
文章目录
0 前言
🔥 这两年开始毕业设计和毕业答辩的要求和难度不断提升,传统的毕设题目缺少创新和亮点,往往达不到毕业答辩的要求,这两年不断有学弟学妹告诉学长自己做的项目系统达不到老师的要求。
为了大家能够顺利以及最少的精力通过毕设,学长分享优质毕业设计项目,今天要分享的是
🚩 金融大数据分析与可视化
🥇学长这里给一个题目综合评分(每项满分5分)
- 难度系数:3分
- 工作量:3分
- 创新点:3分
一.题目理解
1.1.题目概况
该数据来自某信贷平台的贷款记录,总数据量超过120w,包含47列变量信息,其中15列为匿名变量。为了保证比赛的公平性,将会从中抽取80万条作为训练集,20万条作为测试集A,20万条作为测试集B,同时会对employmentTitle、purpose、postCode和title等信息进行脱敏。
1.2数据概况
一般而言,对于数据在比赛界面都有对应的数据概况介绍(匿名特征除外),说明列的性质特征。了解列的性质会有助于我们对于数据的理解和后续分析。
Tip:匿名特征,就是未告知数据列所属的性质的特征列。
train.csv
id 为贷款清单分配的唯一信用证标识
loanAmnt 贷款金额
term 贷款期限(year)
interestRate 贷款利率
installment 分期付款金额
grade 贷款等级
subGrade 贷款等级之子级
employmentTitle 就业职称
employmentLength 就业年限(年)
homeOwnership 借款人在登记时提供的房屋所有权状况
annualIncome 年收入
verificationStatus 验证状态
issueDate 贷款发放的月份
purpose 借款人在贷款申请时的贷款用途类别
postCode 借款人在贷款申请中提供的邮政编码的前3位数字
regionCode 地区编码
dti 债务收入比
delinquency_2years 借款人过去2年信用档案中逾期30天以上的违约事件数
ficoRangeLow 借款人在贷款发放时的fico所属的下限范围
ficoRangeHigh 借款人在贷款发放时的fico所属的上限范围
openAcc 借款人信用档案中未结信用额度的数量
pubRec 贬损公共记录的数量
pubRecBankruptcies 公开记录清除的数量
revolBal 信贷周转余额合计
revolUtil 循环额度利用率,或借款人使用的相对于所有可用循环信贷的信贷金额
totalAcc 借款人信用档案中当前的信用额度总数
initialListStatus 贷款的初始列表状态
applicationType 表明贷款是个人申请还是与两个共同借款人的联合申请
earliesCreditLine 借款人最早报告的信用额度开立的月份
title 借款人提供的贷款名称
policyCode 公开可用的策略代码=1新产品不公开可用的策略代码=2
n系列匿名特征 匿名特征n0-n14,为一些贷款人行为计数特征的处理
1.3预测指标
竞赛采用AUC作为评价指标。AUC(Area Under Curve)被定义为 ROC曲线 下与坐标轴围成的面积。
分类算法常见的评估指标如下:
1、混淆矩阵(Confuse Matrix)
(1)若一个实例是正类,并且被预测为正类,即为真正类TP(True Positive )
(2)若一个实例是正类,但是被预测为负类,即为假负类FN(False Negative )
(3)若一个实例是负类,但是被预测为正类,即为假正类FP(False Positive )
(4)若一个实例是负类,并且被预测为负类,即为真负类TN(True Negative )
2、准确率(Accuracy) 准确率是常用的一个评价指标,但是不适合样本不均衡的情况。


8、AUC(Area Under Curve) AUC(Area Under Curve)被定义为 ROC曲线
下与坐标轴围成的面积,显然这个面积的数值不会大于1。又由于ROC曲线一般都处于y=x这条直线的上方,所以AUC的取值范围在0.5和1之间。AUC越接近1.0,检测方法真实性越高;等于0.5时,则真实性最低,无应用价值。
对于金融风控预测类常见的评估指标如下:
1、KS(Kolmogorov-Smirnov) KS统计量由两位苏联数学家A.N. Kolmogorov和N.V.
