
目录
VideoReTalking是一个强大的开源模型,是目前语音驱动面部表情的模型中效果最好的一个。此模型是由西安电子科技大学、腾讯人工智能实验室和清华大学联合开发的。
项目地址:https://github.com/OpenTalker/video-retalking
论文地址:https://arxiv.org/pdf/2211.14758.pdf
1 VideoReTalking论文解读
我们展示了VideoReTalking,这是一种新系统,可以根据输入音频编辑真实世界中说话的头部视频的面部,从而产生高质量和口型同步的输出视频,即使带有不同的情绪。我们的系统将这个目标分解为三个连续的任务:
- 具有规范表达的面部视频生成;
- 音频驱动的口型同步;
- 面部增强以提高照片的真实感。
给定一个会说话的头像视频,我们首先使用表情编辑网络根据相同的表情模板修改每一帧的表情,从而生成具有规范表情的视频。然后将该视频与给定的音频一起输入口型同步网络以生成口型同步视频。最后,我们通过身份感知面部增强网络和后处理提高合成面部的照片真实感。我们对所有三个步骤都使用基于学习的方法,并且我们所有的模块都可以在没有任何用户干预的情况下按顺序处理。此外,我们的系统是一种通用方法,不需要针对特定人员进行再培训。对两个广泛使用的数据集和实际示例的评估表明,我们的框架在口型同步准确性和视觉质量方面优于其他最先进的方法。
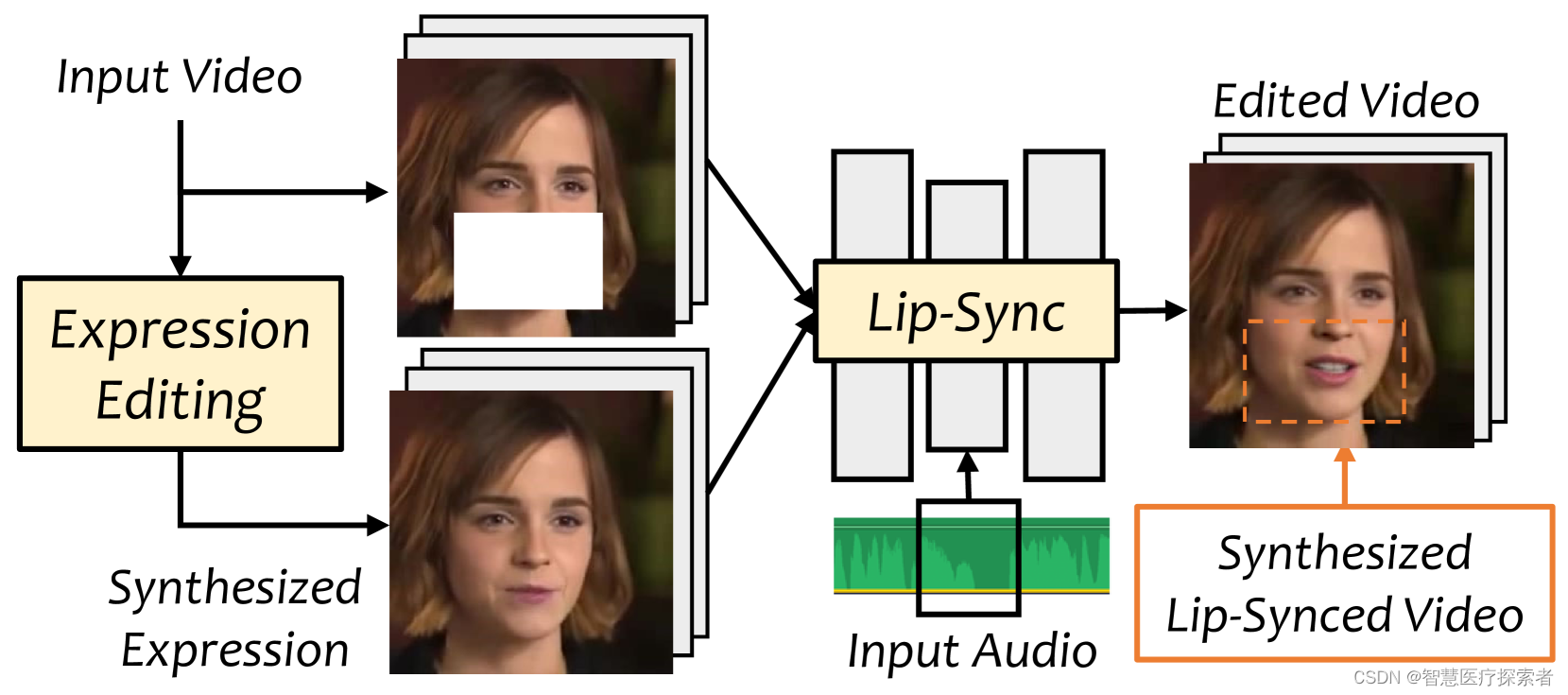
图1 我们的方法修改原始视频并通过表情编辑和口型同步网络通过输入音频生成口型同步视频。
面部动画、视频合成、音频驱动生成

图 2 给定一个任意的谈话视频和另一个音频,我们的方法可以合成一个照片般逼真的谈话视频,具有精确的唇音同步和修饰的面部表情。
1.1 介绍
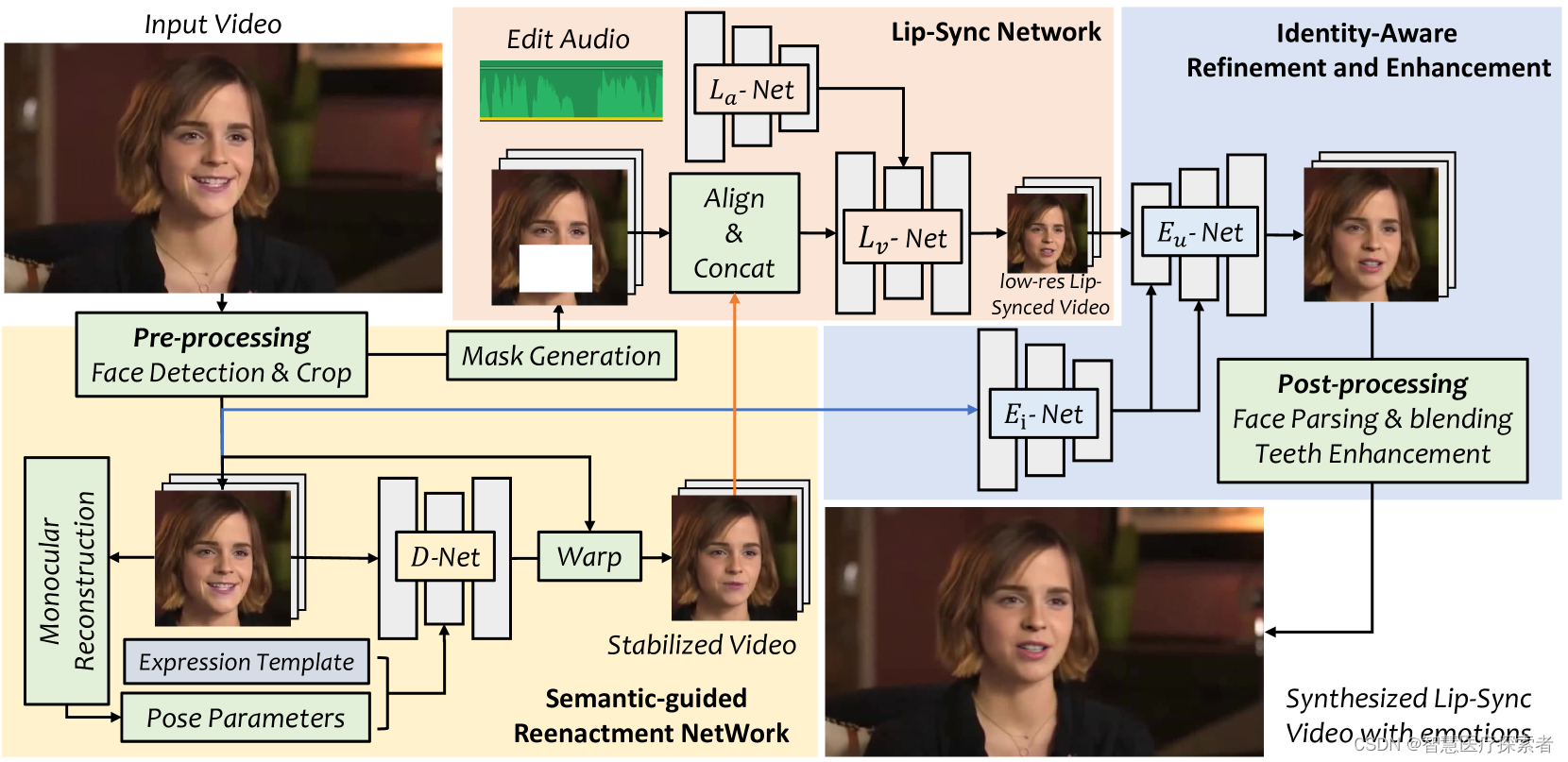
图 3 我们的框架包含三个主要组件,用于生成逼真的口型同步视频。
根据输入的语音音频编辑说话的头部视频的任务具有重要的现实应用,例如将整个视频翻译成不同的语言,或者在视频录制后修改语音。这项任务被称为视觉配音,已经在之前的几部作品中进行了研究 (Suwajanakorn 等人,2017年; Wen等人,2020年; Thies 等人; Prajwal 等人,2020年),它通过修改面部动画和情绪以匹配目标音频来编辑输入的说话头部视频,同时保持所有其他动作不变(如图 2 所示)。一些方法(Suwajanakorn 等人,2017年; Wen等人,2020; Thies 等人。,2020
)可以在特定说话人上取得满意的效果,但需要在目标说话人的说话语料库上进行训练,得到个性化的模型,这并不总是可用的。另一方面,当前的通用方法会产生模糊的下部面孔 (Prajwal 等人,2020)或口型同步不准确 (Song et al . ,2022年
),它们在视觉上具有侵扰性。这些方法也不支持情感编辑,这在更改语音内容时通常是可取的。
受先前基于修复的头部说话视频编辑方法的启发 (Prajwal 等人,2020),我们提出了一个新系统来编辑说话的嘴唇,以匹配输入音频,具有更稳定的口型同步结果和更好的视觉质量。以前的作品将视频中的原始帧视为头部姿势参考。然而,我们发现唇型生成对这些参考非常敏感,直接使用原始帧作为唇型生成的基础往往会产生不同步的结果。为此,如图1所示,我们采用分而治之的策略,首先中和面部表情,然后使用修改后的帧作为唇形生成的姿势参考,考虑到所有参考面现在都具有相同的规范表情,这样更准确。最后,与以前经常产生低分辨率和模糊结果的作品相比,我们通过提出的身份感知增强网络和恢复产生照片般逼真的结果 (Yang 等人,2021年; Wang等人。,2021)基于StyleGAN的面部先验 (Karras 等人,2019)。
