
图像中的注意力机制详解
注意力机制目前主要有通道注意力机制和空间注意力机制两种
一、 前言
我们知道,输入一张图片,神经网络会提取图像特征,每一层都有不同大小的特征图。如图1所示,展示了 VGG网络在提取图像特征时特征图的大小变化。
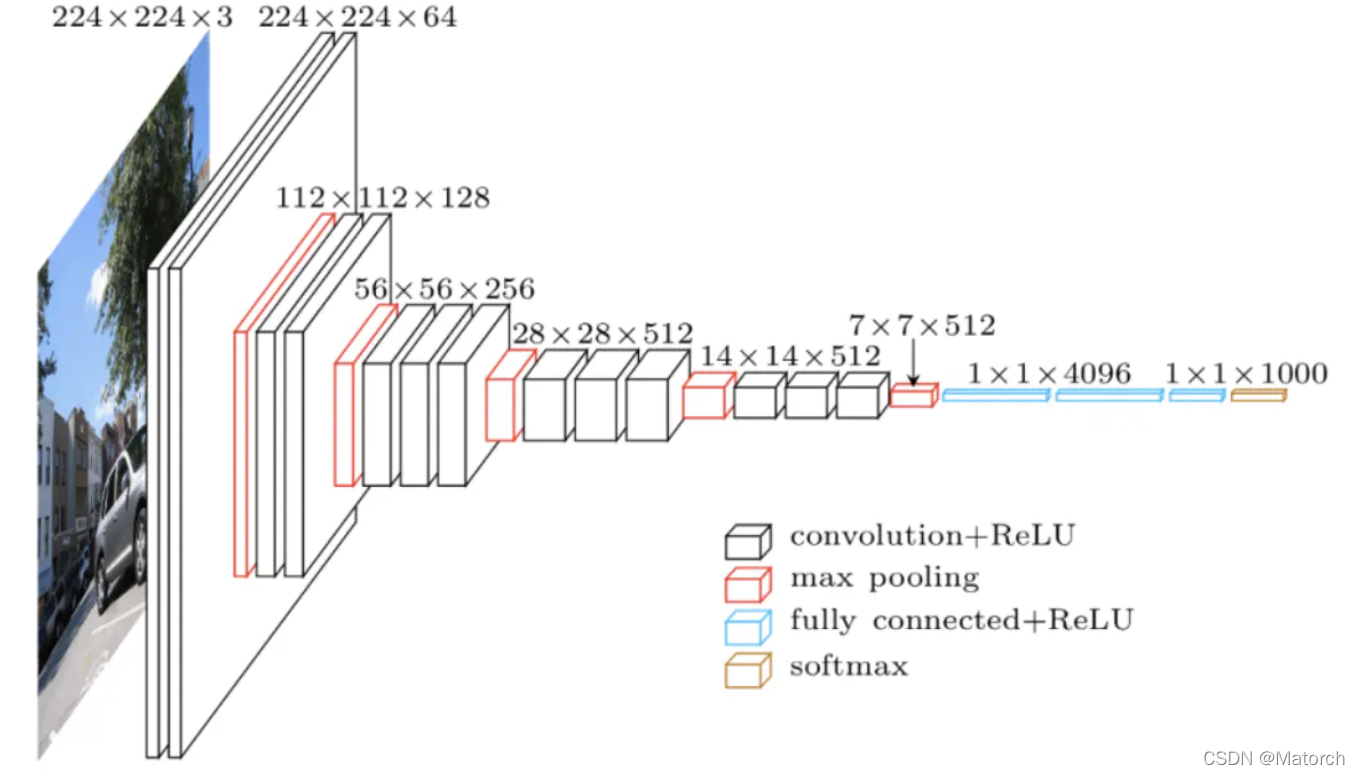
图1 VGG网络特征结构图
其中,特征图常见的矩阵形状为
[
C
,
H
,
W
]
{[C,H,W]}
[C,H,W](图1中的数字为
[
H
,
W
,
C
]
{[H,W,C]}
[H,W,C]格式)。当**model在training时,特征图的矩阵形状为
[
B
,
C
,
H
,
W
]
{[B,C,H,W]}
[B,C,H,W]**。其中B表示为batch size(批处理大小),C表示为channels(通道数),H表示为特征图的high(高度),W表示为特征图的weight(宽度)
提问:为什么特征图的维度就是
[
B
,
C
,
H
,
W
]
{[B,C,H,W]}
[B,C,H,W],而不是其他什么维度格式?
