
最近公司想要开发一款有关知识图谱的构建工具,以前没有接触过neo4j的我只能现学现用。闲话少说,只撸干货😎。
一、Neo4j图数据库搭建
1.1 Neo4j概述
Neo4j是一个高性能的NOSQL图形数据库,它将结构化数据存储在网络上而不是表中。它是一个嵌入式的、基于磁盘的、具备完全的事务特性的Java持久化引擎,但是它将结构化数据存储在网络(从数学角度叫做图)上而不是表中。Neo4j也可以被看作是一个高性能的图引擎,该引擎具有成熟数据库的所有特性。程序员工作在一个面向对象的、灵活的网络结构下而不是严格、静态的表中——但是他们可以享受到具备完全的事务特性、企业级的数据库的所有好处。Neo4j因其嵌入式、高性能、轻量级等优势,越来越受到关注.
1.2 Neo4j搭建
1.2.1 tar包安装
Neo4j是基于Java的图形数据库,运行Neo4j需要启动JVM进程,因此必须安装JAVA SE的JDK。
linux服务器配置:

java版本:

neo4j版本:

(1)下载
liunx环境Neo4j下载地址:Neo4j Download Center - Neo4j Graph Data Platform社区版免费)

或者直接在服务器上使用命令下载:
curl -O http://dist.neo4j.org/neo4j-community-3.5.35-unix.tar.gz
(2)解压安装
tar -axvf neo4j-community-3.5.35-unix.tar.gz
(3)修改配置
配置文件在
neo4j-community-3.5.35/conf
目录下
修改第22行load csv时的路径,在前面加个#,可从任意路径读取文件
#dbms.directories.import=import

