
目录
随着互联网的快速发展,网络数据成为了新时代的"黑金"。然而,获取这些数据并非易事,尤其是面对各种各样的技术和政策壁垒。
一、获取网络数据的挑战
在大数据时代,数据被视为推动生产力增长的核心资源。然而,获取网络数据的过程远比人们想象的要复杂和具有挑战性。
1、反爬虫机制的威胁
互联网平台普遍部署了反爬虫机制,以防止未经授权的数据抓取。各种验证码、IP限制、动态网页加载、复杂的JavaScript验证。这些措施虽然保护了网站的数据安全,但也让合法的数据采集面临巨大的挑战。反爬虫机制不仅需要额外的人力和时间去处理,还可能导致采集效率的严重下降,甚至直接使采集活动无法进行。
2、IP封锁与访问频率控制
频繁访问同一网站会触发服务器的警报,导致IP被封锁,很多网站还设置了访问频率限制。对于需要收集大量数据的企业来说,IP封锁带来的麻烦不言而喻。一旦某个IP被封锁,整个数据采集工作就可能被迫中断,这不仅会影响采集效率,还会增加运营成本。此外,某些网站可能使用地域性IP封锁的手段,进一步增加了数据采集的复杂性。
3、数据隐私与法律合规
数据采集不仅面临技术挑战,还需要应对隐私保护和法律合规的问题。如何在合法合规的前提下获取数据,成为了企业面临的巨大难题。此外,越来越多的国家和地区开始制定自己的数据保护法规,进一步增加了数据采集的合规难度。企业需要在采集过程中考虑数据的来源、用途和保管方式,确保不会侵犯用户的隐私权。
二、亮数据动态代理:数据采集的最佳拍档
在众多代理服务中,亮数据动态代理凭借其高效、稳定的服务表现,逐渐成为数据采集行业的佼佼者。那么,亮数据动态代理到底有何独特之处?
1、高质量IP资源
