
系列篇章💥
AI大模型探索之路-训练篇1:大语言模型微调基础认知
AI大模型探索之路-训练篇2:大语言模型预训练基础认知
AI大模型探索之路-训练篇3:大语言模型全景解读
AI大模型探索之路-训练篇4:大语言模型训练数据集概览
AI大模型探索之路-训练篇5:大语言模型预训练数据准备-词元化
AI大模型探索之路-训练篇6:大语言模型预训练数据准备-预处理
AI大模型探索之路-训练篇7:大语言模型Transformer库之HuggingFace介绍
AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验
AI大模型探索之路-训练篇9:大语言模型Transformer库-Pipeline组件实践
AI大模型探索之路-训练篇10:大语言模型Transformer库-Tokenizer组件实践
AI大模型探索之路-训练篇11:大语言模型Transformer库-Model组件实践
AI大模型探索之路-训练篇12:语言模型Transformer库-Datasets组件实践
AI大模型探索之路-训练篇13:大语言模型Transformer库-Evaluate组件实践
目录
前言
在自然语言处理(NLP)的领域中,Hugging Face的Transformer库已经成为了一个不可或缺的工具。它不仅提供了大量预训练模型,还为我们构建了一个高效、灵活的训练框架——Trainer组件。随着人工智能技术的不断进步,Agent AI智能体的智能化水平正在不断提高,它们在未来社会中的角色、发展路径以及可能带来的挑战也引起了广泛关注。Trainer组件的实践应用,正是推动这一进程的关键因素之一。
官网的API:https://huggingface.co/docs/transformers/main_classes/trainer
在本文中,我们将深入探讨Trainer组件的工作原理和实际应用。通过逐步解析TrainingArguments与Trainer的配置和使用,我们将展示如何利用这一工具进行高效的模型训练和评估。此外,我们还将提供一个完整的代码示例,以指导读者如何在实践中应用Trainer组件,以及如何通过调整参数来优化预训练模型的代码。
通过本文的学习和实践,我们将能够更好地理解Transformer库的Trainer组件,掌握其在模型训练和评估中的应用,并为未来Agent AI智能体的开发提供坚实的技术基础。接下来,我们将从Trainer组件的基本介绍开始,逐步深入到参数配置、代码实践,以及基于Trainer组件的预训练代码优化。
一、Trainer组件介绍
Trainer模块主要包含两部分的内容:TrainingArguments与Trainer,前者用于训练参数的设置,后者用于创建真正的训练器,进行训练、评估预测等实际操作。
1)TrainingArguments
TrainingArguments中可以配置整个训练过程中使用的参数,默认版本是包含90个参数,涉及模型存储、模型优化、训练日志、GPU使用、模型精度、分布式训练等多方面的配置内容。
2)Trainer
Trainer中配置具体的训练用到的内容,包括模型、训练参数、训练集、验证集、分词器、评估函数等内容
二、常见的 TrainingArguments 参数的使用样例
1、学习率 (Learning Rate):
from transformers import TrainingArguments
training_args = TrainingArguments(
learning_rate=3e-5,)
2、批次大小 (Batch Size):
training_args = TrainingArguments(
per_device_train_batch_size=8,
per_device_eval_batch_size=8,)
3、训练步数 (Number of Epochs):
training_args = TrainingArguments(
num_train_epochs=3,
num_eval_steps=100,)
4、梯度累积 (Gradient Accumulation):
training_args = TrainingArguments(
gradient_accumulation_steps=4,)
5、优化器 (Optimizer):
training_args = TrainingArguments(
optimizer="adam",)
6、权重衰减 (Weight Decay):
training_args = TrainingArguments(
weight_decay=0.01,)
7、学习率衰减策略 (Learning Rate Scheduler):
training_args = TrainingArguments(
lr_scheduler="linear",)
8、保存最佳模型 (Save Best Model):
training_args = TrainingArguments(
save_best_model=True,)
9、评估模式 (Evaluation Mode):
training_args = TrainingArguments(
evaluation_strategy="steps",
evaluation_steps=100,)
10、加载最佳模型 (Load Best Model):
training_args = TrainingArguments(
load_best_model_at_end=True,
metric_for_best_model="f1",)
11、数据集中的数据列名 (Data Column Names):
training_args = TrainingArguments(
label_decoding_format="int",
label_smoothing_factor=0.1,)
12、多设备训练 (Multi-Device Training):
training_args = TrainingArguments(
device_ids=[0,1],# Assuming two GPUs are available
fp16=True,# Use mixed precision training with Tensor Cores)
三、Trainer组件使用样例
from transformers import Trainer, TrainingArguments
from transformers import AutoModelForSequenceClassification, AutoTokenizer
