
最近在GitHub上发现了一个爆火的开源项目。
好家伙,凑近一看,居然还是由微软开源,并且和最近炙手可热的ChatGPT息息相关。
项目的名字叫做:Visual ChatGPT。

这个项目最早是3月上旬微软开源的,项目宣布开源后仅用了短短一周,就斩获了2w+ star。

到现在为止,距离当初项目开源大约过去了3周多,仓库star数则来到了28k+,亦可谓是火箭式上涨(doge)。
众所周知,ChatGPT自2022年11月推出以来,持续走红。

ChatGPT具备强大的会话能力,可以理解文字、聊天、写小说、解答问题、编写代码… 但是目前还并不能直接处理或生成图像。
而Visual ChatGPT这个项目则可以把ChatGPT和一系列视觉基础模型(VFM,Visual Foundation Model)给联系起来,以便实现在ChatGPT聊天的过程中来发送和接收图像,也使得ChatGPT能够处理更为复杂的视觉任务。

讲白了,就是通过Visual ChatGPT,可以把一系列视觉基础模型给接入ChatGPT,使得ChatGPT能胜任更为复杂的视觉处理任务。
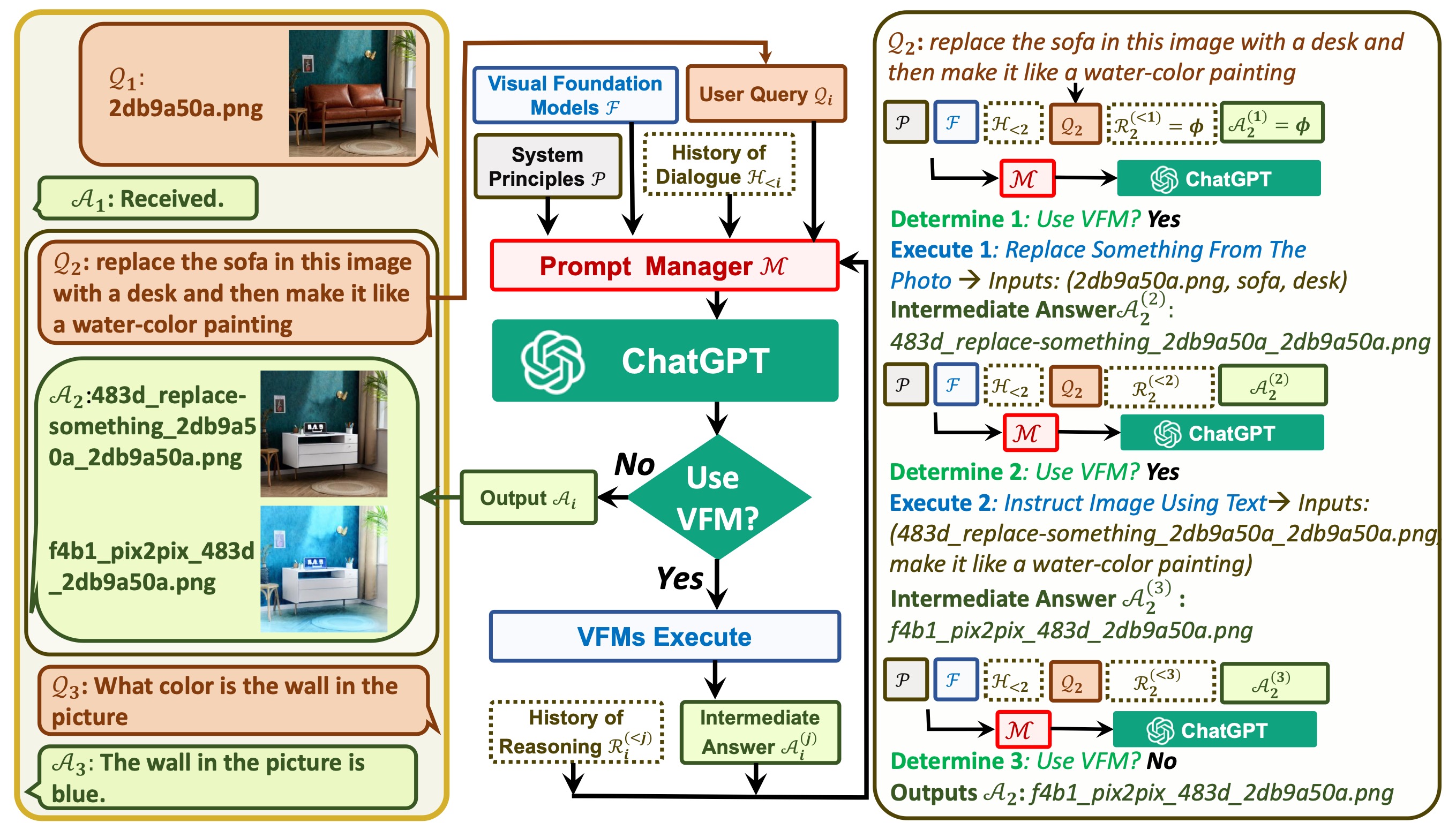
Visual ChatGPT的整体技术架构图如上所示,我们可以清楚地看到ChatGPT和视觉基础模型(VFM,Visual Foundation Model)分别位于其中的位置。
一方面,ChatGPT(或LLM)作为一个通用接口,继续发挥它本身的优势,提供对不同话题的智能理解。另一方面,基础视觉模型VFM则通过提供特定领域的深入知识来充当领域专家,它们通过交互管理模块(Prompt Manger)进行连接和适配。
这样聊可能比较抽象,我们可以拿官方给的一个例子来进行说明:

1、首先是用户:输入一张黄色的向日葵图片,并且要求ChatGPT根据该图像预测深度来生成一朵红花,然后再一步一步将其做成卡通画。
2、接着是交互管理模块(Prompt Manger)发挥作用,在它的协调和控制下,VFM模块开始发挥作用:
- 首先需要运用深度估计模型来预测并生成图像的深度信息;
- 然后需要运用深度图像模型来生成对应空间深度的红花图像;
- 最后运用Stable Diffusion的风格迁移模型来完成图像风格的变换。
3、最后Visual ChatGPT系统再将最终结果返回给用户,完成本次对话。
说到这里,有兴趣的小伙伴可以可以看看微软给出的一篇有关Visual ChatGPT的论文。

里面关于这部分的流程解释得非常详细,而且还给出了多轮对话的案例、以及实验结果,有兴趣的小伙伴可以看看。
好了,今天的分享就到这里了,感谢大家的收看,我们下篇见。
注:本文在GitHub开源仓库「编程之路」 https://github.com/rd2coding/Road2Coding 中已经收录,里面有我整理的6大编程方向(岗位)的自学路线+知识点大梳理、面试考点、我的简历、几本硬核pdf笔记,以及程序员生活和感悟,欢迎star。
版权归原作者 CodeSheep程序羊 所有, 如有侵权,请联系我们删除。