亮数据动态代理提供海量的高质量IP资源,涵盖全球各个国家和地区。这意味着你可以轻松实现全球范围的数据采集,绕过地域限制。无论目标数据在哪里,亮数据都能为你提供最佳的访问途径。亮数据的IP资源不仅数量庞大,而且质量优异,确保了数据采集的高成功率和高稳定性。
2、智能调度与自动切换
亮数据的动态代理服务具备智能调度功能,能够根据目标网站的响应情况,自动切换IP,最大限度地降低被封禁的风险。这种灵活的调度机制,就像是为数据采集提供了一道"保护罩",让整个过程更加安全高效。智能调度功能还能根据目标网站的访问量动态调整采集策略,以适应不同场景下的数据需求。
3、合规与隐私保护
亮数据不仅注重技术优势,还严格遵守各国的数据保护法律,帮助企业在合法合规的前提下进行数据采集。亮数据确保每一次的数据采集都在法律允许的范围内进行,避免了潜在的法律风险。亮数据还通过匿名化处理和数据加密等手段,保护用户的隐私和数据安全,让企业可以放心地进行数据采集。
4、多场景应用支持
无论是市场调研、舆情监测,还是电子商务数据分析,亮数据动态代理都能提供稳定的解决方案。对于电商平台的价格监控、社交媒体的舆情抓取、甚至是金融数据的收集,亮数据都能通过灵活的代理策略提供高效支持。不仅如此,亮数据还能根据不同的应用场景提供定制化的解决方案,帮助企业在最短的时间内获得最有价值的数据。

三、使用亮数据代理 IP进行网络数据抓取
我们采用亮数据 IP 代理服务,其核心优势在于提供高频 IP 切换,使得抓取过程具有较高的匿名性和动态性,从而有效绕过目标网站的防御机制,减少因频繁请求而导致的封禁风险。
1、引入 requests 库
首先,我们需要引入 requests 库,并定义一个代理 IP。以下假设代理的 IP 为 http://127.0.0.1:8000,代码如下:
import requests
proxy ="http://127.0.0.1:8000"
