

八大链表OJ题带你手撕单链表
1. 移除链表元素

方法一:(不带哨兵位的)
代码:
需要考虑的情况:
- 正常情况
- 链表连续几个节点存储的值都是val
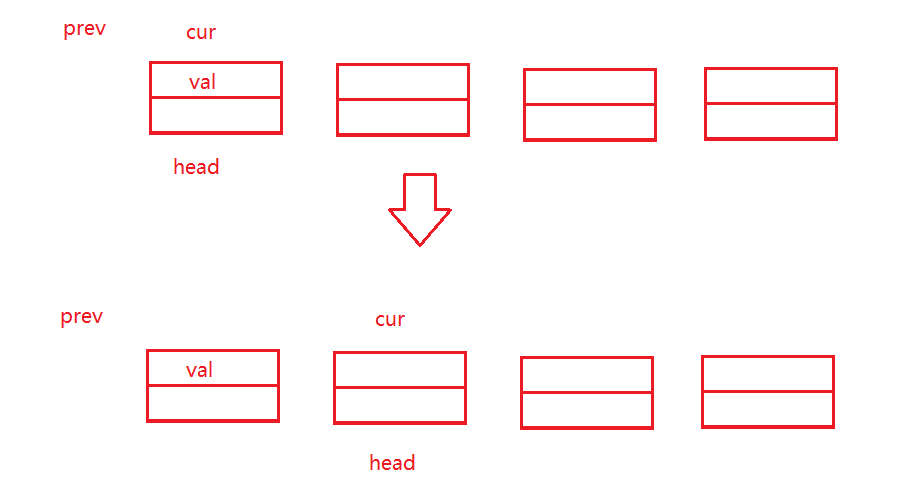
- 链表最开始的节点存储的值是val
图示:
正常情况:(经画图之后,正常情况能够处理链表中连续几个节点存储的值都是val的情况)
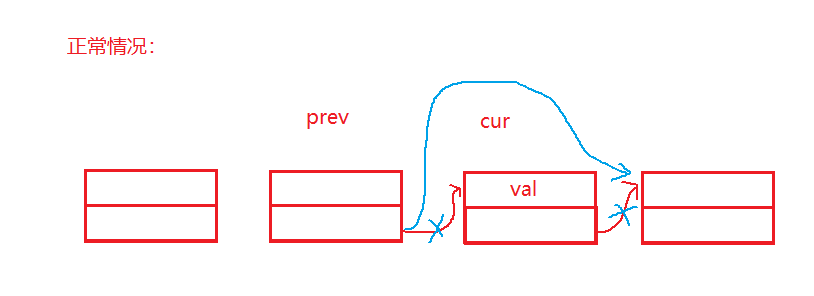
头节点存储值为val的情况:
structListNode*removeElements(structListNode* head,int val){structListNode*prev =NULL;structListNode*cur = head;while(cur){if(cur->val==val){if(prev==NULL){structListNode* next = cur->next;free(cur);
cur = next;
head = cur;}else{
prev->next = cur->next;free(cur);
cur = prev->next;}}else{
prev = cur;
cur = cur->next;}}return head;}
方法二:(带哨兵位的)
与前面一种方法进行相比,这种方法更为简单,操作起来难度较小并且代码更为简洁,不需要进行区分上面的三种情况。
代码:
structListNode*removeElements(structListNode* head,int val)//带哨兵位的{structListNode*new=malloc(sizeof(structListNode));new->next = head;structListNode*prev =new;structListNode*cur = head;while(cur){if(cur->val==val)//需要删除的节点{structListNode*next = cur;//next用来存放cur当前的地址,方便后面进行释放
cur = cur->next;
prev->next = cur;free(next);}else//不需要删除的节点{
