
背景
距离上篇打带你实现自己迷你chatgpt文章,到现在已经过去快两个月。自制mini chatgpt文章一直没有更新,原因有二:1.一直在找合适体量表现不错模型 2.公司内部太卷了,没太多时间好好梳理文章。这篇文章会给大家介绍一些大模型训练的概念,然后会给大家介绍pretrain model在自己数据集合上的微调学习。
大家一直在讲大模型,但是感觉大家也只是在讲大模型。到现在似乎还没看到一篇文章介绍大模型的整个工艺流程是如何的,1.需要经历哪几个步骤 2.有哪些手段学习知识 3.如何做特定域知识增强 4.如何去让机器更懂人(适应不同人表达方式,精准给出他们想要答案;其实就是增强智能体的模糊适应性)。
这篇文章会尝试去回答上面几个问题,当然一些技术细节和技术流程没法完全覆盖到。原因有二:1.不同情况解决方案不同,只能讲个大方向 2.公司也不允许我把所有细节公布,毕竟这个关系钱财之事。
大模型训练流程
1.pretain model:这个阶段大部分情况是设计成无监督或者弱监督学习,让模型成为博览群书有知识的通才
2.模型微调:这部分主要对pretrain model做少量标签或者知识补充,让通才把自己的知识结构做梳理成为体系
3.上游任务学习:这部分任务训练模型专业技能,让模型在有通识时也有更强工作力,同时也会重塑通识体系
4.对齐学习:渊博且有能力,但是还得让它更懂人话,更容易和他沟通,所以需要做alignment,这部分现在主流是RLHF
上面的几个过程并非只做一轮,经常是需要做很多轮的迭代才可能让模型有较好表现。上面的流程分工在开始的几轮是顺序进行,有相对明显的界限。但是越到后面的迭代边界越模糊,往往是同时几种方法一起上。所以大家知道有这些流程和手段就好,不需要去纠结他们清晰边界。
大模型训练手段
finetune
Fine-tune的核心思想是利用在大型数据集(例如ImageNet、COCO等)上训练好的预训练模型,然后使用较小数据集(小于参数数量)对其进行微调[3]。这样做的优势在于,相对于从头开始训练模型,Fine-tune可以省去大量的计算资源和时间成本,提高了计算效率,甚至可以提高准确率[1][2]。
finetune是指在预训练模型的基础上,针对特定任务进行微调,以提高模型的性能。Fine-tune的具体方法有多种,但一般而言,可以通过调整模型的层数、调整学习率、调整批量大小等方式进行微调[2]。
Finetune的优势在于不用完全重新训练模型,从而提高效率,因为一般新训练模型准确率都会从很低的值开始慢慢上升,但是finetune能够让我们在比较少的迭代次数之后得到一个比较好的效果。
虽然Fine-tune有很多优势,但也存在一些不足之处。例如,Fine-tune需要大量的数据集才能提高模型的性能,这可能会导致一些任务难以实现。此外,Fine-tune的性能很大程度上依赖于预训练模型的质量和适用性,如果预训练模型和微调数据集之间存在差异,则Fine-tune可能无法提高模型性能[1]。
未来,Fine-tune技术将继续得到广泛的应用。一方面,随着深度学习模型的不断发展和改进,预训练模型的质量和适用性将会不断提高,从而更加适用于Fine-tune技术。另一方面,Fine-tune技术也将有助于解决一些实际应用中的难题,例如小数据集、数据集标注困难等问题[1][3]。