回答:pytorch在处理图像时,读入的图像处理为
[
C
,
H
,
W
]
{[C,H,W]}
[C,H,W]格式,如果在训练时加入batch size,那么就有多个特征图,将batch size放在第一维,自然就是
[
B
,
C
,
H
,
W
]
{[B,C,H,W]}
[B,C,H,W]。这是pytorch的处理方式
在网络提取图像特征层时,通过在卷积层之间添加通道注意力机制、空间注意力机制可以增强网络提取图像的能力。在编写代码时,考虑的是特征图间的attention机制,因此代码输入是
[
B
,
C
,
H
,
W
]
{[B,C,H,W]}
[B,C,H,W]的特征图,输出仍然是
[
B
,
C
,
H
,
W
]
{[B,C,H,W]}
[B,C,H,W]维的特征图。让我们接下来通过三篇论文来看这两种注意力机制是如何工作的。
二、SENet——通道注意力机制
1. 论文介绍
论文名称:Squeeze-and-Excitation Networks
论文链接:https://arxiv.org/pdf/1709.01507.pdf
论文代码: https://github.com/hujie-frank/SENet
SEBlock结构图:
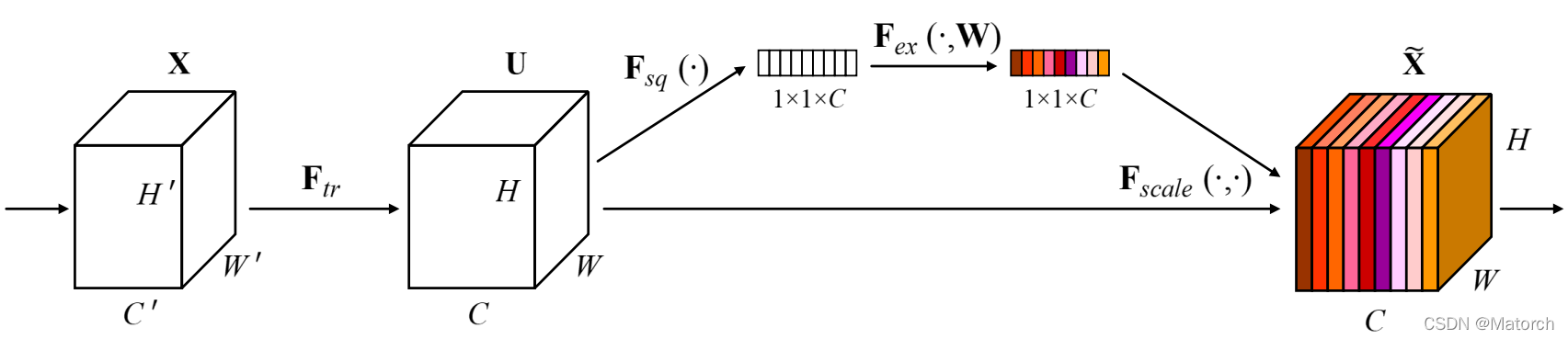
图2 SEBlock结构图
Abstract: The central building block of convolutional neural networks (CNNs) is the convolution operator, which enables networks to construct informative features by fusing both spatial and channel-wise information within local receptive fields at each layer. A broad range of prior research has investigated the spatial component of this relationship, seeking to strengthen the representational power of a CNN by enhancing the quality of spatial encodings throughout its feature hierarchy. **In this work, we focus instead on the channel relationship and propose a novel architectural unit, which we term the “Squeeze-and-Excitation” (SE) block, that adaptively recalibrates channel-wise feature responses by explicitly modelling interdependencies between channels. We show that these blocks can be stacked together to form SENet architectures that generalise extremely effectively across different datasets. **We further demonstrate that SE blocks bring significant improvements in performance for existing state-of-the-art CNNs at slight additional computational cost. Squeeze-and-Excitation Networks formed the foundation of our ILSVRC 2017 classification submission which won first place and reduced the top-5 error to 2.251%, surpassing the winning entry of 2016 by a relative improvement of ∼25%. Models and code are available at https://github.com/hujie-frank/SENet.
