id = '20230207093012';
DELETE FROM `order` WHERE order_id = '20230207093012';
利用Kafka的kafka-console-consumer或者Kafka Tools查看test这个topic的数据:
sh /data/kafka/kafka_2.13-2.4.0/bin/kafka-console-consumer.sh --bootstrap-server 127.0.0.1:9092 --from-beginning --topic test

第5章 基于Canal 和RabbitMQ,实现MySQL的Binlog 近实时同步
Docker 安装MySQL
请参考:Docker 安装MySQL
Docker 安装RabbitMQ
请参考:Docker 安装RabbitMQ
RabbitMQ 增加交换机和队列
- 添加交换机 canal_exchange
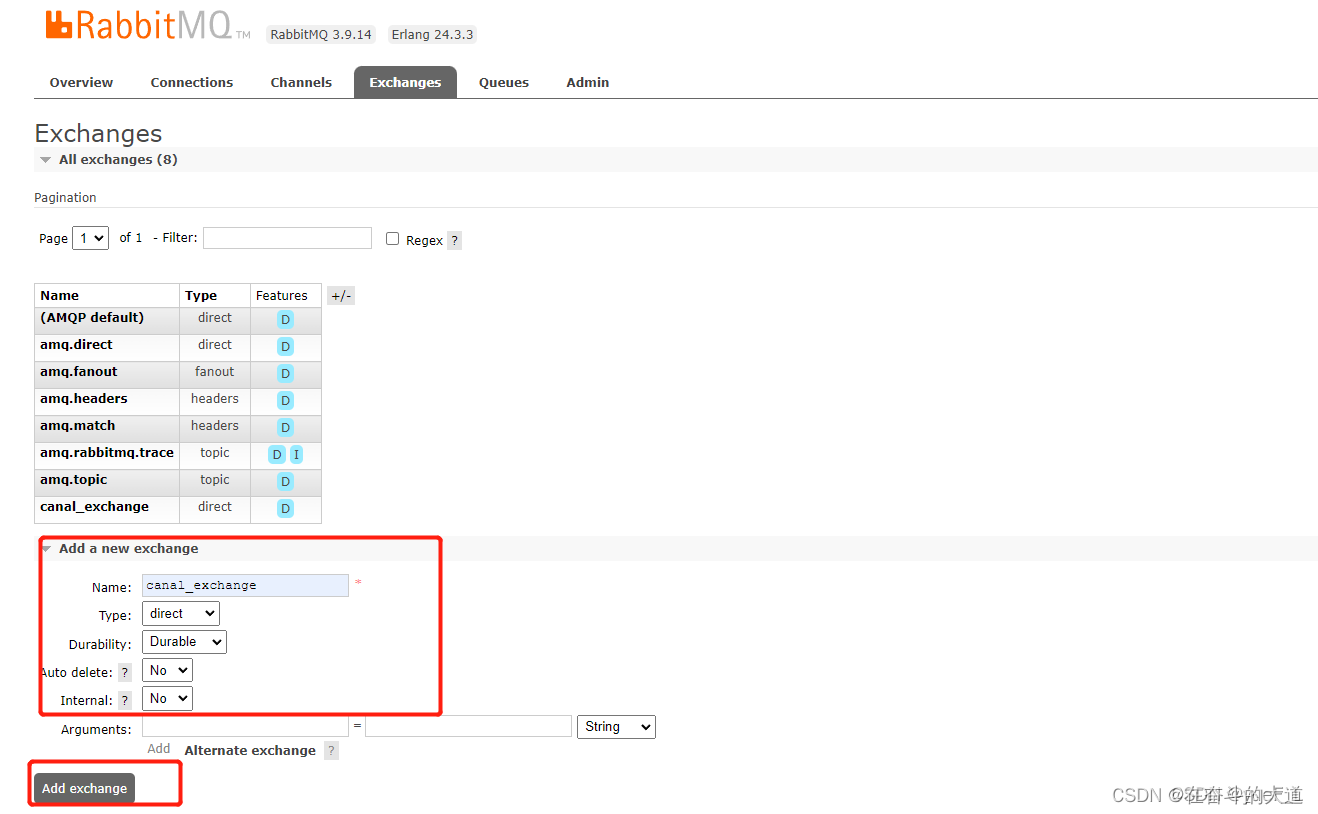
