
💗博主介绍:✌全网粉丝10W+,CSDN全栈领域优质创作者,博客之星、掘金/华为云/阿里云等平台优质作者。
👇🏻 精彩专栏 推荐订阅👇🏻
计算机毕业设计精品项目案例-200套
🌟文末获取源码+数据库+文档🌟
感兴趣的可以先收藏起来,还有大家在毕设选题,项目以及论文编写等相关问题都可以和学长沟通,希望帮助更多的人
一.前言

随着人工智能技术的飞速发展,数据驱动的推荐系统成为了满足用户个性化需求的重要工具。特别是在漫画产业中,如何从海量数据中提取有价值的信息,推荐符合用户喜好的漫画作品,具有重要的实际应用价值。本文旨在探讨利用Spark技术进行大数据爬虫漫画推荐系统的研究,以期为漫画产业的可持续发展提供新的思路和方法。
在当今信息化社会,人们对信息的需求日益增长,而漫画作为一种深受大众喜爱的艺术形式,其产业发展迅速,涵盖了网络、出版、影视等多个领域。然而,面对如此庞大的漫画作品库,如何选择适合自己的作品成为了用户面临的难题。传统的推荐方法往往基于用户历史行为或社交网络数据进行推荐,但这些方法难以准确地反映用户的个性化需求。因此,研究基于大数据的漫画推荐系统,对于解决用户面临的信息过载问题具有重要意义。
在 Spark 大数据爬虫漫画推荐系统中,我们利用 Spark 强大的数据处理能力,从海量漫画数据中提取特征,建立推荐模型,为用户提供精准的漫画推荐服务。该系统的实现不仅可以提高漫画产品的质量和数量,还能满足用户的个性化需求,提高用户的满意度。此外,通过基于 Spark 的大数据爬虫技术,我们能够实时更新数据,确保推荐系统的有效性和实时性。
尽管目前市场上的漫画推荐系统多种多样,但仍然存在一些问题,如信息过载和个性化推荐不足等。这些问题的出现主要是由于缺乏有效的数据处理技术和准确的推荐算法。因此,本研究旨在通过 Spark 大数据爬虫技术,对于海量的漫画数据进行深度的分析和挖掘,从用户行为、作品属性、社交网络等多个维度提取特征,建立更加精准的推荐模型,以解决现有推荐系统存在的问题。
二.技术环境
开发语言:Python
python框架:django
软件版本:python3.7/python3.8
数据库:mysql 5.7或更高版本
数据库工具:Navicat11
爬虫框架:Spark
开发软件:PyCharm/vs code
前端框架:vue.js
三.功能设计
个人中心
用户信息管理:用户可以查看和编辑自己的个人信息,包括头像、昵称、性别等。
收藏管理:用户可以在个人中心查看自己收藏的漫画作品,以及对收藏的作品进行管理,如取消收藏、添加标签等。
评分管理:用户可以在个人中心查看自己对漫画作品的评分,以及修改或删除评分。
历史记录管理:用户可以在个人中心查看自己的浏览历史记录,以及删除历史记录。
漫画数据管理:
漫画数据管理模块是整个系统的基础,提供以下功能:
数据存储:系统可以存储大量的漫画数据,包括漫画的图片、简介、作者、出版社等信息。
数据查询:系统提供多种查询方式,使用户能够方便快捷地查找到自己感兴趣的漫画作品。
数据统计和分析:系统可以对漫画数据进行统计和分析,为推荐算法提供数据支持。
数据爬取:系统可以自动爬取各大漫画平台的漫画数据,包括漫画的图片、简介、评分等信息。
数据清洗:对于爬取到的原始数据进行清洗和过滤,包括去除重复数据、标准化处理等。
数据更新:系统可以更新漫画数据,保证数据的时效性和准确性。
系统管理:
系统管理模块是整个系统的后台管理部分,提供以下功能:
系统设置:管理员可以设置系统的各项参数,包括推荐算法的参数、系统的响应等。
漫画推荐
协同过滤算法
系统总体流程图如下所示:
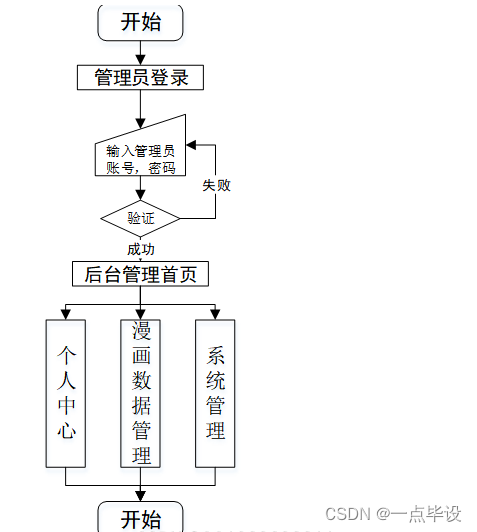
四.部分效果展示
系统用户登录,在登录页面选择需要登录的角色,在正确输入用户名和密码后,进入操作系统进行操作;如图所示。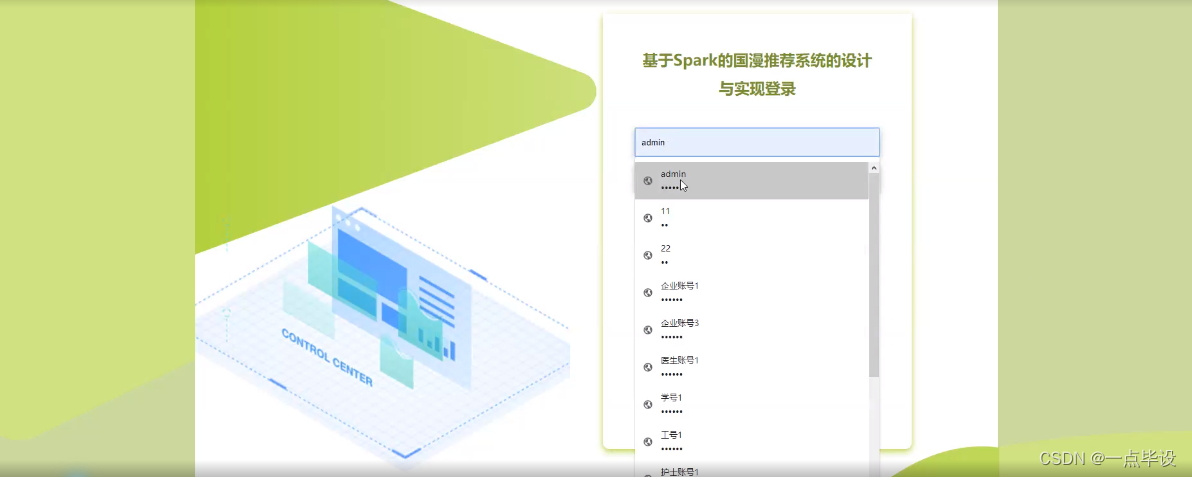
管理员点击漫画数据管理。进入漫画数据页面输入标题、作者、状态、类别和类型可以对漫画数据列表进行查询、删除或爬取数据,并根据需要对漫画数据详细信息进行详情、修改或删除操作,如图所示: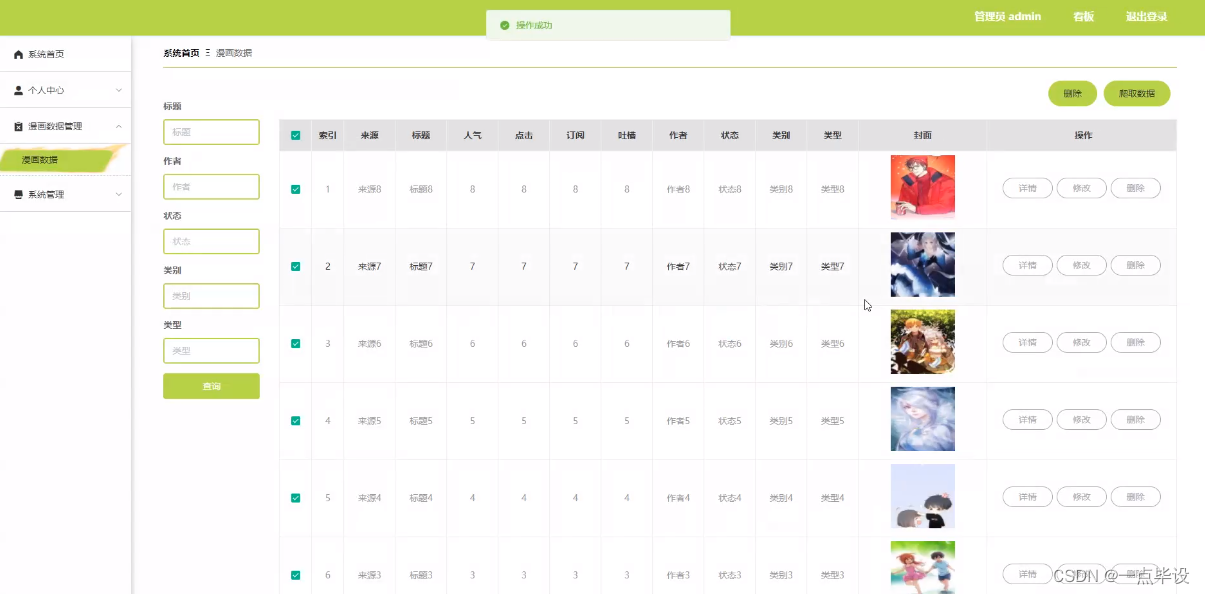