修改54行,去掉改行的#,可以远程通过ip访问neo4j数据库
dbms.connectors.default_listen_address=0.0.0.0

修改245行,去掉#,允许从远程url来load csv
dbms.security.allow_csv_import_from_file_urls=true

修改265行,设置neo4j可读可写
dbms.read_only=false

(4)启动
进入
neo4j-community-3.5.35/bin
目录下
启动
neo4j
/bin/sh ./neo4j start
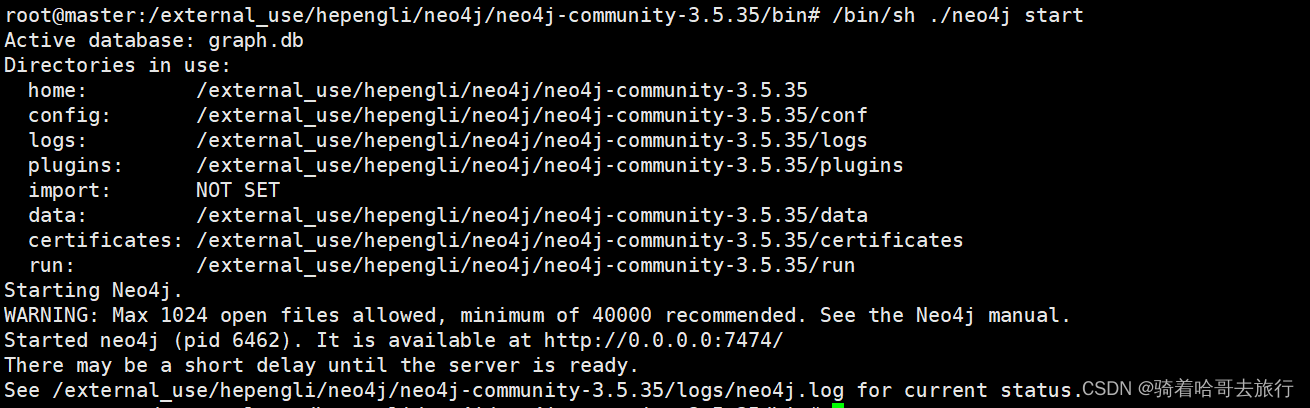
./neo4j 参数说明start启动status查看状态stop停止restart重启
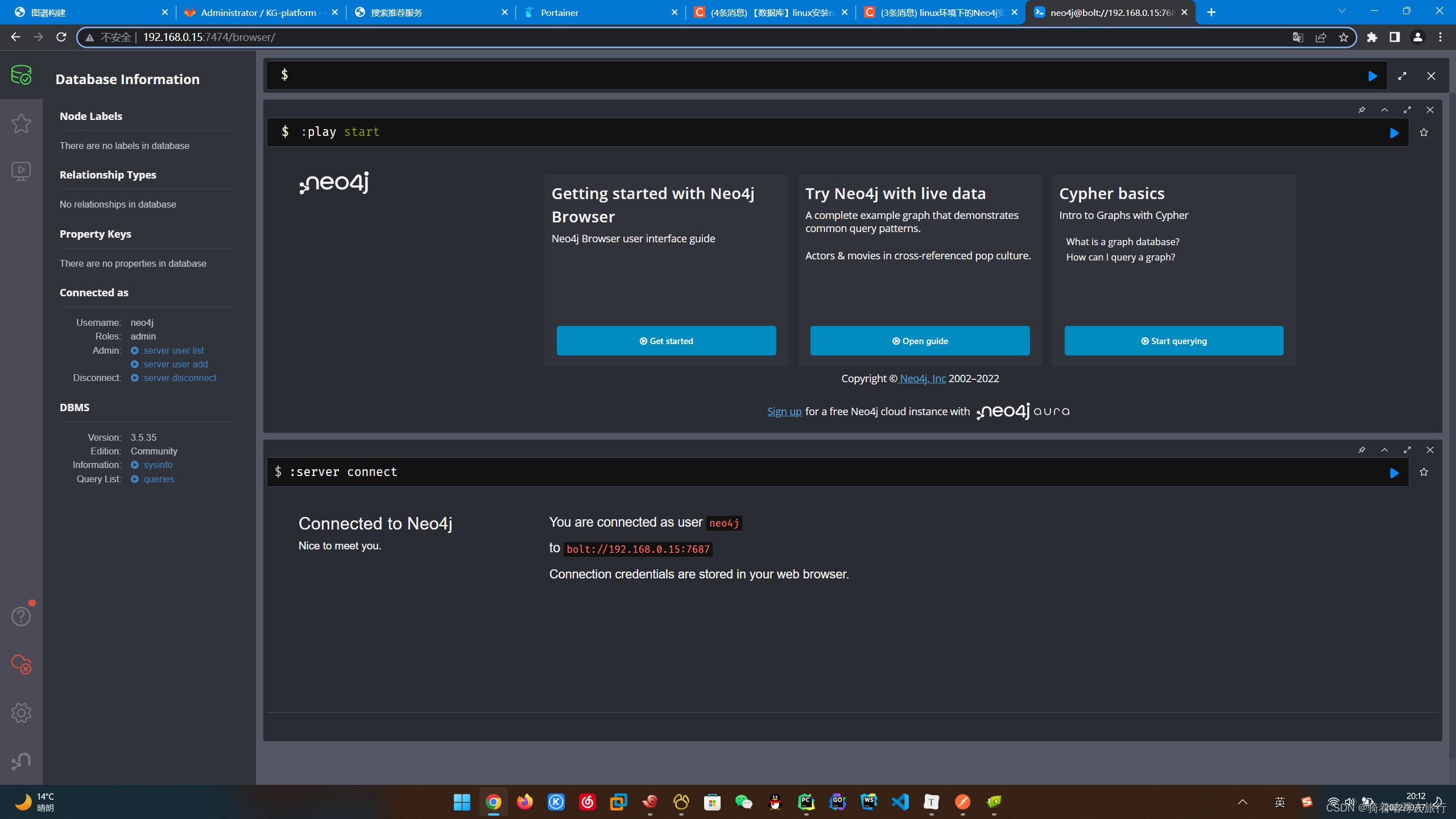
(5)客户端访问
http://服务器ip地址:7474/browser/
在浏览器访问图数据库所在的机器上的7474端口(第一次访问账号neo4j,密码neo4j,会提示修改初始密码)
1.2.2 docker安装
docker run -d --name neo4j_3.5.22 -p 7474:7474 -p 7687:7687 --restart=always -v /external_use/hepengli/neo4j/data:/data -v /external_use/hepengli/neo4j/logs:/logs -v /external_use/hepengli/neo4j/conf:/var/lib/neo4j/conf -v /external_use/hepengli/neo4j/import:/var/lib/neo4j/import neo4j:3.5.22-community
二、py2neo连接Neo4j
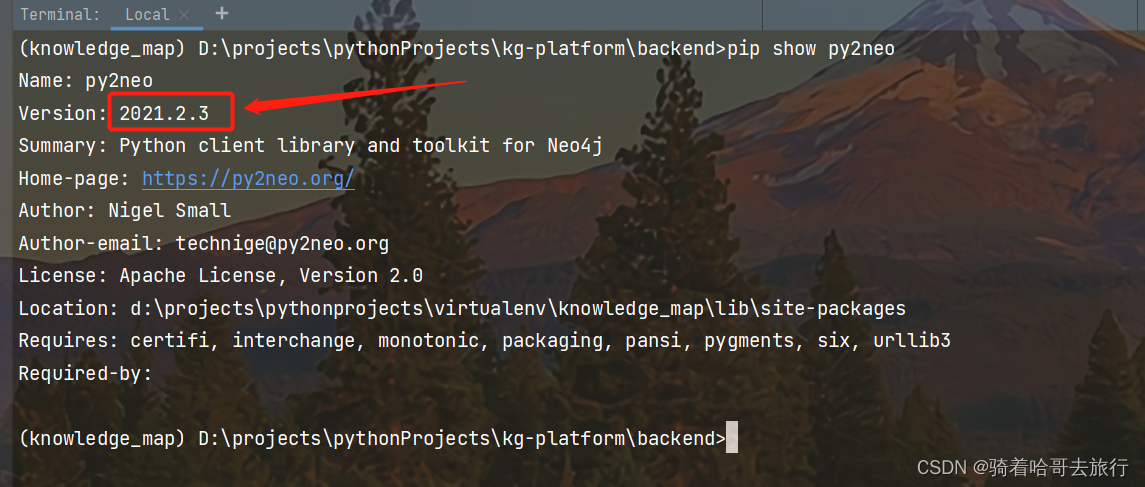
先在使用的虚拟python环境中安装py2neo库
pip install py2neo -i https://pypi.mirrors.ustc.edu.cn/simple/
在Django的settings.py配置文件中进行配置
from py2neo import Graph
...........
# ip地址 端口 neo4j账号 密码
graph = Graph("bolt://192.168.220.128:7687", auth=("neo4j", "123456")) # 连接neo4j图数据库
三、基本使用
温馨提示:以下Debugger出的数据全是小编随便写的测试数据,请不要在意。
首先对要对进行使用的地方根据实际情况进行导入