具体来说,给定一个任意的谈话视频,我们首先裁剪面部区域并通过深度提取 3D 可变形模型 (3DMM) 的姿势和表情系数 ( Deng 等人,2019)。然后,我们将 3DMM 的参数与标准中性模板表达式一起使用,并通过类似于(Ren等人,2021)。通过这样做,我们获得了一个在所有帧中都具有相同规范表达的视频,它们将被视为我们口型同步网络的结构参考。有趣的是,我们还可以通过改变表情模板,合成出不同情绪的说话头像视频。例如,通过改变表情模板的唇形来匹配“快乐”的情绪,这种唇形将被口型同步网络考虑在内,导致说话的头部视频表现出相同的情绪。
在表情中和之后,然后应用口型同步网络,使用合成的表情作为条件结构信息来合成逼真的下半脸。具体来说,我们设计了一个带有快速傅立叶卷积块的类似沙漏的网络 (Chi 等人,2020)作为基本学习单元,因为它在一般图像修复任务中取得了巨大成功 (Suvorov 等人,2021)。至于音频注入,我们使用自适应实例规范化 (AdaIN) 块 (Huang 和 Belongie,2017)来调制全局的音频特征。类似于(Prajwal 等人,2020),我们使用预训练的口型同步鉴别器来确保视听同步性。
虽然前面的步骤可以合成具有相对准确唇形的说话头部视频,但视觉质量仍然受到低分辨率训练数据集的限制 (Nagrani 等人,2017; Afouras 等人,2018)。为了解决这个问题,我们设计了一个身份保持面部增强网络,通过渐进式训练产生高质量的输出。增强网络在增强的 LRS2 数据集上进行训练 (Afouras 等人,2018)通过人脸修复方法 (Yang et al . ,2021)。我们还应用了 StyleGAN 先验引导人脸修复网络(Wang 等人,2021)去除牙齿周围的视觉伪影。
以上所有模块都可以按顺序应用,无需人工干预或微调。我们进行了广泛的实验,以评估我们在几个现有基准和野外视频中的框架。结果表明,所提出的系统可以生成比以前的方法具有更高视觉质量的视频,同时提供准确的口型同步。
1.2 相关工作
我们从两个方面回顾了相关方法,包括旨在通过音频编辑输入视频的视觉配音任务,以及以音频为条件的单图像动画。
1.2.1 视频编辑中的音频配音
(1)任意主题方法
任意主题方法旨在建立一个不需要针对不同身份重新训练的通用模型。Speech2Vid (Chung 等人,2017)可以使用上下文编码器重新配音带有不同音频片段的源视频。通过修复重建下半脸最近很流行 (KR 等人,2019; Prajwal 等人,2020; Park et al., 2022)。例如,LipGAN (KR 等人,2019)设计一个神经网络来填充下半脸作为先验姿势。Wav2Lip (Prajwal 等人,2020)使用预训练的 SyncNet 作为口型同步鉴别器扩展 LipGAN(Chung 和 Zisserman,2016)以生成准确的嘴唇同步。基于 Wav2Lip,SyncTalkFace (Park 等人,2022)涉及音频嘴唇记忆以隐式存储嘴唇运动特征并在推理时检索它们。另一类方法首先预测中间表示,然后通过图像到图像转换网络合成逼真的结果,例如面部标志 (Xie 等人,2021)和基于 3D 人脸重建的人脸特征点 (Song et al . ,2022)。然而,所有这些方法都难以合成具有可编辑情感的高质量结果。
(2)个性化方法
