
公司:
苍穹数码技术股份有限公司2001年创建于北京,是一家专业从事3S技术研究、开发与应用服务,致力于政府、国防和企业信息化建设的高新技术企业,也是业内率先打通地理信息全产业链的平台级产品、技术与服务提供商,在信息化相关技术领域具有核心竞争优势。
背景:
我国常见的地质灾害共有12类、48种。在所有的地质灾害中,崩塌、滑坡、泥石流是最为严重的,其以分布广、灾发性和破坏性强,具有隐蔽性及容易链状成灾的特点,对工程建筑、交通运输、居民生命财产等造成直接危害,间接影响社会安定、引发生态环境恶化,加剧各种自然灾害,引发次生灾害。
国家突发事件应急体系建设“十三五”规划强调预防与准备,提高综合风险研判能力、灾害监测和预警预报能力,真正体现风险防范的效益。建设地灾专业监测物联网平台势在必行。

场景与痛点
一、应用场景
物联网监测平台主要包含一下5个方面:
1、数据采集
不同时期不同采集频率,设备自适应,监测到异常数据,自动提高采集频率,且支持设备反控。
2、数据传输
考虑断网,断电情况(丘陵地区监测特殊性要求,对设备稳定性,阴雨绵绵,对太阳能供电考虑)
3、数据存储(强依赖入库性能)
考虑后期设备增多,数据存储问题 ,高频采集数据入库效率问题
4、数据分析(强依赖查询性能)
一点一策,一设备一策
充分考虑灾害发育特征,岩土体结构,基于主要诱因设置阈值模型(单因子、多因子模型设置)
基于人工智能模型
5、预警预报
虚报不漏报,宁愿听骂声也不听哭声
二、应用痛点
解决海量时序数据的存储和计算,有着体量大、时间长,写入,查询要求高的特点,传统关系型数据库无法满足实时写入与高性能查询要求。
技术选型
我们的地灾物联网专业监测平台研发于2018年,当时选用的大型企业级数据库ORACLE,随着接入的设备传感器越来越多数据量越来越大,数据入库与数据查询越来越慢。特别是雨季来临,传感器数据采集频率提高到秒级、毫秒级别,数据入库会阻塞,效率严重跟不上。
自2019年我们便开始关注一些国内外的时序数据库,通过调研发现 TimescaleDB、 TDengine两款比较合适,主要从数据写入、查询、团队上手难度等指标项考察。
下面以近10年全省的雨量站小时雨量数据为例,从常用的应用场景为例对2个数据库进行比对分析。
测试机器配置信息

一、历史数据批量入库场景比对:
数量
timescaledb _1.7.0
tdengine_2.0.22
125958796
24小时
2小时
二、入库后数据文件大小比对:
数量
timescaledb _1.7.0
tdengine_2.0.22
125958796
38G
698M
三、常见查询场景比对:
1、查询全省全部站点累计降雨(10-30天),按站点分组,汇总累计降雨
2、查询单一站点、区县所有站点, 多年年数据 按照年,月,日,小时统计汇总 (全省2138个雨量站点,单位S)
应用场景
oracle 11g
timescaledb _1.7.0
tdengine_2.0.22
查询全省全部站点累计降雨(10-30天)
7.125
1.57
0.579
1月每小时雨量
12.297
1.92
0.027954
1年每日雨量
7.234
1.988
0.025952
1年每月雨量
7.232
1.913
0.020388
10年单个站点每年雨量
7.243
4.275
0.141484
10年全省站点每年雨量
超时了
920.434
3.608482
结论:从入库、压缩比、与查询3个维度,TDengine 都是完胜。
基于以上信息综合比对如下:
TimescaleDB
TDengine
时序数据库
√
√
开源数据库
√
√
集群释是否开源
√
√
传统关系型数据库查询支持
√
×
查询性能
×
√
写入性能
×
√
数据压缩比
×
√
超级表
√
√
子表
×
√
标签
×
√
聚合查询(sum、count、 min、 max、 avg等)
√
√
滑动窗口
×
√
团队人员学习曲线
√
×
信创名录产品
×
√
数据库设计与应用
TDengine在物联网监测平台中的数据采集侧架构图如下所示:

TDengine存储从空间与时间2个维度分层分级存储:

一、数据库
1、创建数据库
地灾专业监测数据库设置保存20年,分片参数90天,每个vnode 30个内存块(根据机器内存调大),允许编辑,建库语句如下:
CREATE DATABASE IF NOT EXISTS geohazard_monitor KEEP 7300 DAYS 90 BLOCKS 30 UPDATE 1 ;
2、创建超级表
根据传感器类型 ,创建超级表以水压力计含水率为例 ,例如传感器类型编码:201,超级表命名 m_201 ,其他传感器 m_xxx(传感器类型编码) ,统一命名规则。统一约定t20采集时间, t30同步入库时间 ,超级表2个tag ,传感器编码,编号(注意每个子表 tag值一样),建超级表语句如下:
CREATE STABLE IF NOT EXISTS m_201 (t20 TIMESTAMP, t30 TIMESTAMP ,v_water FLOAT) TAGS (sensor_code BINARY(20), sensor_id INT);
3、数据入库
使用超级表模板入库 ,子表命名规则 m_XXX( 传感器编码)
入库语句如下:
INSERT INTO m_05162300008 USING m_201 TAGS ('05162300008', 2) VALUES ('2021-01-01 00:00:00.000','2021-01-01 00:00:00.001', 0.02);
4、查询
时间窗口(interval)avg聚合滚动查询,时间窗口单位可以是 b(纳秒)、u(微秒)、a(毫秒)、s(秒)、m(分)、h(小时)、d(天)、w(周)、 n(自然月) 和 y(自然年) 。查询每天含水率平均值语句如下:
SELECT AVG(v_water) FROM m_05162300008 WHERE t20 >= '2020-01-01 00:00:00.000' AND t20<'2020-01-03 00:00:00.000' interval(1d) ;
二、开发
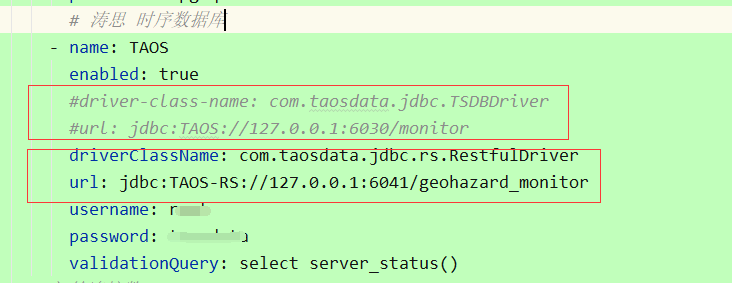
JAVA应用程序数据库连接:我们的开发环境选择了 JDBC-RESTful方式,生产环境选择了安装客户端的JDBC-JNI方式,相比JDBC-RESTful有一定的性能优势,最大化发挥TDengine的性能。但是JDBC-RESTful具有轻便,问题易定位等优势。所以大家可以酌情选择。JDBC-RESTful到JDBC-JNI的切换十分简单,一般只需要修改配置文件即可。如下图所示:
三、 典型应用
某个滑坡监测项目
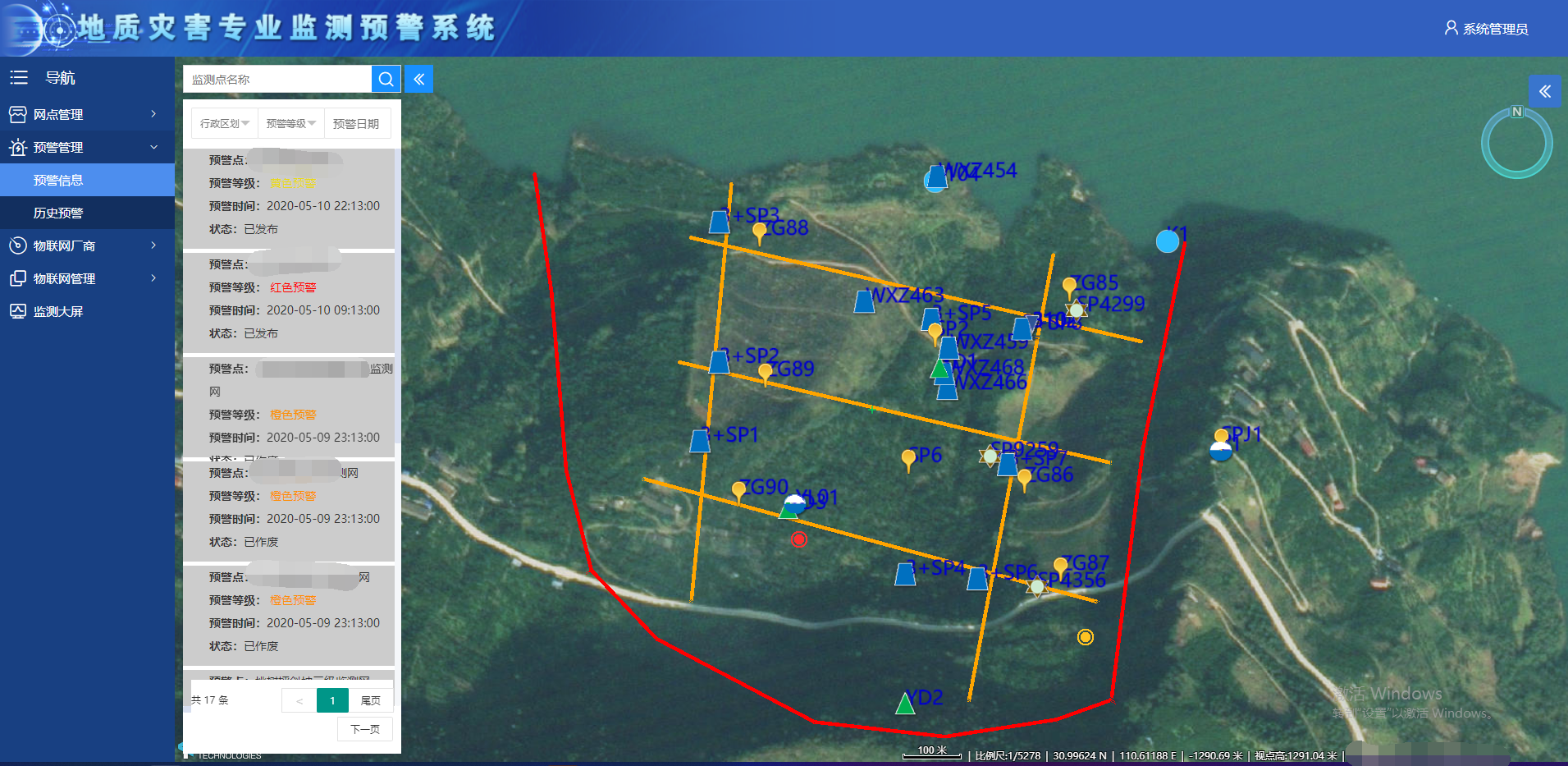
某含水率传感器监测曲线

某省累计降雨等值线

特色功能:
1、使用超级表模板,数据入库,自动创建子表
2、滑动窗口统计功能
3、速度足够快,资源占用足够少,属于节能减排绿色产品
4、开发、部署足够方便
5、支持国产芯片与国产操作系统,属于信创名录产品,应用于保密项目没有后顾之忧
写在最后
在本次产品中,TDengine展现出了强大的读写性能和数据压缩能力,聚合类查询速度非常快,也帮助我们有效降低了机器使用成本。超级表、子表、标签、时间窗口、状态窗口等概念非常适配物联网大数据应用场景,随着产品的越加完善,可以说是未来潜力无限。百舸争流,奋楫者先;千帆竟发,勇进者胜;祝涛思数据越来越好,做物联网大数据的ORACLE。
版权归原作者 Xerxes Fang 所有, 如有侵权,请联系我们删除。