摘要重点:
卷积神经网络(CNN)的核心组成部分是卷积算子,它使网络能够通过融合每层局部感受野中的空间和通道信息来构建信息特征。之前的大量研究已经调查了这种关系的空间成分,并试图通过在CNN的特征层次中提高空间编码的质量来增强CNN。在这项工作中,我们将重点放在通道(channel-wise)关系上,并提出了一个新的名为SE模块的架构单元,它通过显式地建模通道之间的相互依赖性,自适应地重新校准通道特征响应。这些模块可以堆叠在一起形成SENet网络结构,并在多个数据集上非常有效地推广。
SEBlock创新点:
- SEBlock会给每个通道一个权重,让不同通道对结果有不同的作用力。
- 这个SE模块能够非常方便地添加进目前主流的神经网络当中。
2. 算法解读
图3展示了通道注意力机制的四个步骤,具体如下:
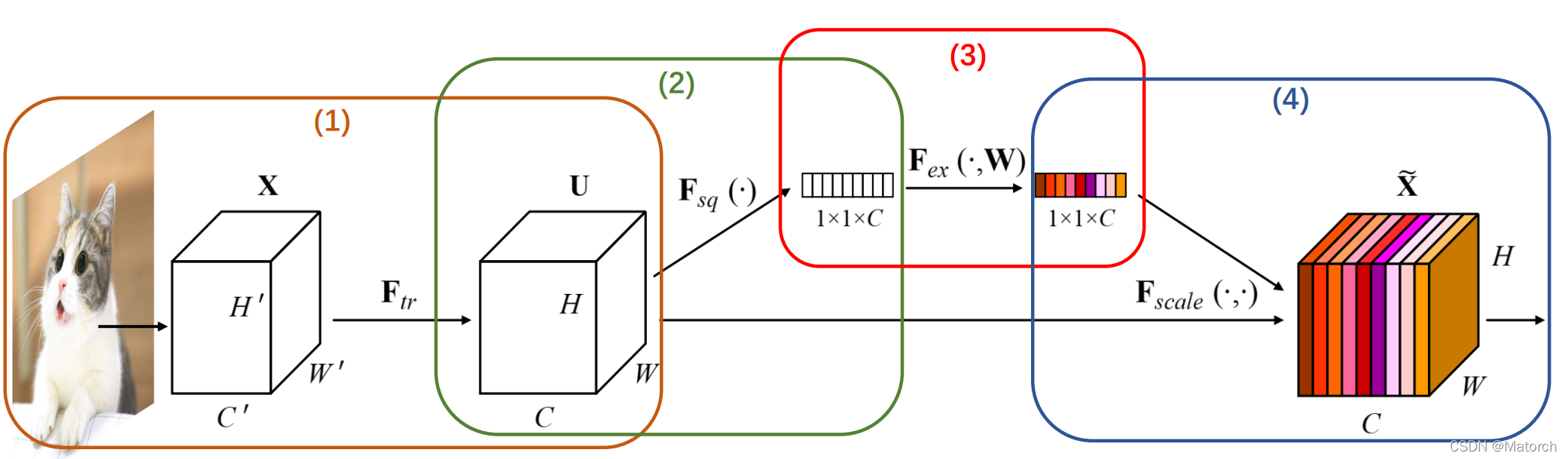
图3 SEBlock模块分析
- **从单张图像开始,提取图像特征,当前特征层U的特征图维度为 [ C , H , W ] {[C,H,W]} [C,H,W]**。
- 对特征图的 [ H , W ] {[H,W]} [H,W]维度进行平均池化或最大池化,池化过后的特征图大小从 [ C , H , W ] {[C,H,W]} [C,H,W]-> [ C , 1 , 1 ] {[C,1,1]} [C,1,1]。 [ C , 1 , 1 ] {[C,1,1]} [C,1,1]可理解为对于每一个通道C,都有一个数字和其一一对应。图4对应了步骤(2)的具体操作。
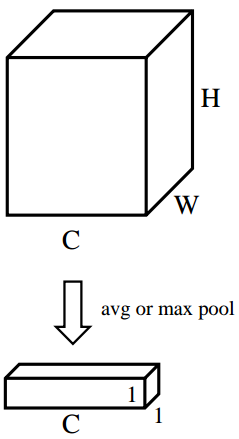
图4 平均池化(最大池化)操作,得到每个通道的权重,得到每个通道的权重
- 对 [ C , 1 , 1 ] {[C,1,1]} [C,1,1]的特征可以理解为,从每个通道本身提取出来的权重,权重表示了每个通道对特征提取的影响力,全局池化后的向量通过MLP网络后,其意义为得到了每个通道的权重。图5对应了步骤(3)的具体操作。

图5 通道权重生成
- 上述步骤,得到了每个通道C的权重 [ C , 1 , 1 ] {[C,1,1]} [C,1,1],将权重作用于特征图U [ C , H , W ] {[C,H,W]} [C,H,W],即每个通道各自乘以各自的权重。可以理解为,当权重大时,该通道特征图的数值相应的增大,对最终输出的影响也会变大;当权重小时,该通道特征图的数值就会更小,对最终输出的影响也会变小。图6对应了步骤(4)的具体操作。
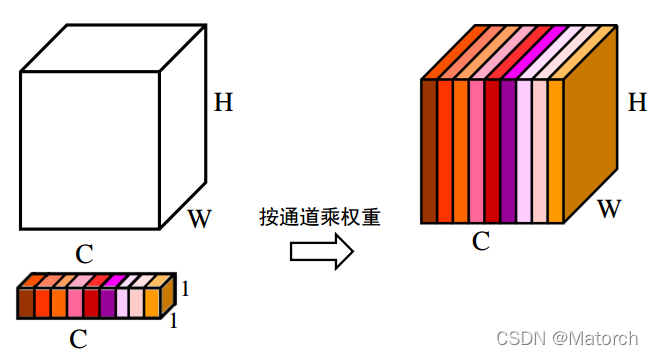
图6 通道注意力——各通道乘以各自不同权重
原论文中给出了通道注意力网络细节,这里展示出来,如图7所示。
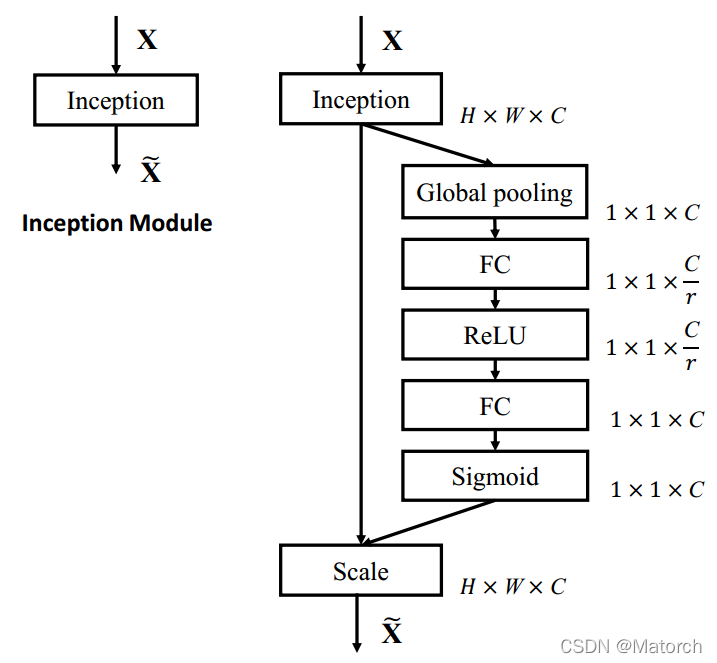
图7 SEBlock实现前(左)后(右)对比
注:文中经过对比实验发现,
r
r
r取16的时候效果最好,所以一般默认
r
=
16
r=16
r=16,但当通道数很小的时候,需要自己再调整
3. Pytorch代码实现
import torch
import torch.nn as nn