个性化视觉配音比通用配音更容易,因为这些方法仅限于已知环境中的某个人。例如,SynthesizeObama (Suwajanakorn 等人,2017)可以通过 audio-to-landmark 网络合成 Obama 的嘴巴区域。受面部重现方法的启发 (Kim 等人,2018; Thies 等人,2019),最近的视觉配音方法侧重于从音频生成中间表示,然后通过图像到图像的转换网络渲染照片般逼真的结果。例如,几部作品 (Thies 等人,2020; 文等人,2020; 张等人,2021)关注音频特征的表达系数,并通过图像生成网络渲染照片般逼真的结果 (Thies 等人,2019; 金等人。,2018; 王等人,2018)。面部标志 (Lu 等人,2021)和边缘 (Ji et al . ,2021)也是投影 3D 渲染面孔的流行选择,因为它包含更稀疏的信息。此外,基于 3D 网格 (Lahiri 等人,2021)和 NeRF (Mildenhall 等人,2020)为基础的方法 (Guo et al . ,2020)也很强大。尽管这些方法可以合成照片般逼真的结果,但它们的应用相对有限,因为它们需要针对特定的人和环境重新训练模型。
1.2.2 基于音频的单图像面部动画
与视觉配音不同,单图人脸动画旨在通过单一的音频驱动来生成动画,同时也受到了视频驱动人脸动画的影响。例如,(Song等人,2018)使用递归神经网络从音频生成运动,(Zhou 等人,2019)通过对抗性表征学习解开主题相关信息和语音相关信息的输入。(Vougioukas 等人,2020; 周等人。,2021)将音频视为潜在代码,并通过图像生成器驱动面部动画。中间表示也是该任务中的流行选择。ATVG (Chen等人,2019)和 MakeItTalk (Zhou et al . ,2020)首先从音频生成面部标志,然后使用标志到视频网络渲染视频。稠密流场是另一个活跃的研究方向 (Yin et al . ,2022; Siarohin 等人,2019)。(张等人,2021)从音频预测 3DMM 系数,然后将这些参数传输到基于流的变形网络中。(王等人,2021)借用视频驱动的面部动画的想法 (Siarohin et al . ,2019)。
1.3 框架
从技术上讲,我们的方法是一种跨模态视频修复框架,用于在驱动音频和情绪调制参考框架的指导下填充蒙版的下半脸。为此,我们设计了一个口型同步网络(1.3.2章节中的L-Net),它使用蒙版的下半脸帧、给定的音频和原始视频帧作为输入来生成口型同步视频。但是,如果我们仅用L-Net网络,首先是参考系造成的信息泄露,生成的口型仍然严重依赖参考系。另一个是视觉质量低,因为当前的大规模谈话头部数据集分辨率较低。
最终,除了L-Net,我们提出了两个额外的模块,如图3所示。首先,为了解决信息泄露问题,我们通过语义引导的表情重现网络(1.3.1章节中的D-Net)。合成的嘴唇是参考嘴唇而不是原始嘴唇。然后,编辑视频的下半部分脸将用作我们的唇形合成网络的参考结构(L-Net)。在L-Net中,我们的方法将音频作为输入并逐帧合成口型同步结果。此外,在1.3.3章节中我们设计了一个E-Net用于 身份识别面部恢复。最后,我们可以通过第 1.3.4章节中的后期处理将生成的人脸无缝粘贴回原始视频。下面,我们给出每个组件的详细信息。

图 4 所提出的D-Net 用于从原始视频中删除与谈话相关的动作。在没有 D-Net 的情况下,生成的嘴唇运动受源视频的严重影响,即使在音频无声时仍在运动,这表明信息泄漏会影响嘴唇合成。
1.3.1 语义引导重演网络
直接编辑视频中与嘴唇相关的动作具有挑战性。以前的作品经常省略原来的嘴唇运动变化 (Prajwal 等人,2020)或重定时背景 (Suwajanakorn et al . ,2017; 宋等。,2022)以避免头部姿势和嘴唇之间的不自然运动。不同的是,我们直接编辑整个下半脸,包括借助面部重现方法的面部运动。我们的主要观察是存在信息泄漏 (KR 等人,2019; Prajwal 等人,2020)在基于条件内画的方法中,如果我们使用原始帧作为唇形同步的条件图像。我们在图4中举例说明这种现象 。给定音频和输入帧,如果我们直接使用原始帧作为参考(D-Net),生成的嘴唇将根据原始嘴唇进行修改。因此,我们的目标是通过所提出的语义引导重演网络来编辑整个下半脸的表情。然后,表达稳定的框架将作为进一步唇部合成的参考。