prompt learn
Prompt Learning的基本概念:Prompt Learning是一种自然语言处理技术,它通过在预训练模型的输入前面加上简短的提示文本来引导模型完成不同的任务[1]。这些提示文本通常是问题或指令形式,用来告诉模型如何理解输入并生成输出。Prompt Learning的优点在于它可以用少量的数据完成多个任务[2]。
Multi-Prompt Learning:Multi-Prompt Learning是Prompt Learning的一种扩展形式,它可以将多个Prompt应用于一个问题,达到数据增强或问题分解等效果[1]。常见的Multi-Prompt Learning方法包括并行方法、增强方法和组合方法[2]。并行方法将多个Prompt并行进行,并通过加权或投票的方式将多个单Prompt的结果汇总;增强方法会将一个与当前问题相似的案例与当前输入一起输入,以便模型能够更准确地进行预测;组合方法则将多个Prompt组合在一起使用,以便训练模型进行更复杂的任务[2]。
如何选择合适的预训练模型:选择合适的预训练模型是Prompt Learning的关键步骤之一。在选择模型时,需要考虑以下因素:任务类型、数据集、模型大小和训练时间等[1]。通常情况下,预训练模型的大小越大,它在各种任务上的表现也越好,但同时需要消耗更多的计算资源[1]。
如何调整Prompt的训练策略:Prompt Learning的另一个关键步骤是如何调整Prompt的训练策略。可以采用全数据下单纯提高模型效果的方法,也可以采用few-shot/zero-shot下使用Prompt作为辅助的方法,或者固定预训练模型并仅训练Prompt[[1]。
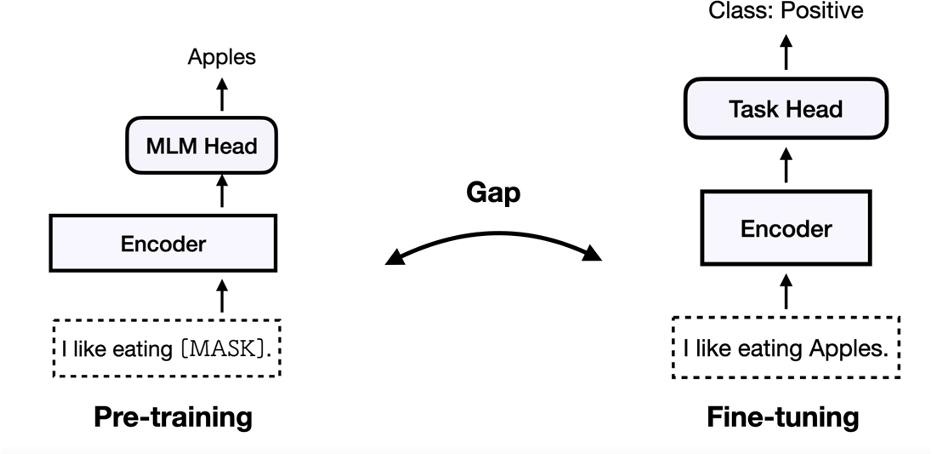
如上图所示,finetune的做法pre-traning使用PLMs作为基础编码器,finetune下游任务时候添加额外的神经层以进行特定任务,调整所有参数。预训练和微调任务之间存在差距。

如上图所示prompt,在pre-traing和finetuning下游任务时候使用同样的MLM任务。弥合模型调整和预训练之间的差距来增强 few-shot 学习能力。使用PLMs作为基础编码器,添加额外的上下文(模板)和[MASK]位置,将标签投影到标签词(verbalizer),缩小预训练和微调之间的差距。
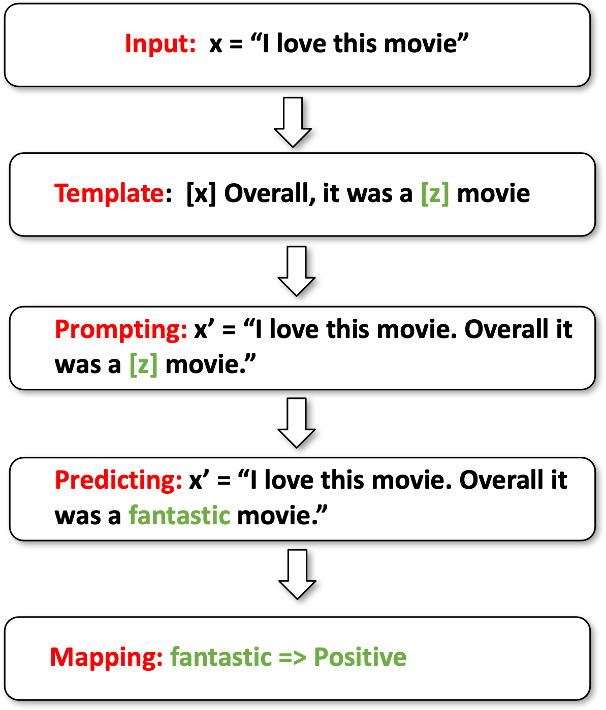
上面是用户评论问题转prompt的一个流程示意图,包括模版选择、模版包裹、MLM输出词选择、词映射到评论正负性这个几个流程。
模版选择
人工模版设计包括,就是专家根据对问题的了解,设计一套模版把专用问题的解决方法转成适合自然语言生成方式的表述方法。下面就是人针对QA问题做的结构化模版,把QA问题转成生成模型生成输出的问题。