Smirnov提出。在风控中,KS常用于评估模型区分度。区分度越大,说明模型的风险排序能力(ranking ability)越强。
K-S曲线与ROC曲线类似,不同在于
ROC曲线将真正例率和假正例率作为横纵轴
K-S曲线将真正例率和假正例率都作为纵轴,横轴则由选定的阈值来充当。 公式如下:
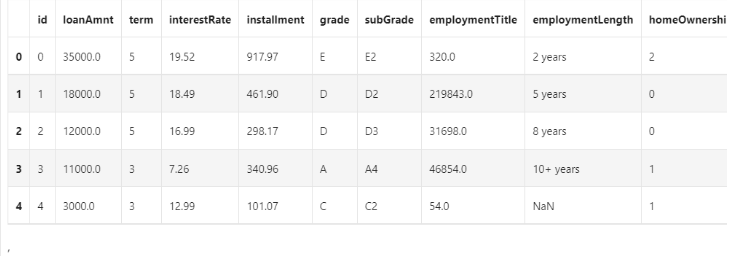
三.查看数据
train = pd.read_csv('train.csv')
testA = pd.read_csv('testA.csv')print('Train data shape:',train.shape)print('TestA data shape:',testA.shape)
train.head()
Train data shape: (800000, 47)
TestA data shape: (200000, 46)
四.分类指标计算示例
4.1混淆矩阵
## 混淆矩阵import numpy as np
from sklearn.metrics import confusion_matrix
y_pred =[0,1,0,1]
y_true =[0,1,1,0]print('混淆矩阵:\n',confusion_matrix(y_true, y_pred))

4.2准确度
## accuracyfrom sklearn.metrics import accuracy_score
y_pred =[0,1,0,1]
y_true =[0,1,1,0]print('ACC:',accuracy_score(y_true, y_pred))
ACC: 0.5
4.3precision(精确度),recall(召回率),f1-score
## Precision,Recall,F1-scorefrom sklearn import metrics
y_pred =[0,1,0,1]
y_true =[0,1,1,0]print('Precision',metrics.precision_score(y_true, y_pred))print('Recall',metrics.recall_score(y_true, y_pred))print('F1-score:',metrics.f1_score(y_true, y_pred))
Precision 0.5
Recall 0.5
F1-score: 0.5
4.4P-R曲线
## P-R曲线import matplotlib.pyplot as plt
from sklearn.metrics import precision_recall_curve
y_pred =[0,1,1,0,1,1,0,1,1,1]
y_true =[0,1,1,0,1,0,1,1,0,1]
precision, recall, thresholds = precision_recall_curve(y_true, y_pred)
plt.plot(precision, recall)
4.5ROC曲线
## ROC曲线from sklearn.metrics import roc_curve
y_pred =[0,1,1,0,1,1,0,1,1,1]
y_true =[0,1,1,0,1,0,1,1,0,1]
FPR,TPR,thresholds=roc_curve(y_true, y_pred)
plt.title('ROC')
plt.plot(FPR, TPR,'b')
plt.plot([0,1],[0,1],'r--')
plt.ylabel('TPR')
plt.xlabel('FPR')
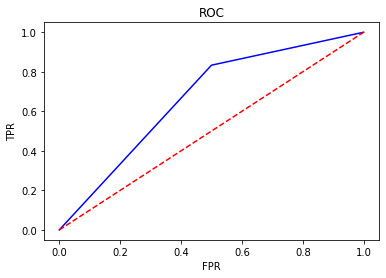
4.6AUC曲线
## AUCimport numpy as np
from sklearn.metrics import roc_auc_score
y_true = np.array([0,0,1,1])
y_scores = np.array([0.1,0.4,0.35,0.8])print('AUC socre:',roc_auc_score(y_true, y_scores))
AUC socre: 0.75
4.7KS值
## KS值 在实际操作时往往使用ROC曲线配合求出KS值from sklearn.metrics import roc_curve
y_pred =[0,1,1,0,1,1,0,1,1,1]
y_true =[0,1,1,0,1,0,1,1,1,1]
FPR,TPR,thresholds=roc_curve(y_true, y_pred)
KS=abs(FPR-TPR).max()print('KS值:',KS)
KS值: 0.5238095238095237
五.数据分析
5.1基本信息
data_train.info()

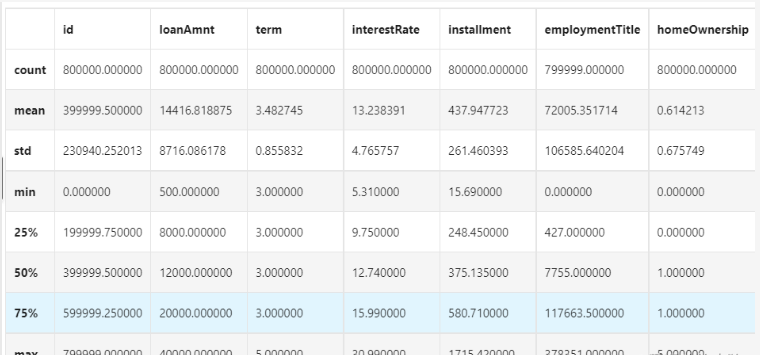
总体粗略的查看数据集各个特征的一些基本统计量
data_train.describe()
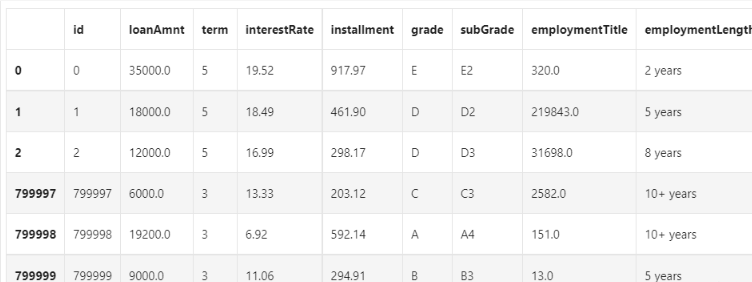
data_train.head(3).append(data_train.tail(3))
5.2查看数据集中特征缺失值,唯一值等
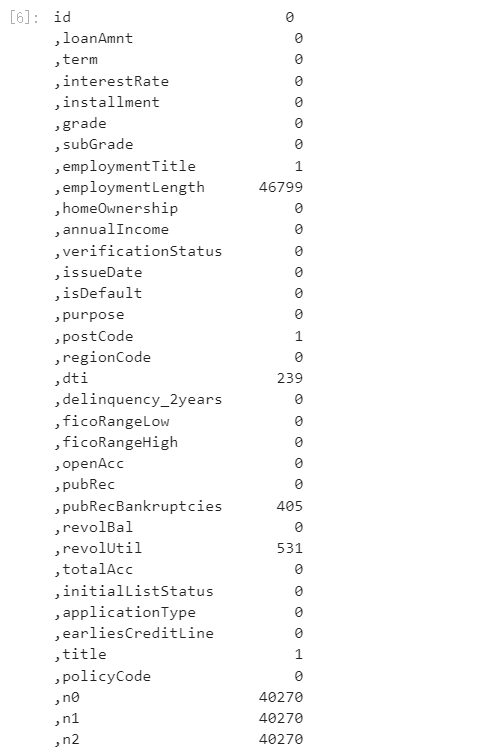
查看缺失值
print(f'There are {data_train.isnull().any().sum()} columns in train dataset with missing values.')
