
技术清单:
** · Yolov5 **
** · DeepSort**
** · Segementation/背景减除法**
** · GaitSet**
** · CASIA-B**
Yolov5+DeepSort

yolov5用于目标检测,DeepSort用于通过目标检测所获得的bbox作为输入实现行人追踪。给每个单独的行人打出专属ID。
行人追踪onnx成品
Segementation/背景减除法
** 此方法是用来获取剪影图的,具体在GaitSet中有所介绍。**
GaitSet
基本原理:
本步态识别系统主要基于GaitSet模型进行实现的。
**介绍:Gaitset是具有泛化能力的, 这一点和图像分类网络完全不一样,Gaitset不是学训练集中人的步态特征,而是学习提取步态特征的能力,也就是如何在一堆人里(数据库里)找到与探针最相近的那个数据。所以正在使用的时候,数据库是随时可以改变且不需要再次训练的。**
损失函数(三元组损失函数Triplet Loss):
最小化锚点和具有相同身份的正样本之间的距离,最小化锚点和具有不同身份的负样本之间的距离。
(Triplet Loss的目标:Triplet Loss的目标是使得相同标签的特征在空间位置上尽量靠近,同时不同标签的特征在空间位置上尽量远离,同时为了不让样本的特征聚合到一个非常小的空间中要求对于同一类的两个正例和一个负例,负例应该比正例的距离至少远margin)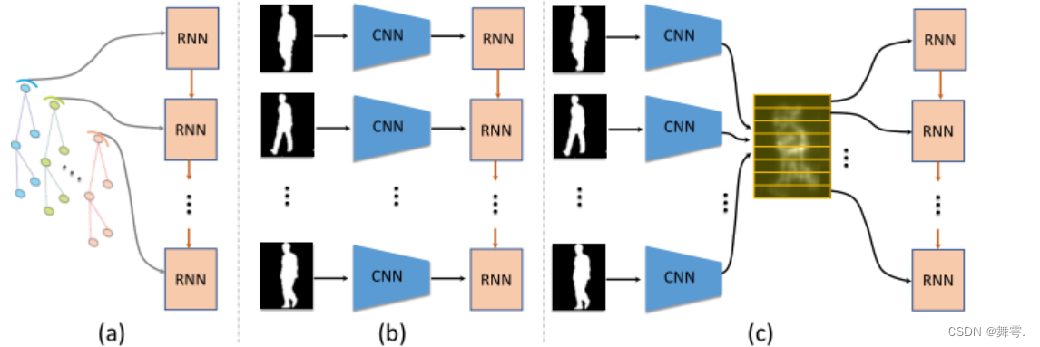
剪影图:
我们对每一个包含人物的64*64像素的图像裁剪后进行cv2图像处理,使其处理成只包含人物轮廓黑白剪影图,这个工作是图像**显著化处理和语义分割**的简化版.
** 深度学习推荐方法:分割:**
** 机器学习推荐方法:背景减除法**
步态特征:
非连续不相关,是一个人30张步态图像中任取5张做为代表为消除其被遮挡或者剪影图裁剪有误的误差.
外形混合步态识别:

步态识别是需要对数据集进行归类,如A人为A人集合,B人为B人集合,这样的输入顺序,但是这与摄像头(video)经过YOLOV5部分读入的人物信息不一致的,实际上读入的信息是 第一帧:甲,乙,丙。第二帧:甲,乙,丙,......我们先要判断出每一帧甲乙丙等三幅图下和ABC等人的对应关系,如甲:B,乙:A,丙:C(不一定是顺序对应)然后再对每一帧出现的A,B,C等进行归类.如A人集合,B人集合,C人集合. 然后得到对应每人的集合后,并且假设每个人的集合的大小都大于10,即每个人都有10张以上的图片后,再将其投入Gaitset网络,这样就从人—图片字典,变成了人—特征向量字典,我们先得到目标人物步态的特征向量,通过余弦相似度与其余的每个人都进行计算,最终得到相似度最为显著的为依照目标人物步态的步态试别.(即相似度不仅要与目标人物步态特征向量相似度高,还要在实时系统中随帧数增加变化中最为稳定,这里采用假设检验,3sigma原则,即计算相对于其他人与目标人物的相似度后得出相似度μ+3sigma,目标人物再次出现的相似度要>μ+3sigma)
迁移学习:
我们运用的数据集是CASIA-B包括15004个步态序列,在gaitset网络中训练完成之后,将其网络训练好的参数作为迁移学习的初始参数再进行微调.
【output】:
与目标步态相似度显著表:以下的表对应:
第一部分:当前存在的人物步态字典中每个人与测试目标的相似度(欧氏距离)字典
第二部分:目标与测试目标1的相似度,目标及其其相似度的假设检验值

CASIA-B数据集:
CASIA-B是一个比较经典的步态识别数据集(2006),其包含124个目标(subjects),每个目标有3种步行情况和11个角度。3种步行情况指“normal(NM)”、“walking with bag(BG)”、“wearing coar or jacket(CL)”,其中每个目标有6段NM序列、2段BG序列、2段CL序列。11个角度是指0°、18°、…、180°。因此,这124个目标中,每个目标都有11×(6+2+2)=110段序列。经我观察,每段序列长度不定,一般80~100帧。

本文转载自: https://blog.csdn.net/qq_51831335/article/details/126577572
版权归原作者 大气层煮月亮 所有, 如有侵权,请联系我们删除。
版权归原作者 大气层煮月亮 所有, 如有侵权,请联系我们删除。