# 加载预训练模型和分词器
model_name ="bert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSequenceClassification.from_pretrained(model_name)# 配置训练参数
training_args = TrainingArguments(
output_dir="./results",# 输出目录
num_train_epochs=3,# 训练轮数
per_device_train_batch_size=8,# 每个设备的训练批次大小
per_device_eval_batch_size=8,# 每个设备的评估批次大小
warmup_steps=500,# 预热步数
weight_decay=0.01,# 权重衰减系数
logging_dir="./logs",# 日志目录)# 创建Trainer对象并进行训练、评估和预测操作
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,# 训练数据集
eval_dataset=eval_dataset,# 评估数据集
tokenizer=tokenizer,# 分词器)
四、基于Trainer优化预训练代码
基于Trainer整体优化前面篇章《AI大模型探索之路-训练篇8:大语言模型Transformer库-预训练流程编码体验》的预训练代码
学术加速
# 学术资源加速import subprocess
import os
result = subprocess.run('bash -c "source /etc/network_turbo && env | grep proxy"', shell=True, capture_output=True, text=True)
output = result.stdout
for line in output.splitlines():if'='in line:
var, value = line.split('=',1)
os.environ[var]= value
步骤一:导入相关包
from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from datasets import load_dataset
步骤二:加载数据集
使用load_dataset函数加载CSV格式的数据集。split参数指定了我们想要加载的数据集的哪一部分,这里是"train",意味着我们只加载数据集的训练部分。
dataset = load_dataset("csv", data_files="/root/pretrains/ChnSentiCorp_htl_all/ChnSentiCorp_htl_all.csv", split="train")# 使用filter方法对数据集进行过滤,以移除那些"review"字段缺失的样本。# lambda x: x["review"] is not None是一个匿名函数,它对于数据集中的每个样本x进行评估,# 如果样本中的"review"字段不是None(即不是缺失或空的),那么这个样本就会通过过滤。# 过滤后,dataset对象将只包含"review"字段有有效值的样本。
dataset = dataset.filter(lambda x: x["review"]isnotNone)
dataset
输出
Dataset({
features:['label','review'],
num_rows:7765})
步骤三:划分数据集
使用dataset对象的train_test_split方法来分割数据集。train_test_split方法随机地将数据集分为两部分:训练集(train)和测试集(test)。
test_size参数指定了测试集应该占原始数据集的比例,这里设置为0.1,意味着测试集将占总数据集的10%。
datasets = dataset.train_test_split(test_size=0.1)
datasets
输出
DatasetDict({
train: Dataset({
features:['label','review'],
num_rows:6988})
test: Dataset({
features:['label','review'],
num_rows:777})})
步骤四:数据集预处理
定义函数进行数据预处理
import torch
tokenizer = AutoTokenizer.from_pretrained("/root/transformers/classmodel/rbt3")# 定义一个处理函数,该函数将被应用到数据集中的每个样本上。# 这个函数接收一个examples对象,其中包含了数据集中的一部分样本。defprocess_function(examples):# 使用tokenizer对"review"字段进行编码,生成模型可理解的格式。# max_length=128指定了输出序列的最大长度,超过这个长度的文本将被截断。# truncation=True指示Tokenizer进行截断操作。
tokenized_examples = tokenizer(examples["review"], max_length=128, truncation=True)
tokenized_examples["labels"]= examples["label"]return tokenized_examples
# 使用map方法将process_function应用到datasets对象中的每个样本上。# map方法会自动对数据集中的所有样本运行process_function函数。# batched=True指示map操作应该批处理样本,这通常比逐个处理样本更高效。# remove_columns=datasets["train"].column_names指定在映射过程中移除原始数据集中的列,只保留处理后的tokenized数据。
tokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)
tokenized_datasets

DatasetDict({
train: Dataset({
features:['input_ids','token_type_ids','attention_mask','labels'],
num_rows:6988})
test: Dataset({
features:['input_ids','token_type_ids','attention_mask','labels'],
num_rows:777})})
步骤五:创建模型
model = AutoModelForSequenceClassification.from_pretrained("/root/pretrains/rbt3")