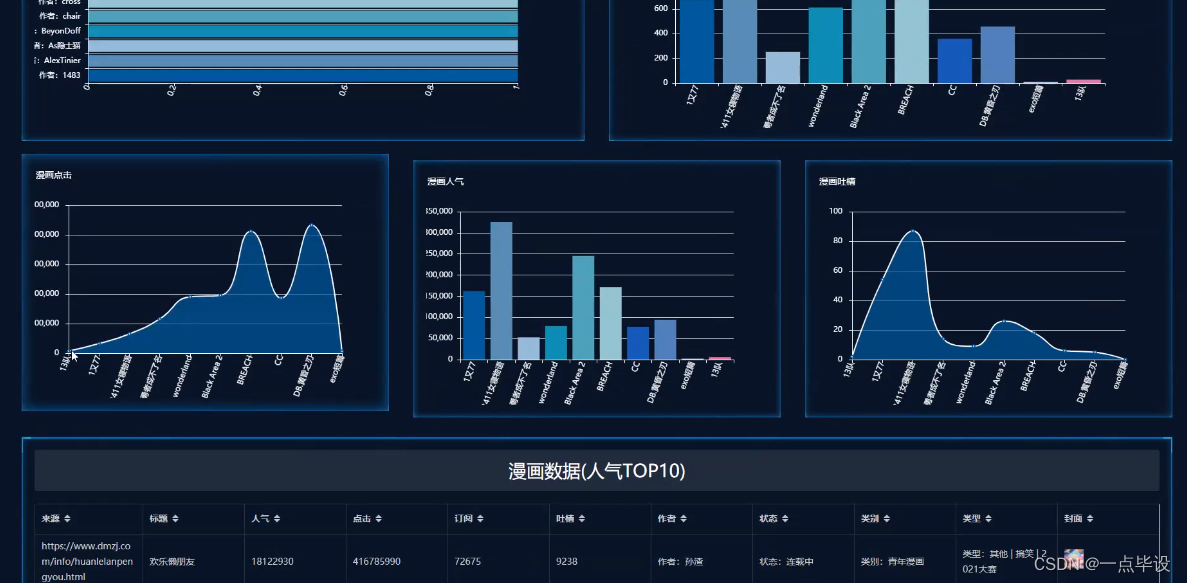
管理员点击爬取数据,点击右上角的看板,进入看板页面可以查看到系统简介、漫画类别、漫画状态、 漫画数据总数、作者分析、漫画订阅、漫画点击、漫画人气、漫画吐槽、漫画数据等实时的数据信息进行分析与可视化,如图所示: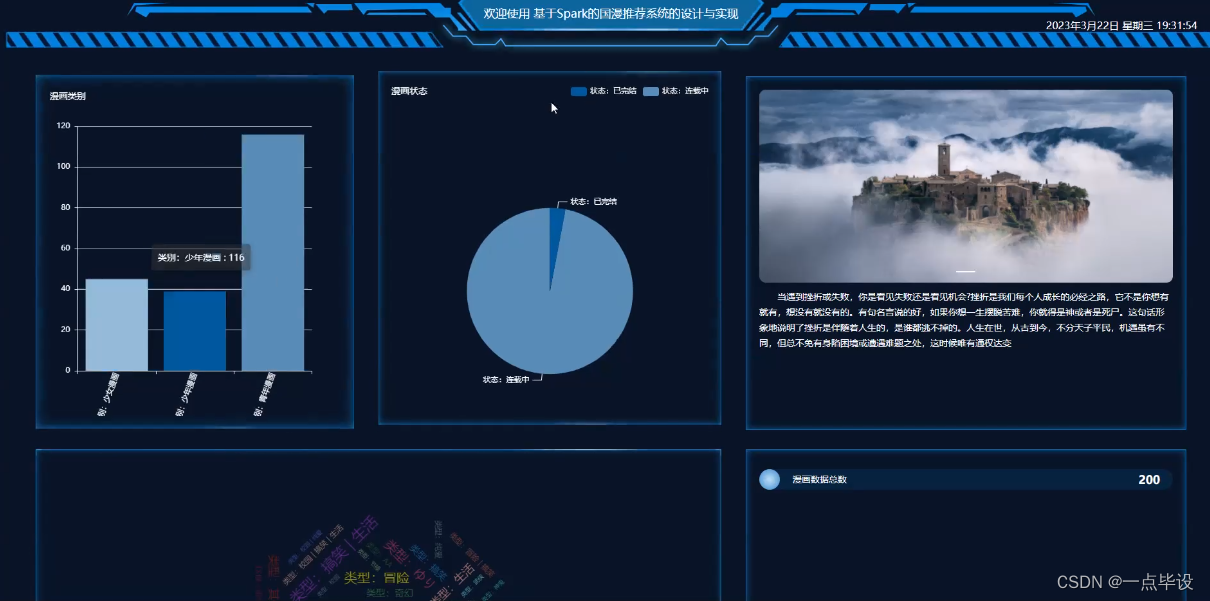
六.部分功能代码
defnews_page(request):'''
'''if request.method in["POST","GET"]:
msg ={"code": normal_code,"msg": mes.normal_code,"data":{"currPage":1,"totalPage":1,"total":1,"pageSize":10,"list":[]}}
req_dict = request.session.get("req_dict")#获取全部列名
columns= news.getallcolumn( news, news)#当前登录用户所在表
tablename = request.session.get("tablename")#authColumn=list(__authTables__.keys())[0]#authTable=__authTables__.get(authColumn)# if authTable==tablename:#params = request.session.get("params")#req_dict[authColumn]=params.get(authColumn)'''__authSeparate__此属性为真,params添加userid,后台只查询个人数据'''try:
__authSeparate__=news.__authSeparate__
except:
__authSeparate__=Noneif __authSeparate__=="是":
tablename=request.session.get("tablename")if tablename!="users"and'userid'in columns:try:
req_dict['userid']=request.session.get("params").get("id")except:pass#当项目属性hasMessage为”是”,生成系统自动生成留言板的表messages,同时该表的表属性hasMessage也被设置为”是”,字段包括userid(用户id),username(用户名),content(留言内容),reply(回复)#接口page需要区分权限,普通用户查看自己的留言和回复记录,管理员查看所有的留言和回复记录try:
__hasMessage__=news.__hasMessage__
except:
__hasMessage__=Noneif __hasMessage__=="是":
tablename=request.session.get("tablename")if tablename!="users":
req_dict["userid"]=request.session.get("params").get("id")# 判断当前表的表属性isAdmin,为真则是管理员表# 当表属性isAdmin=”是”,刷出来的用户表也是管理员,即page和list可以查看所有人的考试记录(同时应用于其他表)
__isAdmin__ =None
allModels = apps.get_app_config('main').get_models()for m in allModels:if m.__tablename__==tablename:try:
__isAdmin__ = m.__isAdmin__
except:
__isAdmin__ =Nonebreak# 当前表也是有管理员权限的表if __isAdmin__ =="是"and'news'!='forum':if req_dict.get("userid")and'news'!='chat':del req_dict["userid"]else:#非管理员权限的表,判断当前表字段名是否有useridif tablename!="users"and'news'[:7]!='discuss'and"userid"in news.getallcolumn(news,news):
req_dict["userid"]= request.session.get("params").get("id")#当列属性authTable有值(某个用户表)[该列的列名必须和该用户表的登陆字段名一致],则对应的表有个隐藏属性authTable为”是”,那么该用户查看该表信息时,只能查看自己的try:
__authTables__=news.__authTables__
except:
__authTables__=Noneif __authTables__!=Noneand __authTables__!={}:try:del req_dict['userid']# tablename=request.session.get("tablename")# if tablename=="users":# del req_dict['userid']except:passfor authColumn,authTable in __authTables__.items():if authTable==tablename:
params = request.session.get("params")
req_dict[authColumn]=params.get(authColumn)
username=params.get(authColumn)break
q = Q()
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize']=news.page(news, news, req_dict, request, q)return JsonResponse(msg)defnews_autoSort(request):'''
.智能推荐功能(表属性:[intelRecom(是/否)],新增clicktime[前端不显示该字段]字段(调用info/detail接口的时候更新),按clicktime排序查询)
主要信息列表(如商品列表,新闻列表)中使用,显示最近点击的或最新添加的5条记录就行
'''if request.method in["POST","GET"]:
msg ={"code": normal_code,"msg": mes.normal_code,"data":{"currPage":1,"totalPage":1,"total":1,"pageSize":10,"list":[]}}
req_dict = request.session.get("req_dict")if"clicknum"in news.getallcolumn(news,news):
req_dict['sort']='clicknum'elif"browseduration"in news.getallcolumn(news,news):
req_dict['sort']='browseduration'else:
req_dict['sort']='clicktime'
req_dict['order']='desc'
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize']= news.page(news,news, req_dict)return JsonResponse(msg)defnews_list(request):'''
前台分页
'''if request.method in["POST","GET"]:
msg ={"code": normal_code,"msg": mes.normal_code,"data":{"currPage":1,"totalPage":1,"total":1,"pageSize":10,"list":[]}}
req_dict = request.session.get("req_dict")if req_dict.__contains__('vipread'):del req_dict['vipread']#获取全部列名
columns= news.getallcolumn( news, news)#表属性[foreEndList]前台list:和后台默认的list列表页相似,只是摆在前台,否:指没有此页,是:表示有此页(不需要登陆即可查看),前要登:表示有此页且需要登陆后才能查看try:
__foreEndList__=news.__foreEndList__
except:
__foreEndList__=Noneif __foreEndList__=="前要登":
tablename=request.session.get("tablename")if tablename!="users"and'userid'in columns:try:
req_dict['userid']=request.session.get("params").get("id")except:pass#forrEndListAuthtry:
__foreEndListAuth__=news.__foreEndListAuth__
except:
__foreEndListAuth__=None#authSeparatetry:
__authSeparate__=news.__authSeparate__
except:
__authSeparate__=Noneif __foreEndListAuth__ =="是"and __authSeparate__=="是":
tablename=request.session.get("tablename")if tablename!="users":
req_dict['userid']=request.session.get("params",{"id":0}).get("id")
tablename = request.session.get("tablename")if tablename =="users"and req_dict.get("userid")!=None:#判断是否存在userid列名del req_dict["userid"]else:
__isAdmin__ =None
allModels = apps.get_app_config('main').get_models()for m in allModels:if m.__tablename__==tablename:try:
__isAdmin__ = m.__isAdmin__
except:
__isAdmin__ =Nonebreakif __isAdmin__ =="是":if req_dict.get("userid"):# del req_dict["userid"]passelse:#非管理员权限的表,判断当前表字段名是否有useridif"userid"in columns:try:passexcept:pass#当列属性authTable有值(某个用户表)[该列的列名必须和该用户表的登陆字段名一致],则对应的表有个隐藏属性authTable为”是”,那么该用户查看该表信息时,只能查看自己的try:
__authTables__=news.__authTables__
except:
__authTables__=Noneif __authTables__!=Noneand __authTables__!={}and __foreEndListAuth__=="是":try:del req_dict['userid']except:passfor authColumn,authTable in __authTables__.items():if authTable==tablename:
params = request.session.get("params")