如图3所示,在人脸检测和裁剪之后,我们使用单目人脸重建从每一帧中提取姿势和表情系数 (Deng 等人,2019)。然后,我们通过用预定义的表达式模板替换原始表达式系数来获得新的驱动信号。因此,我们可以通过生成的网络密集扭曲场和原始帧来合成具有冻结表情的视频。类似于(Ren等人,2021) , 的𝐷{D}斜体字D-Net 包含两个类似编码器-解码器的结构,用于从粗到精的训练。表情编辑后,我们得到了所有帧的稳定表情。请注意,由于人脸重现网络的质量仍然有限,我们使用编辑后的人脸作为口型同步网络的结构参考。为此,我们首先检测面部标志,使用时间 Savitzky-Golay 滤波器对其进行平滑处理,然后使用眼睛中心和鼻子的关键点作为面部对齐的锚点。
有趣的是,我们还可以通过更多表情模板(例如微笑)利用由口型同步参考帧引起的信息泄漏,从而产生如图2所示的情绪化谈话视频 。由于我们的表情重演网络仅编辑原始视频的下半脸,灵感来自面部动作代码系统 (Ekman 和 Friesen,1978) , 我们可以通过基于图像的表情编辑网络 (Pumarola et *al *. ,2018)在上面。我们将其视为一个插件,并在章节1.5中显示一些结果。
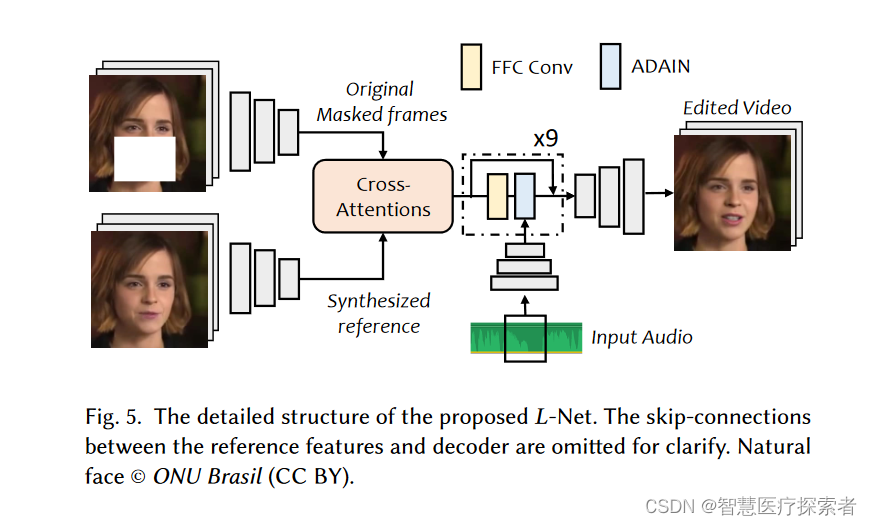
为了清楚起见,省略了参考特征和解码器之间的跳跃连接。
1.3.2 口型同步网络
我们的口型同步网络(L-Net) 的灵感来自最近的基于条件修复的框架 (Prajwal 等人,2020),它通过新音频直接编辑原始视频。不同的是,我们使用来自D-Net作为身份和结构参考,音频和被屏蔽的原始帧作为条件,针对输入音频合成口型同步视频。
在图3中,我们简要概述了L-Net,包含两个子网络,下标𝐿𝑎和下标𝐿𝑣,分别用于音频和视频处理。在这里,图5中我们给出详细的L-Net的网络结构。对于音频处理,我们首先从原始音频中提取梅尔频谱图并使用基于 ResNet 的编码器 (He 等人,2016)提取全局音频向量下标𝐹𝑎𝑢𝑑𝑖𝑜∈ℝ(25611)的一个时间窗口。按照之前的工作,时间窗口设置为每帧0.2s,导致80维度的特征\次×16 处理。至于图像生成,我们首先提取图像特征下标𝐹𝑟𝑒𝑓,𝐹𝑜𝑟𝑖𝑔∈ℝ(256HW)分别通过两个不同的编码器从预处理后的参考图像和原始蒙版图像中学习这些特征,通过两个交叉注意块自动对像素之间的关系进行建模(Vaswani 等人,2017)。这些交叉注意块将计算两个特征的像素级对应矩阵并扩大接收域。之后,我们使用九个残差快速傅里叶卷积块 (Chi 等人,2020)来改进受最近通用图像修复框架启发的特征 (Suvorov 等人,2021),我们通过 AdaIN 块 (Huang 和 Belongie,2017)在每个 FFC 块之后按通道规范化视觉特征。最后,使用一系列卷积上采样层来生成最终结果。
1.3.3 身份感知增强网络
结果来自L-Net 仍然不完美,因为很难在高分辨率说话头数据集上训练模型。一方面,没有公开可用的大规模高分辨率谈话头部数据集。另一方面,如果我们直接应用基于 GAN 先验的人脸恢复网络 (Wang 等,2021; Yang等,2021)作为改进结果的后处理工具,结果在身份变化方面可能并不完美 (Wang et al . ,2021)和模糊的牙齿和脸 (Yang et al . ,2021)如图6所示 。