There are 22 columns in train dataset with missing values.
上面得到训练集有22列特征有缺失值,进一步查看缺失特征中缺失率大于50%的特征
have_null_fea_dict =(data_train.isnull().sum()/len(data_train)).to_dict()
fea_null_moreThanHalf ={}for key,value in have_null_fea_dict.items():if value >0.5:
fea_null_moreThanHalf[key]= value
具体的查看缺失特征及缺失率
# nan可视化
missing = data_train.isnull().sum()/len(data_train)
missing = missing[missing >0]
missing.sort_values(inplace=True)
missing.plot.bar()
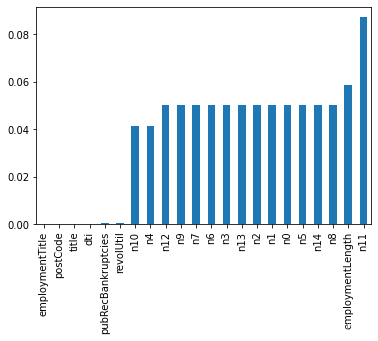
- 纵向了解哪些列存在 “nan”, 并可以把nan的个数打印,主要的目的在于查看某一列nan存在的个数是否真的很大,如果nan存在的过多,说明这一列对label的影响几乎不起作用了,可以考虑删掉。如果缺失值很小一般可以选择填充。
- 另外可以横向比较,如果在数据集中,某些样本数据的大部分列都是缺失的且样本足够的情况下可以考虑删除。
Tips: 比赛大杀器lgb模型可以自动处理缺失值,Task4模型会具体学习模型了解模型哦!
查看训练集测试集中特征属性只有一值的特征
one_value_fea =[col for col in data_train.columns if data_train[col].nunique()<=1]
one_value_fea_test =[col for col in data_test_a.columns if data_test_a[col].nunique()<=1]
[‘policyCode’]
print(f'There are {len(one_value_fea)} columns in train dataset with one unique value.')
print(f'There are {len(one_value_fea_test)} columns in test dataset with one unique value.')
There are 1 columns in train dataset with one unique value.
There are 1 columns in test dataset with one unique value.
总结:
47列数据中有22列都缺少数据,这在现实世界中很正常。‘policyCode’具有一个唯一值(或全部缺失)。有很多连续变量和一些分类变量。
5.3查看特征的数值类型有哪些,对象类型有哪些
- 特征一般都是由类别型特征和数值型特征组成,而数值型特征又分为连续型和离散型
- 类别型特征有时具有非数值关系,有时也具有数值关系。比如‘grade’中的等级A,B,C等,是否只是单纯的分类,还是A优于其他要结合业务判断。
- 数值型特征本是可以直接入模的,但往往风控人员要对其做分箱,转化为WOE编码进而做标准评分卡等操作。从模型效果上来看,特征分箱主要是为了降低变量的复杂性,减少变量噪音对模型的影响,提高自变量和因变量的相关度。从而使模型更加稳定。numerical_fea = list(data_train.select_dtypes(exclude=[‘object’]).columns) category_fea = list(filter(lambda x: x not in numerical_fea,list(data_train.columns)))

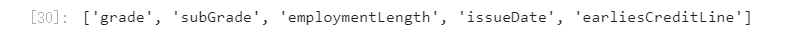
data_train.grade
#过滤数值型类别特征defget_numerical_serial_fea(data,feas):
numerical_serial_fea =[]
numerical_noserial_fea =[]for fea in feas:
temp = data[fea].nunique()if temp <=10:
numerical_noserial_fea.append(fea)continue
numerical_serial_fea.append(fea)return numerical_serial_fea,numerical_noserial_fea
numerical_serial_fea,numerical_noserial_fea = get_numerical_serial_fea(data_train,numerical_fea)

data_train['term'].value_counts()#离散型变量
data_train['homeOwnership'].value_counts()#离散型变量
data_train['verificationStatus'].value_counts()#离散型变量
data_train['initialListStatus'].value_counts()#离散型变量
data_train['applicationType'].value_counts()#离散型变量