classSEBlock(nn.Module):def__init__(self, mode, channels, ratio):super(SEBlock, self).__init__()
self.avg_pooling = nn.AdaptiveAvgPool2d(1)
self.max_pooling = nn.AdaptiveMaxPool2d(1)if mode =="max":
self.global_pooling = self.max_pooling
elif mode =="avg":
self.global_pooling = self.avg_pooling
self.fc_layers = nn.Sequential(
nn.Linear(in_features = channels, out_features = channels // ratio, bias =False),
nn.ReLU(),
nn.Linear(in_features = channels // ratio, out_features = channels, bias =False),)
self.sigmoid = nn.Sigmoid()defforward(self, x):
b, c, _, _ = x.shape
v = self.global_pooling(x).view(b, c)
v = self.fc_layers(v).view(b, c,1,1)
v = self.sigmoid(v)return x * v
if __name__ =="__main__":
model = SEBlock("max",54,9)
feature_maps = torch.randn((8,54,32,32))
model(feature_maps)
4. 个人理解
通道注意力机制为什么有效的原因:特征图在提取图像特征的过程当中,不可避免的就是会出现有些特征图层作用大,而有些特征图层作用小。因此由通道本身提取出的权重施加在特征图上,保证了在特征图提取特征的基础上,自适应地给定通道权重,让作用大的特征图对结果的影响更大一点。因此在最终结果上是比普通的卷积层要更有效提取特征一点。
三、ECANet——通道注意力机制(一维卷积替换SENet中的MLP)
1. 论文介绍
论文名称:ECA-Net: Efficient Channel Attention for Deep Convolutional Neural Networks
论文链接:https://arxiv.org/pdf/1910.03151.pdf
论文代码:https://github.com/BangguWu/ECANet
ECABlock主要结构图
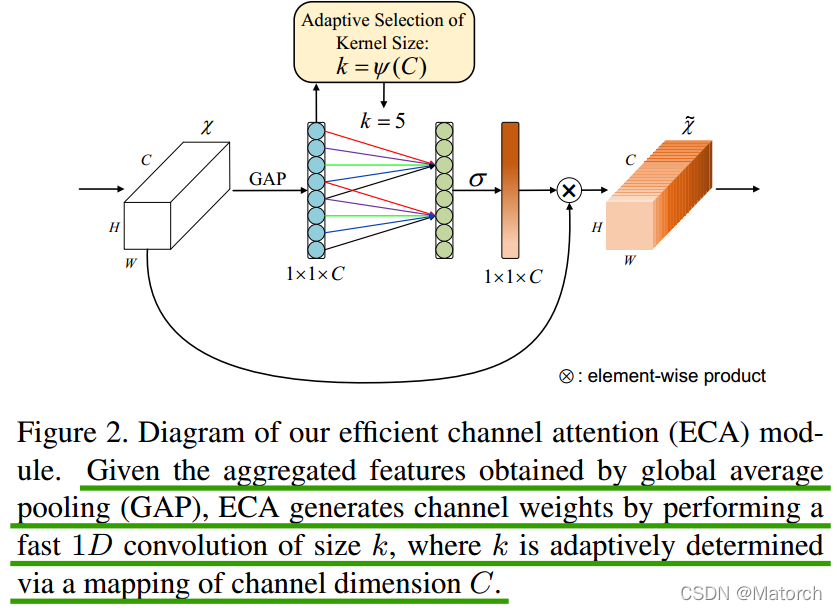
图8 有效通道注意(ECA)模块示意图
Abstract: Recently, channel attention mechanism has demonstrated to offer great potential in improving the performance of deep convolutional neural networks (CNNs). However, most existing methods dedicate to developing more sophisticated attention modules for achieving better performance, which inevitably increase model complexity. To overcome the paradox of performance and complexity trade-off, this paper proposes an Efficient Channel Attention (ECA) module, which only involves a handful of parameters while bringing clear performance gain. **By dissecting the channel attention module in SENet, we empirically show avoiding dimensionality reduction is important for learning channel attention, and appropriate cross-channel interaction can preserve performance while significantly decreasing model complexity. Therefore, we propose a local crosschannel interaction strategy without dimensionality reduction, which can be efficiently implemented via 1D convolution. **Furthermore, we develop a method to adaptively select kernel size of 1D convolution, determining coverage of local cross-channel interaction. The proposed ECA module is efficient yet effective, e.g., the parameters and computations of our modules against backbone of ResNet50 are 80 vs. 24.37M and 4.7e-4 GFLOPs vs. 3.86 GFLOPs, respectively, and the performance boost is more than 2% in terms of Top-1 accuracy. We extensively evaluate our ECA module on image classification, object detection and instance segmentation with backbones of ResNets and MobileNetV2. The experimental results show our module is more efficient while performing favorably against its counterparts.
