
mmselfsup训练自己的数据集
最近在做自监督学习的东西,使用无标签数据做预训练模型,做个分享吧,写的不好,请见谅。
mmselfsup地址:https://github.com/open-mmlab/mmselfsup
相关文档:Welcome to MMSelfSup’s documentation! — MMSelfSup 0.10.1 documentation
一、环境搭建
1.创建虚拟环境
conda create --name openmmlab python=3.8 -y
激活虚拟环境:
conda activate openmmlab
2.安装pytorch、torchvision
根据自己的配置安装相应版本
pip install torch==1.7.1+cu101 torchvision==0.8.2+cu101 -f https://download.pytorch.org/whl/torch_stable.html
或手动下载,地址:https://download.pytorch.org/whl/torch_stable.html
3.下载I MMEngine 和 MMCV
pip install -U openmim
mim install mmengine
mim install 'mmcv>=2.0.0rc1'
4.下载mmselfSup并编译
git clone https://github.com/open-mmlab/mmselfsup.git
cd mmselfsup
git checkout 1.x
pip install -v -e .
二、训练自监督模型(SimCLR)
1.构造数据集
数据集结构为datasetdir->{namedirs}->pics
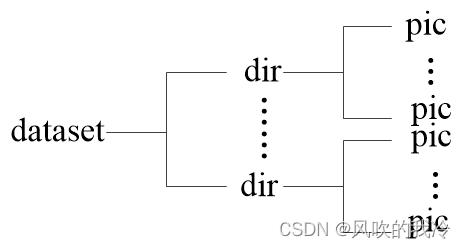
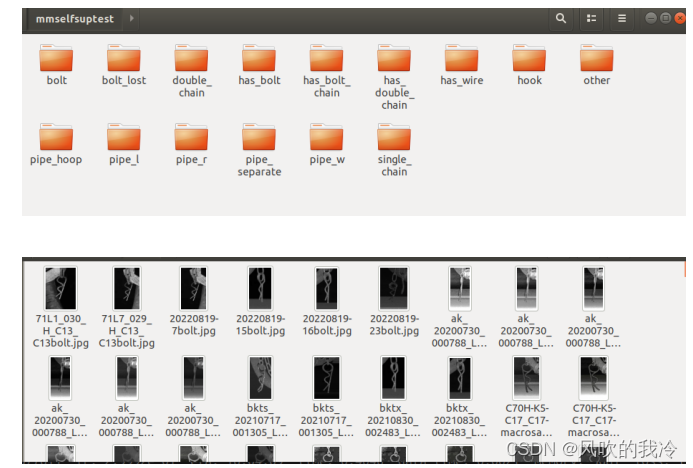
2.写模型自监督预训练的配置文件
新建一个名为
simclr_resnet50_1xb32-coslr-1e_tinyin200.py
的配置文件
新建位置自定,本人为:configs/selfsup/simclr下
写入
_base_ = [
'../_base_/models/simclr.py',
# '../_base_/datasets/imagenet_mae.py', # removed
'../_base_/schedules/lars_coslr-200e_in1k.py',
'../_base_/default_runtime.py',
]
# custom dataset
dataset_type = 'mmcls.CustomDataset'
data_root = 'data/custom_dataset/' #数据集路径
file_client_args = dict(backend='disk')
view_pipeline = [
dict(type='RandomResizedCrop', size=224, backend='pillow'),
dict(type='RandomFlip', prob=0.5),
dict(
type='RandomApply',
transforms=[
dict(
type='ColorJitter',
brightness=0.8,
contrast=0.8,
saturation=0.8,
hue=0.2)
],
prob=0.8),
dict(
type='RandomGrayscale',
prob=0.2,
keep_channels=True,
channel_weights=(0.114, 0.587, 0.2989)),
dict(type='RandomGaussianBlur', sigma_min=0.1, sigma_max=2.0, prob=0.5),
]
train_pipeline = [
dict(type='LoadImageFromFile', file_client_args=file_client_args),
dict(type='MultiView', num_views=2, transforms=[view_pipeline]),
dict(type='PackSelfSupInputs', meta_keys=['img_path'])
]
train_dataloader = dict(
batch_size=32,
num_workers=4,
persistent_workers=True,
sampler=dict(type='DefaultSampler',shuffle=True),
collate_fn=dict(type='default_collate'),
dataset=dict(
type=dataset_type,
data_root=data_root,
# ann_file='meta/train.txt',
data_prefix=dict(img_path='./'),
pipeline=train_pipeline))
# optimizer
optimizer = dict(type='LARS', lr=0.3, momentum=0.9, weight_decay=1e-6)
optim_wrapper = dict(
type='OptimWrapper',
optimizer=optimizer,
paramwise_cfg=dict(
custom_keys={
'bn': dict(decay_mult=0, lars_exclude=True),
'bias': dict(decay_mult=0, lars_exclude=True),
# bn layer in ResNet block downsample module
'downsample.1': dict(decay_mult=0, lars_exclude=True),
}))
# runtime settings
default_hooks = dict(
# only keeps the latest 3 checkpoints
checkpoint=dict(type='CheckpointHook', interval=10, max_keep_ckpts=3))
3.写数据预训练的配置文件(mae)
新建一个名为
selfsup_mae.py
的配置文件
新建位置自定,本人为:configs/selfsup/base/datasets下
写入
_base_ = [
'../_base_/models/mae_vit-base-p16.py',
# '../_base_/datasets/imagenet_mae.py', # removed'
../_base_/schedules/adamw_coslr-200e_in1k.py',
'../_base_/default_runtime.py',
]
#<<<<<<< modified <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<
# custom dataset
dataset_type = 'mmcls.CustomDataset'
data_root = 'data/sbu/' #数据集地址
file_client_args = dict(backend='disk')
train_pipeline = [
dict(type='LoadImageFromFile', file_client_args=file_client_args),
dict(
type='RandomResizedCrop',
size=224,
scale=(0.2, 1.0),
backend='pillow',
interpolation='bicubic'),
dict(type='RandomFlip', prob=0.5),
dict(type='PackSelfSupInputs', meta_keys=['img_path'])
]
# dataset 8 x 512
train_dataloader = dict(
batch_size=512,
num_workers=8,
persistent_workers=True,
sampler=dict(type='DefaultSampler', shuffle=True),
collate_fn=dict(type='default_collate'),
dataset=dict(
type=dataset_type,
data_root=data_root,
# ann_file='meta/train.txt', # removed if you don't have the annotation file
data_prefix=dict(img_path='./'),
pipeline=train_pipeline))
# optimizer wrapper
optimizer = dict(
type='AdamW', lr=1.5e-4 * 4096 / 256, betas=(0.9, 0.95), weight_decay=0.05)
optim_wrapper = dict(
type='OptimWrapper',
optimizer=optimizer,
paramwise_cfg=dict(
custom_keys={
'ln': dict(decay_mult=0.0),
'bias': dict(decay_mult=0.0),
'pos_embed': dict(decay_mult=0.),
'mask_token': dict(decay_mult=0.),
'cls_token': dict(decay_mult=0.)