data_train['policyCode'].value_counts()#离散型变量,无用,全部一个值
data_train['n11'].value_counts()#离散型变量,相差悬殊,用不用再分析
data_train['n12'].value_counts()#离散型变量,相差悬殊,用不用再分析
5.3.1数值连续型变量分析
#每个数字特征得分布可视化# 这里画图估计需要10-15分钟
f = pd.melt(data_train, value_vars=numerical_serial_fea)
g = sns.FacetGrid(f, col="variable", col_wrap=2, sharex=False, sharey=False)
g = g.map(sns.distplot,"value")
图片数量有点多,暂时放置几张
- 查看某一个数值型变量的分布,查看变量是否符合正态分布,如果不符合正太分布的变量可以log化后再观察下是否符合正态分布。
- 如果想统一处理一批数据变标准化 必须把这些之前已经正态化的数据提出
- 正态化的原因:一些情况下正态非正态可以让模型更快的收敛,一些模型要求数据正态(eg. GMM、KNN),保证数据不要过偏态即可,过于偏态可能会影响模型预测结果。
#Ploting Transaction Amount Values Distributionplt.figure(figsize=(16,12))plt.suptitle('Transaction Values Distribution', fontsize=22)plt.subplot(221)sub_plot_1 = sns.distplot(data_train['loanAmnt'])sub_plot_1.set_title("loanAmnt Distribuition", fontsize=18)sub_plot_1.set_xlabel("")sub_plot_1.set_ylabel("Probability", fontsize=15)plt.subplot(222)sub_plot_2 = sns.distplot(np.log(data_train['loanAmnt']))sub_plot_2.set_title("loanAmnt (Log) Distribuition", fontsize=18)sub_plot_2.set_xlabel("")sub_plot_2.set_ylabel("Probability", fontsize=15)
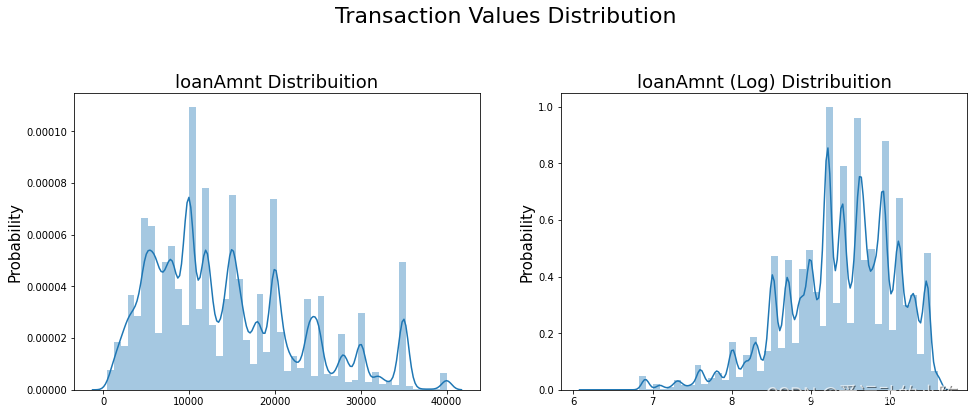
5.3.2非数值类别型变量分析
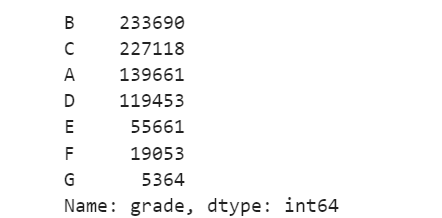
data_train['grade'].value_counts()
data_train['subGrade'].value_counts()

data_train['employmentLength'].value_counts()
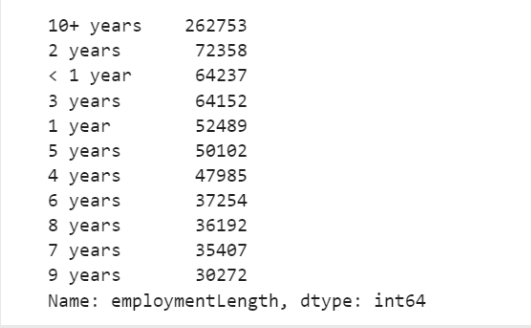
data_train['issueDate'].value_counts()
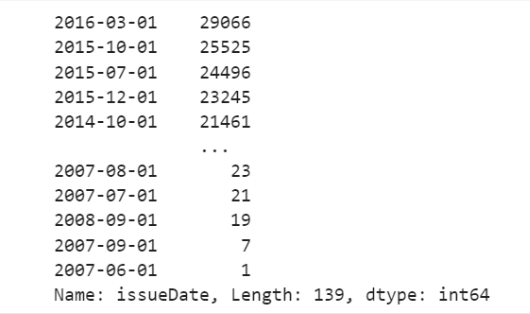
5.3.3总结:
上面我们用value_counts()等函数看了特征属性的分布,但是图表是概括原始信息最便捷的方式。
数无形时少直觉。
同一份数据集,在不同的尺度刻画上显示出来的图形反映的规律是不一样的。python将数据转化成图表,但结论是否正确需要由你保证。
5.4变量分布可视化
5.4.1单一变量分布可视化
plt.figure(figsize=(8,8))
sns.barplot(data_train["employmentLength"].value_counts(dropna=False)[:20],
data_train["employmentLength"].value_counts(dropna=False).keys()[:20])
plt.show()
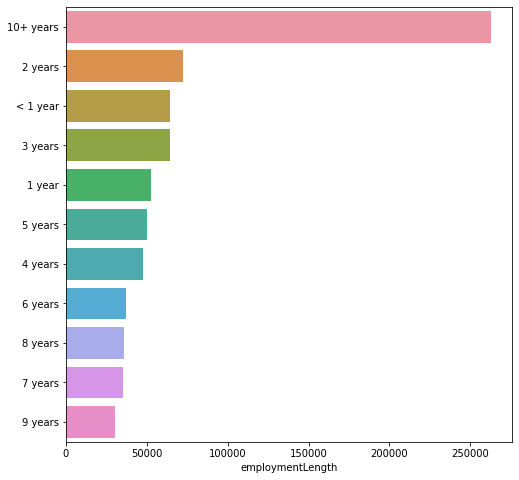
5.4.2根绝y值不同可视化x某个特征的分布
首先查看类别型变量在不同y值上的分布
train_loan_fr = data_train.loc[data_train['isDefault']==1]
train_loan_nofr = data_train.loc[data_train['isDefault']==0]
fig,((ax1, ax2),(ax3, ax4))= plt.subplots(2,2, figsize=(15,8))
train_loan_fr.groupby('grade')['grade'].count().plot(kind='barh', ax=ax1, title='Count of grade fraud')
train_loan_nofr.groupby('grade')['grade'].count().plot(kind='barh', ax=ax2, title='Count of grade non-fraud')
train_loan_fr.groupby('employmentLength')['employmentLength'].count().plot(kind='barh', ax=ax3, title='Count of employmentLength fraud')