req_dict[authColumn]=params.get(authColumn)
username=params.get(authColumn)breakif news.__tablename__[:7]=="discuss":try:del req_dict['userid']except:pass
q = Q()
msg['data']['list'], msg['data']['currPage'], msg['data']['totalPage'], msg['data']['total'], \
msg['data']['pageSize']= news.page(news, news, req_dict, request, q)return JsonResponse(msg)defnews_save(request):'''
后台新增
'''if request.method in["POST","GET"]:
msg ={"code": normal_code,"msg": mes.normal_code,"data":{}}
req_dict = request.session.get("req_dict")if'clicktime'in req_dict.keys():del req_dict['clicktime']
tablename=request.session.get("tablename")
__isAdmin__ =None
allModels = apps.get_app_config('main').get_models()for m in allModels:if m.__tablename__==tablename:try:
__isAdmin__ = m.__isAdmin__
except:
__isAdmin__ =Nonebreak#获取全部列名
columns= news.getallcolumn( news, news)if tablename!='users'and req_dict.get("userid")!=Noneand'userid'in columns and __isAdmin__!='是':
params=request.session.get("params")
req_dict['userid']=params.get('id')
error= news.createbyreq(news,news, req_dict)if error!=None:
msg['code']= crud_error_code
msg['msg']= error
return JsonResponse(msg)defnews_info(request,id_):'''
'''if request.method in["POST","GET"]:
msg ={"code": normal_code,"msg": mes.normal_code,"data":{}}
data = news.getbyid(news,news,int(id_))iflen(data)>0:
msg['data']=data[0]if msg['data'].__contains__("reversetime"):
msg['data']['reversetime']= msg['data']['reversetime'].strftime("%Y-%m-%d %H:%M:%S")#浏览点击次数try:
__browseClick__= news.__browseClick__
except:
__browseClick__=Noneif __browseClick__=="是"and"clicknum"in news.getallcolumn(news,news):try:
clicknum=int(data[0].get("clicknum",0))+1except:
clicknum=0+1
click_dict={"id":int(id_),"clicknum":clicknum}