- 添加队列 canal_queue
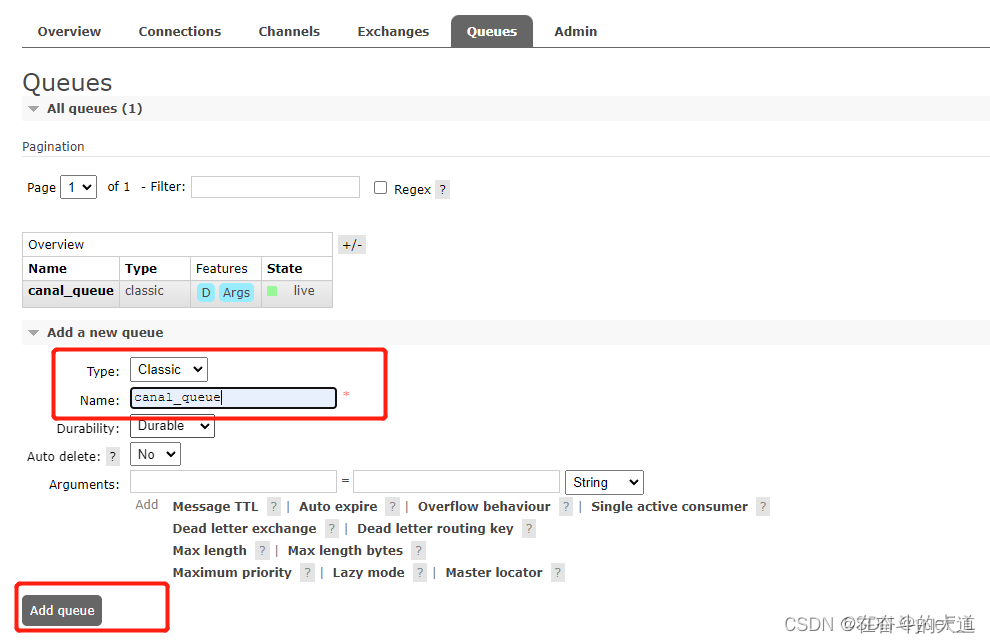
- 队列绑定交换机
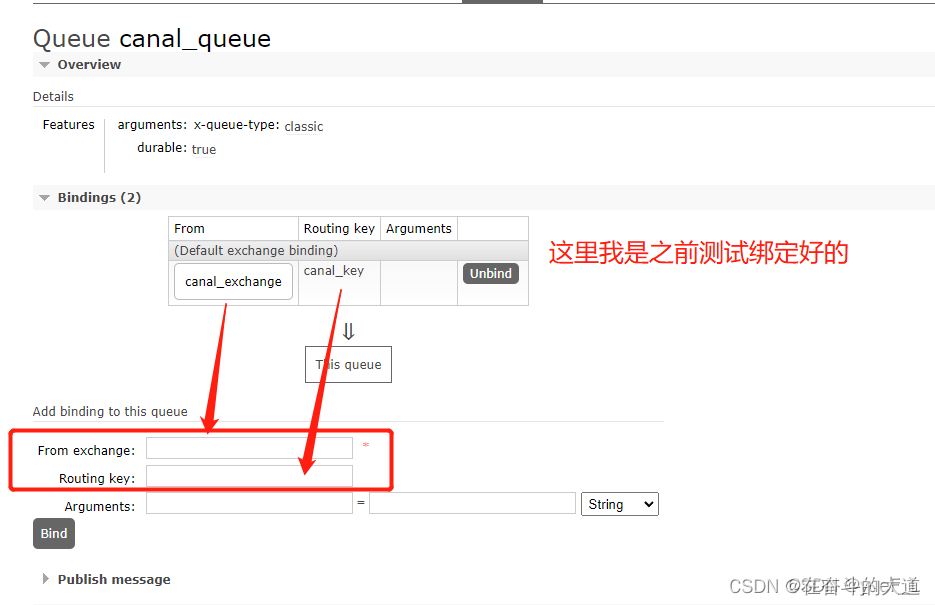
CentOS-7 安装Canal
centos-7 解压安装Canal与上 一章节一致,顾不在做详细描述***。本章节重点讲解Canal 配置RabbitMQ 参数配置。
Canal Server配置
需要配置的东西就两项,一个是监听数据库配置,另一个是 RabbitMQ 连接配置。
instance.properties
监听数据库配置
cd /example 目录下


canal.properties
配置 Canal 服务方式为 RabbitMQ 和连接配置
进入到conf文件,打开canal.properties
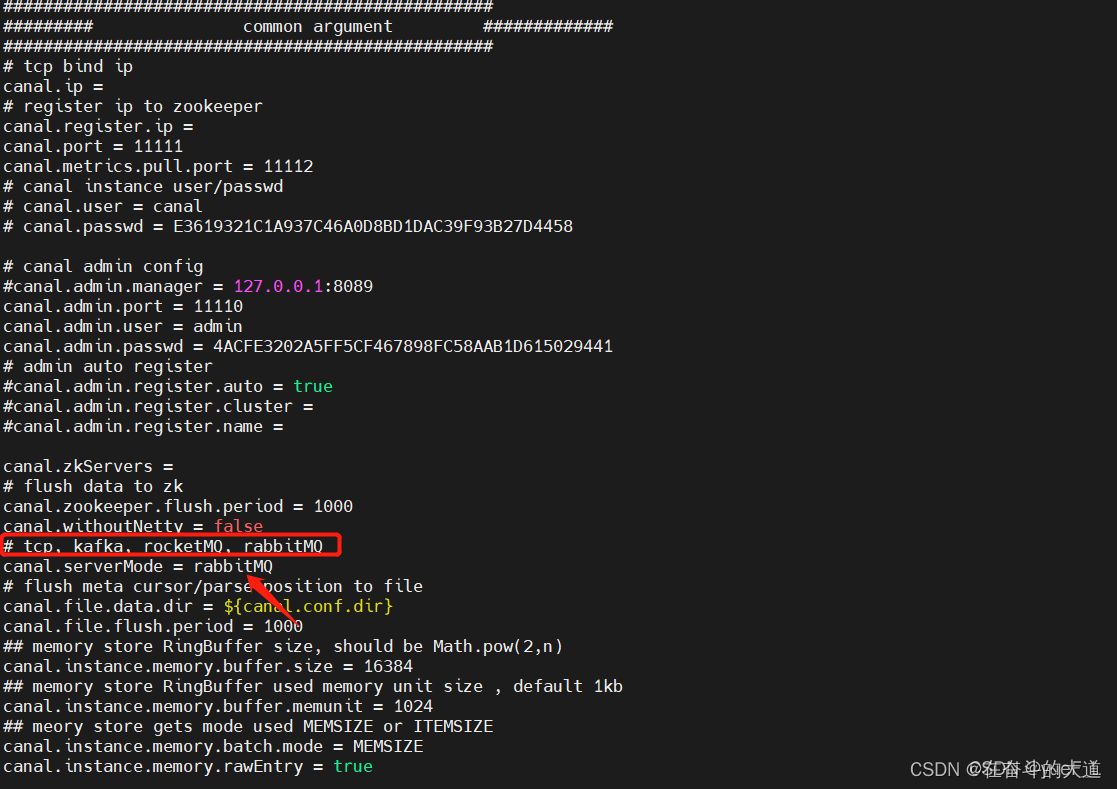
serverMode(服务模式)修改为rabbitMQ,默认TCP.