接下来,我们通过 requests.get() 方法的 proxies 参数来配置代理 IP,以便通过代理发送请求:
response = requests.get(url, proxies={"http": proxy,"https": proxy})
这种方式允许在遭遇封禁时迅速切换到新的 IP,维持抓取的连续性与有效性。
2、使用自动化浏览器的解决方案
使用代理 IP 来突破封禁后,我们进一步探讨如何抓取网页中的邮箱地址。这里使用的是 Selenium 库,一种功能强大的自动化浏览器操作工具。Selenium 能够精确模拟用户操作,执行浏览器的点击、输入以及表单提交等功能,使得爬取网页内容更加智能化。
首先,我们导入必要的 Selenium 库和其他工具:
from selenium import webdriver
import re
import time
(1)配置 Chrome 浏览器的选项,并准备要爬取的文章链接列表:
chrome_options = webdriver.ChromeOptions()
chrome_options.binary_location ="C:\Users\78571\AppData\Local\Google\Chrome\Application"# 请根据自己的 Chrome 安装路径进行调整# 启动 ChromeDriver
driver = webdriver.Chrome(options=chrome_options)# 准备爬取的文章链接列表
article_links =['https://pubmed.ncbi.nlm.nih.gov/39500323/','https://pubmed.ncbi.nlm.nih.gov/37313461/']# 用于存储提取到的邮箱地址