prev = cur;
cur = cur->next;}}structListNode*tmp =new->next;//暂时存储需要返回的地址free(new);//把开辟的哨兵位的空间释放掉return tmp;}
2. 反转链表
方法一:(三个指针反转方向)
图示:
思路:逐个向后进行遍历,在遍历的同时将next指针的指向变为指向前一个指针,同时返回尾节点(反转后新链表的头节点)
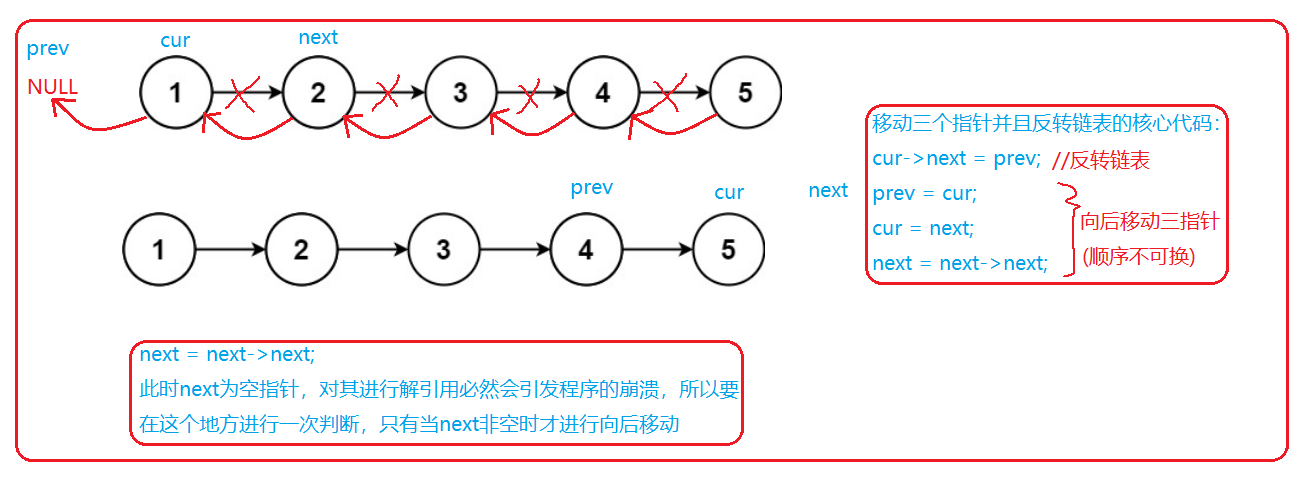
structListNode*reverseList(structListNode* head){if(head==NULL)//当链表尾空时,返回的是空链表{return head;}else{structListNode*prev =NULL;structListNode*cur = head;structListNode*next = head->next;while(cur){
cur->next = prev;
prev = cur;
cur = next;if(next)
next = next->next;}return prev;//返回prev的原因是:当cur为空节点时,cur位于尾节点的下一个,而位于cur的前一个自然就是尾节点,即新的头节点}}
方法二:(头插法)
思路:遍历上面的链表,把节点拿下来头插,但是不创建新的节点。
图示:
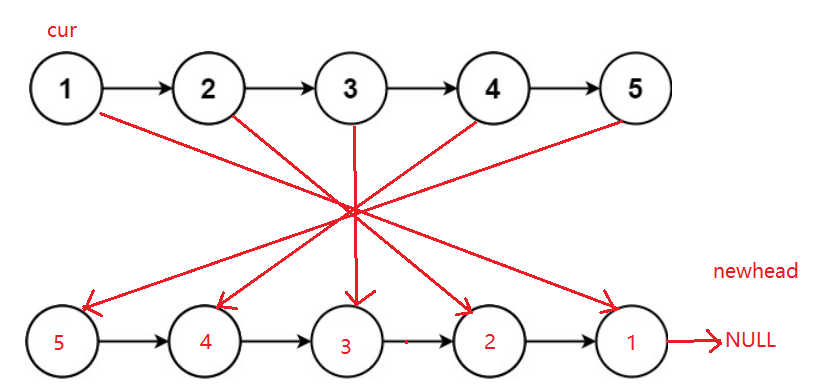
注意:此处并没有创建新的节点,其实从本质上来说和上面没有大的区别,只是思想有所差别。
structListNode*reverseList(structListNode* head){structListNode*newHead =NULL;structListNode*cur = head;while(cur){structListNode*next = cur->next;
cur->next = newHead;
newHead = cur;
cur = next;}return newHead;}
3. 链表的中间节点
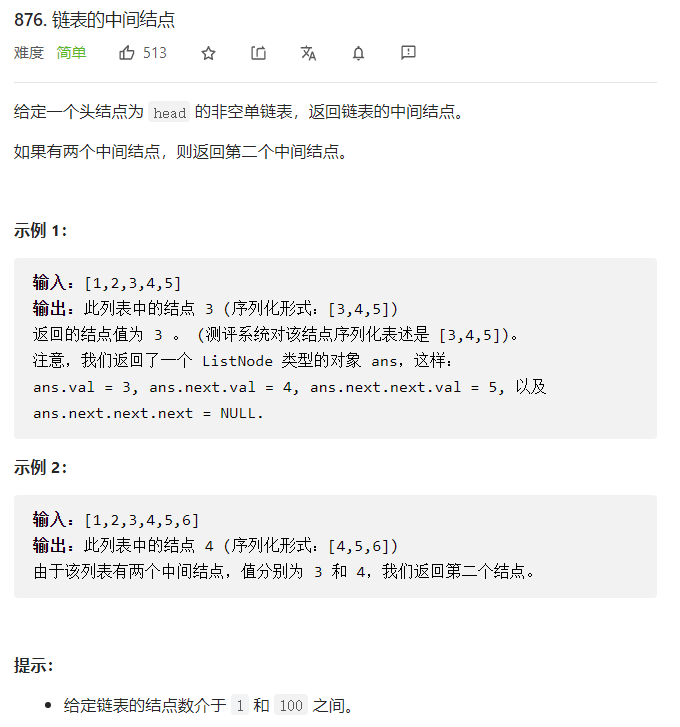