RabbitMQ 服务相关参数设置。
第6章 Canal API
快速开始
第一步:maven 添加相关jar包依赖
<dependency>
<groupId>com.alibaba.otter</groupId>
<artifactId>canal.client</artifactId>
<version>1.1.0</version>
</dependency>
第二步:编写main方法测试
import java.net.InetSocketAddress;
import java.util.List;
import com.alibaba.otter.canal.client.CanalConnectors;
import com.alibaba.otter.canal.client.CanalConnector;
import com.alibaba.otter.canal.common.utils.AddressUtils;
import com.alibaba.otter.canal.protocol.Message;
import com.alibaba.otter.canal.protocol.CanalEntry.Column;
import com.alibaba.otter.canal.protocol.CanalEntry.Entry;
import com.alibaba.otter.canal.protocol.CanalEntry.EntryType;
import com.alibaba.otter.canal.protocol.CanalEntry.EventType;
import com.alibaba.otter.canal.protocol.CanalEntry.RowChange;
import com.alibaba.otter.canal.protocol.CanalEntry.RowData;
public class SimpleCanalClientExample {
public static void main(String args[]) {
// 创建链接
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),
11111), "example", "", "");
int batchSize = 1000;
int emptyCount = 0;
try {
connector.connect();
connector.subscribe(".*\\..*");
connector.rollback();
int totalEmptyCount = 120;
while (emptyCount < totalEmptyCount) {
Message message = connector.getWithoutAck(batchSize); // 获取指定数量的数据
long batchId = message.getId();
int size = message.getEntries().size();
if (batchId == -1 || size == 0) {
emptyCount++;
System.out.println("empty count : " + emptyCount);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
}
} else {
emptyCount = 0;
// System.out.printf("message[batchId=%s,size=%s] \n", batchId, size);
printEntry(message.getEntries());
}
connector.ack(batchId); // 提交确认
// connector.rollback(batchId); // 处理失败, 回滚数据
}
System.out.println("empty too many times, exit");
} finally {
connector.disconnect();
}
}
private static void printEntry(List<Entry> entrys) {
for (Entry entry : entrys) {
if (entry.getEntryType() == EntryType.TRANSACTIONBEGIN || entry.getEntryType() == EntryType.TRANSACTIONEND) {
continue;
}
RowChange rowChage = null;
try {
rowChage = RowChange.parseFrom(entry.getStoreValue());
} catch (Exception e) {
throw new RuntimeException("ERROR ## parser of eromanga-event has an error , data:" + entry.toString(),
e);
}
EventType eventType = rowChage.getEventType();
System.out.println(String.format("================> binlog[%s:%s] , name[%s,%s] , eventType : %s",
entry.getHeader().getLogfileName(), entry.getHeader().getLogfileOffset(),
entry.getHeader().getSchemaName(), entry.getHeader().getTableName(),
eventType));
for (RowData rowData : rowChage.getRowDatasList()) {
if (eventType == EventType.DELETE) {
printColumn(rowData.getBeforeColumnsList());
} else if (eventType == EventType.INSERT) {
printColumn(rowData.getAfterColumnsList());
} else {
System.out.println("-------> before");
printColumn(rowData.getBeforeColumnsList());
System.out.println("-------> after");
printColumn(rowData.getAfterColumnsList());
}
}
}
}
private static void printColumn(List<Column> columns) {
for (Column column : columns) {
System.out.println(column.getName() + " : " + column.getValue() + " update=" + column.getUpdated());
}
}
}
第三步:启动Canal 服务
第四步: 运行Canal 客户端的main 方法,控制台输出如下信息:
empty count : 1
empty count : 2
empty count : 3
empty count : 4
含义:数据库无变更记录。
第五步:模拟数据库变更操作
mysql> use test;
Database changed
mysql> CREATE TABLE `xdual` (
-> `ID` int(11) NOT NULL AUTO_INCREMENT,
-> `X` timestamp NOT NULL DEFAULT CURRENT_TIMESTAMP,
-> PRIMARY KEY (`ID`)
-> ) ENGINE=InnoDB AUTO_INCREMENT=3 DEFAULT CHARSET=utf8 ;
Query OK, 0 rows affected (0.06 sec)
mysql> insert into xdual(id,x) values(null,now());Query OK, 1 row affected (0.06 sec)
再次查看Canal 客户端,控制台输出信息:
empty count : 1
empty count : 2
empty count : 3
empty count : 4
================> binlog[mysql-bin.001946:313661577] , name[test,xdual] , eventType : INSERT
ID : 4 update=true
X : 2013-02-05 23:29:46 update=true
Canal API 文档说明
Canal 类设计
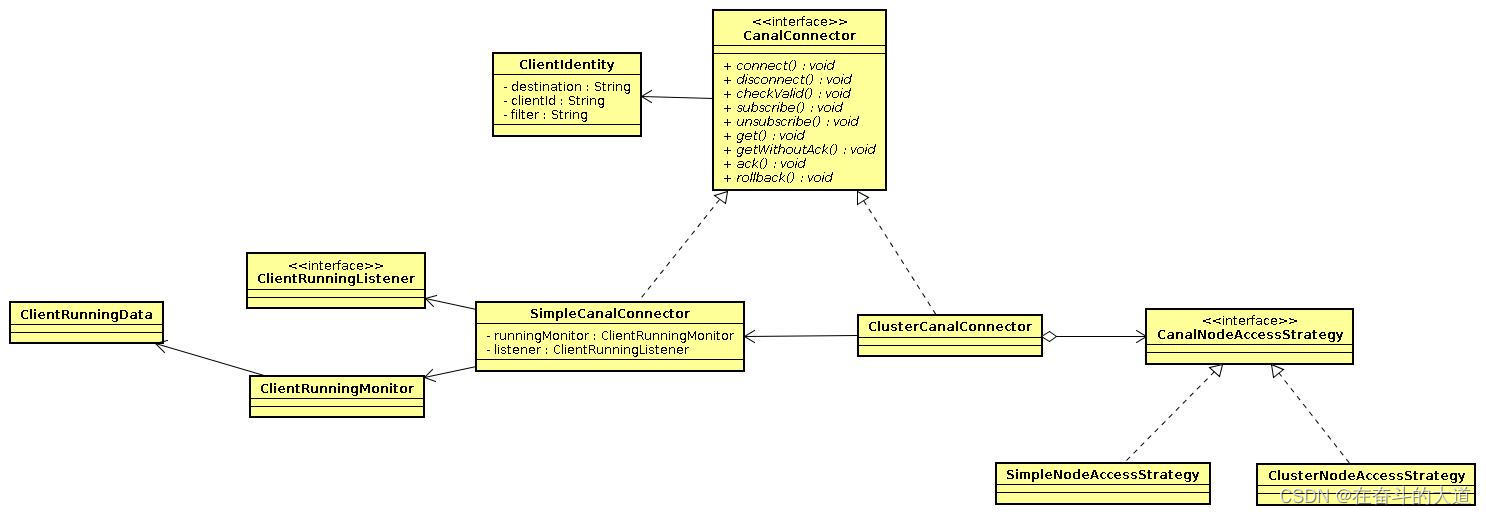
大致分为几部分:
ClientIdentitycanal client和server交互之间的身份标识,目前clientId写死为1001. (目前canal server上的一个instance只能有一个client消费,clientId的设计是为1个instance多client消费模式而预留的,暂时不需要理会)
CanalConnectorSimpleCanalConnector/ClusterCanalConnector : 两种connector的实现,simple针对的是简单的ip直连模式,cluster针对多ip的模式,可依赖CanalNodeAccessStrategy进行failover控制
CanalNodeAccessStrategySimpleNodeAccessStrategy/ClusterNodeAccessStrategy:两种failover的实现,simple针对给定的初始ip列表进行failover选择,cluster基于zookeeper上的cluster节点动态选择正在运行的canal server.