3.1 创建节点
test = Node("Person",name = "大明")
graph.create(test)

3.2 给节点添加属性
data = {
'name': 'Amy',
'age': 23
}
test.update(data)
graph.push(test)

3.3 添加关系
节点间的关系(Relationship)是有向的,所以在建立关系的时候,必须定义一个起始节点和一个结束节点。起始节点可以和结束节点是同一个点,这时候的关系就是这个点指向它自己。
relation = Relationship(test1,'喜欢',test2)
graph.create(relation)

3.4 节点删除
graph.delete(test) #删除特定节点test
graph.delete_all() #删除所有节点
3.5 查询所有节点和属性信息
MATCH (p) RETURN p LIMIT 25
graph.run("MATCH (p) RETURN p LIMIT 25").data()

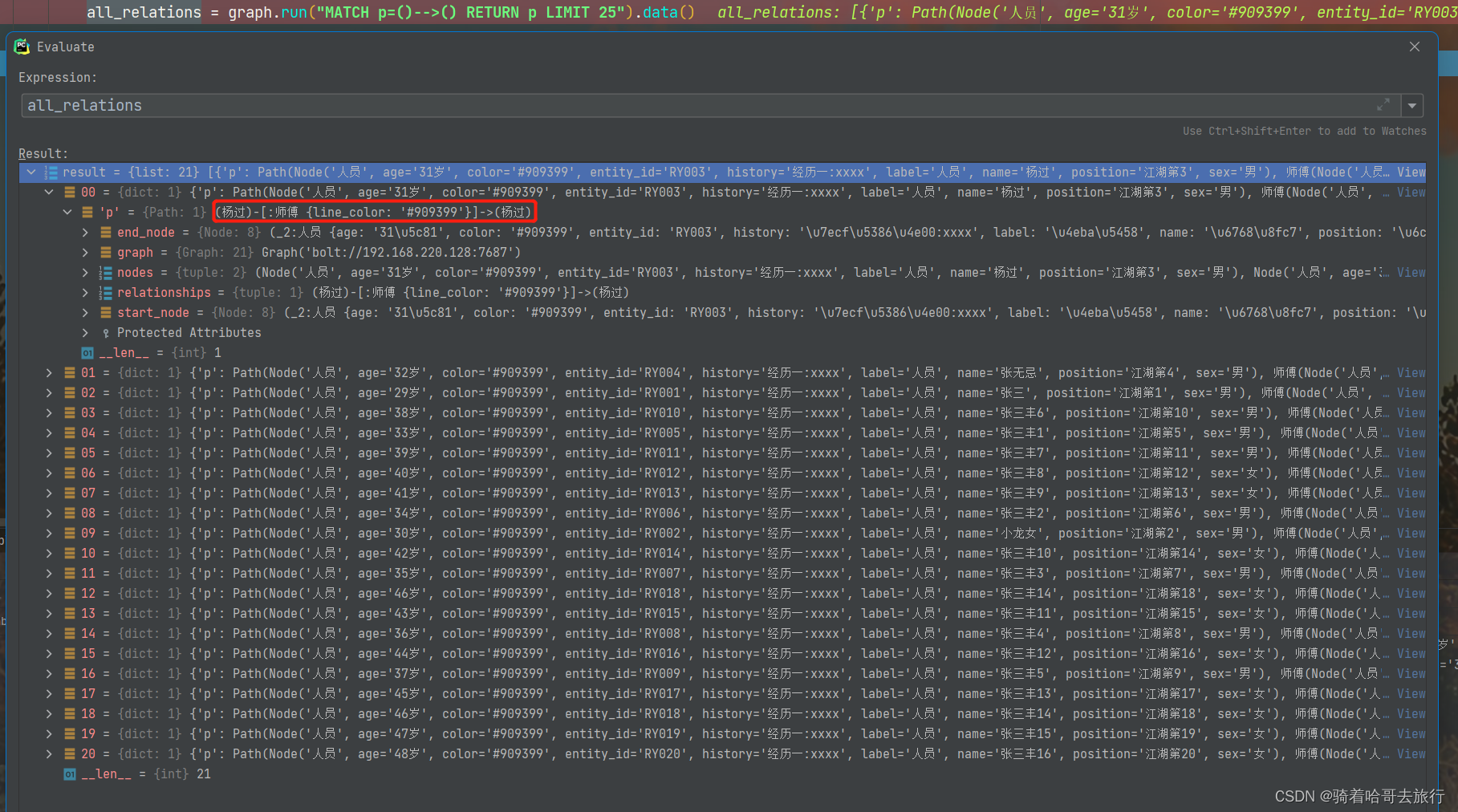
3.6 查询所有节点和属性信息以及节点之间的关系
MATCH p=()-->() RETURN p LIMIT 25
all_relations = graph.run("MATCH p=()-->() RETURN p LIMIT 25").data()
3.7 查询指定labels(如:Person)所有节点和属性信息
MATCH (p:`Person`) RETURN p LIMIT 25
graph.run(f"MATCH (p:{node_labels}) RETURN p LIMIT 25").data()

3.8 查询指定关系(如:喜欢)所有节点和属性信息以及节点之间的关系
MATCH p=()-[r:`喜欢`]->() RETURN p LIMIT 25
graph.run(f"MATCH p=()-[r:{relationship_types}]->() RETURN p LIMIT 25").data()