ret=news.updatebyparams(news,news,click_dict)if ret!=None:
msg['code']= crud_error_code
msg['msg']= ret
return JsonResponse(msg)defnews_detail(request,id_):'''
'''if request.method in["POST","GET"]:
msg ={"code": normal_code,"msg": mes.normal_code,"data":{}}
data =news.getbyid(news,news,int(id_))iflen(data)>0:
msg['data']=data[0]if msg['data'].__contains__("reversetime"):
msg['data']['reversetime']= msg['data']['reversetime'].strftime("%Y-%m-%d %H:%M:%S")#浏览点击次数try:
__browseClick__= news.__browseClick__
except:
__browseClick__=Noneif __browseClick__=="是"and"clicknum"in news.getallcolumn(news,news):try:
clicknum=int(data[0].get("clicknum",0))+1except:
clicknum=0+1
click_dict={"id":int(id_),"clicknum":clicknum}
ret=news.updatebyparams(news,news,click_dict)if ret!=None:
msg['code']= crud_error_code
msg['msg']= retfo
return JsonResponse(msg)defnews_update(request):'''
'''if request.method in["POST","GET"]:
msg ={"code": normal_code,"msg": mes.normal_code,"data":{}}
req_dict = request.session.get("req_dict")if req_dict.get("mima")and"mima"notin news.getallcolumn(news,news):del req_dict["mima"]if req_dict.get("password")and"password"notin news.getallcolumn(news,news):del req_dict["password"]try:del req_dict["clicknum"]except:pass
error = news.updatebyparams(news, news, req_dict)if error!=None:
msg['code']= crud_error_code
msg['msg']= error
return JsonResponse(msg)defnews_delete(request):'''
批量删除
'''if request.method in["POST","GET"]:
msg ={"code": normal_code,"msg": mes.normal_code,"data":{}}
req_dict = request.session.get("req_dict")
error=news.deletes(news,
news,
req_dict.get("ids"))if error!=None:
msg['code']= crud_error_code
msg['msg']= error
最后
最新计算机毕业设计选题篇-选题推荐(值得收藏)
计算机毕业设计精品项目案例-200套(值得订阅)
版权归原作者 一点毕设 所有, 如有侵权,请联系我们删除。