email_addresses =[]
(2)利用 Selenium,接下来我们逐一打开文章链接,获取页面源代码,并通过正则表达式提取其中的邮箱地址:
# 遍历所有文章链接for link in article_links:
driver.get(link)
time.sleep(2)# 等待页面加载# 使用正则表达式从页面中提取邮箱地址
email_matches = re.findall(r'[\w\.-]+@[\w\.-]+\.[a-zA-Z]+', driver.page_source)# 将找到的邮箱地址添加到列表中if email_matches:for email in email_matches:
email_addresses.append(email)
(3)关闭浏览器并打印出所有提取到的邮箱地址:
# 关闭浏览器
driver.quit()# 打印所有提取到的邮箱地址print(email_addresses)
通过这种方式,Selenium 在每个页面中模拟用户的浏览行为,并自动提取邮箱地址。如此一来,大量的邮箱提取工作变得简单、自动化且高效。
四、采集CSDN中关于AI的文章
在当今信息爆炸的时代,获取高质量的AI相关文章犹如在浩瀚的知识海洋中捞针。然而,借助亮数据(Bright Data)的Web Scraper IDE,这一过程变得如同在自家后院采摘果实般轻松。
亮数据的Web Scraper IDE是一款专为开发者设计的集成开发环境,提供了强大的网页抓取功能。它建立在亮数据强大的代理基础设施之上,能够从任何地理位置收集大量数据,同时绕过复杂的机器人验证和验证码处理。