思路:
使用两个指针,然后使用两个指针进行遍历,快指针一次跳跃两个节点,慢指针一次跳跃一个节点,当快指针遍历完整个数组的时候,慢指针所处的位置就是中间节点所处的位置。
图示:
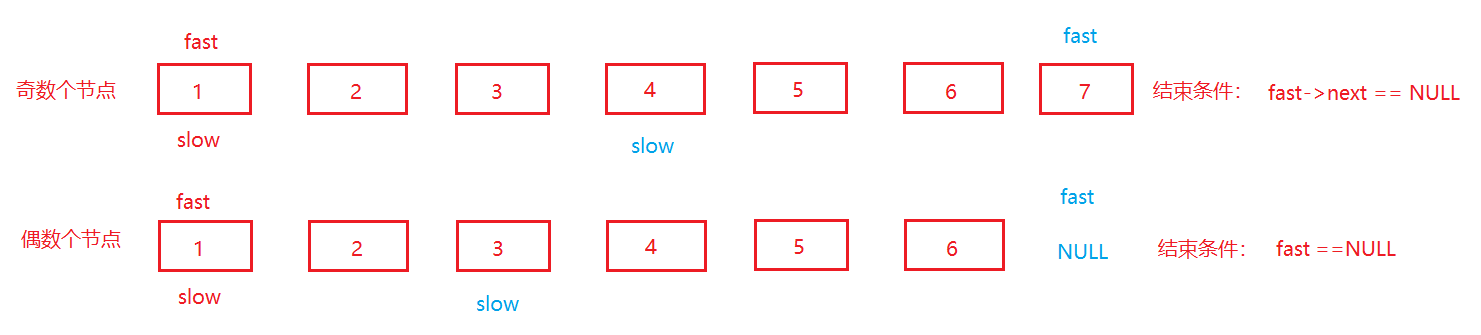
代码:
structListNode*middleNode(structListNode* head){structListNode*slow = head;//慢节点structListNode*fast = head;//快节点while(fast&&fast->next){
fast = fast->next->next;
slow = slow->next;}return slow;}
注意:fast和fast->next是不可以进行互换的,因为只有当fast为空的时候就不可能执行到fast->next,所以也就不会出现对空指针进行解引用的情况,一旦互换之后,就可能出现对空指针进行解引用的情况。
4. 链表中倒数第k个结点
思路:其实这个与前面的寻找链表的中间节点相类似,也是使用快慢指针的方法,使快指针先走k个节点,当快指针走到空指针的位置的时候,慢指针所停留的位置就是我们想要找到的节点。
代码:
structListNode*FindKthToTail(structListNode* pListHead,int k ){structListNode*fast = pListHead;structListNode*slow = pListHead;while(k--){if(fast==NULL)returnNULL;//当k大于链表的长度时返回空指针NULL
fast = fast->next;}while(fast){
fast = fast->next;
slow = slow->next;}return slow;}
注意:
注意下面的两种情况:
- 当k大于链表的长度的时候
- 当链表为空链表的时候
上面的这两种情况,都是通过if判断来进行解决的。
5. 合并两个有序链表

思路:
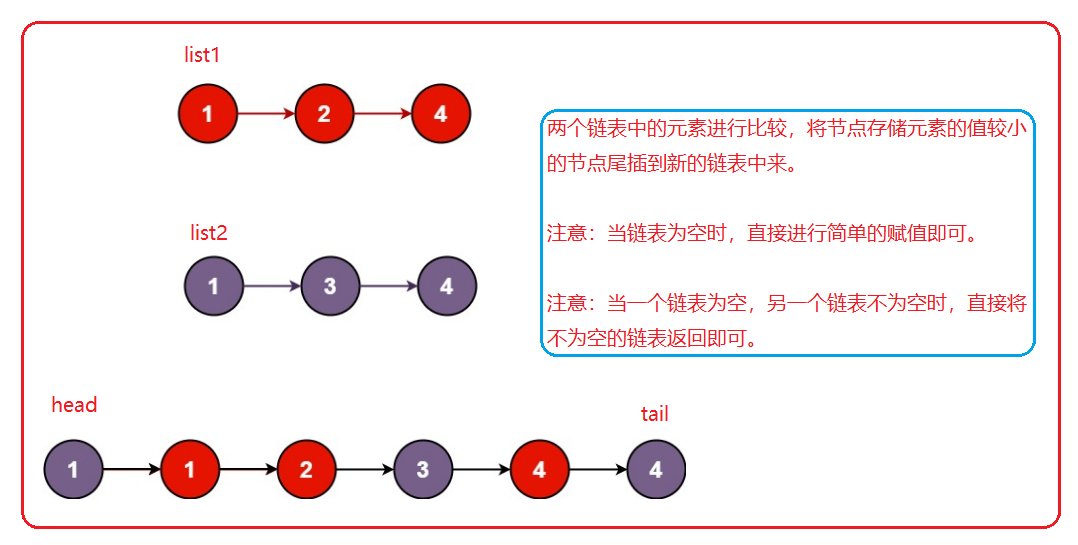
代码:(这是不带哨兵位的)