自动搜索生成prompt模版,选择一个元模版,然基于现有单词的梯度搜索生成最优prompt模版。
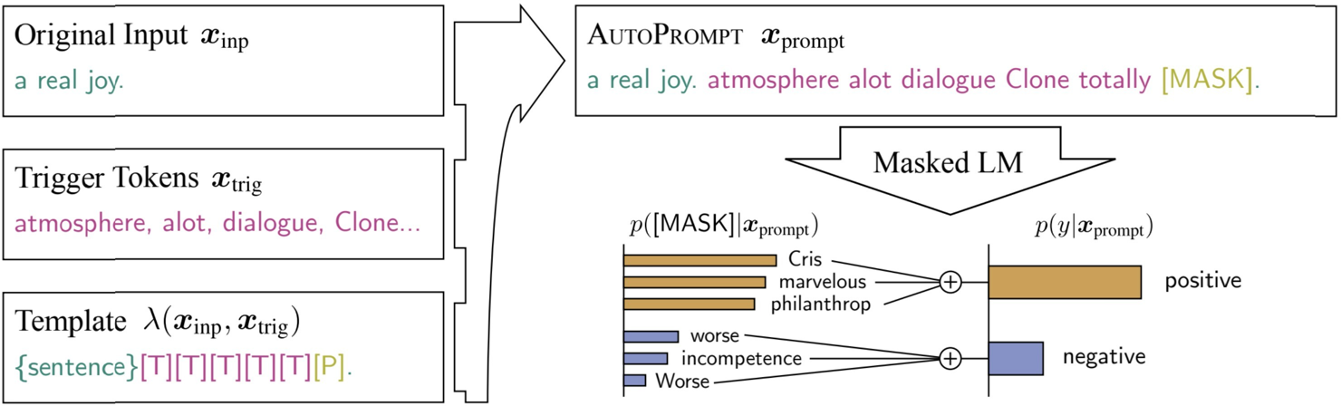
利用T5对输入的多个句子,做模版自动化生成。操作如下图,大致步骤:1.利用已有模版训练一个T5模型,让模型学会如何通过语料(把所有任务输入拉平作为向量输入,输出就是最后模版)2.把任务输入作为输入,用训好的模型做模版生成
让pre-model自动化的生成模版,思路如下,fix主pre-train模型,让模型对有标注的任务做训练,模型学习后改的输入的句子embbeding,当然输入原句是不改的,只是让模型改非输入句子部分,最后就可以自动化的学习到最有prompt模版了。当然这模版有可能人是看不懂的。
P-tuning v1:将提示用于输入层(使用重新参数化)
P-tuning v2:将提示用于每个层(如前缀调整)

填入词选择
在做prompt任务设计适合,把任务都转成生成模式了,所以会存在怎么把生成的东西映射到想要结果这样一个转化过程,这中间词表的设计和选择对最后结果影响很大,所以我们需要对输出深词作设计。
Positive: great, wonderful, good.. Negative: terrible, bad, horrible…
手动生成

人脑爆生成一波关键词或者句子短语,然后利用已经有的知识库去召回更多相关的词、概念或者短语句子,然后再对召回的这些词、句子短语作排序精选。
自动化生成

和自动化模版生成很像,模型固定,用打标注的数据来训练,梯度反传时候改的是输入embedding的词。
delta learn
整体思路,通过增加一些控制参数,来让表现力强大的大模型可以可控的学习和使用。用个例子作比喻:控制论里面,用简单线性控制矩阵,来控制庞大且复杂系统;这个比喻不一定完全准确,因为deta learn其实还是可以合并到原模型,那其实就是对所学知识链路的重整理了。
实际操作就是使用增量调整来模拟具有数十亿参数的模型,并优化一小部分参数。
这张图表示的意思是,我还是我,但是我经过简单变化和学习后,我就可以成为多样不一样的我,但是pre-train模型是不动的,动的只是参入的参数,眼睛、一幅、装饰。很形象的表示训练过程,但是感觉对于表意不够。但这图传的很广,这边也就顺带放上来了。

