
一、
bottleneck layery中文名称:瓶颈层。我初次接触也就是在残差网络中。一般在较深的网络中,如resnet101中使用。
一般的结构如下:
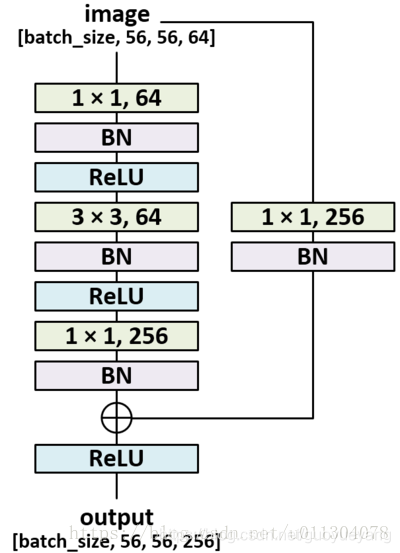
其中两个1X1fliter分别用于降低和升高特征维度,主要目的是为了减少参数的数量,从而减少计算量,且在降维之后可以更加有效、直观地进行数据的训练和特征提取,对比如下图所示:

瓶颈层使用的是1*1的卷积神经网络,之所以称之为瓶颈层,是因为长得比较像一个瓶颈:中间比较细,像一个瓶子的颈部。

如上图所示,经过1x1的网络,中间那个看起来比较细。使用1x1网络的一大好处就是可以大幅减少计算量。深度可分离卷积中,也有这样的设计考虑。Bottleneck 结构为之后的深度可分离卷积Depthwise Separable Conv(深度可分离卷积 - 知乎)打下了坚实的基础。
(1)ResNet中的Bottleneck layer
Bottleneck layer这种结构比较常见的出现地方就是ResNet block
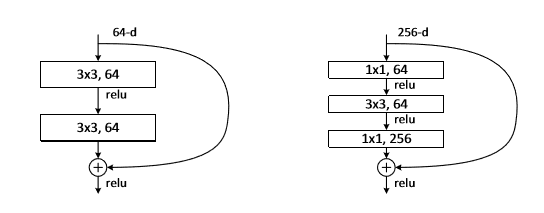
(a)没有bottleneck (b)有bottleneck
如图所示分别是有bottleneck和没有bottleneck的ResNet模块。我们看到,使用 1 x 1 的网络结构很方便改变维度。灵活设计网络,并且减小计算量。(来自论文:Deep Residual Learning for Image Recognition)
(2)Linear Bottleneck
Linear Bottleneck这个结构设计来自论文**MobileNetV2: Inverted Residual and Linear Bottlenecks **下面就来具体解释一下。
这篇论文中的网络模块也参考了ResNet的网络模块,使用了 1 x 1 的卷积,但所不同的是因为MobileNetV2使用了深度可分离卷积,所以网络结构样子有所调整。
MobileNetV2结构基于inverted residual(本质是一个残差网络设计,传统Residual block是block的两端channel通道数多,中间少,而本文设计的inverted residual是block的两端channel通道数少,block内channel多,类似于沙漏和梭子形态的区别)。
如果详细具体了解Linear Bottleneck,可以看我写的MobileNetV2[链接]
二、
2.1、Bottleneck 结构
在inception网络中,为了减少参数量,我们想了很多方法,例如:用多个小尺寸卷积代替一个大尺寸卷积;做下面的变换:
3x3 = 3x1 + 1x3,这个效果在深度较深的情况下比规整的卷积核更好,当然也包括经典的bottleneck结构。
Bottleneck结构就是为了降低参数量,Bottleneck三步走是先PW(Pointwise Convolution点卷积,也叫1x1卷积)对数据进行降维,再进行常规卷积核的卷积,最后PW对数据进行升维(类似于沙漏型)。我们举个例子,方便我们理解:
根据上图我们来做个计算对比,假设输入的特征图的维度为256维,要求输出维度也是256维。有以下两种操作:
(1)直接使用3x3的卷积核。256维的输入直接经过一个3x3x256的卷积层,输出一个256维的特征图,那么参数量为:256(输入)x3x3x256(卷积核) = 589824
(2)先经过1x1的卷积核,再经过3x3的卷积核,最后经过一个1x1的卷积核。256维的输入先经过一个1x1x64的卷积层,再经过一个3x3x64的卷积层,最后经过一个1x1x256的卷积层,则总参数量为:
256(输入)x1x1x64(卷积核) + 64(输入)x3x3x64(卷积核) + 64(输入)x1x1x256(卷积核) = 69632。
经过两种方式的对比,我们可以很明显的看到(2)中的方式的参数量远小于(1)的方式的。Bottleneck的核心思想还是利用多个小卷积核代替一个大卷积核,利用1x1卷积核代替大的卷积核的一部分工作。
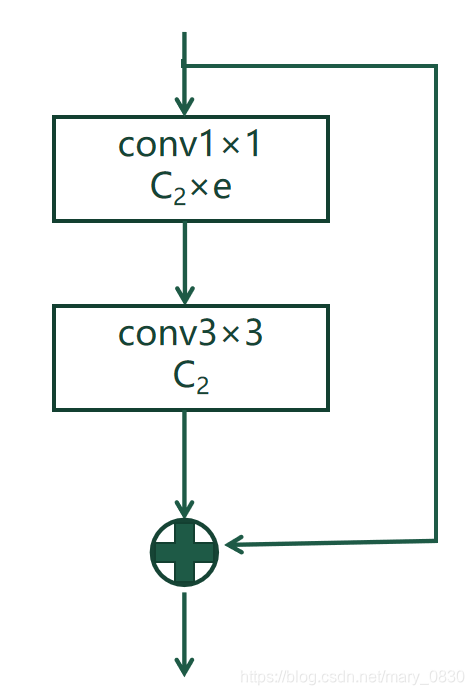
四、标准的BottleNeck
class Bottleneck():
def __init__(self, c1, c2, shortcut=True, g=1, e=0.5): # ch_in, ch_out, shortcut, groups, expansion
super(Bottleneck,self).__init__()
c_ = int(c2 * e) #hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1, g = g)
self.add = shortcut and c1==c2
def forward(self, x):
return x + self.cv2(self.cv1(x)) if self.add else self.cv2(self.cv1(x))
参考:
介绍Bottleneck layer结构 - 知乎 (zhihu.com)
(1条消息) 为什么要分别使用11,33,11的卷积核进行降维和升维_Cool_Uncle的博客-CSDN博客_11卷积核降维
33卷积+13卷积+3*1卷积=白给的精度提升 | ICCV 2019 - 知乎 (zhihu.com)
对于xception非常好的理解 - 简书 (jianshu.com)
CNN模型合集 | 26 HarDNet - 知乎 (zhihu.com)
YOLOv5代码详解(common.py部分)_Liaojiajia-2020的博客-CSDN博客
版权归原作者 曙光_deeplove 所有, 如有侵权,请联系我们删除。