structListNode*mergeTwoLists(structListNode* list1,structListNode* list2){if(list1==NULL){return list2;}if(list2==NULL){return list1;}structListNode*tail =NULL;structListNode*head = tail;while(list1&&list2){if(list1->val<list2->val){if(tail==NULL)
head = tail = list1;else{
tail->next = list1;
tail = list1;}
list1 = list1->next;}else{if(tail==NULL)
head = tail = list2;else{
tail->next = list2;
tail = list2;}
list2 = list2->next;}}if(list1){
tail->next = list1;}if(list2){
tail->next = list2;}return head;}
(带哨兵位的)
图示:
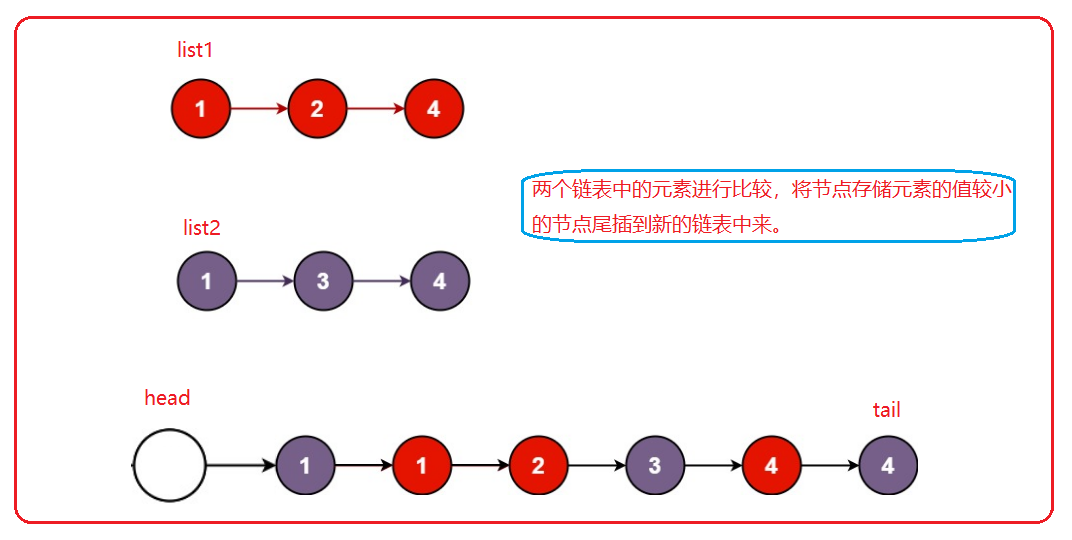
structListNode*mergeTwoLists(structListNode* list1,structListNode* list2){structListNode*tail =(structListNode*)malloc(sizeof(structListNode));structListNode*head = tail;
head->next =NULL;while(list1&&list2){if(list1->val<list2->val){
tail->next = list1;
tail = list1;
list1 = list1->next;}else{
tail->next = list2;
tail = list2;
list2 = list2->next;}}if(list1){
tail->next = list1;}if(list2){
tail->next = list2;}return head->next;}