为此,我们提出了一种受最近图像生成网络启发的身份感知增强网络 (Karras 等人,2020; 陈等,2021)。详细地说,为了获取高分辨率说话头部数据集和对齐域以进行上采样,我们首先使用基于 GAN 先验的人脸恢复网络增强低分辨率数据集(Yang 等人,2021)。然而,训练期间增强的高分辨率数据集与模糊输出之间存在域差距D-Net测试期间的网络。然后,为了避免这种差距,我们产生低分辨率输入E-Net 通过将增强的帧及其相应的音频提供给L-Net。理想情况下,𝐿大号斜体L-Net 应该使用条件音频产生与原始帧相同的嘴唇动作。因此,我们可以直接使用高分辨率输入作为监督。至于架构,我们学习了两个基于样式的块 (Karras 等人,2020)对结果进行四次上采样,我们设计了一个基于 ResBlock 的编码器下标𝐸𝑖-Net 在每个样式块中生成身份感知全局调制。
1.3.4 后期处理
在粘贴回原始视频时,我们还删除了几个伪影,包括牙齿生成的伪影和合成边界框L-Net。为面部视频合成逼真的牙齿非常困难 (Suwajanakorn 等人,2017)。与以前使用牙齿代理的方法不同 (Suwajanakorn 等人,2017),我们从预训练的人脸恢复网络寻求帮助 (Wang et al . ,2021)通过面部解析增强牙齿 (Yu et al . ,2018)。至于由人脸包围盒引起的L-Net,我们分段 (Yu 等人,2018)使用多波段拉普拉斯金字塔混合 (Burt 和 Adelson,1983)。

图 6 不同人脸恢复网络在结果上的比较,包括 GFPGAN (Wang et al . ,2021) , GPEN (Yang 等人,2021)和我们的混合方法。请注意,GFPGAN 改变了很多身份。

图 7 与 LipGAN的定性比较 (KR 等人,2019) , Wav2Lip (Prajwal 等人,2020) , 和 PC-AVS (Zhou et al . ,2021)。上面两行分别显示编辑音频和输入视频帧。请注意,为了可视化输入音频,我们使用音频对应的面部来显示他们的嘴型。
表格1 LRS2 和 HDTF 数据集的定量结果
LRS2 数据集HDTF 数据集视觉质量唇型同步视觉质量唇型同步FID↓CPBD↑LSE-D↓伦敦政经学院↑FID↓CPBD↑LSE-D↓伦敦政经学院↑LipGAN (KR 等人,2019)5.1680.26159.6093.0627.6840.27549.9434.052不带 GAN 的 Wav2Lip (Prajwal 等人,2020)5.0690.26077.1166.8897.3580.27648.689****5.427Wav2Lip (Prajwal 等人,2020)3.9110.27147.1916.8705.6320.27638.8955.228PC-AVS (周等人,2021)12.8000.20857.6665.974----我们的5.1930.28096.5197.0894.5040.29039.3594.518
1.4 训练
我们的框架是使用 Pytorch 实现的 (Paszke 等人,2019),并且我们单独训练每个模块。训练完成后,整个框架可以按顺序进行测试,无需人工干预。下面,我们给出了每个模块的数据集和训练细节。可以在补充材料中找到更多详细信息。
1.4.1 每个模块的训练
(1)D-Net
为了执行语义引导的表情重现,我们在 VoxCeleb (Nagrani 等人,2017)具有姿势和表情的数据集(Deng et al . ,2019)。该数据集包含 22496 个说话的头部视频,具有不同的身份和头部姿势。我们将输入帧的大小调整为256×256类似于(Siarohin 等人,2019)。我们使用渐进式训练设置以 400k次迭代训练网络。至于损失函数,我们使用感知损失计算预测图像和地面实况之间的像素级差异 (Zhang 等人,2018)和am matrix loss (Gatys 等人,2016)。
(2)L-Net