摘要重点:
近年来,通道注意机制在改善深度卷积神经网络(CNN)性能方面显示出巨大的潜力。然而,大多数现有方法致力于开发更复杂的注意模块,以获得更好的性能,这不可避免地增加了模型的复杂性。为了克服性能和复杂性之间的矛盾,本文提出了一种高效的通道注意(ECA)模块,该模块只涉及少量参数,同时带来明显的性能增益。通过剖析SENet中的通道注意模块,我们实证地表明,避免维度缩减对于学习通道注意非常重要,适当的跨通道交互可以在显著降低模型复杂度的同时保持性能。因此,我们提出了一种无降维的局部交叉信道交互策略,该策略可以通过一维卷积有效地实现。
ECABlock创新点
- 针对SEBlock的步骤(3),将MLP模块(FC->ReLU>FC->Sigmoid),转变为一维卷积的形式,有效减少了参数计算量(我们都知道在CNN网络中,往往连接层是参数量巨大的,因此将全连接层改为一维卷积的形式)
- 一维卷积自带的功效就是非全连接,每一次卷积过程只和部分通道的作用,即实现了适当的跨通道交互而不是像全连接层一样全通道交互。
2. 论文解读
**给定通过平均池化(average pooling)获得的聚合特征
[
C
,
1
,
1
]
{[C,1,1]}
[C,1,1],ECA模块通过执行卷积核大小为k的一维卷积来生成通道权重,其中k通过通道维度C的映射自适应地确定。**
图中与SEBlock不一样的地方仅在于SEBlock的步骤(3),用一维卷积替换了全连接层,其中一维卷积核大小通过通道数C自适应确定。
自适应确定卷积核大小公式:
k
=
∣
l
o
g
2
C
+
b
γ
∣
o
d
d
{k=|\cfrac{log_2{C}+b}{\gamma}|_{odd}}
k=∣γlog2C+b∣odd
其中k表示卷积核大小,C表示通道数,
∣
∣
o
d
d
{| |_{odd}}
∣∣odd表示k只能取奇数,
γ
{\gamma}
γ和
b
{b}
b在论文中设置为2和1,用于改变通道数C和卷积核大小和之间的比例。
(如何理解通道C自适应确定卷积核大小:当通道数多的时候,我需要卷积核k稍大一点,当通道数少的时候,我需要卷积核k稍微小一点,这样能充分融合部分通道间的交互)
3. Pytorch代码实现
import math
import torch
import torch.nn as nn
classECABlock(nn.Module):def__init__(self, channels, gamma =2, b =1):super(ECABlock, self).__init__()
kernel_size =int(abs((math.log(channels,2)+ b)/ gamma))
kernel_size = kernel_size if kernel_size %2else kernel_size +1
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.conv = nn.Conv1d(1,1, kernel_size = kernel_size, padding =(kernel_size -1)//2, bias =False)
self.sigmoid = nn.Sigmoid()defforward(self, x):
v = self.avg_pool(x)
v = self.conv(v.squeeze(-1).transpose(-1,-2)).transpose(-1,-2).unsqueeze(-1)
v = self.sigmoid(v)return x * v
if __name__ =="__main__":
features_maps = torch.randn((8,54,32,32))
model = ECABlock(54, gamma =2, b =1)
model(features_maps)
这里对比了两个论文的代码实现,可以看到,只是把MLP更换为了一维卷积。
# SEBlock 采用全连接层方式defforward(self, x):
b, c, _, _ = x.shape
v = self.global_pooling(x).view(b, c)
v = self.fc_layers(v).view(b, c,1,1)
v = self.sigmoid(v)return x * v
# ECABlock 采用一维卷积方式defforward(self, x):
v = self.avg_pool(x)
v = self.conv(v.squeeze(-1).transpose(-1,-2)).transpose(-1,-2).unsqueeze(-1)
v = self.sigmoid(v)return x * v
4.个人理解
ECABlock本身没有大的内容上的改变,只是替换了全连接层,减少了数据量而已(有时候做减法比做加法好)
四、 CBAMBlock——通道注意力机制和空间注意力机制混合使用(SEBlock或ECABlock后接空间注意力机制)
1. 论文介绍
论文名称:CBAM: Convolutional Block Attention Module
论文链接:https://arxiv.org/pdf/1807.06521v2.pdf
论文代码:https://github.com/luuuyi/CBAM.PyTorch(复现版本)
CBAMBlock结构图

图9 CBAM(Convolutional Block Attention Module)模块结构
Abstract: We propose Convolutional Block Attention Module (CBAM), a simple yet effective attention module for feed-forward convolutional neural networks. Given an intermediate feature map, our module sequentially infers attention maps along two separate dimensions, channel and spatial, then the attention maps are multiplied to the input feature map for adaptive feature refinement. Because CBAM is a lightweight and general module, it can be integrated into any CNN architectures seamlessly with negligible overheads and is end-to-end trainable along with base CNNs. We validate our CBAM through extensive experiments on ImageNet-1K, MS COCO detection, and VOC 2007 detection datasets. Our experiments show consistent improvements in classification and detection performances with various models, demonstrating the wide applicability of CBAM. The code and models will be publicly available.