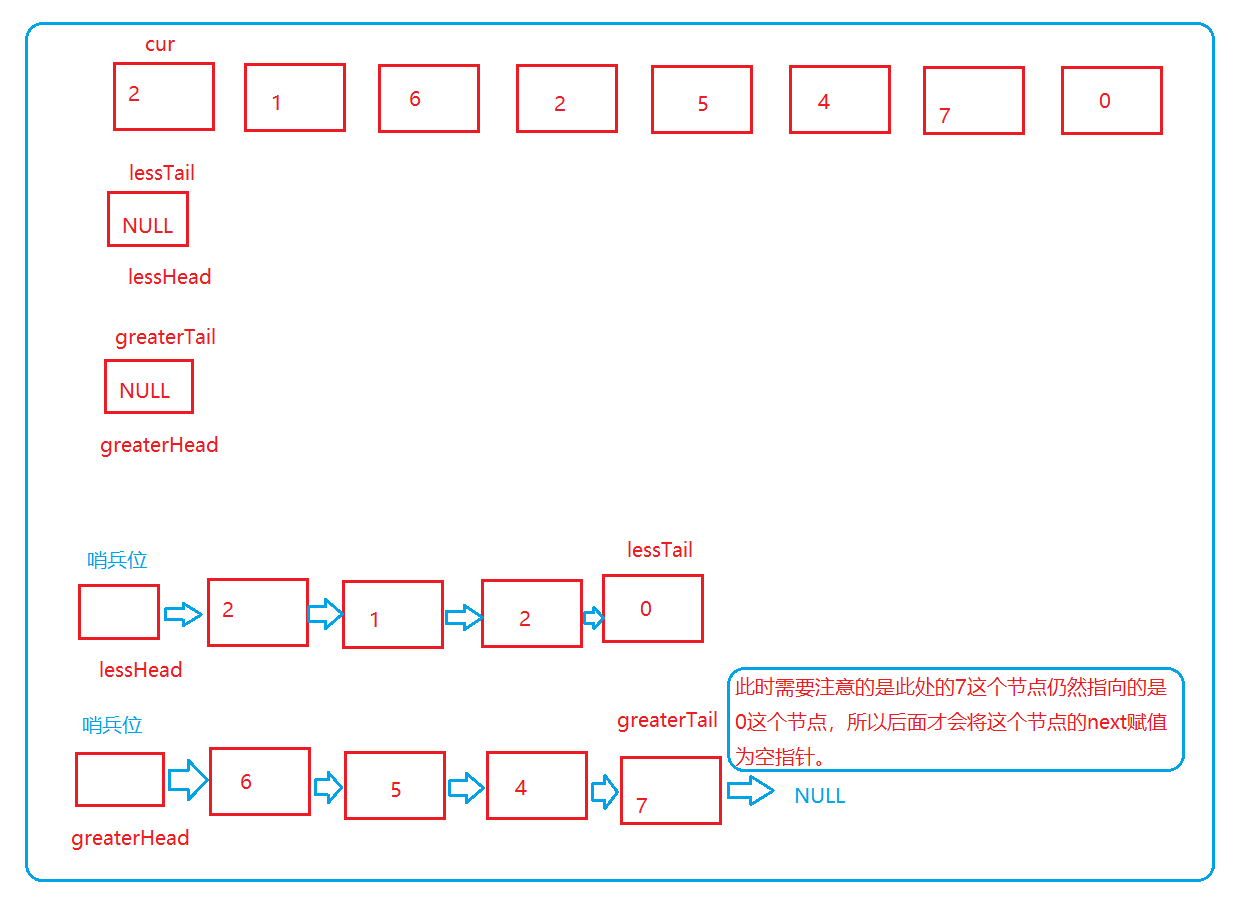
6. 链表分割
思路:对原链表进行遍历,然后将小于x的形成一个链表,大于x的形成一个链表,然后将两个链表连接起来就是我们要返回的新链表。
方法一:(带哨兵位的)
图示:
代码:
ListNode*partition(ListNode* pHead,int x){structListNode* lessTail =(structListNode*)malloc(sizeof(ListNode));//作为结尾structListNode* lessHead = lessTail;//指向新的节点存储元素的值均比x小的链表structListNode* greaterTail =(structListNode*)malloc(sizeof(ListNode));//作为结尾structListNode* greaterHead = greaterTail;//指向新的节点存储元素的值均比x大或者等于的链表structListNode* cur = pHead;//用来遍历所给链表的指针while(cur)//判断所给链表遍历是否终止{if(cur->val < x)//连接比x小的链表节点{
lessTail->next = cur;
lessTail = lessTail->next;}else//连接大于或者等于x的链表节点{
greaterTail->next = cur;
greaterTail = greaterTail->next;}
cur = cur->next;}
lessTail->next = greaterHead->next;//连接两个链表形成最后的结果链表
greaterTail->next =NULL;//将最后一个节点的next置为空structListNode* list = lessHead->next;//存储返回值,方便free掉开辟的空间free(lessHead);free(greaterHead);return list;}
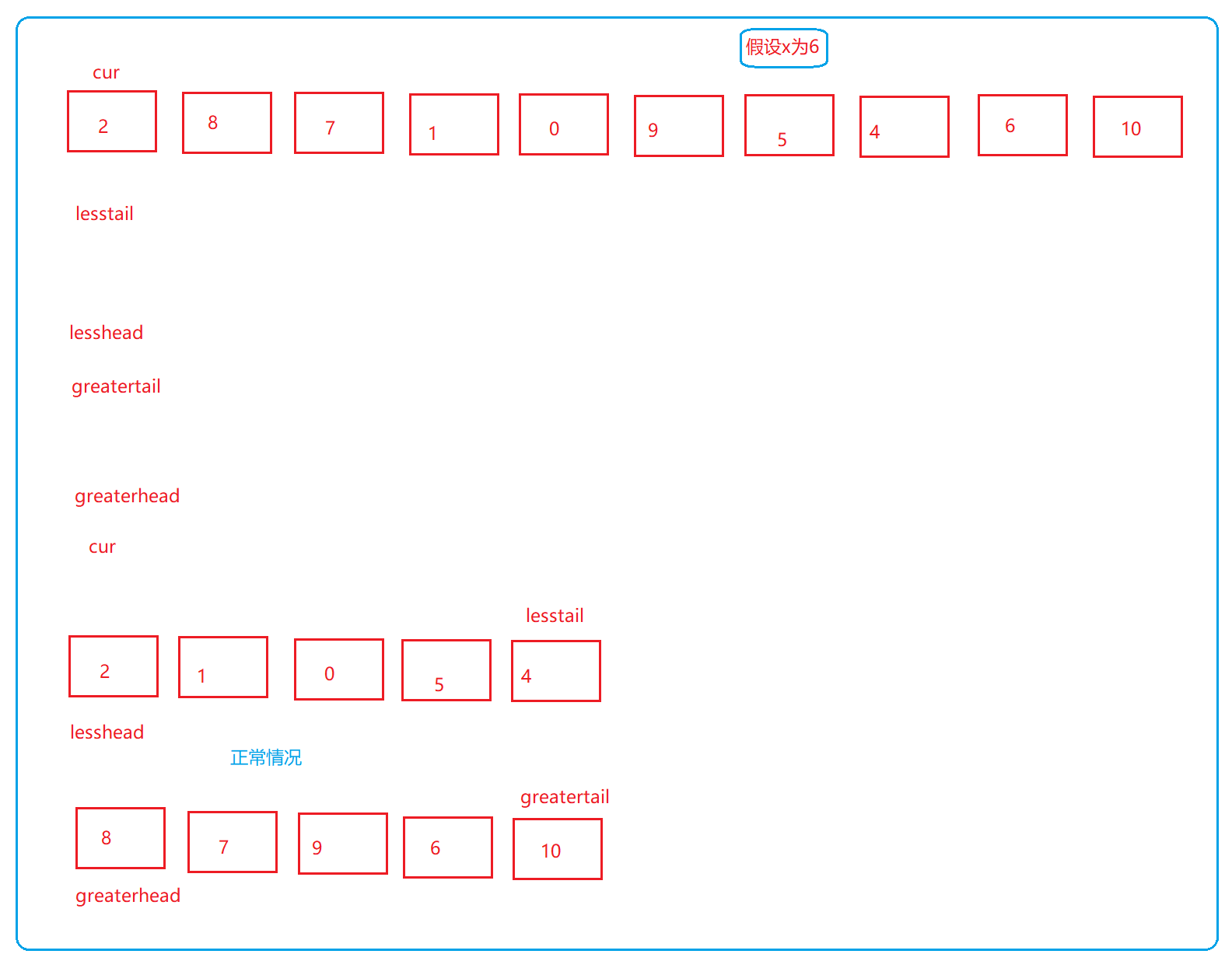
方法二:(不带哨兵位的)
图示:
1、正常情况:
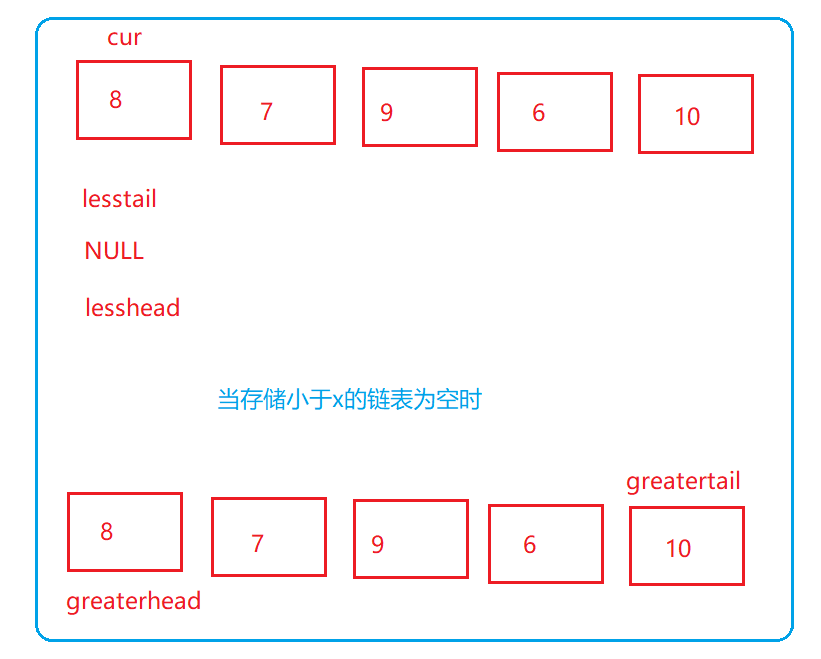
2、当存储比x小的链表为空时
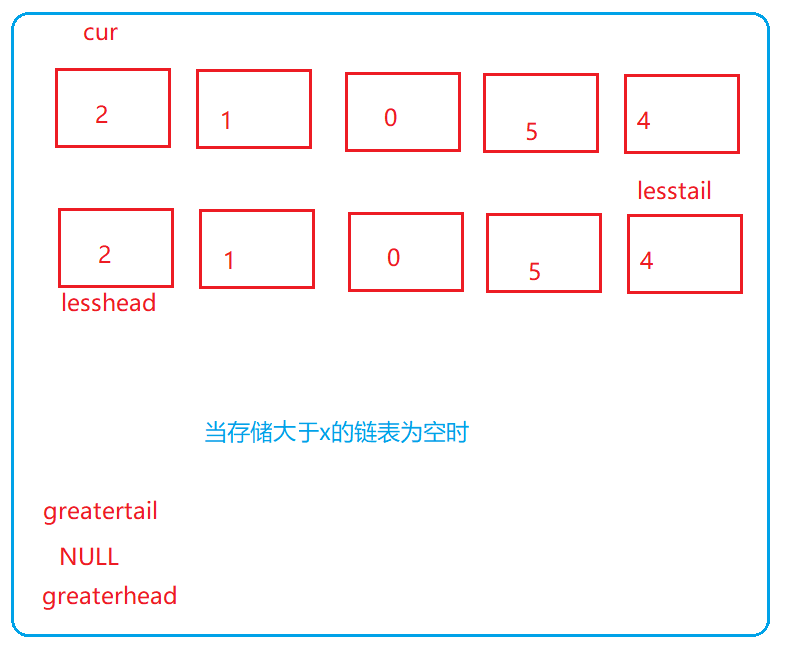
3、当存储大于x的链表为空时
代码:
ListNode*partition(ListNode* pHead,int x){structListNode* lessHead =NULL;structListNode* lessTail =NULL;structListNode* greaterHead =NULL;structListNode* greaterTail =NULL;structListNode* cur = pHead;while(cur){if(cur->val < x){if(lessHead ==NULL){
lessTail = cur;
lessHead = cur;}else{
lessTail->next = cur;
lessTail = cur;}}else{if(greaterHead ==NULL){
greaterTail = cur;
greaterHead = cur;}else{
greaterTail->next = cur;
greaterTail = cur;}}
cur = cur->next;}//应当有三种情况//1、存储小于x的链表为空,存储大于x的链表不为空//2、存储小于x的链表不为空,存储大于x的链表为空//3、存储小于x和存储小于x的链表均不为空//后面的两种方法是可以合并的,因为都要进行两个链表的连接,无论存储大于x的链表是否为空,都不影响最后的结果if(lessTail ==NULL)//判断是否是没有小于x的数据,如果是这种情况,那么就返回存储大于x数据的链表{return greaterHead;}
lessTail->next = greaterHead;//将两个链表进行连接if(greaterHead !=NULL){
greaterTail->next =NULL;//将存储大于x的数据的最后一个节点的next置为空指针}//为什么要进行判定,因为如果直接执行greaterTail->next = NULL属于非法操作,因为当greaterHead等于NULL时,greaterTail也是空指针,执行这行代码就属于对空指针的解引用,属于非法操作return lessHead;}
