
一、基本概念
把手指放在眼前,分别闭上左、右眼,我们会发现手指与后边物体的相对位置是不同的,也即两眼所识别的两幅图像之间存在视觉差异,我们通过“视差”这一概念来表示这种差别。
该过程也可以通过两个处于同一平面的相机来模拟: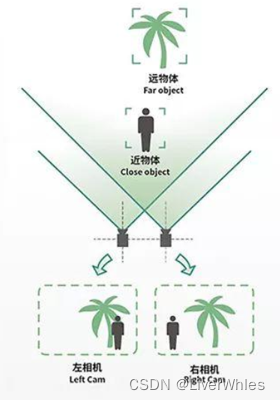
如下图所示,在同一水平面上存在位置偏移的两个相机,它们对同一物体拍照成像后在图片上的像素点坐标位置并不相同:
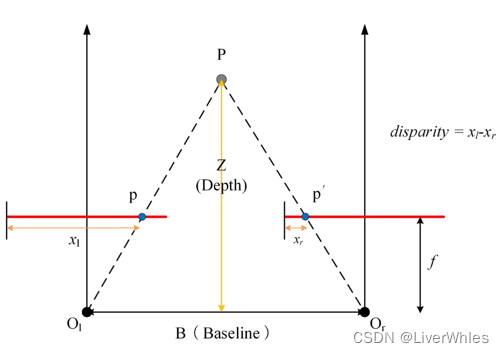
对于同一特征点P,在相机Ol和Or下成像点分别为p和p’,两条向上的箭头线代表了相机的摄影主轴方向(平行),两条红线代表了成像平面(沿x方向的长度相等),以相片的左边界为x方向的零起始边,p点和p‘点在对应相平面下的x坐标分别为xl和xr,定义视差(disparity)为xl-xr。
二、视差与深度的转换
通过视差,利用相似三角形我们可以计算出点P距离相机的深度信息:
记OlOr距离为B,pp‘距离为b,深度为z,焦距为f,视差xl-xr为s,则有
b
B
=
z
−
f
z
\frac{b}{B}=\frac{z-f}{z}
Bb=zz−f
B
−
s
B
=
z
−
f
z
\frac{B-s}{B}=\frac{z-f}{z}
BB−s=zz−f
z
=
f
B
s
z=f\frac{B}{s}
z=fsB
由此通过视差便可以求出物体与相机沿光轴方向上的距离,也即深度信息。
b=B-s推导:
b为pp‘距离,即B减去左右两个红色小三角形的底边,左边的底边为xr - L/2,右边的底边为L/2 - xl,因此b=B - (xr - L/2) - (L/2 - xl) = B - xr + xl,也即b = B-s
三、视差与深度关系
同时根据公式我们可以看出当物体距离越远,视差越小,物体越近,视差越大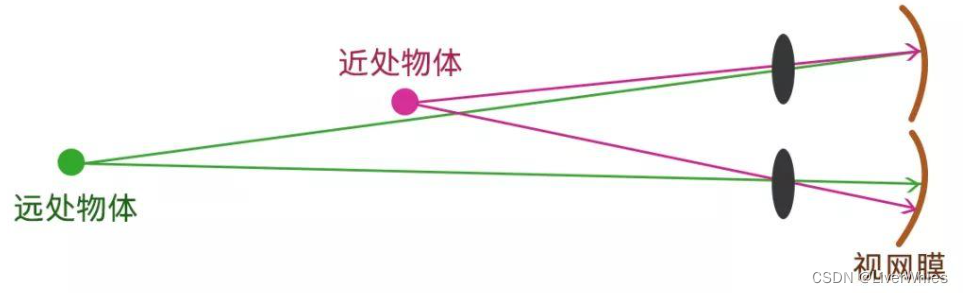
这是符合我们日常生活经验的,对于手指的例子,放的离眼睛越近,两次背后物体与手指的位置偏差越大,当放到足够远时,与手指靠很近的物体则基本看不出位置的偏移。
对于人眼双目系统而言,正是因为两眼之间存在水平的位置偏移产生了视差,人脑在接受到两张图片之后才可以恢复出深度信息,也即我们能够感受到3D场景下看到的物体离我们有多远。
3D电影就是利用了视差,使用两个投影仪投影出两幅具有视差的图像(所以不戴3D眼镜直接看会感觉画面是重叠模糊的),在3D眼镜作用下左、右眼分别只看到对应的一张图像,这就模拟了人眼的双目视觉体系,从而在大脑中产生具有深度感的立体3D场景。
四、视差图与深度图
视差图上每个像素点存储了该点在两幅图像下的视差值(为了反映不同视角下图片的差异),而深度图则记录了各点对应真实物体与相机光心沿光轴方向上的距离(为了存储真实三维场景信息)。
以下分别为不同视角的源图像、处理后的视差图和处理后的深度图:


上边的步骤并不复杂,要想从两张图片中获取视差图,只需对两幅图像上的特征点进行提取,随后在另一张图像上进行特征匹配来寻找对应点,随后即可计算出对应点的视差,获取视差图后可进一步转换为深度图,而有了深度图之后则可以进行三维重建来恢复真实的3D场景(点云等表示方法),因此:
- 视差图可以看作立体匹配(提取特征、特征匹配)的输出承载体
- 深度图是立体匹配与点云生成之间的中间桥梁
参考:
https://www.fpga-china.com/4559.html
https://zhuanlan.zhihu.com/p/522285892
https://www.cnblogs.com/riddick/p/8486223.html
版权归原作者 LiverWhles 所有, 如有侵权,请联系我们删除。