ClientRunningMonitor/ClientRunningListener/ClientRunningDataclient running相关控制,主要为解决client自身的failover机制。canal client允许同时启动多个canal client,通过running机制,可保证只有一个client在工作,其他client做为冷备. 当运行中的client挂了,running会控制让冷备中的client转为工作模式,这样就可以确保canal client也不会是单点. 保证整个系统的高可用性.
javadoc查看:
- CanalConnector :http://alibaba.github.io/canal/apidocs/1.0.13/com/alibaba/otter/canal/client/CanalConnector.html
Canal server/client交互协议

具体的网络协议格式,可参见:CanalProtocol.proto
Canal get/ack/rollback协议
get/ack/rollback协议介绍:
Message getWithoutAck(int batchSize),允许指定batchSize,一次可以获取多条,每次返回的对象为Message,包含的内容为:a. batch id 唯一标识b. entries 具体的数据对象,可参见下面的数据介绍
getWithoutAck(int batchSize, Long timeout, TimeUnit unit),相比于getWithoutAck(int batchSize),允许设定获取数据的timeout超时时间a. 拿够batchSize条记录或者超过timeout时间b. timeout=0,阻塞等到足够的batchSize
void rollback(long batchId),顾命思议,回滚上次的get请求,重新获取数据。基于get获取的batchId进行提交,避免误操作
void ack(long batchId),顾命思议,确认已经消费成功,通知server删除数据。基于get获取的batchId进行提交,避免误操作
canal的get/ack/rollback协议和常规的jms协议有所不同,允许get/ack异步处理,比如可以连续调用get多次,后续异步按顺序提交ack/rollback,项目中称之为流式api.
流式api设计的好处:
get/ack异步化,减少因ack带来的网络延迟和操作成本 (99%的状态都是处于正常状态,异常的rollback属于个别情况,没必要为个别的case牺牲整个性能)
get获取数据后,业务消费存在瓶颈或者需要多进程/多线程消费时,可以不停的轮询get数据,不停的往后发送任务,提高并行化. (作者在实际业务中的一个case:业务数据消费需要跨中美网络,所以一次操作基本在200ms以上,为了减少延迟,所以需要实施并行化)

每次get操作都会在meta中产生一个mark,mark标记会递增,保证运行过程中mark的唯一性
每次的get操作,都会在上一次的mark操作记录的cursor继续往后取,如果mark不存在,则在last ack cursor继续往后取
进行ack时,需要按照mark的顺序进行数序ack,不能跳跃ack. ack会删除当前的mark标记,并将对应的mark位置更新为last ack cursor
一旦出现异常情况,客户端可发起rollback情况,重新置位:删除所有的mark, 清理get请求位置,下次请求会从last ack cursor继续往后取
流式api带来的异步响应模型:
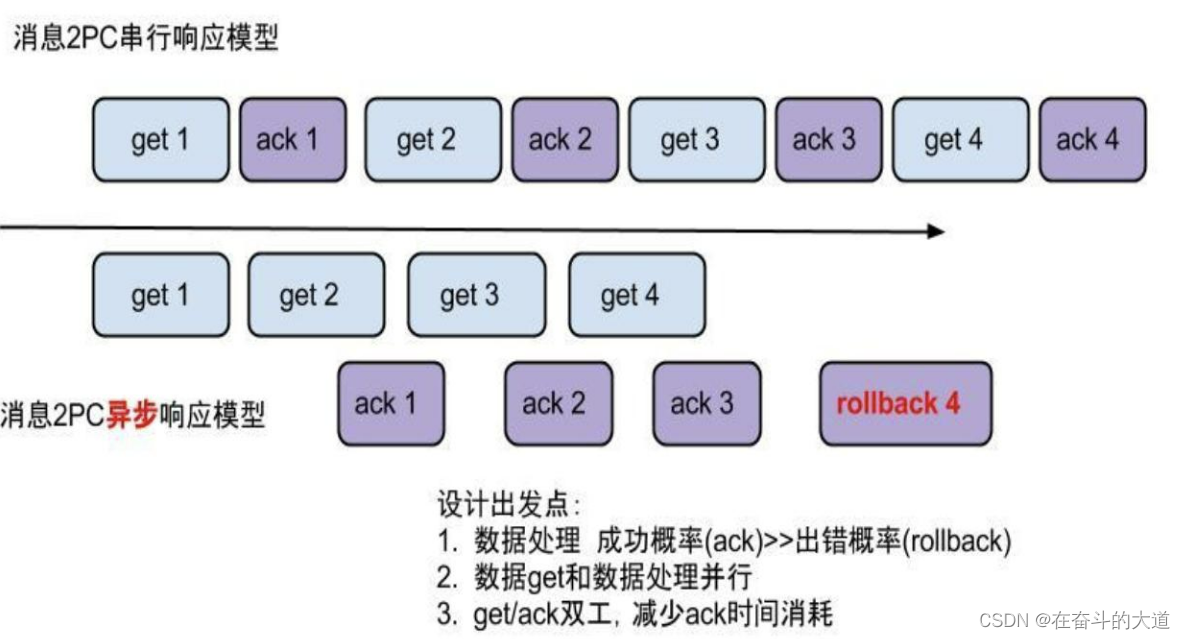
数据对象格式简单介绍:EntryProtocol.proto
Entry
Header
logfileName [binlog文件名]
logfileOffset [binlog position]
executeTime [binlog里记录变更发生的时间戳,精确到秒]
schemaName
tableName
eventType [insert/update/delete类型]
entryType [事务头BEGIN/事务尾END/数据ROWDATA]
storeValue [byte数据,可展开,对应的类型为RowChange]
RowChange
isDdl [是否是ddl变更操作,比如create table/drop table]
sql [具体的ddl sql]
rowDatas [具体insert/update/delete的变更数据,可为多条,1个binlog event事件可对应多条变更,比如批处理]
beforeColumns [Column类型的数组,变更前的数据字段]
afterColumns [Column类型的数组,变更后的数据字段]
Column
index
sqlType [jdbc type]
name [column name]
isKey [是否为主键]
updated [是否发生过变更]
isNull [值是否为null]
value [具体的内容,注意为string文本]
说明:
可以提供数据库变更前和变更后的字段内容,针对binlog中没有的name,isKey等信息进行补全
可以提供ddl的变更语句
insert只有after columns, delete只有before columns,而update则会有before / after columns数据.