train_loan_nofr.groupby('employmentLength')['employmentLength'].count().plot(kind='barh', ax=ax4, title='Count of employmentLength non-fraud')
plt.show()
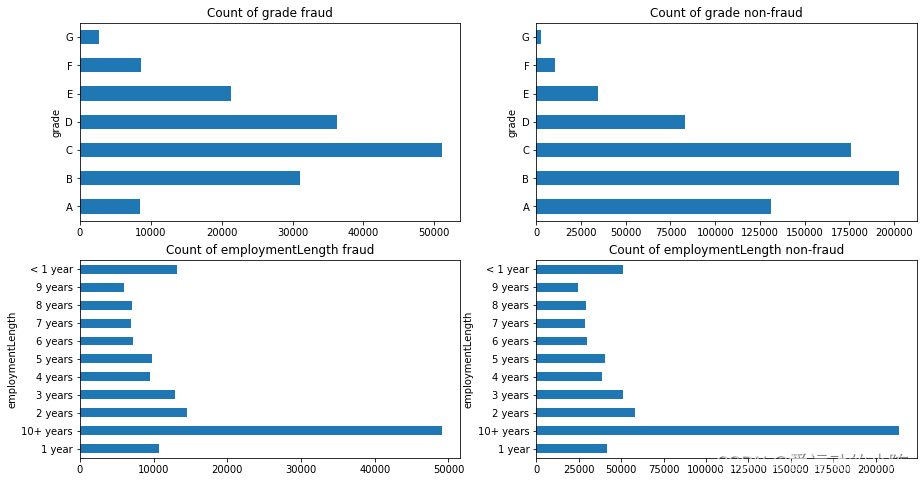
其次查看连续型变量在不同y值上的分布
fig,((ax1, ax2))= plt.subplots(1,2, figsize=(15,6))
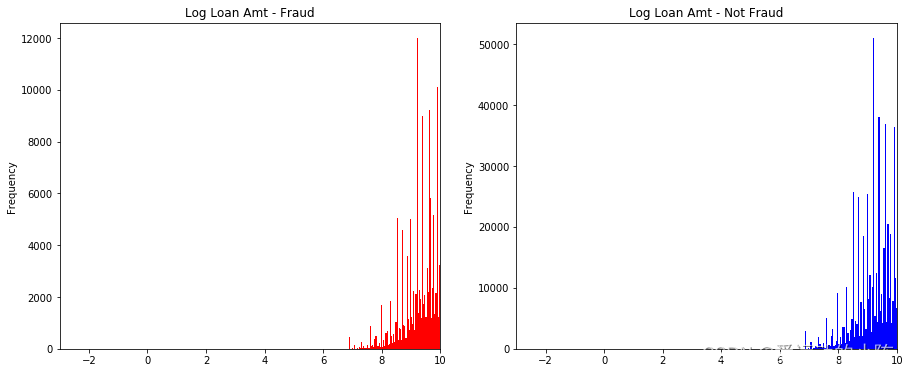
data_train.loc[data_train['isDefault']==1] \
['loanAmnt'].apply(np.log) \
.plot(kind='hist',
bins=100,
title='Log Loan Amt - Fraud',
color='r',
xlim=(-3,10),
ax= ax1)
data_train.loc[data_train['isDefault']==0] \
['loanAmnt'].apply(np.log) \
.plot(kind='hist',
bins=100,
title='Log Loan Amt - Not Fraud',
color='b',
xlim=(-3,10),
ax=ax2)
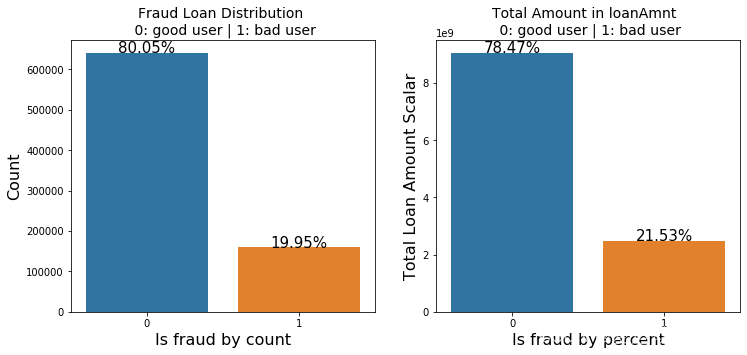
total =len(data_train)
total_amt = data_train.groupby(['isDefault'])['loanAmnt'].sum().sum()
plt.figure(figsize=(12,5))
plt.subplot(121)##1代表行,2代表列,所以一共有2个图,1代表此时绘制第一个图。
plot_tr = sns.countplot(x='isDefault',data=data_train)#data_train‘isDefault’这个特征每种类别的数量**
plot_tr.set_title("Fraud Loan Distribution \n 0: good user | 1: bad user", fontsize=14)
plot_tr.set_xlabel("Is fraud by count", fontsize=16)
plot_tr.set_ylabel('Count', fontsize=16)for p in plot_tr.patches:
height = p.get_height()
plot_tr.text(p.get_x()+p.get_width()/2.,
height +3,'{:1.2f}%'.format(height/total*100),
ha="center", fontsize=15)
percent_amt =(data_train.groupby(['isDefault'])['loanAmnt'].sum())
percent_amt = percent_amt.reset_index()
plt.subplot(122)
plot_tr_2 = sns.barplot(x='isDefault', y='loanAmnt', dodge=True, data=percent_amt)
plot_tr_2.set_title("Total Amount in loanAmnt \n 0: good user | 1: bad user", fontsize=14)
plot_tr_2.set_xlabel("Is fraud by percent", fontsize=16)
plot_tr_2.set_ylabel('Total Loan Amount Scalar', fontsize=16)for p in plot_tr_2.patches:
height = p.get_height()
plot_tr_2.text(p.get_x()+p.get_width()/2.,
height +3,'{:1.2f}%'.format(height/total_amt *100),
ha="center", fontsize=15)
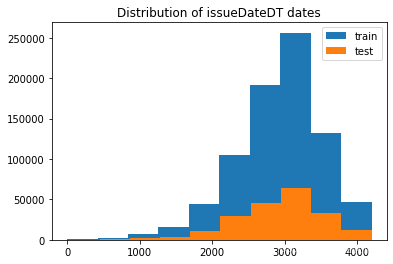
5.4.3时间格式数据处理及查看
#转化成时间格式 issueDateDT特征表示数据日期离数据集中日期最早的日期(2007-06-01)的天数
data_train['issueDate']= pd.to_datetime(data_train['issueDate'],format='%Y-%m-%d')
startdate = datetime.datetime.strptime('2007-06-01','%Y-%m-%d')
data_train['issueDateDT']= data_train['issueDate'].apply(lambda x: x-startdate).dt.days
#转化成时间格式
data_test_a['issueDate']= pd.to_datetime(data_train['issueDate'],format='%Y-%m-%d')
startdate = datetime.datetime.strptime('2007-06-01','%Y-%m-%d')
data_test_a['issueDateDT']= data_test_a['issueDate'].apply(lambda x: x-startdate).dt.days