Addtion:方法引入了额外的可训练神经模块或参数,这些模块或参数在原始模型中不存在;
Specification:方法指定原始模型或过程中的某些参数变为可训练,而其他参数被冻结;
Reparameterization:方法通过变换将现有参数重新参数化为参数高效形式。

detaleran很重要的3个因素:
1.插哪:和原有网络序列性插入,还是桥接式插入
2.怎么插:只插入某些层,还是整个网络每层都插入
3.多大矩阵控制:参入控制层参数多大,一bit、还是原参数0.5%

不同的插入方式、不同参数对于模型效果差异还是比较大的,这个大家可以在实际作模型微调时候去体会,上面表是对不同的方法做的数学抽象表示。大家在实操时候发现没有思路时候会过来看这个表,在结合问题想想会有不一样帮助。
实操部分
这部分是以chatglm 6B模型来做实验,具体的代码在这个链接:GitHub - liangwq/Chatglm_lora_multi-gpu: chatglm多gpu用deepspeed和
模型不一定非的要chatglm、llama或者其他什么模型都是可以的。用到了huggingface的peft来做delta学习,deepspeed做多卡分布式训练。
测试过:2卡A100 80G,8卡 A100 80G硬件配置数据和速度如下
50万 selefinstruct的数据,2卡、32核cpu、128G mem
batch 2 ,gd 4 也就是每个batch size=16;2个epoch lora_rank=8,插入参数量在7M左右,要训练20个小时
8卡差不多在5小时左右
微调,模型收敛很稳定效果不错
代码讲解:
数据处理逻辑
def data_collator(features: list) -> dict:
len_ids = [len(feature["input_ids"]) for feature in features]
longest = max(len_ids) + 1
input_ids = []
attention_mask_list = []
position_ids_list = []
labels_list = []
for ids_l, feature in sorted(zip(len_ids, features), key=lambda x: -x[0]):
ids = feature["input_ids"]
seq_len = feature["seq_len"]
labels = (
[-100] * (seq_len - 1)
+ ids[(seq_len - 1) :]
+ [tokenizer.eos_token_id]
+ [-100] * (longest - ids_l - 1)
)
ids = ids + [tokenizer.eos_token_id] * (longest - ids_l)
_ids = torch.LongTensor(ids)
attention_mask, position_ids = get_masks_and_position_ids(
ids, seq_len, longest, _ids.device, gmask=False
)
labels_list.append(torch.LongTensor(labels))
input_ids.append(_ids)
attention_mask_list.append(attention_mask)
position_ids_list.append(position_ids)
input_ids = torch.stack(input_ids)
labels = torch.stack(labels_list)
attention_mask = torch.stack(attention_mask_list)
position_ids = torch.stack(position_ids_list)
return {
"input_ids": input_ids,
"labels": labels,
"attention_mask": attention_mask,
"position_ids": position_ids,
}
插入lora,允许对在其它数据训练的lora加入训练,意思就是可以部分数据部分数据分开训练lora,需要可以把训练好的lora整合做共同训练,非常方便牛逼。对于机器配置不够的朋友绝对是好事
# setup peft
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=finetune_args.lora_rank,
lora_alpha=32,
lora_dropout=0.1,
)
model = get_peft_model(model, peft_config)
if finetune_args.is_resume and finetune_args.resume_path:
print("=====>load lora pt from =====》:", finetune_args.is_resume, finetune_args.resume_path)
model.load_state_dict(torch.load(finetune_args.resume_path), strict=False)
accelerate整合部分,因为它不会保留checkpoint,所以我hardcode写了每2000步保留一个checkpoint,这部分还没来得急把只保留最新两个checkpount代码写上去,所以会产生很多哥checkpount文件夹,这块如果大家用不到可以注释了,或则自己写下保留两个的代码。当然后面我会update。
if i%2000 ==0 and accelerator.is_main_process:
#accelerator.wait_for_everyone()
path = training_args.output_dir+'/checkpoint_{}'.format(i)
os.makedirs(path)
accelerator.save(lora.lora_state_dict(accelerator.unwrap_model(model)), os.path.join(path, "chatglm-lora.pt"))
#save_tunable_parameters(model, os.path.join(path, "chatglm-lora.pt"))
i +=1
小结
1.介绍了预训练大模型的训练流程是怎么样的
2.介绍了常用的训练手段
3.详细介绍了两种主流的预训练手段原理:promt、delta
4.给了一个multi-gpu chatglm训练的例子
预告:
下面一篇文章会给大家介绍RLHF部分,大家可以关注我
版权归原作者 远洋之帆 所有, 如有侵权,请联系我们删除。