我们训练LRS2 上的网络 (Afouras 等人,2018)数据集。这个唇读数据集包含来自 BBC 节目的大型160p视频。我们使用人脸检测 (Bulat 和 Tzimiropoulos,2017)并将输入图像调整为96×96,按照以前的方法(Prajwal 等人,2020)。我们训练L-Net 使用感知损失和口型同步鉴别器来实现视觉质量和视听同步 (Prajwal 等人,2020)。
(3)E-Net
的训练过程E-Net基于L-Net。我们提前增强 LRS2 数据集以获得高分辨率数据集,并训练E-Net 在 300k 次迭代中。至于损失函数,E-Net 接受了感知损失的混合损失的训练(Johnson 等人,2016年) , 像素级L1 loss,对抗loss(Isola,2017),口型同步鉴别器 (Prajwal et al . ,2020)和使用预训练人脸识别网络的身份丢失 ( Deng 等人,2019)。
1.4.2 评估
我们根据视觉质量和口型同步来评估所提出的方法。至于视觉质量,由于groud-truth实况谈话视频不可用,我们选择 FID (Heusel 等人,2017)和累积概率模糊检测 (CPBD) (Narvekar 和 Karam,2009)来评估生成视频的视觉质量。较低的 FID 分数意味着生成的图像更接近数据集分布。CPBD 反映了结果的清晰度。不同于(Prajwal 等人,2020),我们计算视频全帧的视觉质量指标而不是裁剪的人脸,因为我们关注整个视频的质量。我们选择LSE-C和 LSE-D(Prajwal 等人,2020)来评估嘴唇同步的质量。至于数据集的选择,我们在低分辨率数据集 (LRS2) 和高分辨率数据集 (HDTF) 上评估了我们的框架。HDTF 数据集包含来自 YouTube 的 720p 或 1080p 视频。按照(Prajwal 等人,2020),我们从另一个不同的视频中截取一个视频和一个音频剪辑来合成结果。我们构建14K和100 个二十秒音频视频对,分别用于 LRS2 和 HDTF 数据集评估。
1.5 结果
1.5.1 与最先进方法的比较
我们在相同设置下将我们的方法与三种最先进的方法进行比较,包括 LipGAN (KR 等人,2019) , Wav2Lip (Prajwal 等人,2020)和 PC-AVS (Zhou et al . ,2021)。LipGAN 和 Wav2Lip 具有相似的网络结构。不同的是,Wav2Lip 使用预训练的口型同步鉴别器作为口型专家,但具有更好的口型同步性能。PC-AVS 最初被提议用于一次性姿势可控的说话头部生成。我们使用每个原始视频帧的身份代码来替换原始的单图像人脸动画设置。我们使用开源代码将所提出的方法与这些方法进行比较。
如图1所示 ,所提出的方法根据CPBD和 FID 实现了更好的视觉质量。由于 LRS2 数据集是低分辨率的,而我们的方法产生高分辨率结果,因此 Wav2Lip 在 LRS2 数据集上的 FID 更好。至于唇形同步的准确性,我们的方法在这两个数据集上仍然获得了更好且可比的性能。我们还在图7中展示了一些示例来执行视觉比较。从这个图中,我们的方法产生了高质量的结果,比以前的方法具有更准确的唇形同步。由于视觉配音是一项视频编辑任务,我们强烈建议读者参考随附的视频将我们的方法与其他方法进行比较。
为了比较口型同步质量,需要人工评估。我们进行了一项用户研究,以进一步评估所提出方法的性能。在用户研究中,我们使用我们的方法和两种最先进的方法(LipGAN 和 Wav2Lip)在 HDTF 数据集上生成了十个具有不同音频和视频源的谈话视频。我们让用户在视觉和口型同步质量方面对每个视频发表意见。我们为每个选项设置了五个不同的分数(越大越好,范围从 1 到 5)。我们的表格总共发送给了 51 个人,得到了 510 条意见。如表2所示 ,大多数用户更愿意在视觉和口型同步质量方面给我们的方法更高的分数。