plt.hist(data_train['issueDateDT'], label='train');
plt.hist(data_test_a['issueDateDT'], label='test');
plt.legend();
plt.title('Distribution of issueDateDT dates');#train 和 test issueDateDT 日期有重叠 所以使用基于时间的分割进行验证是不明智的
5.4.4掌握透视图可以让我们更好的了解数据
#透视图 索引可以有多个,“columns(列)”是可选的,聚合函数aggfunc最后是被应用到了变量“values”中你所列举的项目上。
pivot = pd.pivot_table(data_train, index=['grade'], columns=['issueDateDT'], values=['loanAmnt'], aggfunc=np.sum)
5.4.5用pandas_profiling生成数据报告
import pandas_profiling
pfr = pandas_profiling.ProfileReport(data_train)
pfr.to_file("./example.html")
5.4.6总结
数据探索性分析是我们初步了解数据,熟悉数据为特征工程做准备的阶段,甚至很多时候EDA阶段提取出来的特征可以直接当作规则来用。可见EDA的重要性,这个阶段的主要工作还是借助于各个简单的统计量来对数据整体的了解,分析各个类型变量相互之间的关系,以及用合适的图形可视化出来直观观察。希望本节内容能给初学者带来帮助,更期待各位学习者对其中的不足提出建议。
六.特征工程
6.1导入包并读取数据
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
import datetime
from tqdm import tqdm
from sklearn.preprocessing import LabelEncoder
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.preprocessing import MinMaxScaler
import xgboost as xgb
import lightgbm as lgb
from catboost import CatBoostRegressor
import warnings
from sklearn.model_selection import StratifiedKFold, KFold
from sklearn.metrics import accuracy_score, f1_score, roc_auc_score, log_loss
warnings.filterwarnings('ignore')
data_train =pd.read_csv('train.csv')
data_test_a = pd.read_csv('testA.csv')
6.2数据预处理
数据EDA部分我们已经对数据的大概和某些特征分布有了了解,数据预处理部分一般我们要处理一些EDA阶段分析出来的问题,这里介绍了数据缺失值的填充,时间格式特征的转化处理,某些对象类别特征的处理。
首先我们查找出数据中的对象特征和数值特征
numerical_fea =list(data_train.select_dtypes(exclude=['object']).columns)
category_fea =list(filter(lambda x: x notin numerical_fea,list(data_train.columns)))
label ='isDefault'
numerical_fea.remove(label)
6.2缺失值填充
把所有缺失值替换为指定的值0
data_train = data_train.fillna(0)
向用缺失值上面的值替换缺失值
data_train = data_train.fillna(axis=0,method=‘ffill’)
纵向用缺失值下面的值替换缺失值,且设置最多只填充两个连续的缺失值
data_train = data_train.fillna(axis=0,method=‘bfill’,limit=2)
#查看缺失值情况
data_train.isnull().sum()
#按照平均数填充数值型特征
data_train[numerical_fea]= data_train[numerical_fea].fillna(data_train[numerical_fea].median())
data_test_a[numerical_fea]= data_test_a[numerical_fea].fillna(data_train[numerical_fea].median())#按照众数填充类别型特征
data_train[category_fea]= data_train[category_fea].fillna(data_train[category_fea].mode())
data_test_a[category_fea]= data_test_a[category_fea].fillna(data_train[category_fea].mode())
data_train.isnull().sum()

6.3时间格式处理
