
1.概述
Hadoop简介:Hadoop是Apache软件基金会旗下的一个开源分布式计算平台,为用户提供系统底层细节透明的分布式基础架构。Hadoop的核心是Hadoop分布式文件系统(Hadoop Distribute File System,HDFS)和MapReduce。
Hadoop被公认为行业大数据标准开源软件,在分布式环境下提供了海量数据的处理能力。几乎所有主流厂商都围绕Hadoop提供开发工具、开源软件、商业化工具和技术服务,如谷歌、雅虎、微软、思科、淘宝等都支持Hadoop。
Hadoop生态系统:经过多年的发展,Hadoop生态系统不断完善和成熟,目前已经包含了多个子项目。除了核心的HDFS和MapReduce以外,Hadoop生态系统还包括ZooKeeper、HBase、Hive、Pig、Mahout、Flume、Sqoop、Ambari等功能组件。

** 2.Hadoop的安装和使用**
安装准备:在具体操作之前,首先需要选择一个合适的操作系统。尽管Hadoop本身可以运行在Linux、Windows以及其他一些类UNIX操作系统之上,但是Hadoop官方真正支持的操作系统只有Linux。****因此在安装Hadoop之前,如若你使用的是Windows系统需要先安装Linux虚拟机后再配置Hadoop环境,具体安装Linux虚拟机步骤详见我的这篇博客:Linux虚拟机小白教程——windows11安装VMware并配置linux系统环境(Ubuntu22.04版本)_长弓同学的博客-CSDN博客
那么让我们正式开始吧 :)
Hadoop安装步骤:
(1)创建Hadoop用户
(2)更新apt和安装vim编辑器
(3)安装SSH和配置SSH无密码登录
(4)安装Java环境
(5)安装单机Hadoop
(6)Hadoop伪分布式安装
实践开始:
(1)创建Hadoop用户
创建用户命令行:
sudo useradd -m hadoop -s /bin/bash
接下来使用如下命令设置密码,注意设置密码长度需要有8个字符并且不能太简单,必须有英文字符和中文字符,不能与包含用户名。否则会报错(痛的领悟)。Linux中在输入密码时,密码是不显示的,所以需要盲打。
设置密码命令行:
sudo passwd hadoop
运行结果:

然后为Hadoop用户增加管理员权限,这样可以方便部署,避免一些比较棘手的权限问题(这一步骤非常重要)
增加权限命令行:
sudo adduser hadoop sudo
运行结果:

** (2)更新apt和安装vim编辑器**
用过Linux系统的小伙伴都知道在安装一些包和配置环境的时候,都需要对apt进行升级,这样可以确保后续可以顺利安装一些软件。
更新apt命令行:
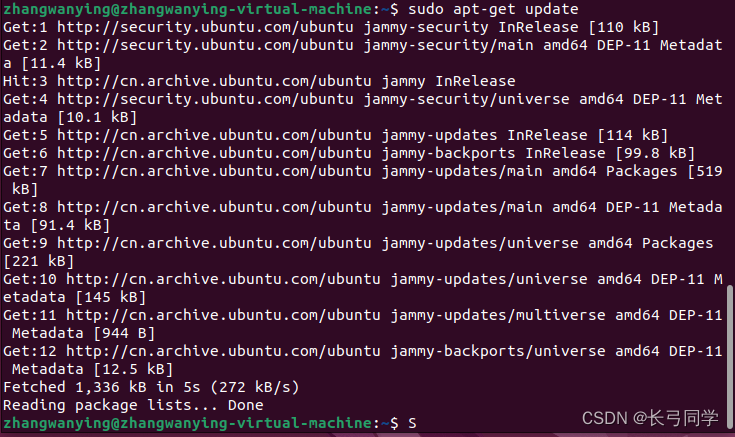
sudo apt-get update
更新中,更新完毕:
在Ubuntu操作系统中,可以使用vim编辑器来创建文件和修改文件。
安装vim编辑器命令行:
sudo apt-get install vim
安装中,安装完毕:

** (3)安装SSH和配置SSH无密码登录**
为了实现SSH无密码登录,需要在Ubuntu操作系统上安装SSH服务端和客户端。Ubuntu操作系统已经默认安装了SSH客户端,所以我们只用安装SSH服务端就可以。
安装SSH服务端命令行:
sudo apt-get install openssh-server
安装中,安装结束:
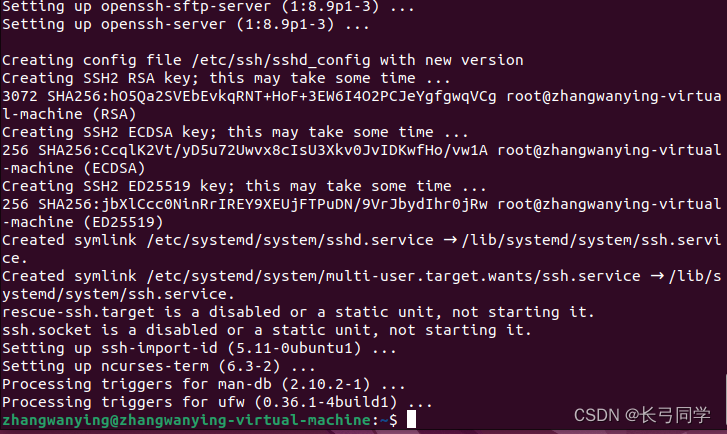
安装后,登录本机,命令行:
ssh localhost
出现提示后输入“yes”,然后输入Ubuntu用户密码即可登录。
出现以下页面,即为登录成功:

退出登录,然后利用ssh-keygen生成密钥,并将密钥加入授权,命令行如下:
exit
cd ~/.ssh/
ssh-keygen -t rsa
cat ./id_rsa.pub >> ./authorized_keys
退出,将路径移到ssh文件下,运行结果:

注意,在利用ssh-keygen生成密钥时,会让你将密钥加入授权文件中,此时空格即可。
输入授权文件密码时空着就行,这样会默认empty是无密码登录。完成后如下:


此时再用ssh localhost命令,无需再输入密码就可以直接登录了。
(4)安装java环境
由于Hadoop本身是使用Java编写的,因此,Hadoop的开发和运行都需要Java的支持。
下载JDK1.8安装包。下载路径(Oracle官网):Java Downloads | Oracle

因为我的Linux系统是64位的,所以这里我下载的是最后一个包。可以通过如下命令来查看Linux版本(如果版本不匹配在后续会出现问题,痛的领):
getconf LONG_BIT
(需要说明的是,如果你需要再官网下载则需要登录oracle账户,没有的话可以按照他的指示创建一个,非常快)
下载完JDK后,创建“/usr/lib/jvm”目录来存放JDK文件,命令行如下:
cd /usr/lib
sudo mkdir jvm
因为每个人下载的JDK包所在路径不同,所以我采用另一种方法在终端中锁定压缩包文件,操作如下:
下载完JDK后在浏览器下载列表中选择JDK压缩包在文件夹中打开

之后在终端中打开
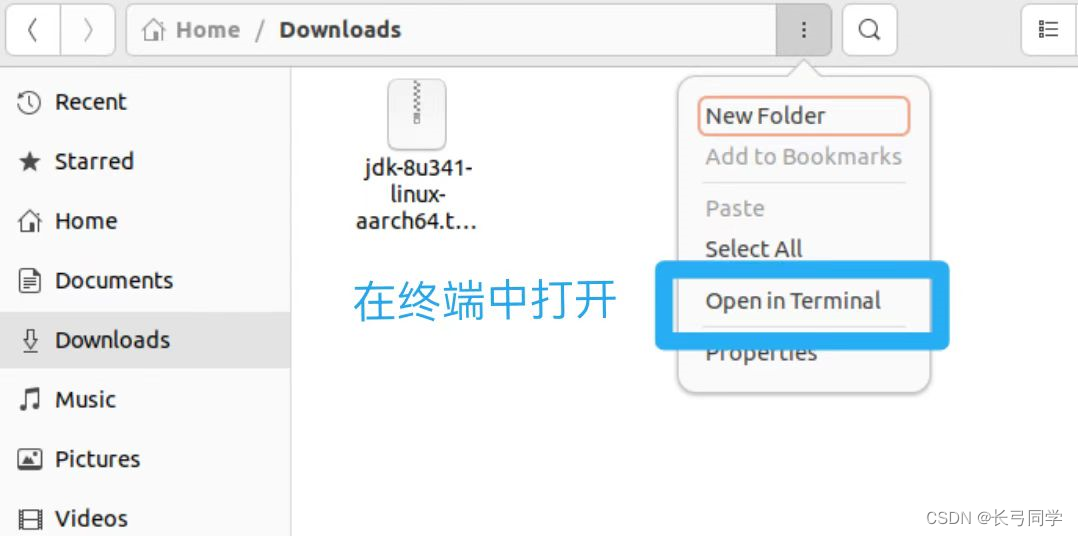
出现如下界面即可:

接着对安装文件进行解压,命令行如下(请根据自己下载的jdk压缩包名称来修改命令行):
sudo tar -zxvf /jdk-8u341-linux-x64.tar.gz -C /usr/lib/jvm
解压中,解压完毕:
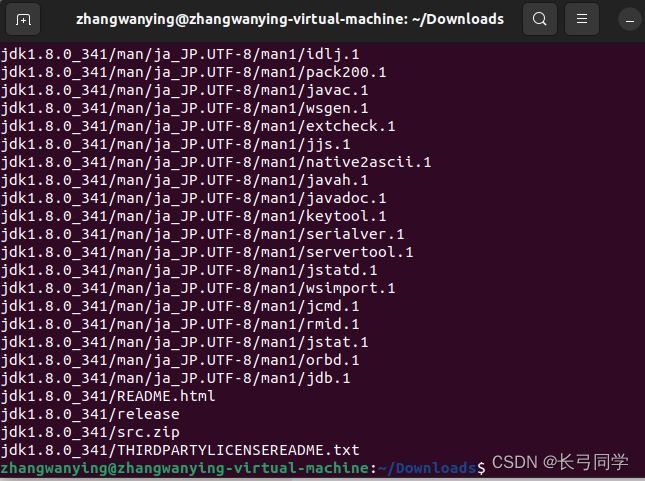
下面继续执行以下命令,设置环境变量:
vim ~/.bashrc
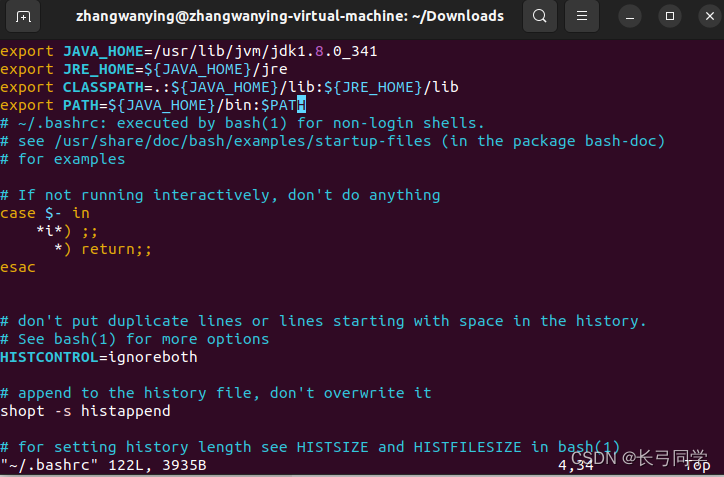
上面的命令行使用vim编辑器打开了“hadoop”这个用户的环境变量配置文件,请在这个文件的开头位置,添加如下几行内容(jdk版本请根据自己的版本进行更改):
(ps:点击“i”键,出现INSERT提示后就可以对文件进行编辑)
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_341
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
修改后 ,文件如下图所示:
先点击Esc退出键,输入“:wq”,退出并保存环境配置文件。
然后继续执行如下命令行让.bashrc文件生效
source ~/.bashrc
执行如下命令,检验Java环境是否配置成功:
java -version
显示如下界面即为安装完毕:

接下来还需要在Hadoop的文件中配置Java环境
打开文件,命令行如下:
sudo gedit /usr/local/hadoop/etc/hadoop/hadoop-env.sh
在文件中配置Java环境(加入如下命令行):
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_341
配置完成后如下图所示:

** (5)安装单机Hadoop**
在采用单机模式时,Hadoop只在一台机器上运行,存储采用本地文件系统,没有采用分布式系统HDFS。
Hadoop下载路径:Apache Downloads
点击第一个链接,开始下载。(此处下载的Hadoop为3.2.4版本)
与JDK的方式一样,在终端打开文件所在目录,执行如下命令进行安装:
sudo tar -zxvf ./hadoop-3.2.4.tar.gz -C /usr/local
将路径移到/usr/local下,并将Hadoop目录名称改为hadoop,以及修改权限,命令行如下(mv命令不可重复):
cd /usr/local/
sudo mv ./hadoop-3.1.3/ ./hadoop
sudo chown -R hadoop ./hadoop
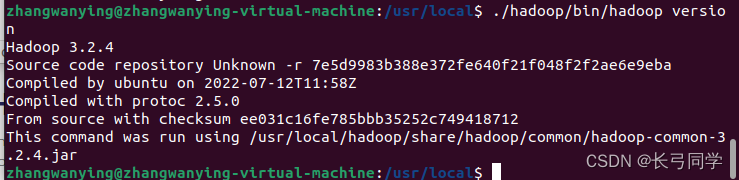
运行以下命令查看Hadoop版本(bin文件夹路径根据自身进行修改):
./hadoop/bin/hadoop version
出现以下页面,即为安装完成:
(6)Hadoop伪分布式安装
在分布式安装时,Hadoop存储采用分布式系统文件HDFS,而且HDFS的名称节点和数据节点位于集群的不同机器上。但是现在我们需要使用一台机器来完成这种分布式系统,所以需要使用伪分布式安装。
伪分布式安装是指在一台机器上模拟一个一个小的集群,但是集群中只有一个节点。
当Hadoop应用于集群时,无论是伪分布式还是真正的分布式进行,都需要通过配置文件对各组件的协同工作进行设置。对于伪分布式配置,我们需要修改core-site.xml、hdfs-site.xml、mapred-site.xml、yarn-site.xml文件
(1)core-site.xml
对于core-site.xml文件,我们只需要在其中指定HDFS的地址和端口号。端口号按照官方文档设置为9000即可。
输入如下命令行打开core-site.xml文件:
cd /usr/local/hadoop/etc/hadoop
sudo gedit core-site.xml
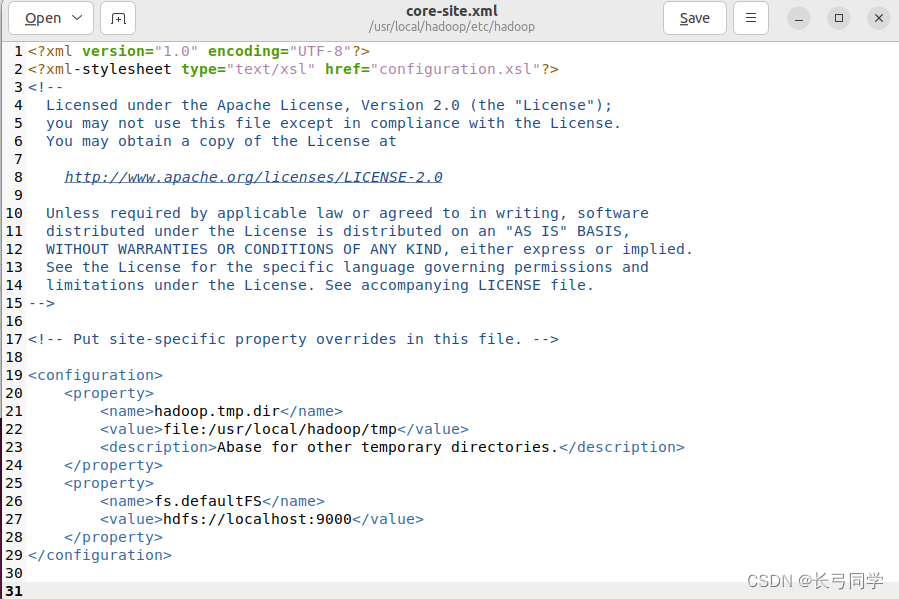
在文件的中加入如下代码段:
<configuration>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
修改后的配置文件如下:
(2)hdfs-site.xml
对于hdfs-site.xml文件,这里设置replication值为1,这也是Hadoop运行的默认最小值,它限制了HDFS中同一份数据的副本数量。由于这里采用伪分布式,集群中只有一个节点,因此该值只能设置为1。
输入如下命令行打开文件:
sudo gedit hdfs-site.xml
加入代码段:
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/tmp/dfs/data</value>
</property>
</configuration>
修改后的文件如下图所示:

** (3)mapred-site.xml**
加入如下代码段:
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(4)****yarn-site.xml
加入如下代码段:
<configuration>
<property>
<name>yarn.resourcemanger.hostname</name>
<value>localhost</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>
在配置完成后,首先需要初始化文件系统。
初始化之前需要修改一个文件参数(否则会出现报错“localhost: ERROR: Cannot set priority of datanode process”)
由于这个文件需要最高权限,所以需要登录root账户(一开始没有设置root账户需要用“sudo passwd”来初始化密码)
登录root账户命令:
su
登录后使用如下命令,打开文件:
vim $HADOOP_HOME/etc/hadoop/hadoop-env.sh
在文件最后一行加入“
HADOOP_SHELL_EXECNAME=root
”,保存并关闭文件执行如下命令行:
$HADOOP_HOME/bin/hdfs --daemon start datanode
结束后开始初始化系统
初始化命令行:
cd /usr/local/hadoop
./bin/hdfs namenode -format
初始化中,初始化结束:

初始化成功后,用以下命令行启动HDFS:
cd /usr/local/hadoop
./sbin/start-all.sh
启动后如图所示:
启动后可以输入
jps
指令查看所有的Java进程(得到如下类似结果):

版权归原作者 长弓同学 所有, 如有侵权,请联系我们删除。