摘要重点:
我们提出了卷积块注意模块(CBAM),一种简单而有效的前馈卷积神经网络注意模块。给定一个中间的特征图,我们的模块采用两个独立的注意力机制,通道注意力和空间注意力,然后将注意力机制得到的权重乘以输入特征图以进行自适应特征细化。因为CBAM是一个轻量级的通用模块,它可以无缝地集成到任何CNN架构中,开销可以忽略不计,并且可以与基础CNN一起进行端到端培训。我们通过在ImageNet-1K、MS COCO检测和VOC 2007检测数据集上的大量实验来验证我们的CBAM。我们的实验表明,各种模型在分类和检测性能上都有一致的改进,证明了CBAM的广泛适用性。代码和模型将公开提供。
CBAM创新点
- 在SENet或ECANet的基础上,在通道注意力模块后,接入空间注意力模块,实现了通道注意力和空间注意力的双机制
- 选择SENet还是ECANet主要取决于通道注意力的连接是MLP还是一维卷积
- 注意力模块不再采用单一的最大池化或平均池化,而是采用最大池化和平均池化的相加或堆叠。通道注意力模块采用相加,空间注意力模块采用堆叠方式。
2. 论文解读
在上述两篇论文中已经实现了通道注意力方法的全连接(SENet)或卷积(ECANet)实现,这一篇论文与上文的最大不同点就在于,加入了空间注意力机制。
1) 通道注意力机制

图10 通道注意力模块实现方法
- 特征图分别经过MaxPool和AvgPool,形成两个 [ C , 1 , 1 ] {[C,1,1]} [C,1,1]的权重向量
- 两个权重向量分别经过同一个MLP网络(由于是同一个网络,因此也可看作是网络参数共享的MLP),映射成每个通道的权重
- 将映射后的权重相加,后接Sigmoid输出
- 将得到的通道权重 [ C , 1 , 1 ] {[C,1,1]} [C,1,1]与原特征图 [ C , H , W ] {[C,H,W]} [C,H,W]按通道相乘
整体上和SENet基本一致,只是将单一的平均池化变为了同时采用最大池化和平均池化方法。之后若将MLP稍加修改,改成一维卷积,就成为了ECANet的变形版本
2) 空间注意力机制
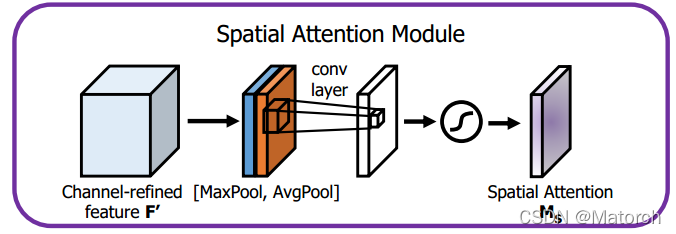
图11 空间注意力模块实现方法
- 特征图分别经过MaxPool和AvgPool,形成两个 [ 1 , H , W ] {[1,H,W]} [1,H,W]的权重向量,即按通道最大池化和平均池化。通道数从 [ C , H , W ] {[C,H,W]} [C,H,W]变为 [ 1 , H , W ] {[1,H,W]} [1,H,W],对同一特征点的所有通道池化。
- 得到的两张特征图进行堆叠,形成 [ 2 , H , W ] {[2,H,W]} [2,H,W]的特征图空间权重
- 经过一层卷积层,特征图维度从 [ 2 , H , W ] {[2,H,W]} [2,H,W]变为 [ 1 , H , W ] {[1,H,W]} [1,H,W],这 [ 1 , H , W ] {[1,H,W]} [1,H,W]的特征图表征了特征图上的每个点的重要程度,数值大的更重要
- 将得到的空间权重 [ 1 , H , W ] {[1,H,W]} [1,H,W]与原特征图 [ C , H , W ] {[C,H,W]} [C,H,W]相乘,即特征图上 [ H , W ] {[H,W]} [H,W]的每一个点都赋予了权重
我们可以看成大小为
[
H
,
W
]
{[H,W]}
[H,W]的特征图,在每一个点
(
x
,
y
)
,
x
∈
(
0
,
H
)
,
y
∈
(
0
,
W
)
{(x,y),x\in(0,H),y\in(0,W)}
(x,y),x∈(0,H),y∈(0,W)上,都有C个数值,数值表征了特征图该点的重要程度,通过感受野反推回原图像,即表示了该区域的重要程度。我们需要让网络自适应关注需要关注的地方(数值大的地方更易受到关注),空间注意力机制应运而生。
3. Pytorch代码实现
通道注意力机制——全连接层版本
import math
import torch
import torch.nn as nn
classChannel_Attention_Module_FC(nn.Module):def__init__(self, channels, ratio):super(Channel_Attention_Module_FC, self).__init__()
self.avg_pooling = nn.AdaptiveAvgPool2d(1)
self.max_pooling = nn.AdaptiveMaxPool2d(1)
self.fc_layers = nn.Sequential(
nn.Linear(in_features = channels, out_features = channels // ratio, bias =False),
nn.ReLU(),
nn.Linear(in_features = channels // ratio, out_features = channels, bias =False))
self.sigmoid = nn.Sigmoid()defforward(self, x):
b, c, h, w = x.shape
avg_x = self.avg_pooling(x).view(b, c)
max_x = self.max_pooling(x).view(b, c)
v = self.fc_layers(avg_x)+ self.fc_layers(max_x)
v = self.sigmoid(v).view(b, c,1,1)return x * v
通道注意力机制——一维卷积版本
classChannel_Attention_Module_Conv(nn.Module):def__init__(self, channels, gamma =2, b =1):super(Channel_Attention_Module_Conv, self).__init__()
kernel_size =int(abs((math.log(channels,2)+ b)/ gamma))
kernel_size = kernel_size if kernel_size %2else kernel_size +1
self.avg_pooling = nn.AdaptiveAvgPool2d(1)
self.max_pooling = nn.AdaptiveMaxPool2d(1)