#转化成时间格式for data in[data_train, data_test_a]:
data['issueDate']= pd.to_datetime(data['issueDate'],format='%Y-%m-%d')
startdate = datetime.datetime.strptime('2007-06-01','%Y-%m-%d')#构造时间特征
data['issueDateDT']= data['issueDate'].apply(lambda x: x-startdate).dt.days
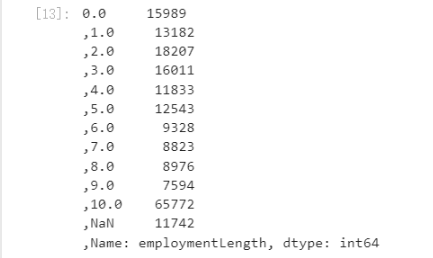
data_train['employmentLength'].value_counts(dropna=False).sort_index()
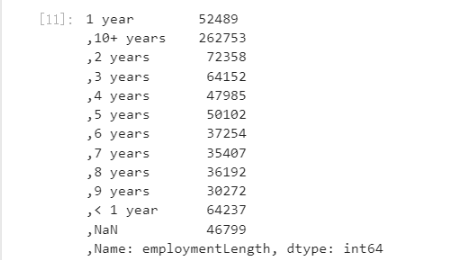
defemploymentLength_to_int(s):if pd.isnull(s):return s
else:return np.int8(s.split()[0])for data in[data_train, data_test_a]:
data['employmentLength'].replace(to_replace='10+ years', value='10 years', inplace=True)
data['employmentLength'].replace('< 1 year','0 years', inplace=True)
data['employmentLength']= data['employmentLength'].apply(employmentLength_to_int)
data['employmentLength'].value_counts(dropna=False).sort_index()
对earliesCreditLine进行预处理
data_train['earliesCreditLine'].sample(5)
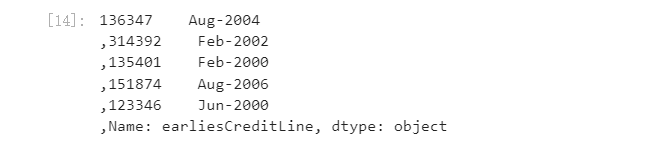
for data in[data_train, data_test_a]:
data['earliesCreditLine']= data['earliesCreditLine'].apply(lambda s:int(s[-4:]))
6.4类别特征处理
# 部分类别特征
cate_features =['grade','subGrade','employmentTitle','homeOwnership','verificationStatus','purpose','postCode','regionCode', \
'applicationType','initialListStatus','title','policyCode']for f in cate_features:print(f,'类型数:', data[f].nunique())

像等级这种类别特征,是有优先级的可以labelencode或者自映射
for data in[data_train, data_test_a]:
data['grade']= data['grade'].map({'A':1,'B':2,'C':3,'D':4,'E':5,'F':6,'G':7})# 类型数在2之上,又不是高维稀疏的,且纯分类特征for data in[data_train, data_test_a]:
data = pd.get_dummies(data, columns=['subGrade','homeOwnership','verificationStatus','purpose','regionCode'], drop_first=True)
6.5异常值处理
检测异常的方法一:均方差¶
在统计学中,如果一个数据分布近似正态,那么大约 68% 的数据值会在均值的一个标准差范围内,大约 95% 会在两个标准差范围内,大约 99.7%
会在三个标准差范围内。
deffind_outliers_by_3segama(data,fea):
data_std = np.std(data[fea])
data_mean = np.mean(data[fea])
outliers_cut_off = data_std *3
lower_rule = data_mean - outliers_cut_off
upper_rule = data_mean + outliers_cut_off
data[fea+'_outliers']= data[fea].apply(lambda x:str('异常值')if x > upper_rule or x < lower_rule else'正常值')return data
得到特征的异常值后可以进一步分析变量异常值和目标变量的关系
data_train = data_train.copy()for fea in numerical_fea:
data_train = find_outliers_by_3segama(data_train,fea)print(data_train[fea+'_outliers'].value_counts())print(data_train.groupby(fea+'_outliers')['isDefault'].sum())print('*'*10)

例如可以看到异常值在两个变量上的分布几乎复合整体的分布,如果异常值都属于为1的用户数据里面代表什么呢?