步骤六:创建评估函数
import evaluate
acc_metric = evaluate.load("accuracy")
f1_metirc = evaluate.load("f1")defeval_metric(eval_predict):#eval_predict拆分成两部分,第一部分是预测值,赋值给predictions,第二部分是实际标签,赋值给labels
predictions, labels = eval_predict
# 获取到预测值
predictions = predictions.argmax(axis=-1)
acc = acc_metric.compute(predictions=predictions, references=labels)
f1 = f1_metirc.compute(predictions=predictions, references=labels)#是更新准确率指标,把F1分数的计算结果加入到准确率指标的计算中
acc.update(f1)return acc
步骤七:创建TrainingArguments
train_args = TrainingArguments(output_dir="./checkpoints",# 输出文件夹
per_device_train_batch_size=64,# 训练时的batch_size
per_device_eval_batch_size=128,# 验证时的batch_size
logging_steps=10,# log 打印的频率
evaluation_strategy="epoch",# 评估策略
save_strategy="epoch",# 保存策略
save_total_limit=3,# 最大保存数
learning_rate=2e-5,# 学习率
metric_for_best_model="f1",# 设定评估指标
load_best_model_at_end=True)# 训练完成后加载最优模型
train_args
输出
TrainingArguments(
_n_gpu=1,
adafactor=False,
adam_beta1=0.9,
adam_beta2=0.999,
adam_epsilon=1e-08,
auto_find_batch_size=False,
bf16=False,
bf16_full_eval=False,
data_seed=None,
dataloader_drop_last=False,
dataloader_num_workers=0,
dataloader_pin_memory=True,
ddp_backend=None,
ddp_broadcast_buffers=None,
ddp_bucket_cap_mb=None,
ddp_find_unused_parameters=None,
ddp_timeout=1800,
debug=[],
deepspeed=None,
disable_tqdm=False,
dispatch_batches=None,
do_eval=True,
do_predict=False,
do_train=False,
eval_accumulation_steps=None,
eval_delay=0,
eval_steps=None,
evaluation_strategy=epoch,
fp16=False,
fp16_backend=auto,
fp16_full_eval=False,
fp16_opt_level=O1,
fsdp=[],
fsdp_config={'min_num_params':0,'xla':False,'xla_fsdp_grad_ckpt':False},
fsdp_min_num_params=0,
fsdp_transformer_layer_cls_to_wrap=None,
full_determinism=False,
gradient_accumulation_steps=1,
gradient_checkpointing=False,
gradient_checkpointing_kwargs=None,
greater_is_better=True,
group_by_length=False,
half_precision_backend=auto,
hub_always_push=False,
hub_model_id=None,
hub_private_repo=False,
hub_strategy=every_save,
hub_token=<HUB_TOKEN>,
ignore_data_skip=False,
include_inputs_for_metrics=False,
include_tokens_per_second=False,
jit_mode_eval=False,
label_names=None,
label_smoothing_factor=0.0,
learning_rate=2e-05,
length_column_name=length,
load_best_model_at_end=True,
local_rank=0,
log_level=passive,
log_level_replica=warning,
log_on_each_node=True,
logging_dir=./checkpoints/runs/Dec14_15-16-59_autodl-container-a6bf4ea7dd-af8739e9,
logging_first_step=False,
logging_nan_inf_filter=True,
logging_steps=10,
logging_strategy=steps,
lr_scheduler_type=linear,
max_grad_norm=1.0,
max_steps=-1,
metric_for_best_model=f1,
mp_parameters=,
neftune_noise_alpha=None,
no_cuda=False,
num_train_epochs=3.0,
optim=adamw_torch,
optim_args=None,
output_dir=./checkpoints,
overwrite_output_dir=False,
past_index=-1,
per_device_eval_batch_size=128,
per_device_train_batch_size=64,
prediction_loss_only=False,
push_to_hub=False,