快速开始代码剖析
1. 创建Connector
a. 创建SimpleCanalConnector (直连ip,不支持server/client的failover机制)
CanalConnector connector = CanalConnectors.newSingleConnector(new InetSocketAddress(AddressUtils.getHostIp(),11111), destination, "", "");
b. 创建ClusterCanalConnector (基于zookeeper获取canal server ip,支持server/client的failover机制)
CanalConnector connector = CanalConnectors.newClusterConnector("10.20.144.51:2181", destination, "", "");
c. 创建ClusterCanalConnector (基于固定canal server的地址,支持固定的server ip的failover机制,不支持client的failover机制
CanalConnector connector = CanalConnectors.newClusterConnector(Arrays.asList(new InetSocketAddress(AddressUtils.getHostIp(),11111)), destination,"", "");
2. get/ack/rollback使用

3. RowData数据处理

第7章 Canal 适配器
基本说明
canal 1.1.1版本之后,提供了适配器功能,可将canal server的数据直接输出到目的地,不需要用户编写客户端。
温馨提示:特殊功能需求,还需要用户编写客户端实现
适配器整体结构
client-adapter分为适配器和启动器两部分,每个适配器会将自己所需的依赖打成一个包, 以SPI的方式让启动器动态加载。
启动器为 SpringBoot 项目, 支持canal-client启动的同时提供相关REST管理接口, 运行目录结构为:
- bin
restart.sh
startup.bat
startup.sh
stop.sh
- lib
...
- plugin
client-adapter.logger-1.1.1-jar-with-dependencies.jar
client-adapter.hbase-1.1.1-jar-with-dependencies.jar
...
- conf
application.yml
- hbase
mytest_person2.yml
- logs
以上目录结构最终会打包成 canal-adapter-*.tar.gz 压缩包
源码结构解析
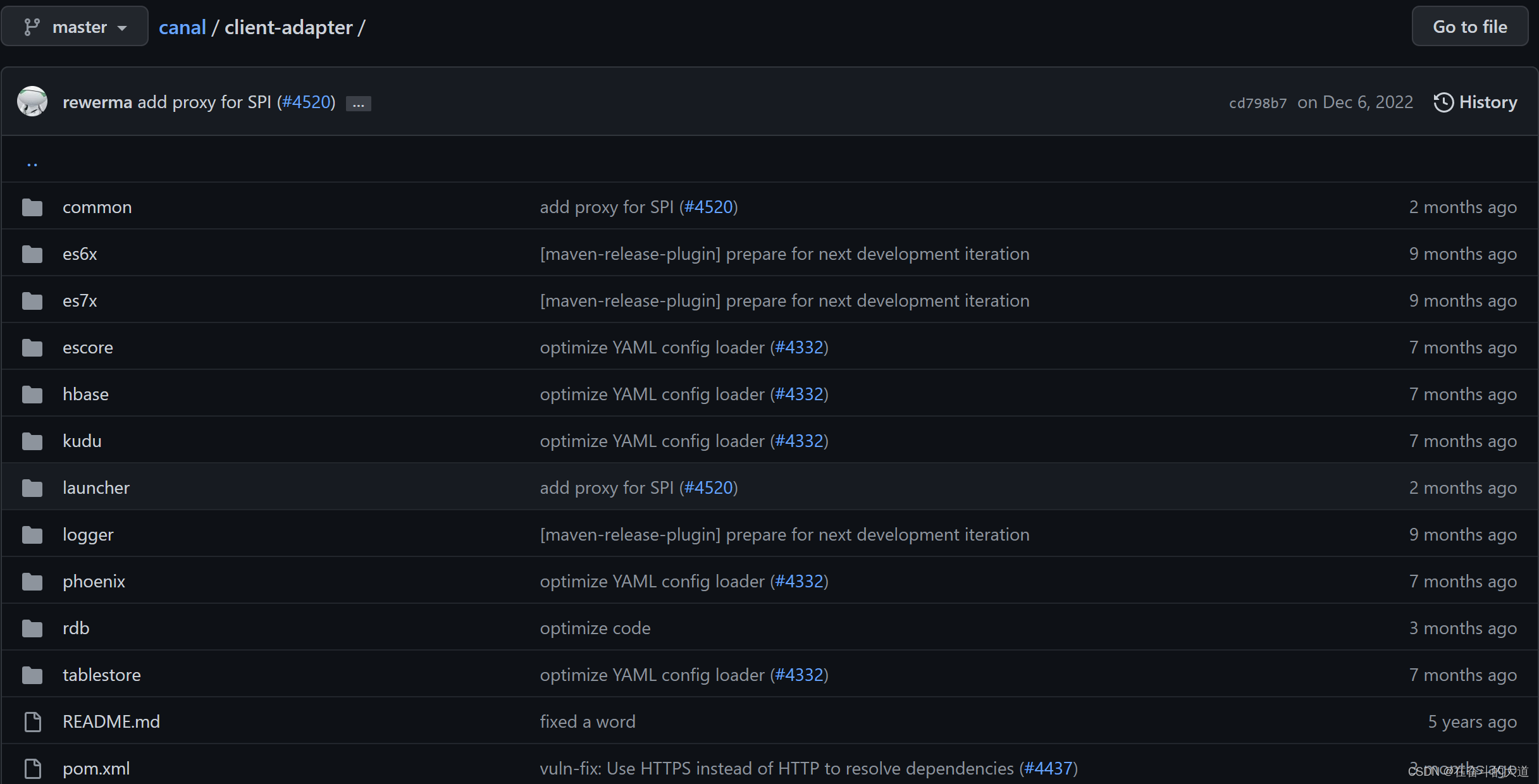
launcher:启动器
logger:日志适配器
rdb:支持jdbc的关系型数据库适配器(mysql、oracle、postgress、sqlserver等)
hbase:hbase适配器
kudu:kudu适配器
Canal适配器之启动
Canal 适配器启动之配置文件application.yml
server:
port: 8081
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
default-property-inclusion: non_null
canal.conf:
mode: tcp #tcp kafka rocketMQ rabbitMQ #客户端消费模式,对应下面的consumerProperties
flatMessage: true #是否以json字符串传递数据,仅对mq生效
zookeeperHosts: #canal server集群部署时,创建curator客户端
#tcp mode需要在consumerProperties tcp中设置
syncBatchSize: 1000 #每次同步的批数量
retries: -1 #重试次数,-1为无限次
timeout:
accessKey:
secretKey:
consumerProperties:
# canal tcp consumer #canal adapter连接的canal server
canal.tcp.server.host: 127.0.0.1:11111
canal.tcp.zookeeper.hosts:
canal.tcp.batch.size: 500
canal.tcp.username:
canal.tcp.password:
# kafka consumer #canal adapter连接的kafka
kafka.bootstrap.servers: 127.0.0.1:9092
kafka.enable.auto.commit: false
kafka.auto.commit.interval.ms: 1000
kafka.auto.offset.reset: latest
kafka.request.timeout.ms: 40000
kafka.session.timeout.ms: 30000
kafka.isolation.level: read_committed
kafka.max.poll.records: 1000
# rocketMQ consumer #canal adapter连接的rocketmq
rocketmq.namespace:
rocketmq.namesrv.addr: 127.0.0.1:9876
rocketmq.batch.size: 1000
rocketmq.enable.message.trace: false
rocketmq.customized.trace.topic:
rocketmq.access.channel:
rocketmq.subscribe.filter:
# rabbitMQ consumer #canal adapter连接的rabbitmq
rabbitmq.host:
rabbitmq.virtual.host:
rabbitmq.username:
rabbitmq.password:
rabbitmq.resource.ownerId:
# srcDataSources:
# defaultDS:
# url: jdbc:mysql://127.0.0.1:3306/mytest?useUnicode=true
# username: root
# password: 121212
canalAdapters:
- instance: example # canal instance Name or mq topic name
# 注意:instance name、topic name不支持通配符匹配
groups:
- groupId: g1 #一份数据可被多个groupId消费
#不同groupId并发执行,
#同一groupId内的adapters顺序执行
outerAdapters:
- name: logger #输出到日志
# - name: rdb #输出到rdb(关系型数据库
# key: mysql1 #输出到mysql数据库
# properties:
# jdbc.driverClassName: com.mysql.jdbc.Driver
# jdbc.url: jdbc:mysql://127.0.0.1:3306/mytest2?useUnicode=true
# jdbc.username: root
# jdbc.password: 121212
# druid.stat.enable: false
# druid.stat.slowSqlMillis: 1000
# - name: rdb
# key: oracle1 #输出到oracle数据库
# properties:
# jdbc.driverClassName: oracle.jdbc.OracleDriver
# jdbc.url: jdbc:oracle:thin:@localhost:49161:XE
# jdbc.username: mytest
# jdbc.password: m121212
# - name: rdb
# key: postgres1 #输出到postgress数据库
# properties:
# jdbc.driverClassName: org.postgresql.Driver
# jdbc.url: jdbc:postgresql://localhost:5432/postgres
# jdbc.username: postgres
# jdbc.password: 121212
# threads: 1
# commitSize: 3000
# - name: hbase #输出到hbase
# properties:
# hbase.zookeeper.quorum: 127.0.0.1
# hbase.zookeeper.property.clientPort: 2181
# zookeeper.znode.parent: /hbase
# - name: es #输出到es
# hosts: 127.0.0.1:9300 # 127.0.0.1:9200 for rest mode
# properties:
# mode: transport # or rest
# # security.auth: test:123456 # only used for rest mode
# cluster.name: elasticsearch
# - name: kudu #输出到kudu
# key: kudu
# properties:
# kudu.master.address: 127.0.0.1 # ',' split multi address
# - name: phoenix #输出到phoenix
# key: phoenix
# properties:
# jdbc.driverClassName: org.apache.phoenix.jdbc.PhoenixDriver
# jdbc.url: jdbc:phoenix:127.0.0.1:2181:/hbase/db
# jdbc.username:
# jdbc.password:
Canal适配器实例
业务需求:商品表新增商品数据实时同步ES搜索引擎。
解决方案:基于Canal监听MySQL-binlog 日志信息变化,通过Canal-Adapter 读取Canal 数据变更记录,同时写入ES搜索引擎。
1、软件版本
MySQL:8.x
canal:1.1.6
adapter:1.1.6
elasticsearch:7.4.2
2、MySQL开启binlog
[mysqld]
log-bin=mysql-bin # 开启 binlog
binlog-format=ROW # 选择 ROW 模式
server_id=1 # 配置 MySQL replaction 需要定义,不要和 canal 的 slaveId 重复
# 是否开启binlog
show variables like 'log_bin';
# 结果
log_bin ON
# binlog模式
show variables like 'binlog_format';
# 结果
binlog_format ROW
# 创建用户canal及密码设置
CREATE USER canal IDENTIFIED BY 'canal';
# 赋权
GRANT SELECT, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'canal'@'%';
# 刷新生效
FLUSH PRIVILEGES;
3、下载canal及adapter
# canal-server
https://github.com/alibaba/canal/releases/download/canal-1.1.6/canal.deployer-1.1.6.tar.gz
# canal-adapter
https://github.com/alibaba/canal/releases/download/canal-1.1.6/canal.adapter-1.1.6.tar.gz
4、编辑canal配置文件
vi conf/example/instance.properties
此处只展示修改的配置
# 伪装成从库的slaveId,不能与MySQL重复
canal.instance.mysql.slaveId=1234
# 数据库的ip:端口
canal.instance.master.address=127.0.0.1:3306
# 数据库用户名密码
canal.instance.dbUsername=canal
canal.instance.dbPassword=canal
5、启动canal
cd bin
sh startup.sh
如遇到如下报错
OpenJDK 64-Bit Server VM warning: ignoring option PermSize=96m; support was removed in 8.0
OpenJDK 64-Bit Server VM warning: ignoring option MaxPermSize=256m; support was removed in 8.0
OpenJDK 64-Bit Server VM warning: UseCMSCompactAtFullCollection is deprecated and will likely be removed in a future release.
