
CVPR2022刚刚结束,作为影响力最广的视觉盛会,今年又有一批优秀的工作被展示出来。相信关注视觉最新研究进展的各位小伙伴,已经磨拳擦掌,准备向CVPR2023投稿了。基于今年的工作,到底哪些领域是CVPR关注的热点?哪些领域的工作,接受度更高,oral的比例更大呢?基于CVPR官方最新的统计信息,我将跟大家聊聊CVPR的一些研究热点,希望对那些计划投下一轮CVPR的同学提供一点参考信息。
1. 十大热点研究领域
首先,我们基于oral论文的统计信息,按照接收论文比重以及所述领域进行排序,得到的十个热点领域,包括:多角度三维视觉,图像与视频合成,识别检测分类与检索,深度网络结构设计,视觉与语言处理交叉,低质量数据视觉分析,形状分析,迁移学习,视频分析与理解,姿态估计。
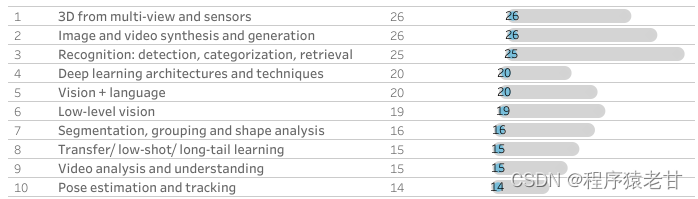
图1. 十大研究热点领域(Oral)
当我们统计全部接收论文时,统计数据在顺序上会有一点变化,包括:识别检测分类与检索,图像与视频合成,多角度三维视觉,低质量数据视觉分析,视觉与语言处理交叉,形状分析,迁移学习,深度网络结构设计,自监督与非监督学习,视频分析与理解。
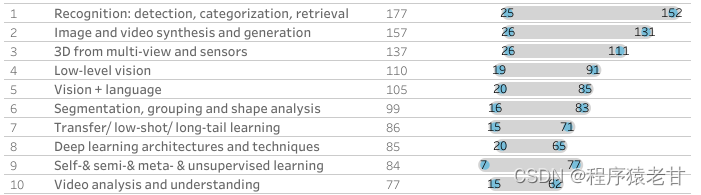
图2. 十大研究热点领域(All)
可以看到,两个排序对应的研究热点问题,具有极高的重复性。结合两个表,偏重于应用层面的角度对热点进行总结,我从中选出五个热点研究方向,供计划投稿的同学参考:
- 多角度三维视觉
- 图像与视频合成
- 识别检测分类与检索
- 视觉与语言处理交叉
- 低质量数据视觉分析
2. Best Paper
CVPR2022的Best paper list包含四篇文章,分别为:
**Best Paper Award: **Learning to Solve Hard Minimal Problems
**Best Paper Honorable Mention: **Dual-Shutter Optical Vibration Sensing
**Best Student Paper Award: **EPro-PnP: Generalized End-to-End Probabilistic Perspective-n-Points for Monocular Object Pose Estimation
**Best Student Paper Honorable Mention: **Ref-NeRF: Structured View-Dependent Appearance for Neural Radiance Fields
最佳论文为《Learning to Solve Hard Minimal Problems》。粗看了下,不是很懂,大概是在对优化问题领域做了一些偏理论性的工作,引入了几何优化的一些工具。《Dual-Shutter Optical Vibration Sensing》是关于三维激光扫描的技术。《EPro-PnP: Generalized End-to-End Probabilistic Perspective...》基于多点透视理论,提出一种从图像中估计物体的三维姿态的方法。《Ref-NeRF》基本就是NeRF算法的变种研究。从最佳论文的侧重可以知道,CVPR比较青睐三维视觉相关研究。另外,会前呼声较高的Kaiming老师的《Masked Autoencoders Are Scalable Vision Learners》也是值得深入学习的。基于MAE提出一种基于patch预测的编解码结构,对于数据图像内容理解具有极好的预测与重建性能。该论文被列为最佳论文候选。
3. 个人关注
因为我个人最近一直在做颜色迁移,光照优化一类的工作,所以比较关注low-level vision领域。今年CVPR在该领域录取了19篇oral以及91篇poster,接收文章数不能算少。我将对应的19篇oral文章抄写在这里,方便之后学习。
[1] Robust Equivariant Imaging: A Fully Unsupervised Framework for Learning To Image From Noisy and Partial Measurements. (去噪+超分辨率用于图像增强技术)
[2] Bijective Mapping Network for Shadow Removal. (消除影子)
[3] Event-Aided Direct Sparse Odometry. (稀疏点云加强)
[4] MAXIM: Multi-Axis MLP for Image Processing.(通用图像质量增强算法)
[5] Details or Artifacts: A Locally Discriminative Learning Approach to Realistic Image Super-Resolution.(超分辨率)
[6] Dual Adversarial Adaptation for Cross-Device Real-World Image Super-Resolution. (超分辨率)
[7] ELIC: Efficient Learned Image Compression With Unevenly Grouped Space-Channel Contextual Adaptive Coding.
[8] Discrete Cosine Transform Network for Guided Depth Map Super-Resolution. (超分辨率)
[9] Deep Rectangling for Image Stitching: A Learning Baseline.(图像拼接)
[10] CamLiFlow: Bidirectional Camera-LiDAR Fusion for Joint Optical Flow and Scene Flow Estimation. (光流优化)
[11] Toward Fast, Flexible, and Robust Low-Light Image Enhancement. (低光增强)
[12] Faithful Extreme Rescaling via Generative Prior Reciprocated Invertible Represe-ntations.
[13] Learning Trajectory-Aware Transformer for Video Super-Resolution. (超分辨率)
[14] SphereSR: 360deg Image Super-Resolution With Arbitrary Projection via Continuous Spherical Image Representation.(超分辨率)
[15] Parametric Scattering Networks. (优化的学习结构)
[16] Target-Aware Dual Adversarial Learning and a Multi-Scenario Multi-Modality Benchmark To Fuse Infrared and Visible for Object Detection. (低光环境下的对象探测)
[17] Learning to Deblur Using Light Field Generated and Real Defocus Images. (去模糊)
[18] Burst Image Restoration and Enhancement. (图像重建)
[19 ]Restormer: Efficient Transformer for High-Resolution Image Restoration. (去模糊)
在low-level vision领域,超分辨率仍然占有较大的比重。一些工作包括去模糊,质量增强,细节重建等,本质上还是和超分辨率技术有紧密的联系。看来,未来做low-level vision,大概率要利用到超分辨率算法。从部分论文可以看出,三维视觉已经结合到low-level vision领域。针对深度图,全景照片等具有三维属性的数据,进行细节重建,运动补偿等计算,也是很不错的研究方向。
版权归原作者 程序猿老甘 所有, 如有侵权,请联系我们删除。