表 2 用户研究
方法视觉质量↑口型同步质量↑LipGAN2.8673.058Wav2Lip3.1733.398我们的4.171****4.100
1.5.2 消融研究
我们在表3中主要消融了我们框架的三个主要组成部分。第一个组成部分是两个图像编码器之间的交叉注意力。 L-Net表3中的交叉注意力 意味着通道明智地连接来自源帧和参考帧的特征。我们发现交叉注意力在口型同步质量方面很有帮助,因为它可以捕获远程依赖性。除了数值指标的提升,我们还发现它带来了更生动的结果(例如,更大的嘴巴)。然后我们显示添加的结果E-Net在我们的框架中。正如我们所料,身份识别面部增强将极大地提高视觉质量。但是,额外的伪像也会影响口型同步质量。最后,通过使用D-Net 来稳定参考帧,我们的框架在视觉和口型同步质量方面生成更好的视频。
表3。HDTF 数据集的主要消融研究。
视觉质量口型同步质量FID↓CPBD↑LSE-D↓伦敦政经学院↑L-Net w/o cross-att。5.9510.27439.7884.164L-Net6.4710.27559.5784.382L-Net+E-Net3.3340.287310.1713.764L-Net+E-Net+D-Net4.5040.29039.3594.518
1.5.3 情感谈话视频的扩展
我们已经在图2中展示了所提出的方法可用于情绪化的头部谈话视频编辑 。由于我们的方法只修改下半脸,我们也从面部动作单元系统 (Ekman 和 Friesen,1978)并使用(Pumarola et al . ,2018),导致不同的组合,如图8所示。

图 8 使用(Pumarola 等人,2018)

图 9 关于身份和极端姿势的失败案例。
1.5.4 局限性
尽管所提出的方法可以适用于自然环境中的视频,但在某些情况下它仍然包含一些明显的伪像。如图9所示,所提出的框架的一个显着差异是由于D-Net。然而,它只是我们方法的一个模块,我们将用另一个面部重现网络替换它 (Wang 等人,2021)或基于 3D 的人脸重现方法 (Kim 等人,2018)直接。我们的方法还显示了某些极端姿势中的一些伪影,如图9所示。由于我们的方法以逐帧方式编辑视频,因此结果可能会显示一些小的时间抖动和闪烁。
1.6 结论
我们提出了一个通用系统,用于通过首先去除嘴唇运动然后进行编辑来进行基于音频的头部谈话视频编辑。正如演示的那样,我们的框架可以在不进行微调的情况下处理野外视频,并使用音频作为条件产生高质量的结果。此外,我们的系统有潜力为视频的下半脸生成情绪化的说话头像。我们将在未来探索支持更多的情感,并将源音频和上下文与情感联系起来。
道德考虑。由于我们的系统可以在野外编辑视频的谈话内容,我们还考虑了所提出方法的误用。我们将为制作的视频添加强大的视频和音频水印,并开发工具来识别可信度。另一方面,我们希望我们的方法也能对 DeepFake 检测方面的研究有所帮助。
2 VideoReTalking部署与运行
2.1 conda环境准备
conda环境准备详见:annoconda
2.2 运行环境构建
git clone https://github.com/vinthony/video-retalking.git
cd video-retalking
conda create -n retalking python=3.8
conda activate retalking
conda install ffmpeg
pip install torch==1.9.0+cu111 torchvision==0.10.0+cu111 -f https://download.pytorch.org/whl/torch_stable.html
pip install -r requirements.txt
2.3 模型下载