3.9 查询指定条件的节点和属性信息
如查询name为小王的节点信息
node_matcher = NodeMatcher(graph)
node_matcher.match().where(name=`小王`).first()
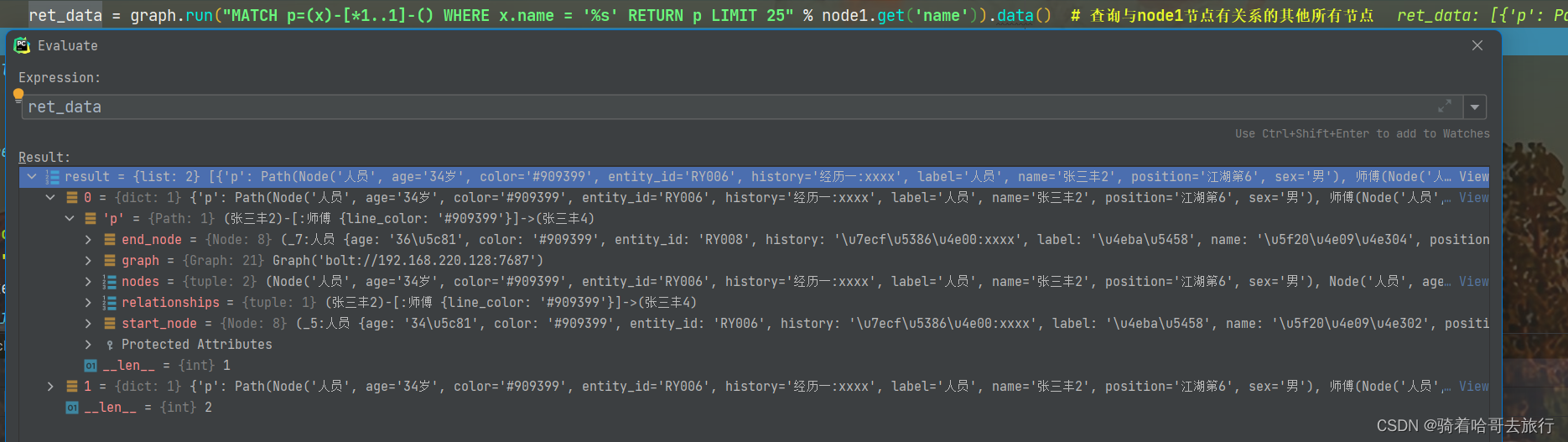
3.10 查询与指定节点有关系的其他节点
MATCH p=(x)-[*1..1]-() WHERE x.name = '小王' RETURN p LIMIT 25
graph.run("MATCH p=(x)-[*1..1]-() WHERE x.name = '%s' RETURN p LIMIT 25" % node1.get('name')).data()
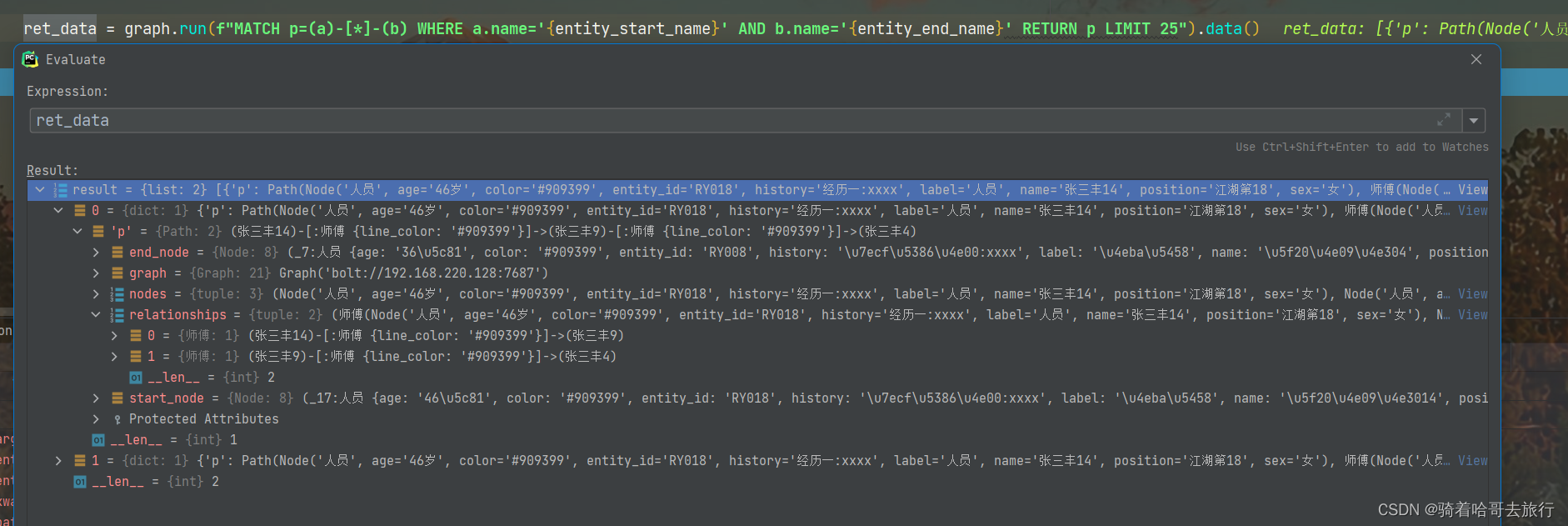
3.11 查询从一个节点到另一个节点的双向路径
MATCH p=(a)-[*]-(b) WHERE a.name='小王' AND b.name='小张' RETURN p LIMIT 25
graph.run(f"MATCH p=(a)-[*]-(b) WHERE a.name='{entity_start_name}' AND b.name='{entity_end_name}' RETURN p LIMIT 25").data()
3.12 查询从一个节点到另一个节点的单向路径
MATCH p=(a)-[*]->(b) WHERE a.name='小王' AND b.name='小张' RETURN p LIMIT 25
graph.run(f"MATCH p=(a)-[*]->(b) WHERE a.name='{entity_start_name}' AND b.name='{entity_end_name}' RETURN p LIMIT 25").data()

3.13 获取两个节点之间的关系字符串

至此,这就是我用到的一些操作,希望对您有帮助!
版权归原作者 骑着哈哥去旅行 所有, 如有侵权,请联系我们删除。