1、如何使用Web Scraper IDE采集CSDN的AI文章
- 目标识别:首先,确定需要抓取的目标网站和页面。在本例中,我们的目标是CSDN网站上的AI相关文章。
- 爬取策略:制定爬取策略,包括爬取深度、频率和路径选择。需要注意的是,避免给目标网站带来过大负载,并遵守网站的robots.txt规则。
- 请求发送与数据获取:通过Web Scraper IDE,发送HTTP请求获取目标网页的HTML内容。
- 内容解析与数据处理:使用内置的解析工具,提取所需的文章标题、作者、发布时间和内容等信息。
- 数据存储:将提取的数据存储到本地数据库或文件中,便于后续分析和使用。
2、具体操作
(1)选择采集工具Web Scraper IDE

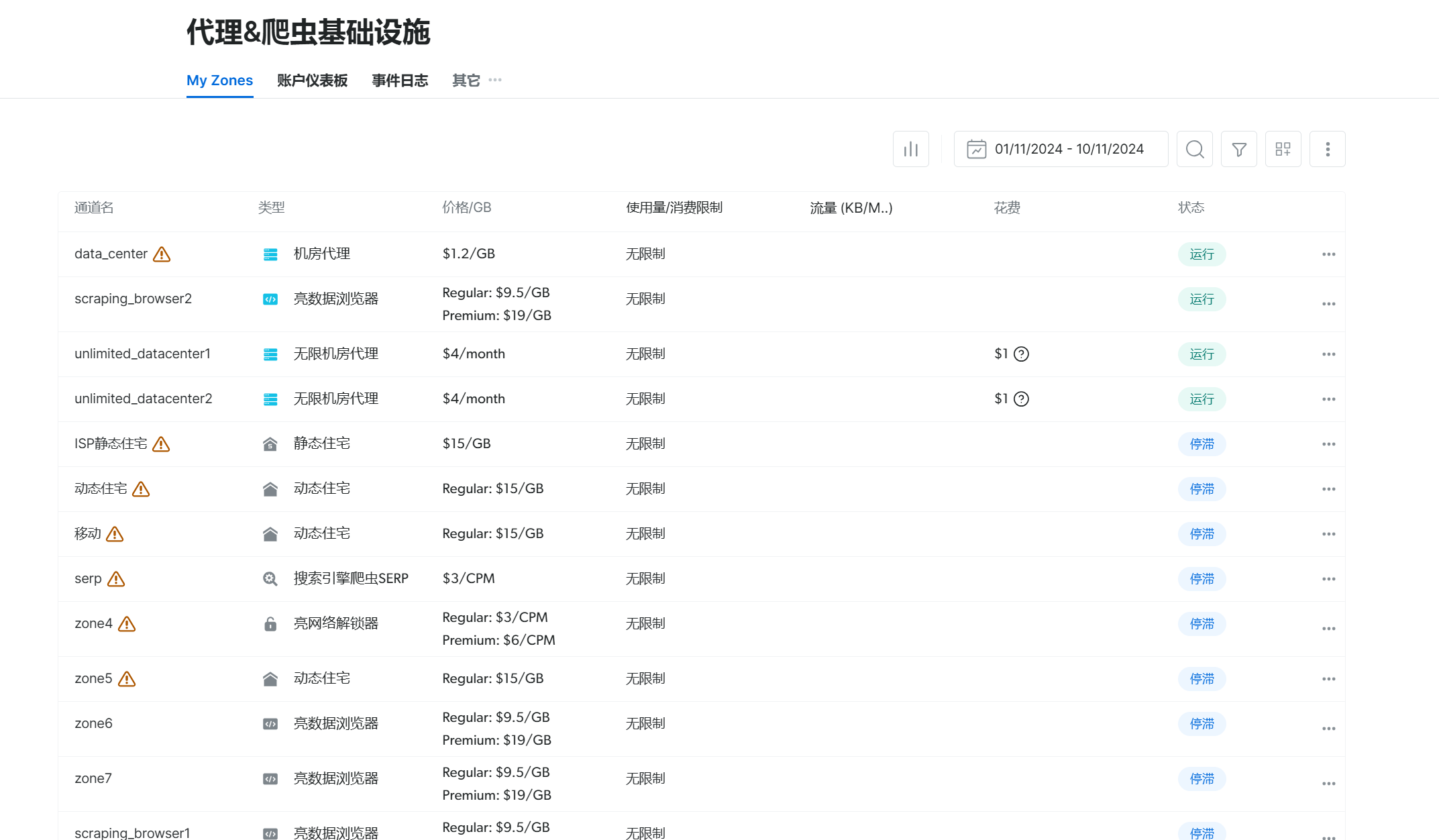
(2)选择按需定制数据集
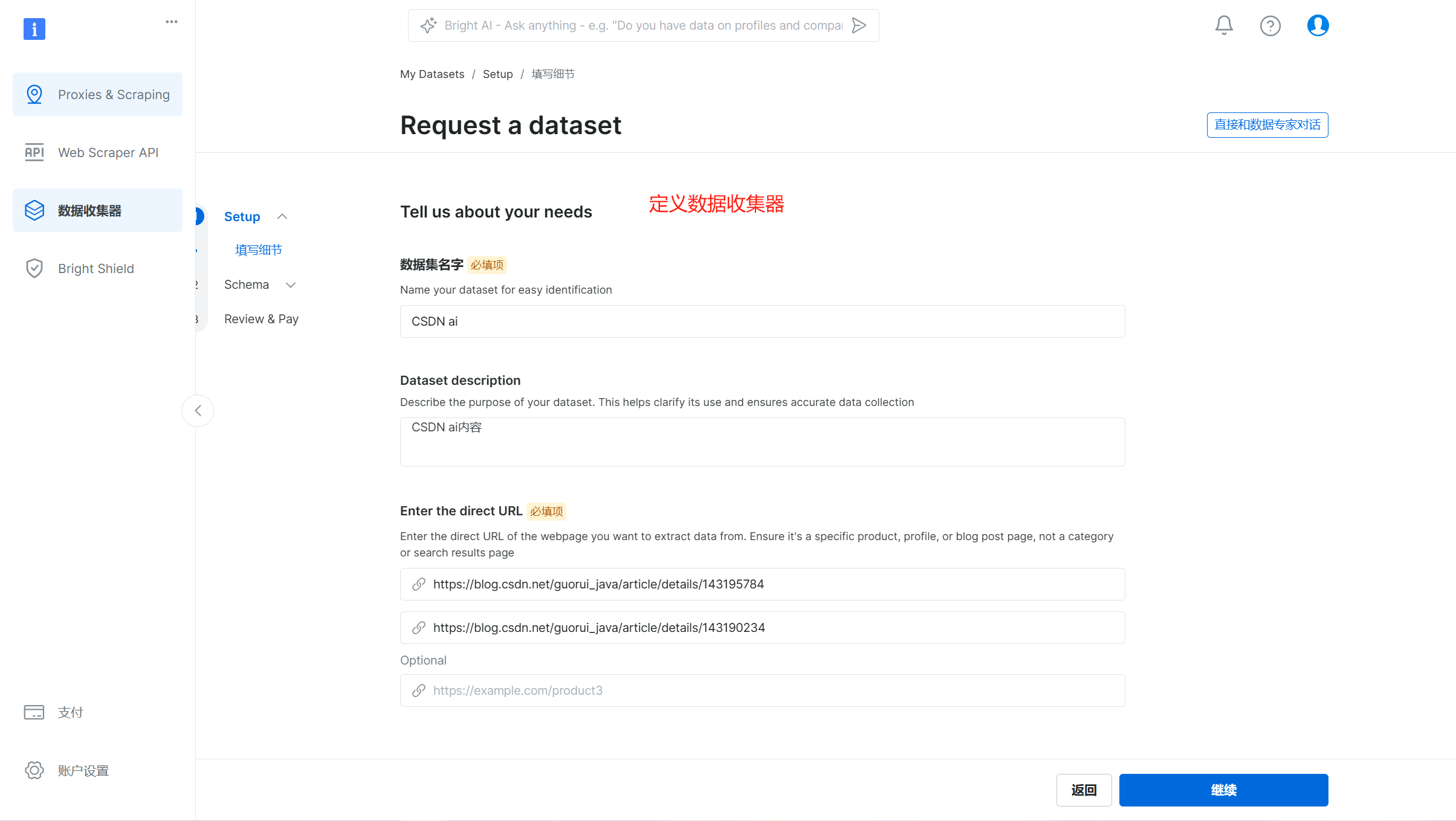
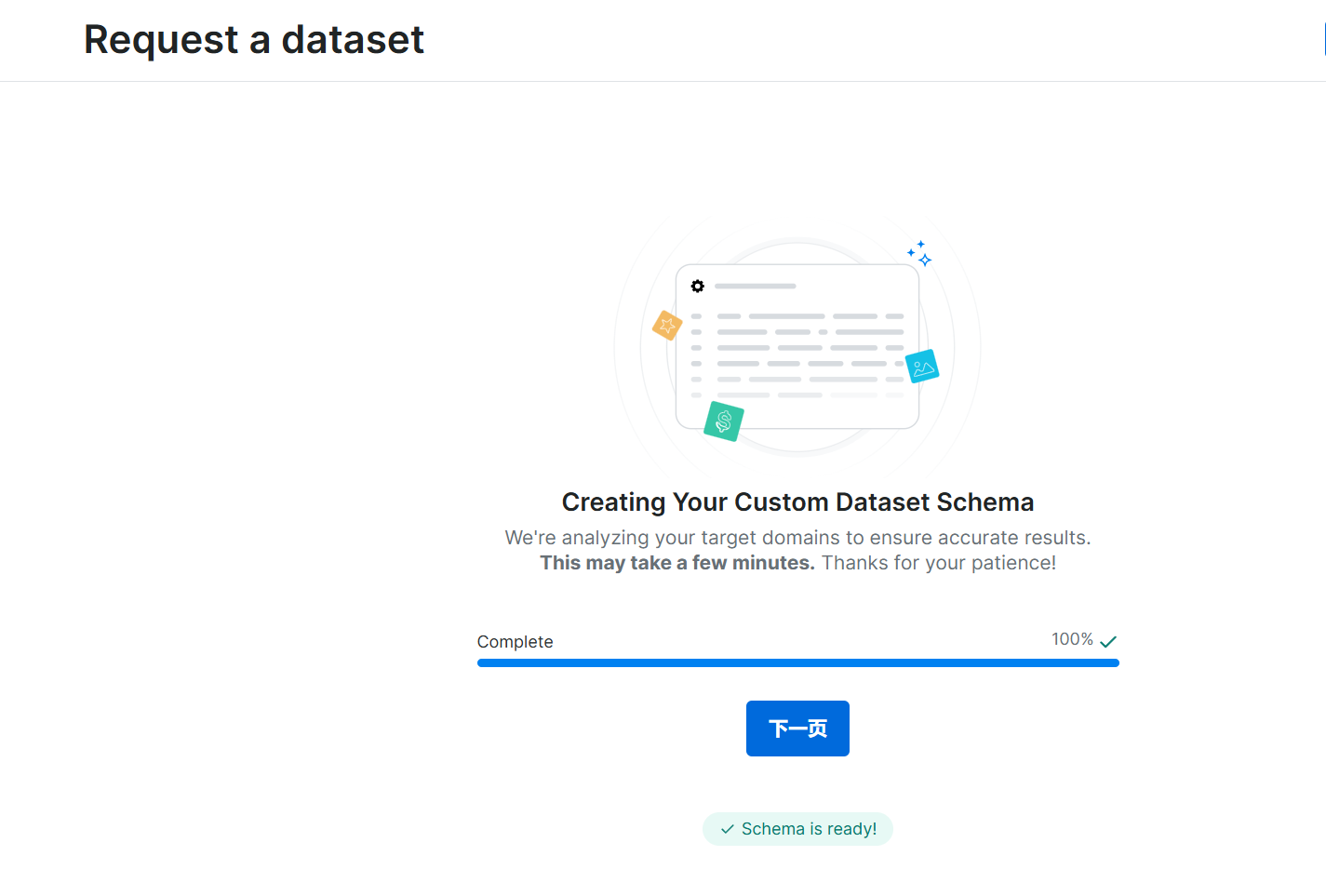
(3)保存提交,提交后就会自动抓取,抓取完成后点击查看
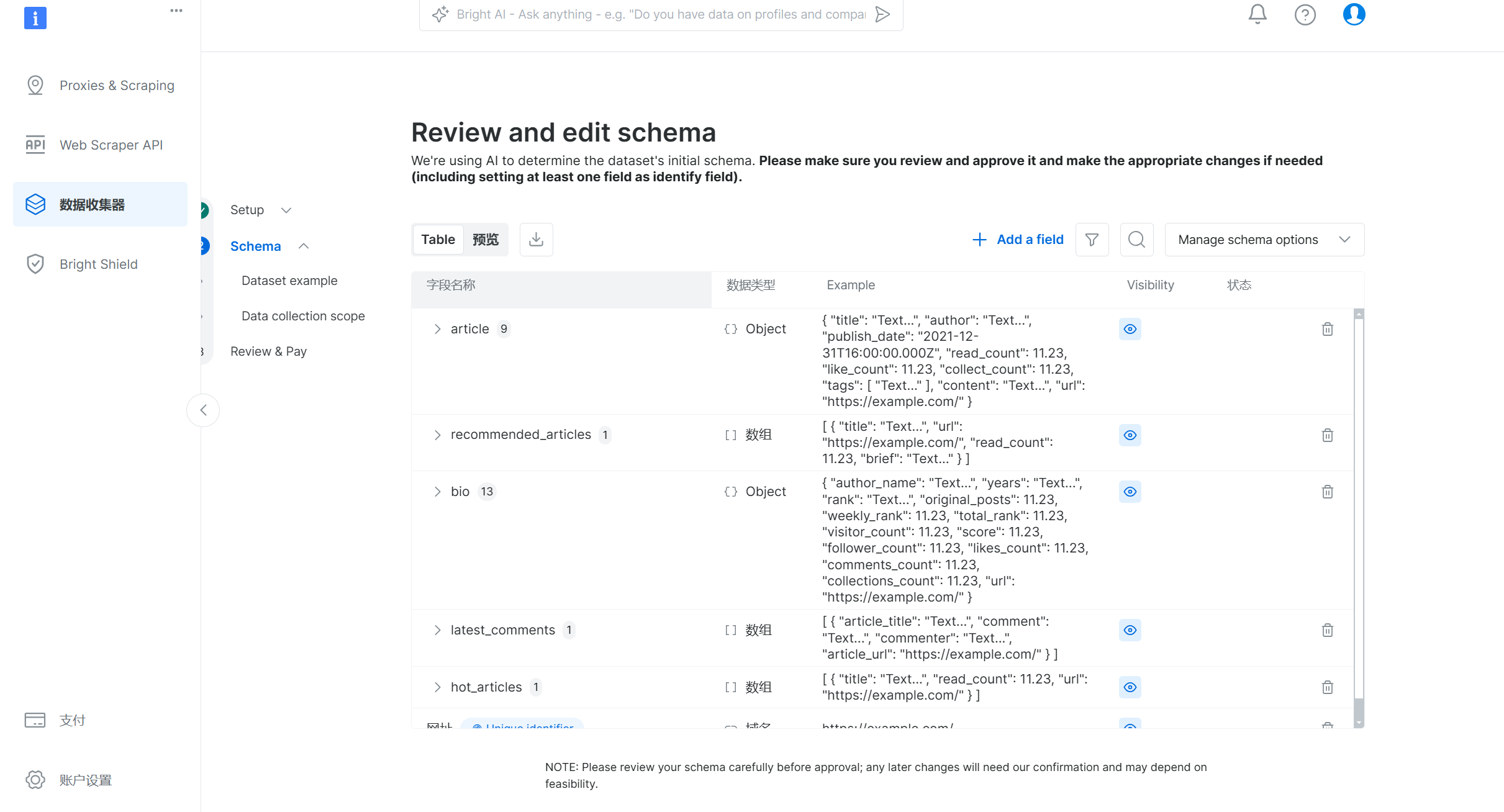
(4)可以对抓取到的数据,进行预览和下载
五、亮数据重磅推出“免费试用优惠”及“充值优惠升级”
1、即日起,注册新用户,可以获得2+5共7美金免费试用产品的机会。
2、新客户首次充值优惠,充多少送多少,最高500美金。
数据中心代理和静态代理,最近做了大幅的价格和收费模式的调整,颇具竞争力,有兴趣的可以上公司主页了解详情。
以上充值赠送活动,针对数据中心和静态代理同样有效!
亮数据为此次内容提供额外优惠:现在点击注册,可以享受以上所有的价格优惠的同时,再送15美金特别试用金!