7. 链表的回文结构
思路:(偶数个节点一定不会出现问题,很容易就能想到)

代码:
structListNode*middleNode(structListNode* head)//求中间节点{structListNode* slow = head;//慢节点structListNode* fast = head;//快节点while(fast && fast->next){
fast = fast->next->next;
slow = slow->next;}return slow;}structListNode*reverseList(structListNode* head)//反转链表{if(head ==NULL)//当链表尾空时,返回的是空链表{return head;}else{structListNode* prev =NULL;structListNode* cur = head;structListNode* next = head->next;while(cur){
cur->next = prev;
prev = cur;
cur = next;if(next)
next = next->next;}return prev;}}boolchkPalindrome(ListNode* head){structListNode* mid =middleNode(head);//记录中间节点
mid =reverseList(mid);//将反转后的新的节点的起始位置赋值给midstructListNode* cur = head;//用来从头遍历链表while(head && mid){if(head->val != mid->val)returnfalse;
head = head->next;
mid = mid->next;}returntrue;}//此处是C++的,true代表1,false代表0
8. 相交链表

思路:
第一种方法(不推荐):用listA的每一个节点和listB的每一个节点的地址进行遍历比较,既能判断出是否相交,同时也能找到相交的节点。
第二种方法:先从头找到尾对两个节点同时进行遍历,同时记录两个链表各自的节点数,最后将尾节点进行比较,如果尾节点相同,说明有相交节点,如果不相同,就说明没有相交节点,同时计算出两个链表节点数目的差值,然后使用快慢指针的方法,让较长的链表先走差值步,然后再同时走,两个指针相同的那个点就是我们要求的两个链表相加的点。
图示:
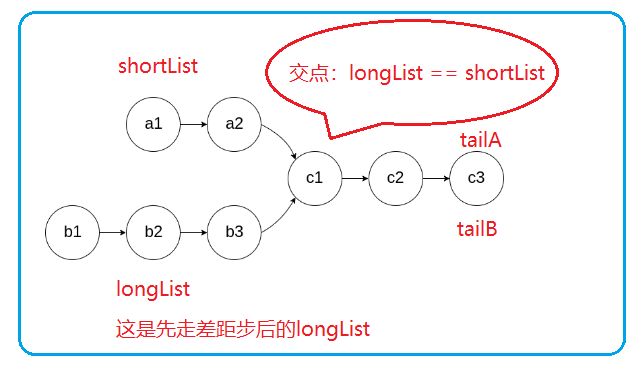
structListNode*getIntersectionNode(structListNode*headA,structListNode*headB){structListNode*tailA = headA;//记录链表A的尾节点structListNode*tailB = headB;//记录链表B的尾节点int lenA =1;//记录链表A的长度int lenB =1;//记录链表B的长度while(tailA->next!=NULL){
tailA = tailA->next;
lenA++;}while(tailB->next!=NULL){
tailB = tailB->next;
lenB++;}if(tailA!=tailB)//尾节点不等,所以直接返回NULL{returnNULL;}//相交,求节点,长的先走差距步,再同时走找交点structListNode*shortList = headA,*longList = headB;//默认B是较长节点的链表,A是较短的if(lenA>lenB){
longList = headA;
shortList = headB;}int gap =abs(lenA - lenB);//gap存储的是节点数的差值while(gap--){
longList = longList->next;//节点数多的先走gap步}while(longList!=shortList)//两者同时开始进行遍历,在交点处停下{
longList = longList->next;
shortList = shortList->next;}return longList;//随便返回一个就行,因为两个都是交点}
版权归原作者 鹿九丸 所有, 如有侵权,请联系我们删除。