

前言
上一篇我们学习了如何利用labelimg标注自己的数据集,下一步就是该对这些数据集进行划分了。面对繁杂的数据集,如果手动划分的话不仅麻烦而且不能保证随机性。本篇文章就来手把手教你利用代码,自动将自己的数据集划分为训练集、验证集和测试集。一起来学习吧!

前期回顾:
YOLOv5入门实践(1)——手把手带你环境配置搭建
YOLOv5入门实践(2)——手把手教你利用labelimg标注数据集
 🍀本人YOLOv5源码详解系列:
🍀本人YOLOv5源码详解系列:
YOLOv5源码逐行超详细注释与解读(1)——项目目录结构解析
YOLOv5源码逐行超详细注释与解读(2)——推理部分detect.py
YOLOv5源码逐行超详细注释与解读(3)——训练部分train.py
YOLOv5源码逐行超详细注释与解读(4)——验证部分val(test).py
YOLOv5源码逐行超详细注释与解读(5)——配置文件yolov5s.yaml
YOLOv5源码逐行超详细注释与解读(6)——网络结构(1)yolo.py
YOLOv5源码逐行超详细注释与解读(7)——网络结构(2)common.py
目录

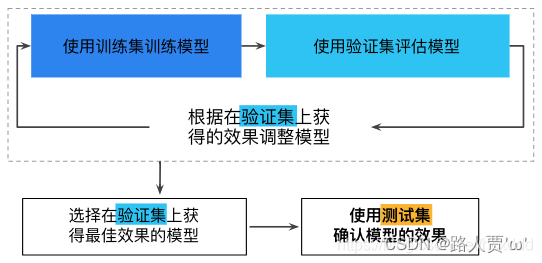
一、训练集、测试集、验证集介绍
我们通常把训练的数据分为三个文件夹:训练集、测试集和验证集。
我们来举一个栗子:模型的训练与学习,类似于老师教学生学知识的过程。
- 1、训练集(train set):用于训练模型以及确定参数。相当于老师教学生知识的过程。
- 2、验证集(validation set):用于确定网络结构以及调整模型的超参数。相当于月考等小测验,用于学生对学习的查漏补缺。
- 3、测试集(test set):用于检验模型的泛化能力。相当于大考,上战场一样,真正的去检验学生的学习效果。
参数(parameters):指由模型通过学习得到的变量,如权重和偏置。
超参数(hyperparameters):指根据经验进行设定的参数,如迭代次数,隐层的层数,每层神经元的个数,学习率等。
二、准备自己的数据集
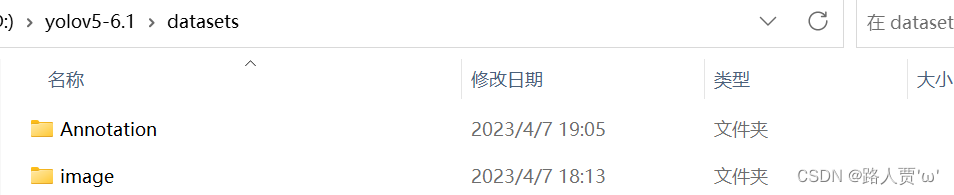
第1步:在YOLOv5项目下创建对应文件夹
在YOLOv5项目目录下创建datasets文件夹(名字自定义),接着在该文件夹下新建Annotations和images****文件夹。
- Annotations:存放标注的标签文件
- images:存放需要打标签的图片文件
如下图所示:
第2步:打开labelimg开始标注数据集
使用教程可以看我的上一篇介绍: YOLOv5入门实践(2)——手把手教你利用labelimg标注数据集
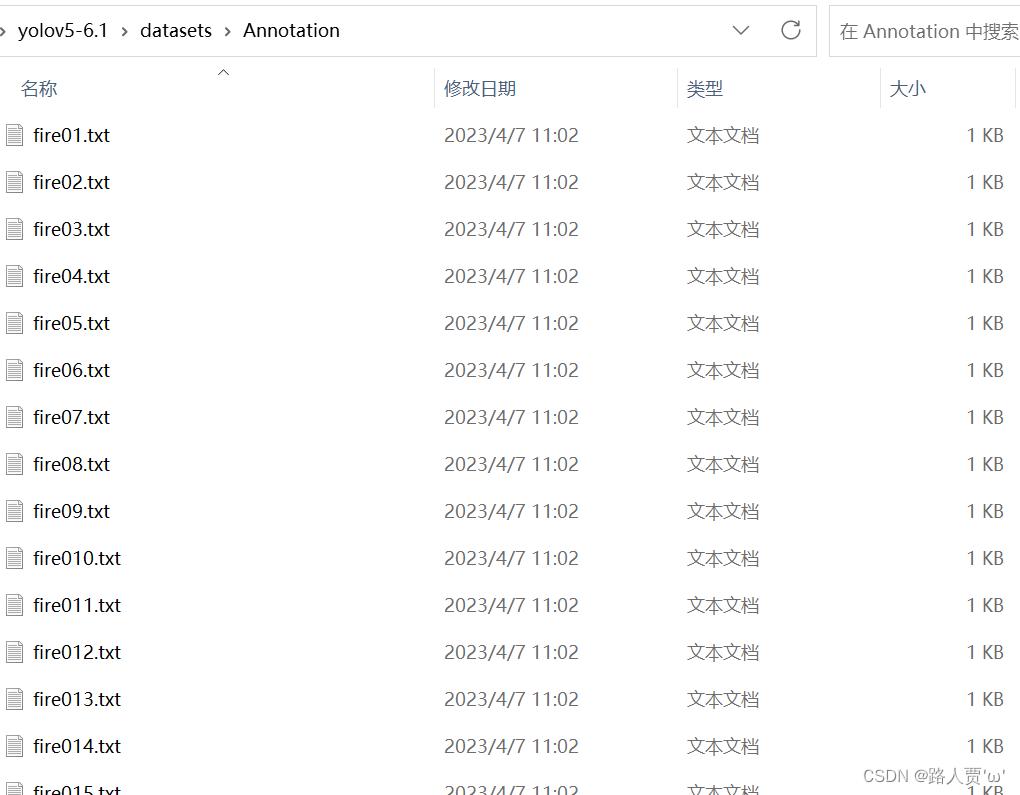
标注后Annotations文件夹下面为xml文件,如下图所示:
** images文件夹**是我们的数据集图片,格式为jpg,如下图所示: 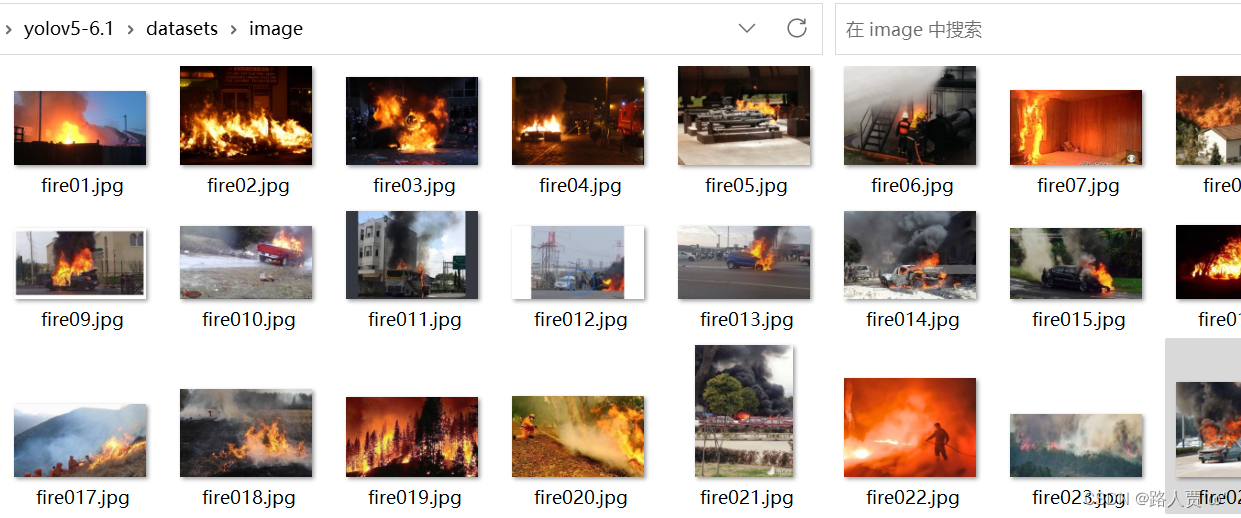
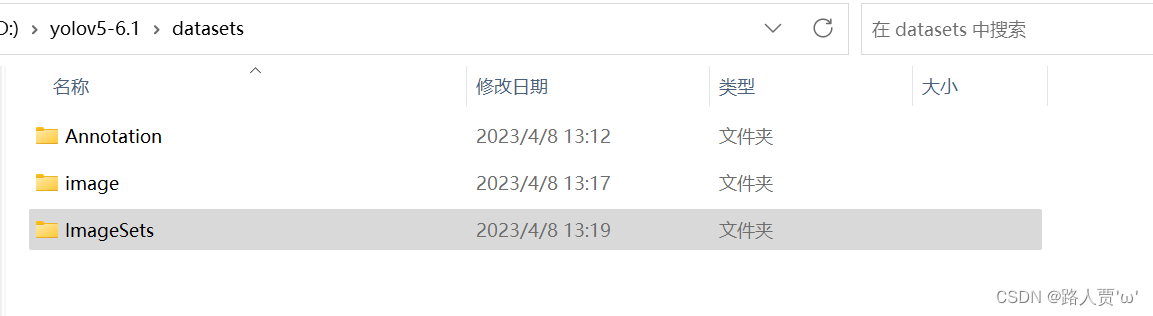
第3步:创建保存划分后数据集的文件夹
创建一个名为ImageSets的文件夹(名字自定义),用来保存一会儿划分好的训练集、测试集和验证集。
** 准备工作的注意事项:**
- 所有训练所需的图像存于一个目录,所有训练所需的标签存于一个目录。
- 图像文件与标签文件都统一的格式。
- 图像名与标签名一一对应。
三、划分的代码及讲解
完成以上工作我们就可以来进行数据集的划分啦!
**第1步:创建split.py **
在YOLOv5项目目录下创建split.py项目。
第2步:将数据集打乱顺序
通过上面我们知道,数据集有images和Annotations这两个文件,我们需要把这两个文件绑定,然后将其打乱顺序。
首先设置空列表,将for循环读取这两个文件的每个数据放入对应表中,再将这两个文件通过zip()函数绑定,计算总长度。
def split_data(file_path,xml_path, new_file_path, train_rate, val_rate, test_rate):
each_class_image = []
each_class_label = []
for image in os.listdir(file_path):
each_class_image.append(image)
for label in os.listdir(xml_path):
each_class_label.append(label)
data=list(zip(each_class_image,each_class_label))
total = len(each_class_image)
然后用random.shuffle()函数打乱顺序,再将两个列表解绑。
random.shuffle(data)
each_class_image,each_class_label=zip(*data)
第3步:按照确定好的比例将两个列表元素分割
分别获取train、val、test这三个文件夹对应的图片和标签。
train_images = each_class_image[0:int(train_rate * total)]
val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)]
test_images = each_class_image[int((train_rate + val_rate) * total):]
train_labels = each_class_label[0:int(train_rate * total)]
val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)]
test_labels = each_class_label[int((train_rate + val_rate) * total):]