六、AI时代,亮数据也集成了ChatGPT
1、无需审核,直接使用
自即日起,普通新用户注册亮数据,只需一步!再无等待审核的烦恼!提交注册信息后,就可以成功注册,直接登录产品页面。只有在用户使用一些特殊产品的时候,才会有后续审核流程。进入亮数据主页www.bright.cn后,右上角点击“注册”按钮后,弹出的以下注册信息界面。请完整填写所有信息。
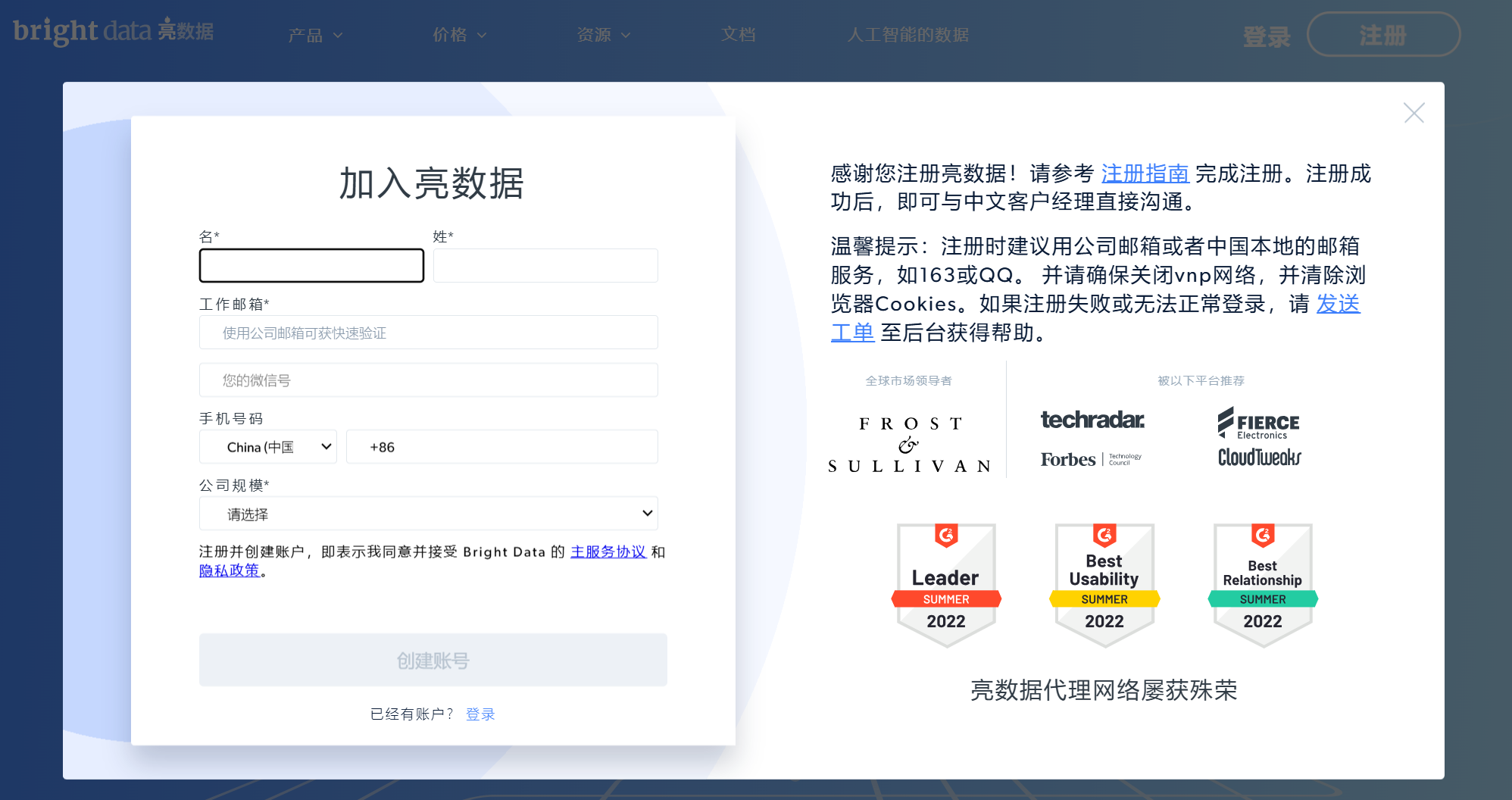
填写完上图中的注册页面信息,点击“新建账户”提交后,网页会显示(如下图)- 验证邮件已发送至您的注册邮箱。
很快(小编亲测30秒内)您就可以在注册邮箱里(如下图),找到一封名为“Bright Data - Welcome”的验证邮件,点击登录,即可直接进入产品界面,开始使用。
修改密码
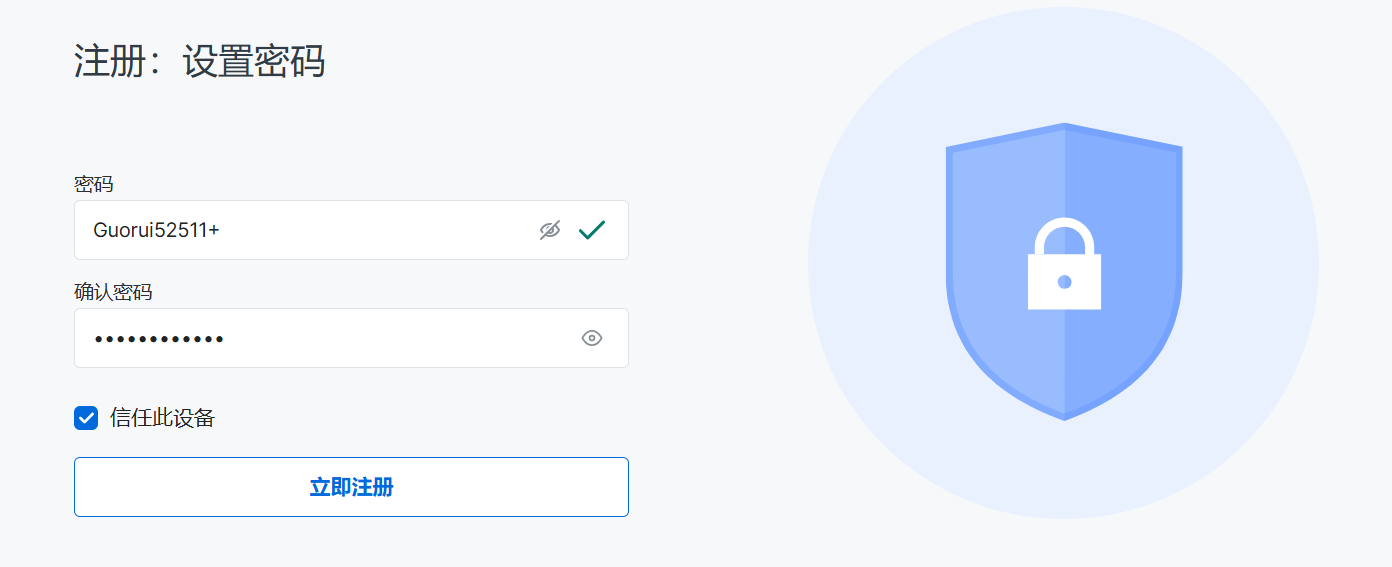
此时完成所有注册步骤均已完成!