The stack size specified is too small, Specify at least 384k
Error: Could not create the Java Virtual Machine.
Error: A fatal exception has occurred. Program will exit.
解决办法:调整startup.sh脚本的-Xss参数
vi bin/startup.sh
我这里调整到-Xss512k
if [ -n "$str" ]; then
JAVA_OPTS="-server -Xms2048m -Xmx3072m -Xmn1024m -XX:SurvivorRatio=2 -XX:PermSize=96m -XX:MaxPermSize=256m -Xss512k -XX:-UseAdaptiveSizePolicy -XX:MaxTenuringThreshold=15 -XX:+DisableExplicitGC -XX:+UseConcMarkSweepGC -XX:+CMSParallelRemarkEnabled -XX:+UseCMSCompactAtFullCollection -XX:+UseFastAccessorMethods -XX:+UseCMSInitiatingOccupancyOnly -XX:+HeapDumpOnOutOfMemoryError"
else
JAVA_OPTS="-server -Xms1024m -Xmx1024m -XX:NewSize=256m -XX:MaxNewSize=256m -XX:MaxPermSize=128m "
6、编辑adapter配置文件
cd conf
vi application.yml
此处只展示修改的配置
canal.conf:
consumerProperties:
# 单机配置属性
# canal.tcp.server.host: 127.0.0.1:11111
# 此配置数据库信息与canal-server配置的数据库信息相同
srcDataSources:
defaultDs:
url: jbdc:mysql://127.0.0.1:3306/canal_test
username: canal
password: canal
# 配置 ES信息
canalAdapters:
groups:
outerAdapters:
- name: logger
- name: es7
hosts: http://127.0.0.1:9200
properties:
mode: rest
security.auth: es账号:es密码
cluster.name: es的名字
7、编辑es7 索引配置文件
cd conf/es7/
cp mytest_user.yml canal_test_order.yml
rm biz_order.yml customer.yml mytest_user.yml
vi canal_test_order.yml
dataSourceKey: defaultDS
destination: example
groupId: g1
esMapping:
_index: canal_test_order
_id: _id
# 这个必须要加,源文件没有
_type: _doc
upsert: true
# pk: id
sql: "select
a.id as _id,
a.order_no as orderNo,
a.order_name as orderName
from t_order a"
# objFields:
# _labels: array:;
etlCondition: "where a.c_time>={}"
commitBatch: 3000
8、启动Canal adapter
cd bin
sh startup.sh
查看Adapter 日志记录出现如下错误时:
java.lang.RuntimeException: java.lang.RuntimeException: java.lang.ClassCastException: com.alibaba.druid.pool.DruidDataSource cannot be cast to com.alibaba.druid.pool.DruidDataSource
at com.alibaba.otter.canal.client.adapter.es7x.ES7xAdapter.init(ES7xAdapter.java:54) ~[client-adapter.es7x-1.1.5-jar-with-dependencies.jar:na]
at com.alibaba.otter.canal.adapter.launcher.loader.CanalAdapterLoader.loadAdapter(CanalAdapterLoader.java:225) [client-adapter.launcher-1.1.5.jar:na]
at com.alibaba.otter.canal.adapter.launcher.loader.CanalAdapterLoader.init(CanalAdapterLoader.java:56) [client-adapter.launcher-1.1.5.jar:na]
at com.alibaba.otter.canal.adapter.launcher.loader.CanalAdapterService.init(CanalAdapterService.java:60) [client-adapter.launcher-1.1.5.jar:na]
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method) ~[na:1.8.0_322]
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62) ~[na:1.8.0_322]
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43) ~[na:1.8.0_322]
at java.lang.reflect.Method.invoke(Method.java:498) ~[na:1.8.0_322]
at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleElement.invoke(InitDestroyAnnotationBeanPostProcessor.java:365) [spring-beans-5.0.5.RELEASE.jar:5.0.5.RELEASE]
at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor$LifecycleMetadata.invokeInitMethods(InitDestroyAnnotationBeanPostProcessor.java:308) [spring-beans-5.0.5.RELEASE.jar:5.0.5.RELEASE]
at org.springframework.beans.factory.annotation.InitDestroyAnnotationBeanPostProcessor.postProcessBeforeInitialization(InitDestroyAnnotationBeanPostProcessor.java:135) [spring-beans-5.0.5.RELEASE.jar:5.0.5.RELEASE]
at org.springframework.beans.factory.support.AbstractAutowireCapableBeanFactory.applyBeanPostProcessorsBeforeInitialization(AbstractAutowireCapableBeanFactory.java:422) [spring-beans-5.0.5.RELEASE.jar:5.0.5.RELEASE]
解决办法,更改源码
下载canal-adapter源码
修改client-adapter/escore/pom.xml为
原
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
</dependency>
改成
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>druid</artifactId>
<scope>provided</scope>
</dependency>
重新打包编译生成client-adapter.es7x-1.1.5-jar-with-dependencies.jar
放入canal-adapter的plugin目录下,替换原jar