push_to_hub_model_id=None,
push_to_hub_organization=None,
push_to_hub_token=<PUSH_TO_HUB_TOKEN>,
ray_scope=last,
remove_unused_columns=True,
report_to=['tensorboard'],
resume_from_checkpoint=None,
run_name=./checkpoints,
save_on_each_node=False,
save_safetensors=True,
save_steps=500,
save_strategy=epoch,
save_total_limit=3,
seed=42,
skip_memory_metrics=True,
split_batches=False,
tf32=None,
torch_compile=False,
torch_compile_backend=None,
torch_compile_mode=None,
torchdynamo=None,
tpu_metrics_debug=False,
tpu_num_cores=None,
use_cpu=False,
use_ipex=False,
use_legacy_prediction_loop=False,
use_mps_device=False,
warmup_ratio=0.0,
warmup_steps=0,
weight_decay=0.0,)
步骤八:创建Trainer
from transformers import DataCollatorWithPadding
trainer = Trainer(model=model,
args=train_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
data_collator=DataCollatorWithPadding(tokenizer=tokenizer),
compute_metrics=eval_metric)
步骤九:模型训练
trainer.train()
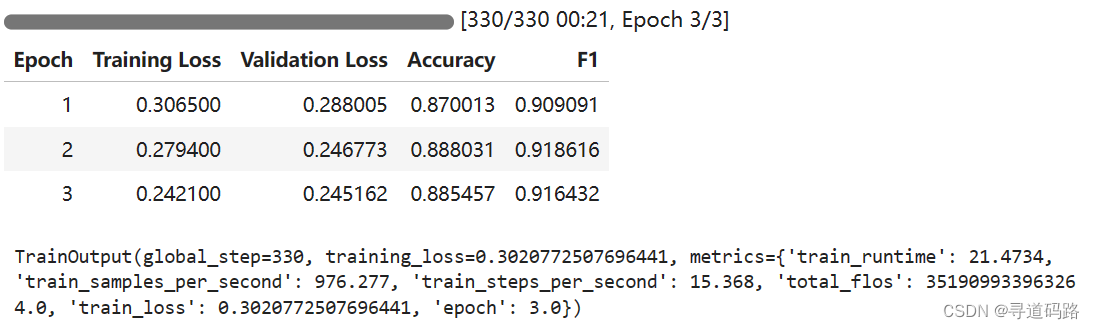
步骤十:模型评估
trainer.evaluate(tokenized_datasets["test"])
输出
{'eval_loss':0.24680815637111664,'eval_accuracy':0.8944658944658944,'eval_f1':0.9258589511754068,'eval_runtime':0.2755,'eval_samples_per_second':2820.097,'eval_steps_per_second':25.406,'epoch':3.0}
步骤十一:模型预测
trainer.predict(tokenized_datasets["test"])
输出
PredictionOutput(predictions=array([[-2.2057114,2.638173],[-2.4150753,2.23317],[-2.3024874,2.4696612],...,[-2.3230095,2.4339147],[-2.5654528,2.8227382],[-2.4460046,2.808864]], dtype=float32), label_ids=array([1,1,1,1,1,1,0,1,1,0,1,1,1,1,1,1,0,0,0,1,1,0,0,1,1,0,1,1,1,1,1,0,1,0,1,1,1,1,1,1,0,0,0,1,1,1,1,0,1,0,1,1,0,0,1,1,0,0,0,1,1,1,1,1,1,1,1,1,1,0,1,0,0,1,0,1,1,1,1,1,1,1,1,1,0,1,1,0,0,0,0,1,0,1,0,1,0,1,0,0,1,1,1,1,0,1,0,1,0,1,0,0,1,1,1,1,0,1,0,1,1,1,1,1,1,1,0,1,1,1,1,1,0,1,0,0,0,0,1,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,1,0,1,1,1,1,0,1,1,1,0,0,1,0,0,1,1,1,0,0,1,1,1,0,1,1,0,1,1,1,0,1,1,1,0,1,1,1,1,0,1,0,1,1,1,1,1,1,1,1,1,1,1,0,1,1,1,1,1,1,1,1,1,1,1,1,0,0,1,1,1,1,0,1,1,0,0,1,1,1,0,1,1,1,0,1,1,0,0,0,1,1,1,0,1,0,1,0,0,0,1,1,0,1,1,1,1,0,1,1,1,0,1,0,0,0,1,1,0,1,0,1,1,1,1,1,1,1,0,1,1,0,1,1,1,1,0,1,1,1,1,1,0,1,1,1,1,0,1,1,1,0,0,0,0,0,1,1,0,1,1,1,1,1,1,0,1,1,1,1,1,1,0,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,1,1,1,1,1,1,1,1,1,0,0,0,1,0,1,1,1,0,0,1,0,0,0,1,0,1,1,0,0,0,1,1,1,1,0,0,1,1,1,0,1,1,1,1,0,1,0,1,0,0,1,1,0,0,1,0,1,1,1,1,1,0,1,1,1,1,1,1,0,1,1,0,1,1,1,1,0,0,0,0,1,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,0,0,1,1,0,1,0,0,1,1,1,1,1,1,0,1,1,1,0,1,1,0,1,1,0,1,0,1,1,0,0,0,1,0,1,1,1,1,0,0,1,1,0,1,1,1,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,1,1,1,0,1,0,0,1,1,0,0,1,1,0,1,1,1,1,1,1,1,0,0,1,1,0,1,1,1,0,1,1,1,0,1,1,0,1,1,1,1,1,0,1,0,1,1,1,1,1,1,1,1,0,1,1,1,1,1,1,0,1,1,1,1,1,1,1,0,1,1,1,0,0,0,1,0,1,0,1,1,1,1,1,1,1,1,1,1,0,0,1,1,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,1,1,1,1,1,0,1,1,1,1,1,1,1,0,1,1,1,0,1,0,1,1,1,1,1,0,1,1,1,1,0,1,1,1,1,1,1,1,1,1,0,1,1,0,1,1,1,0,1,1,1,1,1,1,1,1,0,1,0,0,1,1,0,0,1,1,1,1,1,1,1,1,0,0,1,0,0,1,1,0,1,1,1,1,1,0,1,0,0,0,1,1,0,1,0,0,1,0,0,1,0,0,1,0,1,1,1,1,1,1,1,1,1,1,1,1,1,1,0,0,1,1,1,1,0,1,0,0,1,1,1,1,0,1,1,0,1,1,1,1,1,1,1]), metrics={'test_loss':0.24680815637111664,'test_accuracy':0.8944658944658944,'test_f1':0.9258589511754068,'test_runtime':0.2817,'test_samples_per_second':2758.114,'test_steps_per_second':24.848})