第4步:在本地生成文件夹,将划分好的数据集分别保存
接下来就是设置相应的路径保存格式,将图片和标签对应保存下来。
for image in train_images:
print(image)
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'train' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in train_labels:
print(label)
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'train' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in val_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'val' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in val_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'val' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in test_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'test' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in test_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'test' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
第5步:设置路径并设置划分比例
这里要设置的有三个:
- file_path:图片所在位置,就是image文件夹
- xml_path:标签所在位置,就是Annotation文件夹
- new_file_path:划分后三个文件的保存位置,就是ImageSets文件夹
if __name__ == '__main__':
file_path = "D:\yolov5-6.1\datasets\image"
xml_path = "D:\yolov5-6.1\datasets\Annotation"
new_file_path = "D:\yolov5-6.1\datasets\ImageSets"
split_data(file_path,xml_path, new_file_path, train_rate=0.7, val_rate=0.1, test_rate=0.2)
最后一行是设置划分比例,这里的比例分配大家可以随便划分,我选取的是7:1:2。
至此,我们的数据集就划分好了。
来运行一下看看效果吧:
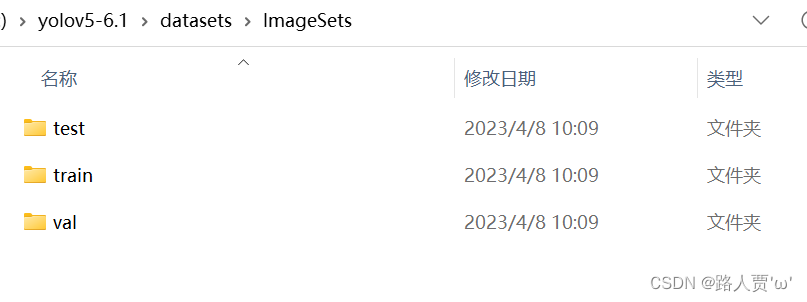
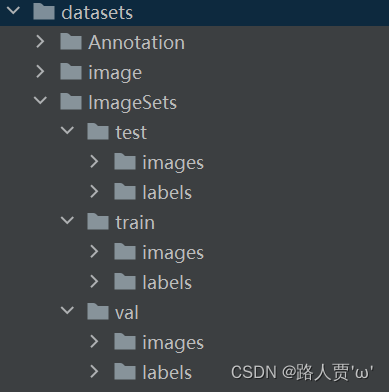
我们可以看到,数据集图片和标签已经划分成了train、val和test三个文件夹。
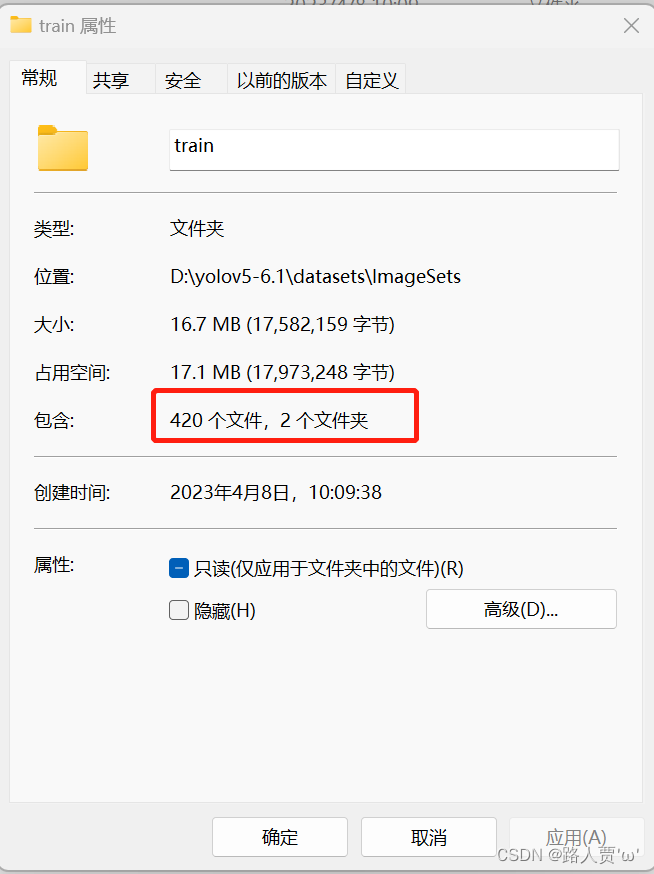
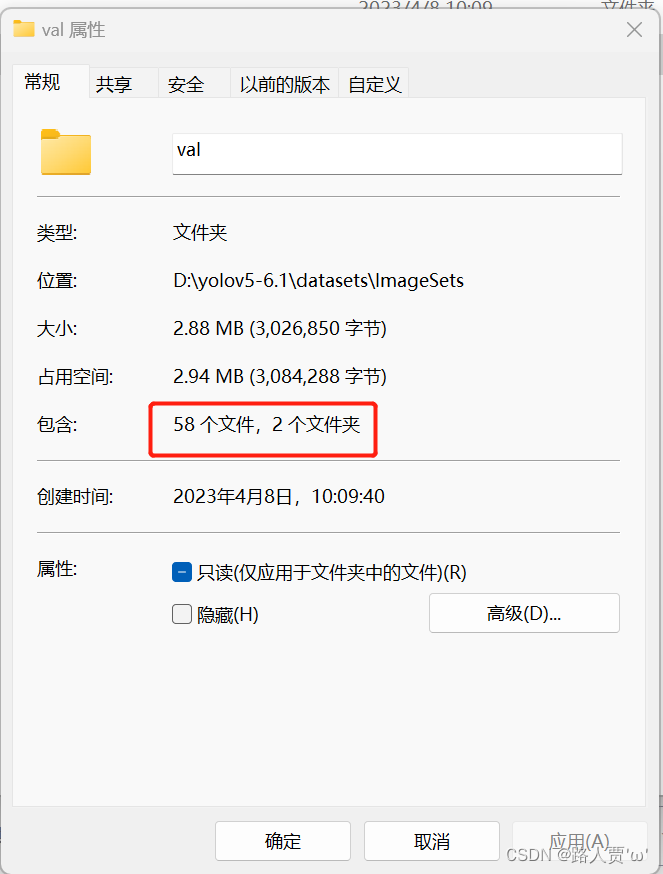
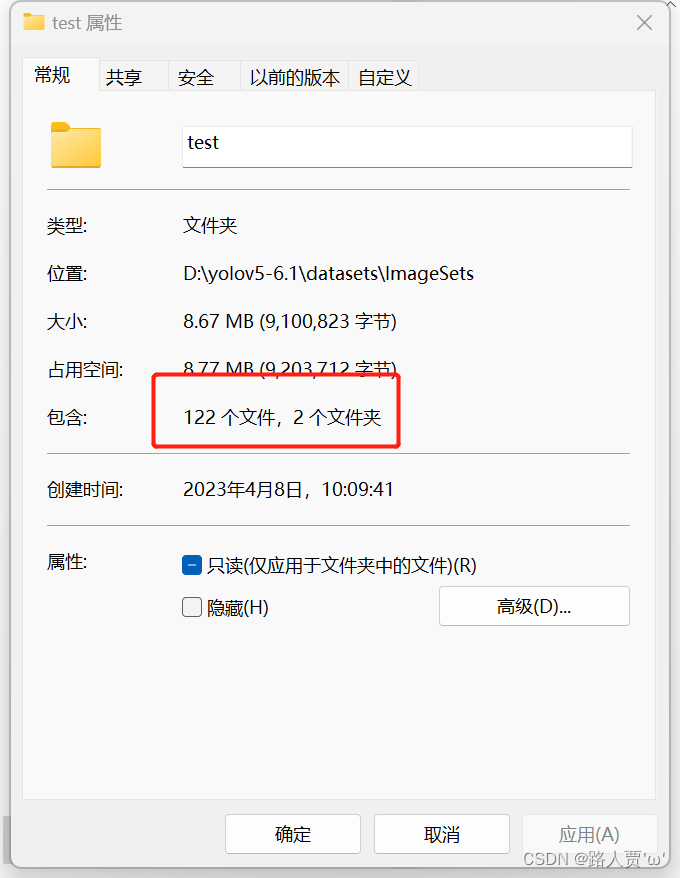
比例也符合7:1:2
** split.py完整代码**
import os
import shutil
import random
random.seed(0)
def split_data(file_path,xml_path, new_file_path, train_rate, val_rate, test_rate):
each_class_image = []
each_class_label = []
for image in os.listdir(file_path):
each_class_image.append(image)
for label in os.listdir(xml_path):
each_class_label.append(label)
data=list(zip(each_class_image,each_class_label))
total = len(each_class_image)
random.shuffle(data)
each_class_image,each_class_label=zip(*data)
train_images = each_class_image[0:int(train_rate * total)]
val_images = each_class_image[int(train_rate * total):int((train_rate + val_rate) * total)]
test_images = each_class_image[int((train_rate + val_rate) * total):]
train_labels = each_class_label[0:int(train_rate * total)]
val_labels = each_class_label[int(train_rate * total):int((train_rate + val_rate) * total)]
test_labels = each_class_label[int((train_rate + val_rate) * total):]
for image in train_images:
print(image)
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'train' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in train_labels:
print(label)
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'train' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in val_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'val' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in val_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'val' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
for image in test_images:
old_path = file_path + '/' + image
new_path1 = new_file_path + '/' + 'test' + '/' + 'images'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + image
shutil.copy(old_path, new_path)
for label in test_labels:
old_path = xml_path + '/' + label
new_path1 = new_file_path + '/' + 'test' + '/' + 'labels'
if not os.path.exists(new_path1):
os.makedirs(new_path1)
new_path = new_path1 + '/' + label
shutil.copy(old_path, new_path)
if __name__ == '__main__':
file_path = "D:\yolov5-6.1\datasets\image"
xml_path = "D:\yolov5-6.1\datasets\Annotation"
new_file_path = "D:\yolov5-6.1\datasets\ImageSets"
split_data(file_path,xml_path, new_file_path, train_rate=0.7, val_rate=0.1, test_rate=0.2)
本文参考:
三天玩转yolo——数据集格式转化及训练集和验证集划分 - 知乎 (zhihu.com)
【yolov5】将标注好的数据集进行划分(附完整可运行python代码)

版权归原作者 路人贾'ω' 所有, 如有侵权,请联系我们删除。