重新启动,Canal Adapter 日志如下
9、测试
在MySQL手动插入一条数据
adapter.log打印日志如下
2023-02-09 15:20:25.519 [pool-2-thread-1] INFO c.a.o.canal.client.adapter.logger.LoggerAdapterExample - DML: {"data":[{"id":7,"order_no":1122,"order_name":"2211"}],"database":"canal_test","destination":"example","es":1664090425000,"groupId":"g1","isDdl":false,"old":null,"pkNames":["id"],"sql":"","table":"t_order","ts":1664090425518,"type":"INSERT"}
2023-02-09 15:20:25.520 [pool-2-thread-1] DEBUG c.a.o.canal.client.adapter.es.core.service.ESSyncService - DML: {"data":[{"id":7,"order_no":1122,"order_name":"2211"}],"database":"canal_test","destination":"example","es":1664090425000,"groupId":"g1","isDdl":false,"old":null,"pkNames":["id"],"sql":"","table":"t_order","ts":1664090425518,"type":"INSERT"}
Affected indexes: canal_test_order
查看elasticsearch数据
# get 127.0.0.1:9200/canal_test_order/_search
{
"took": 0,
"timed_out": false,
"_shards": {
"total": 1,
"successful": 1,
"skipped": 0,
"failed": 0
},
"hits": {
"total": {
"value": 1,
"relation": "eq"
},
"max_score": 1.0,
"hits": [
{
"_index": "canal_test_order",
"_type": "_doc",
"_id": "1",
"_score": 1.0,
"_source": {
"orderNo": 111111,
"orderName": "11111"
}
}
]
}
}
第8章 Canal 管理平台搭建
背景
canal-admin设计上是为canal提供整体配置管理、节点运维等面向运维的功能,提供相对友好的WebUI操作界面,方便更多用户快速和安全的操作。
准备
canal-admin的限定依赖:
MySQL,用于存储配置和节点等相关数据
canal版本,要求>=1.1.4 (需要依赖canal-server提供面向admin的动态运维管理接口)
部署
- 下载 canal-admin, 访问 release 页面 , 选择需要的包下载, 如以 1.1.6 版本为例
wget https://github.com/alibaba/canal/releases/download/canal-1.1.6/canal.admin-1.1.6.tar.gz
- 解压缩
mkdir /tmp/canal-admin
tar zxvf canal.admin-$version.tar.gz -C /tmp/canal-admin
解压完成后,进入 /tmp/canal 目录,可以看到如下结构
drwxr-xr-x 6 agapple staff 204B 8 31 15:37 bin
drwxr-xr-x 8 agapple staff 272B 8 31 15:37 conf
drwxr-xr-x 90 agapple staff 3.0K 8 31 15:37 lib
drwxr-xr-x 2 agapple staff 68B 8 31 15:26 logs
- 配置修改
vi conf/application.yml
server:
port: 8089
spring:
jackson:
date-format: yyyy-MM-dd HH:mm:ss
time-zone: GMT+8
spring.datasource:
address: 127.0.0.1:3306
database: canal_manager
username: canal
password: canal
driver-class-name: com.mysql.jdbc.Driver
url: jdbc:mysql://${spring.datasource.address}/${spring.datasource.database}?useUnicode=true&characterEncoding=UTF-8&useSSL=false
hikari:
maximum-pool-size: 30
minimum-idle: 1
canal:
adminUser: admin
adminPasswd: admin
- 初始化元数据库
mysql -h127.1 -uroot -p
# 导入初始化SQL
> source conf/canal_manager.sql
a. 初始化SQL脚本里会默认创建canal_manager的数据库,建议使用root等有超级权限的账号进行初始化 b. canal_manager.sql默认会在conf目录下。
- 启动
sh bin/startup.sh
- 日志查看
vi logs/admin.log
2023-02-09 15:43:38.162 [main] INFO o.s.boot.web.embedded.tomcat.TomcatWebServer - Tomcat initialized with port(s): 8089 (http)
2023-02-09 15:43:38.180 [main] INFO org.apache.coyote.http11.Http11NioProtocol - Initializing ProtocolHandler ["http-nio-8089"]
2023-02-09 15:43:38.191 [main] INFO org.apache.catalina.core.StandardService - Starting service [Tomcat]
2023-02-09 15:43:38.194 [main] INFO org.apache.catalina.core.StandardEngine - Starting Servlet Engine: Apache Tomcat/8.5.29
....
2023-02-09 15:43:39.789 [main] INFO o.s.w.s.m.m.annotation.ExceptionHandlerExceptionResolver - Detected @ExceptionHandler methods in customExceptionHandler
2023-02-09 15:43:39.825 [main] INFO o.s.b.a.web.servlet.WelcomePageHandlerMapping - Adding welcome page: class path resource [public/index.html]
此时代表canal-admin已经启动成功,可以通过 http://127.0.0.1:8089/ 访问,默认密码:admin/123456
- 关闭
sh bin/stop.sh
- canal-server端配置
使用canal_local.properties的配置覆盖canal.properties
# register ip
canal.register.ip =
# canal admin config
canal.admin.manager = 127.0.0.1:8089
canal.admin.port = 11110
canal.admin.user = admin
canal.admin.passwd = 4ACFE3202A5FF5CF467898FC58AAB1D615029441
# admin auto register
canal.admin.register.auto = true
canal.admin.register.cluster =
启动admin-server即可。
第9章 Canal 管理平台操作指南
请参考:Canal-Admin-指南
版权归原作者 在奋斗的大道 所有, 如有侵权,请联系我们删除。