}))
# learning rate scheduler
param_scheduler = [
dict(
type='LinearLR',
start_factor=1e-4,
by_epoch=True,
begin=0,
end=40,
convert_to_iter_based=True),
dict(
type='CosineAnnealingLR',
T_max=360,
by_epoch=True,
begin=40,
end=400,
convert_to_iter_based=True)
]
# runtime settings
# pre-train for 400 epochs
train_cfg = dict(max_epochs=400) #训练次数
default_hooks = dict(
logger=dict(type='LoggerHook', interval=100),
# only keeps the latest 3 checkpoints
checkpoint=dict(type='CheckpointHook', interval=1, max_keep_ckpts=3))
# randomness
randomness = dict(seed=0, diff_rank_seed=True)
resume = True
4.启动训练程序
参数

训练
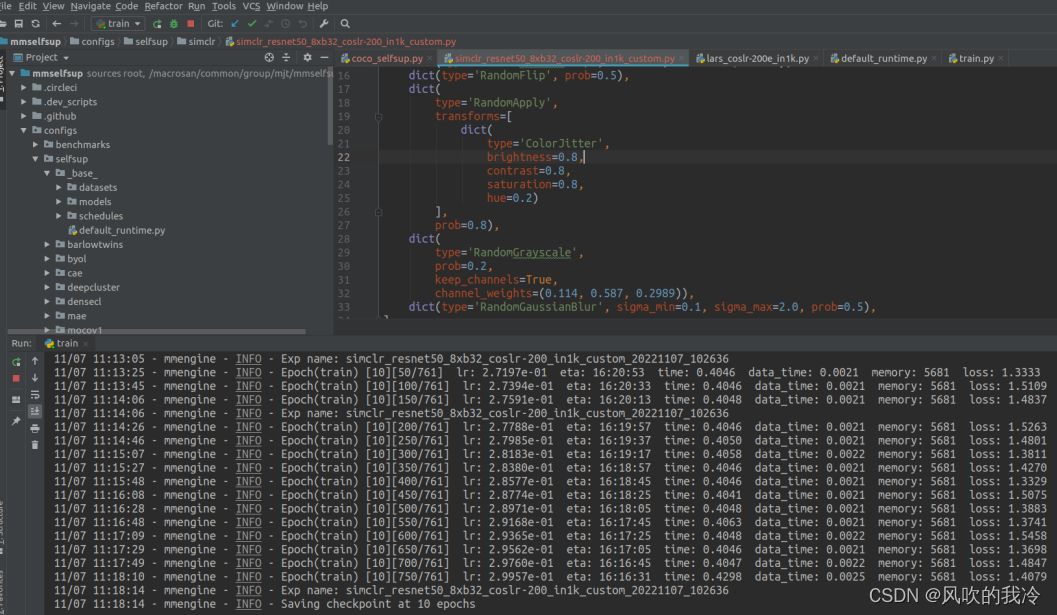
结果
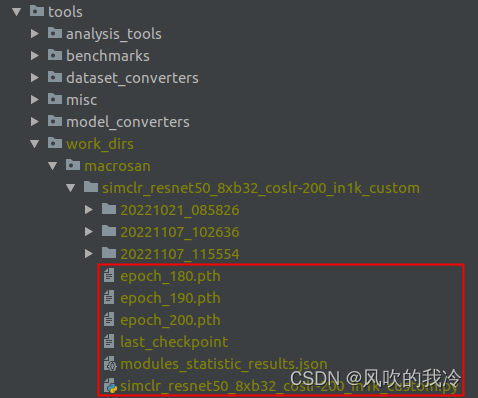
本文转载自: https://blog.csdn.net/qq_41980080/article/details/127727598
版权归原作者 风吹的我冷 所有, 如有侵权,请联系我们删除。
版权归原作者 风吹的我冷 所有, 如有侵权,请联系我们删除。