2、集成ChatGPT
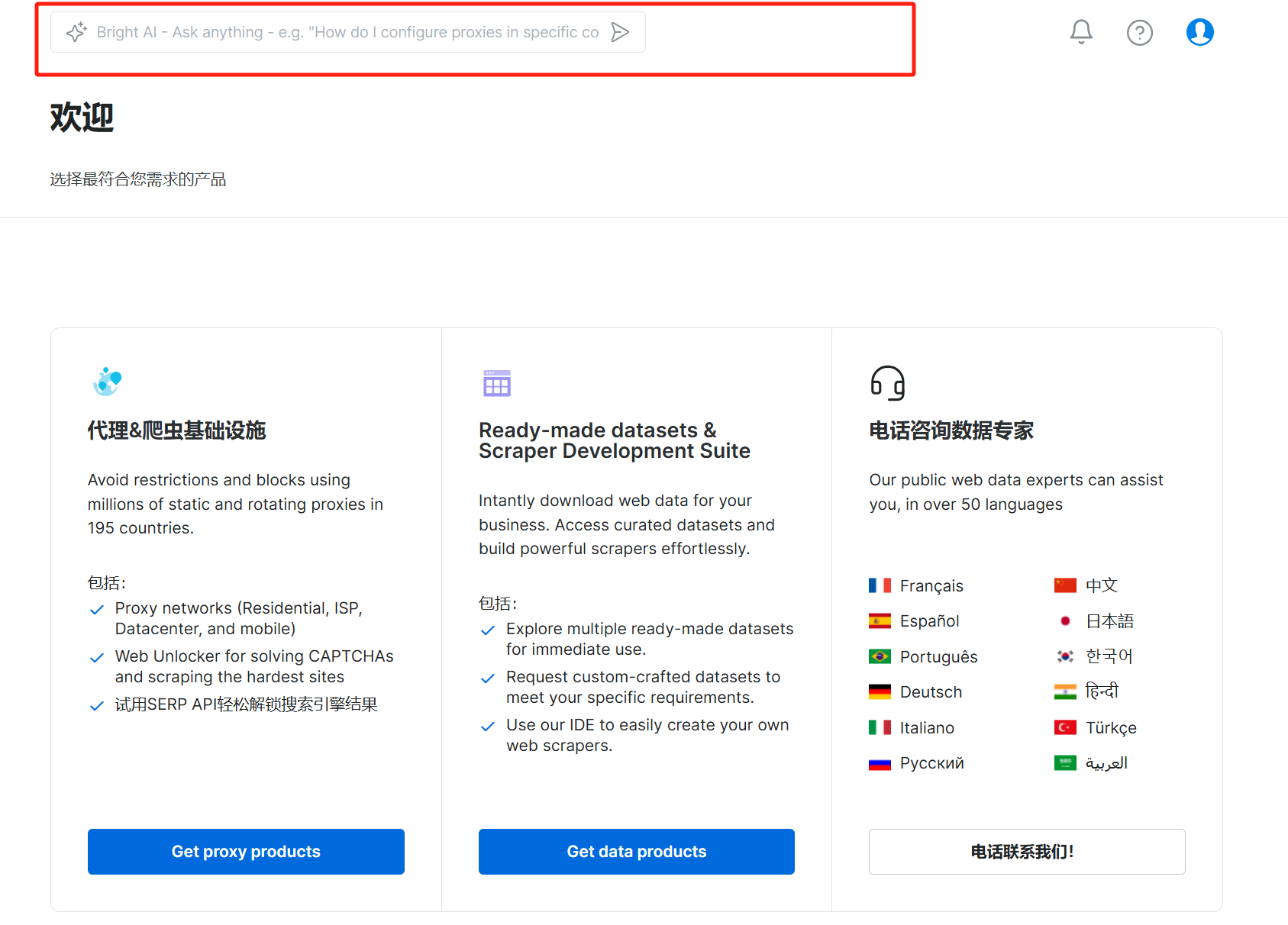
许多新手用户,刚开始接触亮数据的产品,对于代理及相关技术不熟悉,一时不知如何操作。我们的软件研发团队在产品里内嵌了ChatGPT,您可以直接以中文提出问题,获得相关的帮助。
您可以在初始登录界面的上方,找到这个可以输入文字的小框,开始用AI查询并获得帮助。
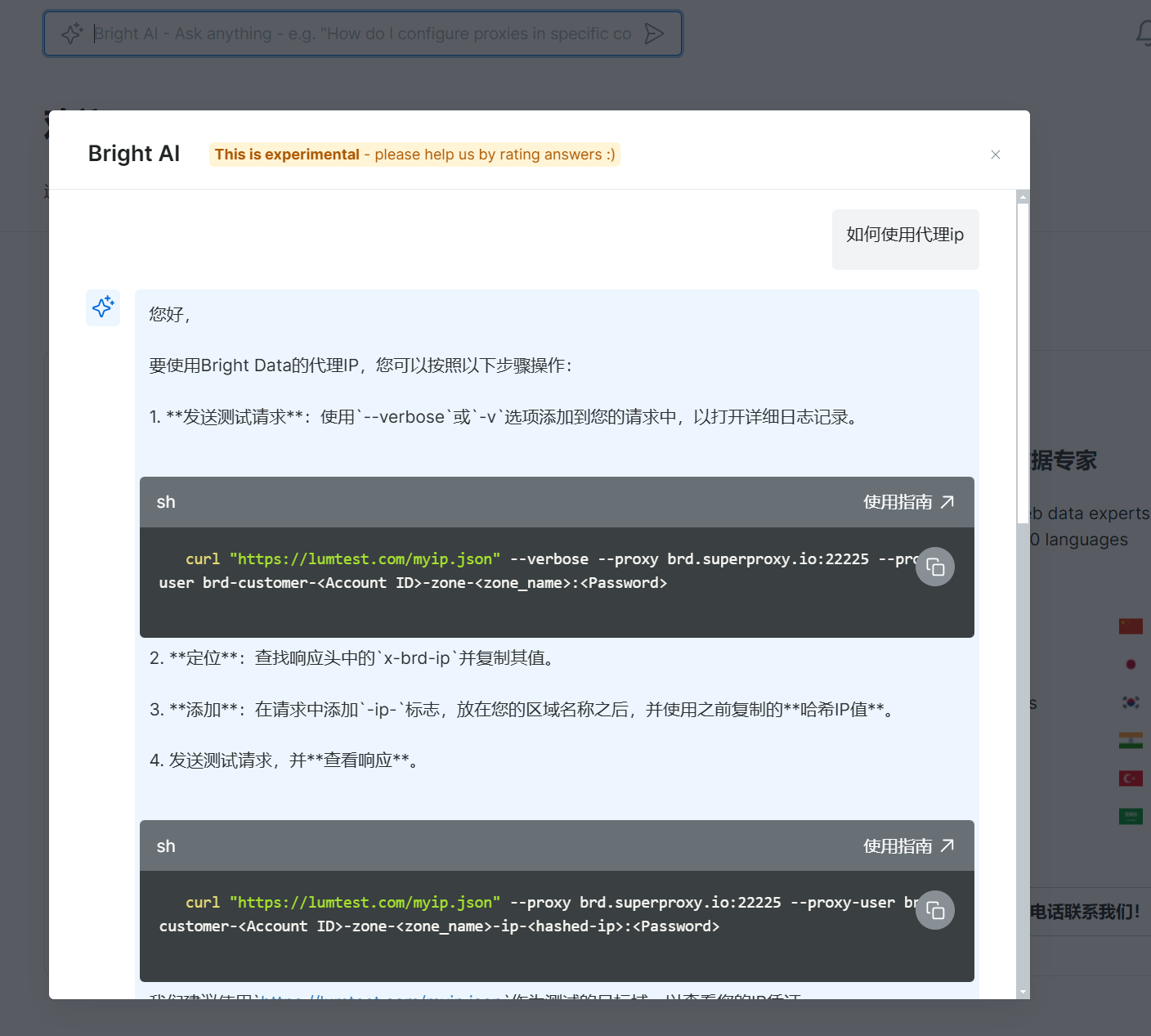
输入问题后,稍等片刻,就会弹出相应的帮助内容回答。这里我们以“如何选择代理服务”举例,可以看到系统处理后,自动弹出中英文双语的内容,并提供了相关的链接,供您进一步参考。
七、总结:数据采集的未来展望
面对网络数据获取的种种挑战,代理网络的崛起无疑为数据采集开辟了一条全新的道路。通过动态代理的使用,我们可以更加灵活、高效地获取所需数据,而亮数据动态代理则是这一过程中不可或缺的重要伙伴。未来,随着技术的不断发展,数据采集的方式也将更加智能化和合规化,让数据真正成为推动业务发展的"发动机"。
所以,如果你还在为数据采集的困难发愁,不妨考虑一下代理网络,特别是像亮数据这样可靠的动态代理服务。毕竟,在互联网的世界里,数据才是最终的赢家。而代理网络,正是帮助你赢得这场胜利的秘密武器。代理网络和数据采集的结合,将为你的业务带来无限可能,助你在数据驱动的竞争中占据有利位置。
版权归原作者 哪 吒 所有, 如有侵权,请联系我们删除。