完整代码如下
# 导入所需的库和模块from transformers import AutoTokenizer, AutoModelForSequenceClassification, Trainer, TrainingArguments
from transformers import DataCollatorWithPadding
from datasets import load_dataset
import torch
import evaluate
# 加载数据集
dataset = load_dataset("csv", data_files="/root/transformers/classdata/ChnSentiCorp_htl_all.csv", split="train")
dataset = dataset.filter(lambda x: x["review"]isnotNone)
datasets = dataset.train_test_split(test_size=0.1)# 加载预训练模型的分词器
tokenizer = AutoTokenizer.from_pretrained("/root/transformers/classmodel/rbt3")# 定义处理函数,将文本转换为模型可接受的格式defprocess_function(examples):
tokenized_examples = tokenizer(examples["review"], max_length=128, truncation=True)
tokenized_examples["labels"]= examples["label"]return tokenized_examples
# 对数据集进行预处理,并返回处理后的结果
tokenized_datasets = datasets.map(process_function, batched=True, remove_columns=datasets["train"].column_names)# 加载预训练模型
model = AutoModelForSequenceClassification.from_pretrained("/root/transformers/classmodel/rbt3")# 加载评估指标
acc_metric = evaluate.load("accuracy")
f1_metirc = evaluate.load("f1")# 定义评估函数,计算准确率和F1分数defeval_metric(eval_predict):
predictions, labels = eval_predict
predictions = predictions.argmax(axis=-1)
acc = acc_metric.compute(predictions=predictions, references=labels)
f1 = f1_metirc.compute(predictions=predictions, references=labels)
acc.update(f1)return acc
# 设置训练参数
train_args = TrainingArguments(output_dir="./checkpoints",# 输出文件夹
per_device_train_batch_size=64,# 训练时的batch_size
per_device_eval_batch_size=128,# 验证时的batch_size
logging_steps=10,# log 打印的频率
evaluation_strategy="epoch",# 评估策略
save_strategy="epoch",# 保存策略
save_total_limit=3,# 最大保存数
learning_rate=2e-5,# 学习率
metric_for_best_model="f1",# 设定评估指标
load_best_model_at_end=True)# 训练完成后加载最优模型# 创建Trainer对象,用于训练和评估模型
trainer = Trainer(model=model,
args=train_args,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["test"],
data_collator=DataCollatorWithPadding(tokenizer=tokenizer),
compute_metrics=eval_metric)# 开始训练模型
trainer.train()# 在测试集上评估模型性能
trainer.evaluate(tokenized_datasets["test"])# 使用训练好的模型进行预测
trainer.predict(tokenized_datasets["test"])
总结
本文介绍了Hugging Face Transformer库中的Trainer组件,包括TrainingArguments和Trainer。TrainingArguments用于配置训练参数,而Trainer则负责创建真正的训练器,进行训练、评估预测等实际操作。通过使用Trainer组件,可以方便地进行模型的训练、评估和预测等任务。
在实际应用中,我们可以通过调整TrainingArguments中的参数来优化模型的训练效果,例如学习率、批次大小等。同时,我们还可以使用不同的预训练模型和数据集来进行实验,以找到最佳的模型结构和参数设置。

🎯🔖更多专栏系列文章:AIGC-AI大模型探索之路
如果文章内容对您有所触动,别忘了点赞、⭐关注,收藏!加入我,让我们携手同行AI的探索之旅,一起开启智能时代的大门!
版权归原作者 寻道AI小兵 所有, 如有侵权,请联系我们删除。