(1)下载预训练模型
下载地址:https://drive.google.com/drive/folders/18rhjMpxK8LVVxf7PI6XwOidt8Vouv_H0
下载完成后,放入工程目录的checkpoints文件夹下。
命令行查看显示如下:
(retalking) [root@localhost video-retalking]# ll checkpoints/
总用量 3455452
-rw-r--r-- 1 root root 33877439 9月 22 14:17 30_net_gen.pth
drwxr-xr-x 2 root root 273 9月 22 14:18 BFM
-rw-r--r-- 1 root root 180424655 9月 22 14:18 DNet.pt
-rw-r--r-- 1 root root 573261168 9月 22 14:19 ENet.pth
-rw-r--r-- 1 root root 1456 9月 22 14:19 expression.mat
-rw-r--r-- 1 root root 288860037 9月 22 14:19 face3d_pretrain_epoch_20.pth
-rw-r--r-- 1 root root 348632874 9月 22 14:20 GFPGANv1.3.pth
-rw-r--r-- 1 root root 284085738 9月 22 14:20 GPEN-BFR-512.pth
-rw-r--r-- 1 root root 1534697728 9月 22 14:22 LNet.pth
-rw-r--r-- 1 root root 85331193 9月 22 14:23 ParseNet-latest.pth
-rw-r--r-- 1 root root 109497761 9月 22 14:23 RetinaFace-R50.pth
-rw-r--r-- 1 root root 99693937 9月 22 14:23 shape_predictor_68_face_landmarks.dat
(2)facexlib模型
下载地址:parsing_parsenet.pth, detection_Resnet50_Final.pth
下载完成后,放入如下目录:
~/anaconda3/envs/retalking/lib/python3.8/site-packages/facexlib/weights
(3)x2DFAN4-cd938726ad模型
下载地址:https://www.adrianbulat.com/downloads/python-fan/2DFAN4-cd938726ad.zip
下载完成后,放入如下目录:
~/.cache/torch/hub/checkpoints/
2.4 模型运行
python3 inference.py --face examples/face/1.mp4 --audio examples/audio/1.wav --outfile results/1_1.mp4
参数说明:
--exp_img
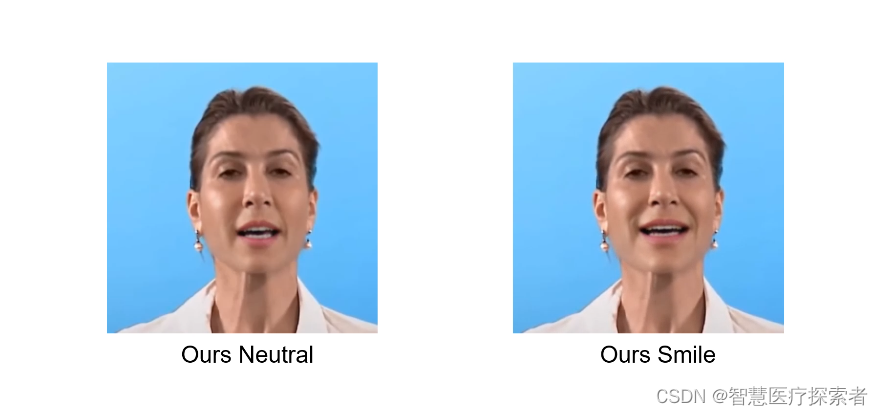
: 预训练表情模板,默认值为neutral,可以设置为smile或指向一个图片路径
--up_face
: 可以选择"surprise"或"angry"来改变表情
效果展示如下:
可以通过视频链接查看完整视频效果:
https://user-images.githubusercontent.com/4397546/224310754-665eb2dd-aadc-47dc-b1f9-2029a937b20a.mp4
版权归原作者 智慧医疗探索者 所有, 如有侵权,请联系我们删除。