#删除异常值for fea in numerical_fea:
data_train = data_train[data_train[fea+'_outliers']=='正常值']
data_train = data_train.reset_index(drop=True)
检测异常的方法二:箱型图
总结一句话:四分位数会将数据分为三个点和四个区间,IQR = Q3 -Q1,下触须=Q1 − 1.5x IQR,上触须=Q3 + 1.5x IQR;
6.6数据分桶
特征分箱的目的:
从模型效果上来看,特征分箱主要是为了降低变量的复杂性,减少变量噪音对模型的影响,提高自变量和因变量的相关度。从而使模型更加稳定。
数据分桶的对象:
将连续变量离散化
将多状态的离散变量合并成少状态
分箱的原因:
数据的特征内的值跨度可能比较大,对有监督和无监督中如k-
均值聚类它使用欧氏距离作为相似度函数来测量数据点之间的相似度。都会造成大吃小的影响,其中一种解决方法是对计数值进行区间量化即数据分桶也叫做数据分箱,然后使用量化后的结果。
分箱的优点:
处理缺失值:当数据源可能存在缺失值,此时可以把null单独作为一个分箱。
处理异常值:当数据中存在离群点时,可以把其通过分箱离散化处理,从而提高变量的鲁棒性(抗干扰能力)。例如,age若出现200这种异常值,可分入“age >
60”这个分箱里,排除影响。
业务解释性:我们习惯于线性判断变量的作用,当x越来越大,y就越来越大。但实际x与y之间经常存在着非线性关系,此时可经过WOE变换。
特别要注意一下分箱的基本原则:
(1)最小分箱占比不低于5%
(2)箱内不能全部是好客户
(3)连续箱单调
固定宽度分箱
当数值横跨多个数量级时,最好按照 10
的幂(或任何常数的幂)来进行分组:09、1099、100999、10009999,等等。固定宽度分箱非常容易计算,但如果计数值中有比较大的缺口,就会产生很多没有任何数据的空箱子。
# 通过除法映射到间隔均匀的分箱中,每个分箱的取值范围都是loanAmnt/1000
data['loanAmnt_bin1']= np.floor_divide(data['loanAmnt'],1000)## 通过对数函数映射到指数宽度分箱
data['loanAmnt_bin2']= np.floor(np.log10(data['loanAmnt']))##分位数分箱
data['loanAmnt_bin3']= pd.qcut(data['loanAmnt'],10, labels=False)
6.7特征编码
labelEncode 直接放入树模型中
#label-encode:subGrade,postCode,title# 高维类别特征需要进行转换for col in tqdm(['employmentTitle','postCode','title','subGrade']):
le = LabelEncoder()
le.fit(list(data_train[col].astype(str).values)+list(data_test_a[col].astype(str).values))
data_train[col]= le.transform(list(data_train[col].astype(str).values))
data_test_a[col]= le.transform(list(data_test_a[col].astype(str).values))print('Label Encoding 完成')
逻辑回归等模型要单独增加的特征工程
对特征做归一化,去除相关性高的特征
归一化目的是让训练过程更好更快的收敛,避免特征大吃小的问题
去除相关性是增加模型的可解释性,加快预测过程。
# 举例归一化过程#伪代码for fea in[要归一化的特征列表]:
data[fea]=((data[fea]- np.min(data[fea]))/(np.max(data[fea])- np.min(data[fea])))
6.8特征选择
特征选择技术可以精简掉无用的特征,以降低最终模型的复杂性,它的最终目的是得到一个简约模型,在不降低预测准确率或对预测准确率影响不大的情况下提高计算速度。特征选择不是为了减少训练时间(实际上,一些技术会增加总体训练时间),而是为了减少模型评分时间。
特征选择的方法:
1 Filter
方差选择法
相关系数法(pearson 相关系数)
卡方检验
互信息法
2 Wrapper (RFE)
递归特征消除法
3 Embedded
基于惩罚项的特征选择法
基于树模型的特征选择
方差选择法
方差选择法中,先要计算各个特征的方差,然后根据设定的阈值,选择方差大于阈值的特征
from sklearn.feature_selection import VarianceThreshold
#其中参数threshold为方差的阈值
VarianceThreshold(threshold=3).fit_transform(train,target_train)
相关系数法
Pearson 相关系数 皮尔森相关系数是一种最简单的,可以帮助理解特征和响应变量之间关系的方法,该方法衡量的是变量之间的线性相关性。 结果的取值区间为
[-1,1] , -1 表示完全的负相关, +1表示完全的正相关,0 表示没有线性相关。
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
#选择K个最好的特征,返回选择特征后的数据#第一个参数为计算评估特征是否好的函数,该函数输入特征矩阵和目标向量,#输出二元组(评分,P值)的数组,数组第i项为第i个特征的评分和P值。在此定义为计算相关系数#参数k为选择的特征个数
SelectKBest(k=5).fit_transform(train,target_train)
本数据集中我们删除非入模特征后,并对缺失值填充,然后用计算协方差的方式看一下特征间相关性,然后进行模型训练
# 删除不需要的数据for data in[data_train, data_test_a]:
data.drop(['issueDate'], axis=1,inplace=True)"纵向用缺失值上面的值替换缺失值"
data_train = data_train.fillna(axis=0,method='ffill')
x_train = data_train
#计算协方差
data_corr = x_train.corrwith(data_train.isDefault)#计算相关性
result = pd.DataFrame(columns=['features','corr'])
result['features']= data_corr.index
result['corr']= data_corr.values
# 当然也可以直接看图
data_numeric = data_train[numerical_fea]
correlation = data_numeric.corr()
f , ax = plt.subplots(figsize =(7,7))
plt.title('Correlation of Numeric Features with Price',y=1,size=16)
sns.heatmap(correlation,square =True, vmax=0.8)

恭喜你能够看完这篇博客,相信你已经有点累了,加油!!!
这篇博客侧重于数据分析与数据预处理,特征构造选择,下篇才是重点。由于篇幅过长,写作多有不便,未完结。
最后
版权归原作者 caxiou 所有, 如有侵权,请联系我们删除。