self.conv = nn.Conv1d(1,1, kernel_size = kernel_size, padding =(kernel_size -1)//2, bias =False)
self.sigmoid = nn.Sigmoid()defforward(self, x):
avg_x = self.avg_pooling(x)
max_x = self.max_pooling(x)
avg_out = self.conv(avg_x.squeeze(-1).transpose(-1,-2)).transpose(-1,-2).unsqueeze(-1)
max_out = self.conv(max_x.squeeze(-1).transpose(-1,-2)).transpose(-1,-2).unsqueeze(-1)
v = self.sigmoid(avg_out + max_out)return x * v
空间注意力机制
classSpatial_Attention_Module(nn.Module):def__init__(self, k:int):super(Spatial_Attention_Module, self).__init__()
self.avg_pooling = torch.mean
self.max_pooling = torch.max# In order to keep the size of the front and rear images consistent# with calculate, k = 1 + 2p, k denote kernel_size, and p denote padding number# so, when p = 1 -> k = 3; p = 2 -> k = 5; p = 3 -> k = 7, it works. when p = 4 -> k = 9, it is too big to use in networkassert k in[3,5,7],"kernel size = 1 + 2 * padding, so kernel size must be 3, 5, 7"
self.conv = nn.Conv2d(2,1, kernel_size =(k, k), stride =(1,1), padding =((k -1)//2,(k -1)//2),
bias =False)
self.sigmoid = nn.Sigmoid()defforward(self, x):# compress the C channel to 1 and keep the dimensions
avg_x = self.avg_pooling(x, dim =1, keepdim =True)
max_x, _ = self.max_pooling(x, dim =1, keepdim =True)
v = self.conv(torch.cat((max_x, avg_x), dim =1))
v = self.sigmoid(v)return x * v
CBAM模块(空间注意力和通道注意力二者结合)
classCBAMBlock(nn.Module):def__init__(self, channel_attention_mode:str, spatial_attention_kernel_size:int, channels:int=None,
ratio:int=None, gamma:int=None, b:int=None):super(CBAMBlock, self).__init__()if channel_attention_mode =="FC":assert channels !=Noneand ratio !=Noneand channel_attention_mode =="FC", \
"FC channel attention block need feature maps' channels, ratio"
self.channel_attention_block = Channel_Attention_Module_FC(channels = channels, ratio = ratio)elif channel_attention_mode =="Conv":assert channels !=Noneand gamma !=Noneand b !=Noneand channel_attention_mode =="Conv", \
"Conv channel attention block need feature maps' channels, gamma, b"
self.channel_attention_block = Channel_Attention_Module_Conv(channels = channels, gamma = gamma, b = b)else:assert channel_attention_mode in["FC","Conv"], \
"channel attention block must be 'FC' or 'Conv'"
self.spatial_attention_block = Spatial_Attention_Module(k = spatial_attention_kernel_size)defforward(self, x):
x = self.channel_attention_block(x)
x = self.spatial_attention_block(x)return x
if __name__ =="__main__":
feature_maps = torch.randn((8,54,32,32))
model = CBAMBlock("FC",5, channels =54, ratio =9)
model(feature_maps)
model = CBAMBlock("Conv",5, channels =54, gamma =2, b =1)
model(feature_maps)
4. 个人理解
空间注意力机制与通道注意力机制有异曲同工之妙,都是通过提取权重,作用在原特征图上,只不过一个是在
[
H
,
W
]
{[H,W]}
[H,W]维度上,一个是在
[
C
]
{[C]}
[C]维度上,这样的方法在不增加过多的计算量的前提下能提点,不失为一个好的trick。
Attention is all you need!
版权归原作者 Matorch 所有, 如有侵权,请联系我们删除。